Автор: Денис Аветисян
Новая система EgoAVU позволяет создавать огромные объемы данных для обучения ИИ, анализируя видео от первого лица и сопоставляя их со звуком и текстом.
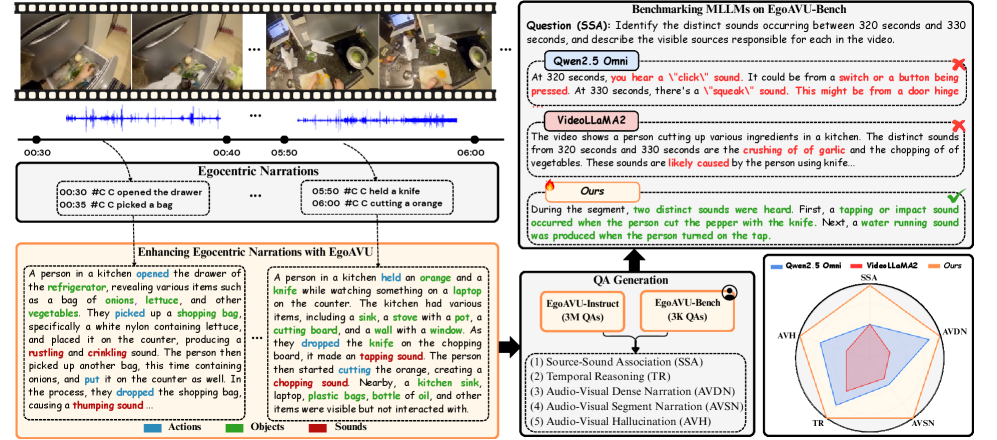
Представлен EgoAVU — полностью автоматизированный движок для генерации масштабных аудио-визуально-языковых данных из эгоцентричных видео, повышающий эффективность мультимодальных языковых моделей в задачах понимания.
Несмотря на успехи мультимодальных больших языковых моделей, их способность к комплексному анализу аудиовизуальной информации в эгоцентричных видео остается недостаточно изученной. В данной работе, представленной под названием ‘EgoAVU: Egocentric Audio-Visual Understanding’, предлагается EgoAVU — масштабируемый движок для автоматической генерации аудиовизуальных описаний, вопросов и ответов, обогащающий существующие данные мультимодальным контекстом. Созданный на его основе датасет EgoAVU-Instruct позволяет существенно улучшить понимание эгоцентричных видео моделями, демонстрируя прирост производительности до 113% на специально разработанном бенчмарке EgoAVU-Bench. Возможно ли с помощью подобных подходов создать действительно «зрячие и слышащие» системы искусственного интеллекта, способные полноценно взаимодействовать с миром?
Постижение Перспективы: Анализ Эгоцентричных Видеоданных
Видеозаписи от первого лица, известные как эгоцентричные видео, представляют собой значительную проблему для систем, анализирующих одновременно звук и изображение. Их сложность обусловлена тем, что камера движется вместе с пользователем, создавая нестабильную перспективу и быстрые изменения в поле зрения. В отличие от традиционных видео, где сцена зафиксирована, эгоцентричные записи отражают динамичный и непредсказуемый мир, что затрудняет точное определение объектов и действий. Более того, отсутствие тщательно подготовленных меток, описывающих происходящее, требует от алгоритмов самостоятельного извлечения смысла из хаотичного потока визуальной и звуковой информации, что существенно повышает сложность задачи.
Современные методы анализа видео, снятых от первого лица, сталкиваются с серьезными трудностями при понимании сложных взаимосвязей между действиями, объектами и звуками в динамичных сценах. Особенность таких видеозаписей заключается в их неструктурированности и отсутствии четких меток, что затрудняет автоматическое определение происходящего. Например, определение контекста действия, такого как «нарезка овощей», требует одновременного анализа визуальных признаков (движения рук, форма овощей), звуков (шум ножа, шуршание овощей) и их взаимосвязи. Неспособность адекватно учитывать эти нюансы препятствует созданию эффективных систем автоматической расшифровки и озвучивания подобных видео, ограничивая их применимость в областях, требующих детального понимания происходящего, таких как робототехника или системы помощи людям с ограниченными возможностями.
Для создания надежных мультимодальных моделей, способных эффективно анализировать видео, снятые от первого лица, необходим масштабируемый подход к автоматической генерации богатых и разнообразных наборов данных. Существующие методы часто сталкиваются с ограничениями при обработке неструктурированных, динамичных сцен, характерных для такого рода видеоматериалов. Автоматизированное создание данных позволяет преодолеть эти трудности, обеспечивая возможность обучения моделей на большом объеме информации, отражающей различные сценарии и взаимодействия. Такой подход позволит существенно повысить точность распознавания действий, объектов и звуков, а также улучшить способность моделей к генерации осмысленных описаний происходящего, что критически важно для широкого спектра приложений, от робототехники до помощи людям с ограниченными возможностями.
