Автор: Денис Аветисян
Новое исследование показывает, что для обучения нейросетей основанных на трансформерах, простым законам физики необходимы специальные «подсказки», выходящие за рамки увеличения размера модели или объема данных.
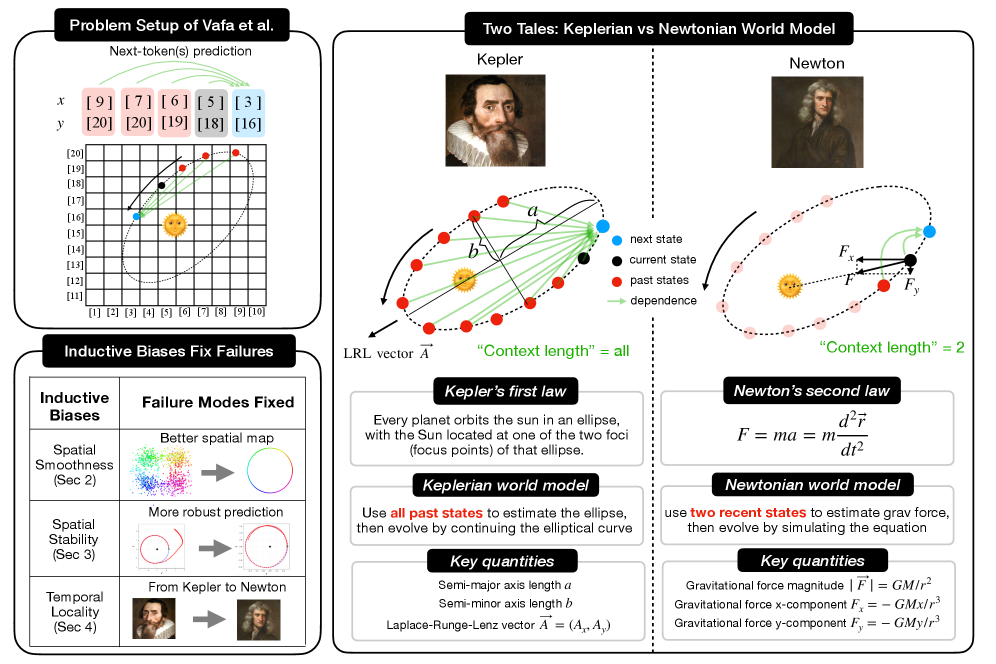
В статье демонстрируется, что ключевым фактором успешного обучения нейронных сетей моделям мира является учет принципов временной локальности и других индуктивных смещений.
Несмотря на впечатляющие успехи в предсказании, современные универсальные архитектуры искусственного интеллекта зачастую не способны выявить лежащие в основе физические законы. В работе ‘From Kepler to Newton: Inductive Biases Guide Learned World Models in Transformers’ исследуется возможность преодоления этого ограничения с помощью трансформаторных сетей, обученных моделированию физического мира. Показано, что введение минимальных априорных знаний, в частности, локальности во времени, позволяет моделям выйти за рамки простого аппроксимирования кривых и перейти к обнаружению представлений ньютоновских сил. Может ли целенаправленное внедрение индуктивных смещений стать ключевым шагом к автоматизированному научному открытию и созданию действительно «понимающего» искусственного интеллекта?
Постижение Мира: За Пределами Простого Предсказания
Современные базовые модели, такие как трансформеры, демонстрируют впечатляющую способность к распознаванию паттернов в данных, однако их возможности в понимании глубинных динамик процессов остаются ограниченными. Несмотря на умение эффективно предсказывать следующие элементы последовательности, этим моделям зачастую не хватает способности к рассуждению, основанному на причинно-следственных связях. Это связано с тем, что они оперируют, главным образом, статистическими закономерностями, не формируя внутреннего представления о структуре и эволюции окружающей среды. В результате, даже при высокой точности предсказаний, модели могут демонстрировать уязвимость в ситуациях, требующих адаптации к новым, непредсказуемым условиям, или понимания физических законов, лежащих в основе наблюдаемых явлений.
Истинный интеллект требует формирования внутренних представлений, так называемых «моделей мира», которые захватывают структуру и эволюцию окружающей среды. Эти модели не просто пассивные отражения данных, но активные симуляции, позволяющие системе предсказывать последствия действий и планировать будущее. Вместо непосредственной реакции на текущий стимул, система с развитой «моделью мира» способна мысленно проигрывать различные сценарии, оценивать их вероятность и выбирать оптимальную стратегию. Подобный подход позволяет не только адаптироваться к изменениям, но и активно формировать окружающую действительность, предвидя и предотвращая нежелательные последствия. Именно способность к построению и использованию внутренних моделей является ключевым отличием разумного поведения от простой реакции на внешние раздражители.
