Автор: Денис Аветисян
Новый фреймворк упрощает и ускоряет процесс обучения масштабных нейронных сетей, обеспечивая эффективное распределение нагрузки и высокую производительность.
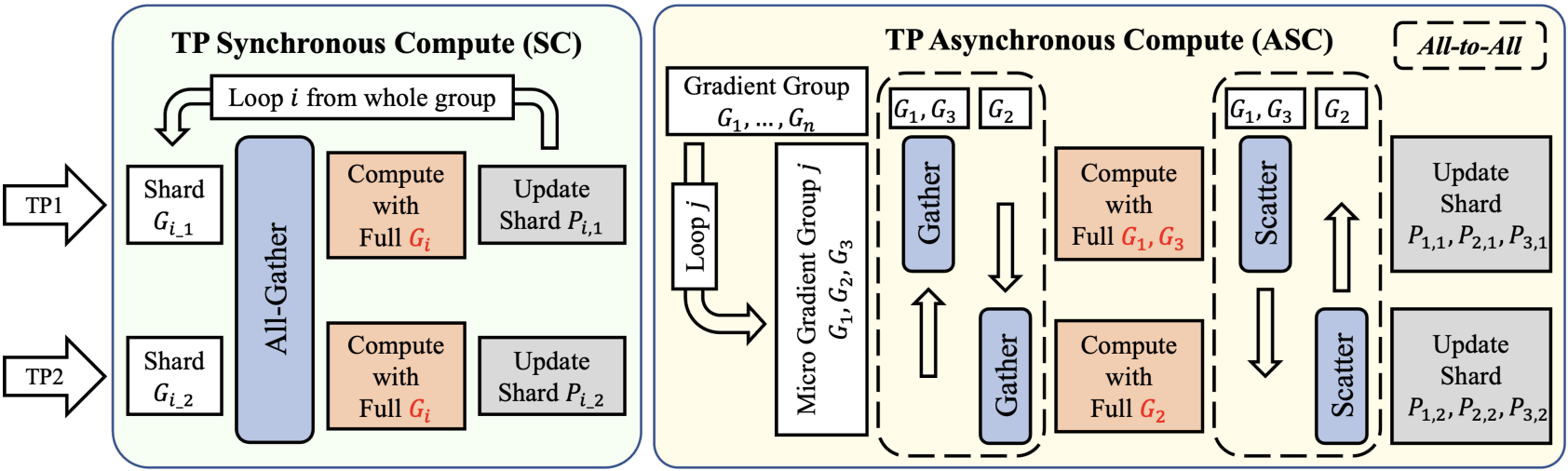
Представлена Canzona — унифицированная и асинхронная платформа для распределенных матричных оптимизаторов, решающая проблему атомарности при обучении больших языковых моделей.
Масштабирование больших языковых моделей (LLM) требует эффективных матричных оптимизаторов, однако их целостные обновления вступают в конфликт с фрагментацией тензоров в распределенных системах. В данной работе представлена система ‘Canzona: A Unified, Asynchronous, and Load-Balanced Framework for Distributed Matrix-based Optimizers’, предлагающая унифицированный, асинхронный и сбалансированный подход, отделяющий логическое назначение оптимизатора от физического распределения параметров. Предложенная стратегия alpha-сбалансированного статического разбиения и асинхронный конвейер вычислений позволяют добиться существенного снижения времени итерации и задержки шага оптимизатора, как показано на модели Qwen3 (до 32B параметров) на 256 GPU. Возможно ли дальнейшее расширение возможностей Canzona для поддержки еще более масштабных моделей и гетерогенных вычислительных сред?