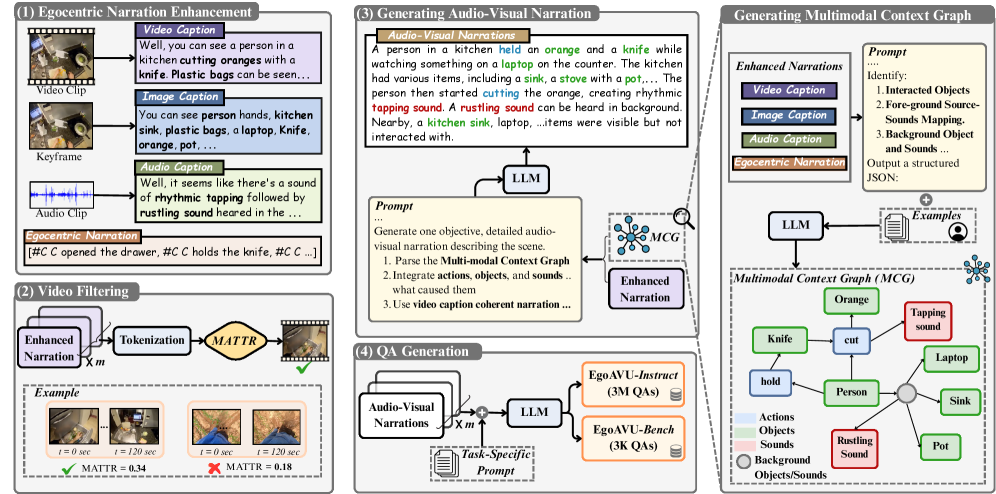
EgoAVU: Автоматизированная Генерация Данных для Мультимодального Обучения
EgoAVU использует возможности больших языковых моделей, таких как LLaMA-70B, для создания ‘Мультимодального графа контекста’, представляющего взаимосвязи между объектами и событиями в каждом кадре видео. Этот граф строится на основе анализа визуальной информации и сопутствующего аудио, позволяя модели понимать не только что происходит в кадре, но и как различные элементы связаны между собой. В частности, LLaMA-70B применяется для извлечения сущностей и отношений, которые затем структурируются в виде узлов и ребер графа, формируя комплексное семантическое представление видеокадра. Это позволяет EgoAVU генерировать более точные и когерентные описания, учитывающие полный контекст происходящего.
Графовое представление, создаваемое EgoAVU, является основой для генерации разнообразных и связных повествований, поскольку позволяет учитывать существенный аудиовизуальный контекст каждого кадра видео. Каждый узел графа представляет собой объект или действие, идентифицированное в кадре, а ребра отражают взаимосвязи между ними. Используя этот структурированный подход, EgoAVU может генерировать описания, которые не просто перечисляют объекты, но и описывают их взаимодействие и последовательность событий, обеспечивая более полное и осмысленное представление видеоконтента. Это позволяет создавать обучающие данные, которые отражают сложность реальных визуальных сцен и улучшают способность моделей машинного обучения понимать и интерпретировать видео.
Использование открытых моделей в EgoAVU обеспечивает масштабируемость и воспроизводимость процесса генерации данных, что критически важно для обучения моделей машинного обучения. Открытый исходный код позволяет исследователям и разработчикам адаптировать и улучшать систему, а также проверять и подтверждать результаты. Это способствует демократизации доступа к высококачественным обучающим данным, позволяя широкому кругу пользователей создавать и использовать системы многомодального обучения без ограничений, связанных с проприетарным программным обеспечением или дорогостоящими ресурсами.
Обеспечение Разнообразия Данных с Помощью Временной Фильтрации
Для повышения разнообразия данных, EgoAVU использует фильтрацию по временной динамике (Temporal Diversity Filtering). Данный процесс отбора видеоклипов направлен на выявление и приоритезацию фрагментов, демонстрирующих широкий спектр аудиовизуальных изменений. Это достигается путем анализа динамики звука и изображения в каждом клипе и выбора тех, которые отличаются наибольшим разнообразием в этих характеристиках, что позволяет охватить более широкий диапазон сценариев и ситуаций, представленных в данных.
Для оценки лексического разнообразия генерируемых описаний в EgoAVU используется метрика MATTR (Measure of Textual Token Repetition) со значением порога 0.3. Данный порог позволяет отбирать описания, демонстрирующие богатый и нюансированный словарный запас, что способствует более полному представлению видеоконтента. При этом, для сохранения наиболее релевантных и информативных отрывков, отбираются описания, входящие в верхние 75% распределения значений MATTR. Это обеспечивает баланс между разнообразием лексики и общей качеством генерируемых текстов.
В рамках EgoAVU, отбор видеофрагментов с высокими значениями метрики MATTR осуществляется для повышения репрезентативности данных. Высокий показатель MATTR указывает на лексическое разнообразие в сгенерированных описаниях к видео, что коррелирует с большей сложностью и информативностью аудиовизуального контента сцены. Приоритет отдается фрагментам, содержащим широкий спектр лексических единиц, что позволяет более полно отразить детали и нюансы происходящего в видео, обеспечивая тем самым более разнообразный и информативный набор данных для обучения моделей.