Современные модели машинного обучения, способные предсказывать следующее слово или пиксель, зачастую демонстрируют поверхностное понимание мира. Для достижения подлинного интеллекта необходимо создание моделей, способных улавливать не просто закономерности, а причинно-следственные связи. Такие модели должны выходить за рамки простой экстраполяции данных и формировать внутреннее представление о том, как функционирует окружающая среда, позволяя предвидеть последствия действий и планировать поведение. Они должны не просто реагировать на текущую ситуацию, но и формировать ожидания относительно будущего, что требует от них понимания динамики и принципов, управляющих миром. Вместо пассивного отражения данных, эти модели активно конструируют внутреннюю картину реальности, позволяющую им действовать проактивно и эффективно.
Для создания эффективных мировых моделей фундаментальными являются предположения о пространственной гладкости и временной локальности. Эти принципы подразумевают, что близлежащие точки в пространстве и времени взаимосвязаны и обладают схожими характеристиками. Именно эта взаимосвязь позволяет системам строить компактные и обобщающие представления окружающей среды, избегая необходимости запоминать каждый отдельный элемент. Представьте себе, что вместо запоминания каждой травинки на лугу, система учится понимать общие закономерности роста травы, что позволяет ей предсказывать ее поведение в различных условиях. Подобный подход не только снижает вычислительную сложность, но и обеспечивает более надежную экстраполяцию и адаптацию к новым, ранее не встречавшимся ситуациям, делая модели более устойчивыми и способными к полноценному пониманию окружающего мира.

Исследование Динамики: Подход Вафы и Коллег
Исследование Вафа и коллег было направлено на оценку способности архитектуры Transformer моделировать динамику движения планет, используя исключительно наблюдательные данные. В рамках работы рассматривалась возможность обучения нейронной сети прогнозировать будущие состояния планет на основе последовательности предыдущих наблюдений. Основная задача заключалась в определении, способна ли модель Transformer, изначально разработанная для обработки естественного языка, эффективно экстраполировать физические закономерности из данных о положении и скорости планет, не имея явного знания физических законов, управляющих их движением. Данный подход позволял проверить, может ли Transformer выучить внутреннее представление динамики системы, основываясь исключительно на паттернах в данных.
В исследовании Вафы и коллег для обучения модели использовался подход, основанный на предсказании следующего токена. Непрерывные данные об орбитальном движении были преобразованы в дискретную последовательность токенов посредством процесса токенизации. Это позволило применить архитектуру Transformer, изначально разработанную для обработки последовательностей текста, к задаче моделирования динамики физических систем. Токенизация необходима, поскольку Transformer работает с дискретными входными данными, а орбитальные данные по своей природе являются непрерывными величинами, такими как координаты и скорости.
В исследовании использовалась трансформерная архитектура масштаба GPT-2 для прогнозирования будущих состояний системы. Обучение проводилось на основе задачи предсказания следующего токена, где входные данные представляли собой последовательность прошлых наблюдений за состоянием системы. Для минимизации ошибки предсказания использовалась функция потерь на основе перекрестной энтропии H(p,q) = -\sum p(x)log(q(x))[latex], где [latex]p(x)[latex] - истинное распределение вероятностей, а [latex]q(x)[latex] - предсказанное моделью распределение.</p> <p>Использование архитектуры Transformer для моделирования динамики планетных движений, предложенное Vafa и соавторами, представляет собой значимый эксперимент для оценки способности данной модели к обучению представлений физических систем. В отличие от традиционных методов, требующих явного задания уравнений движения, Transformer обучается непосредственно на последовательностях наблюдаемых состояний, что позволяет исследовать возможность изучения физических законов из данных. Успешное предсказание будущих состояний на основе истории наблюдений демонстрирует потенциал Transformer к выявлению и воспроизведению скрытых закономерностей, определяющих динамику физических процессов, и открывает перспективы для применения данного подхода к моделированию других сложных систем.</p> <figure> <img alt="При решении задачи Кеплера как задачи классификации (предсказание следующего токена) точность зависит как от размера словаря, так и от объема обучающих данных, причём ограниченный объем данных благоприятствует использованию словарей меньшего размера." src="https://arxiv.org/html/2602.06923v1/x3.png" style="background-color: white;"/><figcaption>При решении задачи Кеплера как задачи классификации (предсказание следующего токена) точность зависит как от размера словаря, так и от объема обучающих данных, причём ограниченный объем данных благоприятствует использованию словарей меньшего размера.</figcaption></figure> <h2>Проверка Внутренних Представлений: Что "Знает" Трансформер?</h2> <p>Для анализа приобретенных представлений в трансформерах применяются методы, такие как линейный зондирование (linear probing). Данный подход позволяет идентифицировать направления в пространстве внутренних состояний модели, которые соответствуют конкретным концепциям или свойствам данных. Суть метода заключается в обучении линейного классификатора на основе внутренних состояний трансформера для предсказания определенных характеристик. Высокая точность классификации указывает на то, что соответствующее направление в пространстве состояний содержит информацию о данной характеристике, что позволяет понять, какие концепции усвоены моделью и как они представлены внутри.