Преодоление Границ Масштабирования: Вызовы Традиционных Подходов
По мере увеличения размеров больших языковых моделей (БЯМ) возникает острая необходимость в более эффективных алгоритмах обучения. Рост числа параметров требует экспоненциального увеличения объёма памяти и пропускной способности коммуникаций между вычислительными узлами. Традиционные методы, разработанные для моделей меньшего размера, сталкиваются с серьёзными ограничениями, приводящими к замедлению обучения и увеличению его стоимости. Узкие места, связанные с обменом данными и хранением промежуточных результатов, становятся критическими препятствиями на пути к созданию ещё более мощных и сложных моделей обработки естественного языка. Разработка алгоритмов, способных эффективно использовать доступные ресурсы и минимизировать эти узкие места, является ключевой задачей для дальнейшего прогресса в области искусственного интеллекта.
Матричные оптимизаторы представляют собой перспективный подход к ускорению обучения больших языковых моделей, поскольку они способны к более быстрой сходимости по сравнению с традиционными методами. Однако, их эффективность напрямую зависит от доступа к полным тензорам данных, что создает принципиальное противоречие с распределенным обучением. В процессе распределенного обучения, данные и вычисления разделяются между множеством вычислительных узлов, и каждый узел имеет доступ лишь к своей части данных. Необходимость объединения всех тензоров для применения матричного оптимизатора приводит к значительным затратам на коммуникацию и, как следствие, снижает общую эффективность масштабирования модели. Таким образом, использование матричных оптимизаторов в контексте распределенного обучения требует поиска инновационных решений, позволяющих обойти это фундаментальное ограничение и реализовать их потенциал для повышения скорости и эффективности обучения.
Ограничение, связанное с необходимостью доступа к полным тензорам при использовании матричных оптимизаторов, представляет собой серьезное препятствие для дальнейшего увеличения масштаба языковых моделей. Вместо ожидаемого ускорения обучения, данный фактор фактически тормозит прогресс в области обработки естественного языка, поскольку увеличение размера моделей и сложности их архитектуры становится всё более проблематичным. Это связано с тем, что традиционные методы распределенного обучения, необходимые для работы с огромными объемами данных и вычислений, оказываются несовместимыми с требованиями матричных оптимизаторов, что приводит к узким местам в памяти и коммуникациях. Преодоление данного ограничения является ключевой задачей для исследователей, стремящихся к созданию более мощных и эффективных языковых моделей, способных решать всё более сложные задачи.
Оптимизация Памяти: Решение ZeRO-1
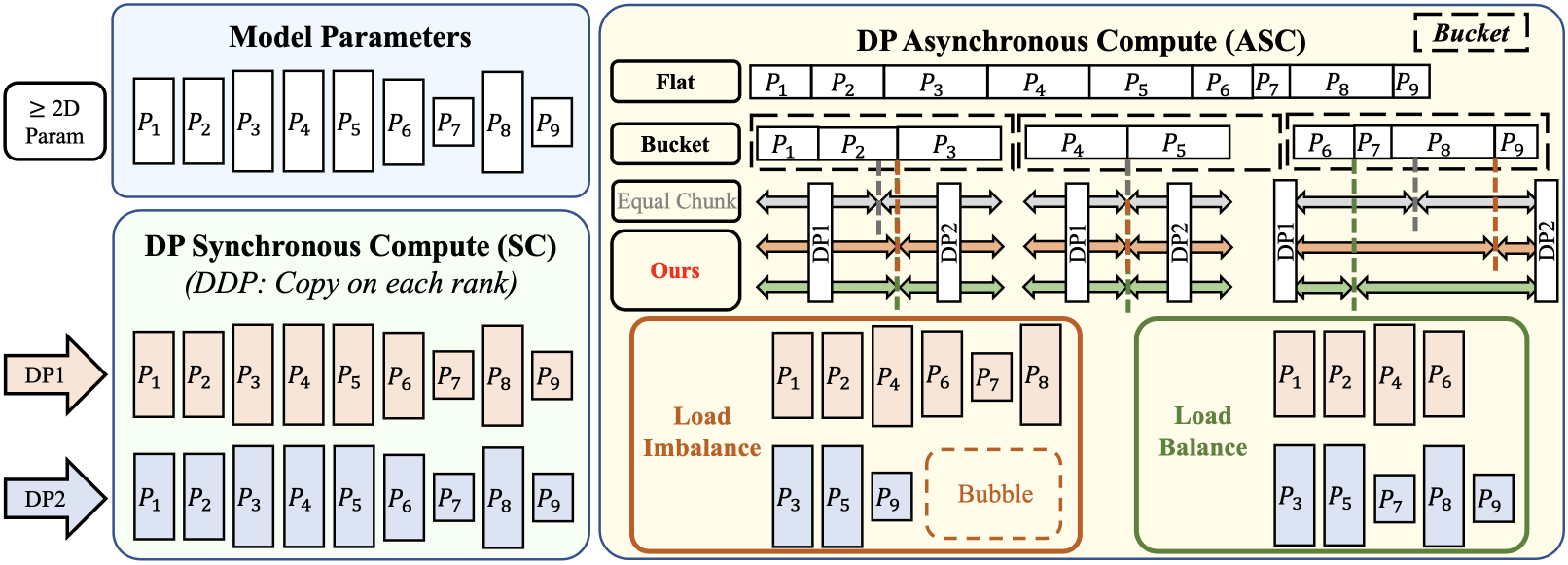