Наборы Данных для Прогресса: Обучение и Оценка Мультимодальных Моделей
Разработанный набор данных EgoAVU-Instruct представляет собой масштабный ресурс, включающий 9 тысяч видеороликов и 3 миллиона аудиовизуальных и языковых примеров, предназначенный для обучения и совершенствования многомодальных больших языковых моделей. Этот обширный корпус данных позволяет создавать более устойчивые и эффективные модели, способные интегрировать и понимать информацию из различных источников — зрения, слуха и текста. Масштаб EgoAVU-Instruct обеспечивает более полное представление о взаимосвязях между этими модальностями, что, в свою очередь, способствует развитию моделей, обладающих улучшенными способностями к рассуждению и пониманию контекста. Особое внимание уделяется созданию качественного и разнообразного набора данных, чтобы преодолеть ограничения существующих ресурсов и обеспечить прогресс в области многомодального искусственного интеллекта.
Для объективной оценки производительности мультимодальных моделей разработан комплекс EgoAVU-Bench, представляющий собой стандартизированный набор данных, состоящий из 900 видеороликов и 3000 тщательно верифицированных примеров. Этот набор данных позволяет исследователям проводить сравнительный анализ различных подходов к обработке аудиовизуальной информации и лингвистического контекста, выявляя сильные и слабые стороны каждой модели. Тщательная ручная проверка примеров гарантирует высокое качество данных и надежность результатов оценки, что способствует прогрессу в области мультимодального машинного обучения и позволяет создавать более совершенные системы, способные эффективно взаимодействовать с реальным миром.
Исследования показали, что применение обучающего набора данных EgoAVU-Instruct для тонкой настройки модели Qwen2.5-Omni привело к значительному улучшению её производительности. В частности, относительный прирост эффективности на тестовом наборе EgoAVU-Bench достиг 113%, что свидетельствует о существенном прогрессе в понимании и обработке мультимодальной информации. Помимо этого, зафиксировано повышение результативности на 28% в задачах, представленных в наборах EgoTempo и EgoIllusion, подтверждающее универсальность и эффективность подхода к обучению моделей, способных интегрировать различные типы данных.
В ходе унимодальных оценок было выявлено, что модель Qwen2.5-Omni демонстрирует уровень ошибок в 54,3% при оценке согласованности аудио и 25,4% при оценке визуальной согласованности. В то же время, модель MiniCPM-o показала более высокие показатели ошибок — 68,2% и 31,2% соответственно. Эти результаты подчеркивают различия в способности моделей обрабатывать и сопоставлять информацию из отдельных модальностей, указывая на потенциальные области для улучшения в архитектуре и обучении моделей, ориентированных на мультимодальные задачи. Более низкие показатели ошибок Qwen2.5-Omni свидетельствуют о её большей надежности в обеспечении внутренней согласованности аудио- и визуальных данных.
Представленная работа демонстрирует элегантный подход к решению проблемы ограниченности данных в области эгоцентричного понимания видео. Авторы создали EgoAVU — автоматизированный механизм, генерирующий масштабные и качественные аудиовизуальные данные, что позволяет значительно улучшить производительность мультимодальных языковых моделей. Как однажды заметил Дэвид Марр: «Вычислительная теория восприятия должна объяснить, как физические стимулы преобразуются в представления, которые позволяют нам взаимодействовать с миром». EgoAVU, по сути, воплощает эту идею, преобразуя сырые видеоданные в структурированные представления, доступные для машинного обучения и способствующие более глубокому пониманию происходящего в эгоцентричном видеоряде. Это не просто техническое решение, а проявление уважения к сложности восприятия и стремление к созданию систем, способных к осмысленному взаимодействию с окружающим миром.
Куда же дальше?
Представленная работа, безусловно, демонстрирует элегантность автоматизированного подхода к генерации данных для обучения моделей, работающих с видео от первого лица. Однако, истинная сложность эгоцентричного восприятия заключается не в количестве данных, а в их интерпретации. Модели, обученные на сгенерированных данных, всё ещё склонны к упрощениям, не учитывающим нюансы человеческого поведения и контекста. Следующим шагом представляется не просто увеличение объёма данных, а разработка методов, позволяющих моделям понимать намерение за действием, а не просто само действие.
Очевидным ограничением остаётся зависимость от исходного видеоматериала. Автоматизированная генерация данных не может компенсировать отсутствие разнообразных сценариев и ситуаций. Потребуются усилия по созданию синтетических данных, имитирующих сложные и редкие события, чтобы модели могли адекватно реагировать на неожиданные ситуации. Иначе, мы рискуем создать системы, прекрасно работающие в лабораторных условиях, но беспомощные в реальном мире.
В конечном счёте, успех в этой области зависит от способности моделей к рассуждению и абстракции. Простого распознавания объектов недостаточно. Необходимо понимать причинно-следственные связи, предвидеть последствия действий и адаптироваться к меняющимся обстоятельствам. Это задача, требующая не только больших вычислительных ресурсов, но и глубокого понимания когнитивных процессов, лежащих в основе человеческого интеллекта.
Оригинал статьи: https://arxiv.org/pdf/2602.06139.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Искусственный интеллект: хрупкость визуального мышления
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Робот-исследователь: новый подход к автономной навигации
2026-02-09 09:57