</p> <p>Анализ направлений в внутреннем состоянии трансформатора позволяет исследователям определить, усваивает ли модель исключительно предсказательные закономерности, подобные законам Кеплера, или же более глубокое, механистическое понимание базовой физики, приближающееся к законам Ньютона. В случае усвоения исключительно предсказательных закономерностей, модель выучивает корреляции между последовательными состояниями системы, но не понимает лежащие в их основе принципы. В противоположность этому, усвоение механистического понимания подразумевает, что модель научилась выявлять и использовать фундаментальные физические законы, что позволяет ей более точно предсказывать поведение системы и экстраполировать на новые, ранее не встречавшиеся условия.</p> <p>Длина контекста, определяющая количество предыдущих состояний, учитываемых трансформером, критически важна для моделирования временных зависимостей и эволюции системы. Эксперименты с линейным зондированием показали, что при длине контекста равной 2 достигается коэффициент детерминации R² в 0.999, что указывает на усвоение трансформером модели, соответствующей ньютоновской механике. Этот результат демонстрирует способность модели к построению механистического понимания динамики системы при минимальном количестве учитываемых предыдущих состояний.</p> <p>Эксперименты с линейным зондированием показали, что длина контекста оказывает существенное влияние на динамику, которую изучает трансформер. При длине контекста в 2 шага, модель демонстрирует поведение, соответствующее ньютоновской механике, что подтверждается значением R² в 0.999. Напротив, увеличение длины контекста до 100 шагов приводит к появлению модели, соответствующей законам Кеплера, с R² равным 0.998. Эти результаты однозначно указывают на то, что короткий контекст (2 шага) способствует обучению ньютоновской модели, в то время как более длинный контекст (100 шагов) приводит к обучению модели, основанной на кеплеровских законах, подчеркивая критическую роль длины контекста в формировании представления о динамике системы.</p> <figure> <img alt="Длина контекста определяет, какую модель мира изучает трансформер: короткие контексты приводят к ньютоновской модели, вычисляющей гравитационные силы, а длинные - к кеплеровской, вычисляющей параметры орбиты (длины большой и малой осей <span class="katex-eq" data-katex-display="false">a/b</span>, вектор Лапласа-Рунге-Ленца <span class="katex-eq" data-katex-display="false">\vec{A}</span>), при этом изменение длины контекста управляет фазовым переходом между этими моделями и влияет на точность предсказаний." src="https://arxiv.org/html/2602.06923v1/figs/two_world_models.png" style="background-color: white;"/><figcaption>Длина контекста определяет, какую модель мира изучает трансформер: короткие контексты приводят к ньютоновской модели, вычисляющей гравитационные силы, а длинные - к кеплеровской, вычисляющей параметры орбиты (длины большой и малой осей [latex]a/b, вектор Лапласа-Рунге-Ленца \vec{A}), при этом изменение длины контекста управляет фазовым переходом между этими моделями и влияет на точность предсказаний.
Исследование, представленное в статье, убедительно демонстрирует, что одного лишь увеличения масштаба модели или объема данных недостаточно для эффективного обучения базовых принципам физики, таким как механика Ньютона. Необходимо встраивать в архитектуру сети специфические априорные знания - индуктивные смещения, в частности, локальность во времени. Это напоминает о важности математической строгости и корректности, ведь алгоритм, не учитывающий фундаментальные принципы, будет давать лишь приближенные решения. Как однажды заметил Дональд Кнут: «Преждевременная оптимизация - корень всех зол». В данном контексте, стремление к масштабу без учета корректности и фундаментальных принципов обучения - подобная преждевременная оптимизация, ведущая к неэффективным моделям.
Что Дальше?
Настоящая сложность, как показывает представленная работа, заключается не в наращивании вычислительных мощностей или увеличении объемов данных, а в понимании того, как эффективно внедрять априорные знания в архитектуру моделей. Простое увеличение масштаба, без учета принципов, лежащих в основе наблюдаемых явлений, подобно попытке решить сложную задачу математики, используя лишь грубую силу перебора вариантов. Оптимизация без анализа - самообман и ловушка для неосторожного разработчика.
Будущие исследования должны быть сосредоточены на разработке методов формализации и внедрения индуктивных смещений, выходящих за рамки простой локальности во времени. Необходимо изучить, как эффективно кодировать фундаментальные принципы физики - сохранение энергии, импульса, углового момента - непосредственно в структуру нейронных сетей. Достаточно ли текущих архитектур для этого, или потребуются принципиально новые подходы?
В конечном счете, задача состоит не в создании моделей, способных "угадывать" поведение мира, а в построении систем, способных понимать его. Истинная элегантность заключается в математической чистоте и доказуемости алгоритмов, а не в их эмпирической эффективности на ограниченном наборе тестов. Следующий шаг - это переход от "черных ящиков" к прозрачным и интерпретируемым системам, способным к обоснованным выводам и прогнозам.
Оригинал статьи: https://arxiv.org/pdf/2602.06923.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Поймать Мгновение: Эволюция Детекторов Времени
- Память для разума: Архитектура коллективного интеллекта
- Оптимизация обучения нейросетей: новый подход на основе оптимального управления
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
2026-02-09 10:02