Параллелизм данных (DataParallelism) является стандартным подходом к распределенному обучению, при котором модель реплицируется на каждом устройстве, а данные разделяются между ними. Несмотря на простоту реализации, данный подход приводит к значительному потреблению памяти, поскольку каждое устройство должно хранить полную копию параметров модели, градиентов и состояний оптимизатора. Объем потребляемой памяти линейно растет с увеличением размера модели и пакета данных, что может стать ограничивающим фактором при обучении больших моделей на ограниченном оборудовании. В результате, доступная память на каждом устройстве становится узким местом, препятствующим масштабированию обучения.
ZeRO-1 (Zero Redundancy Optimizer — 1) решает проблему высокой памяти при распределенном обучении за счет разделения состояний оптимизатора между рангами, участвующими в параллелизме данных. Вместо хранения полных состояний оптимизатора на каждом устройстве, ZeRO-1 распределяет их, таким образом, уменьшая потребление памяти на каждом отдельном GPU или устройстве. Это достигается за счет разделения таких параметров, как моменты первого и второго порядка, между процессами, что позволяет обучать значительно более крупные модели, чем это было бы возможно при использовании стандартного подхода DataParallelism, где каждое устройство хранит полную копию состояний оптимизатора.
Разделение состояний оптимизатора в ZeRO-1 опирается на строгие геометрические ограничения (GeometricConstraints) для обеспечения эффективной коммуникации и корректного обновления параметров модели. Эти ограничения предписывают определенный порядок и структуру обмена данными между процессами, гарантируя, что каждый процесс имеет доступ к необходимым данным для вычисления градиентов и обновления соответствующих параметров. Несоблюдение этих ограничений может привести к неверным обновлениям и, как следствие, к нестабильности или расхождению процесса обучения. Внедрение и поддержание этих геометрических ограничений, однако, усложняет реализацию и требует точного контроля над процессом распределения данных и коммуникации между устройствами.
Canzona: Унификация и Оптимизация Распределенной Оптимизации
Canzona представляет собой унифицированную платформу, разработанную для поддержки обобщенных матричных оптимизаторов в распределенных вычислительных средах. В отличие от существующих решений, ориентированных на конкретные алгоритмы, Canzona обеспечивает гибкость в использовании различных матричных оптимизаторов, упрощая процесс адаптации и интеграции новых методов. Архитектура платформы позволяет эффективно распределять вычислительную нагрузку между несколькими устройствами, обеспечивая масштабируемость и повышение производительности при работе с большими моделями и объемами данных. Ключевой особенностью является абстракция от деталей реализации конкретных оптимизаторов, что позволяет разработчикам сосредоточиться на логике обучения, а не на тонкостях распределенной оптимизации.
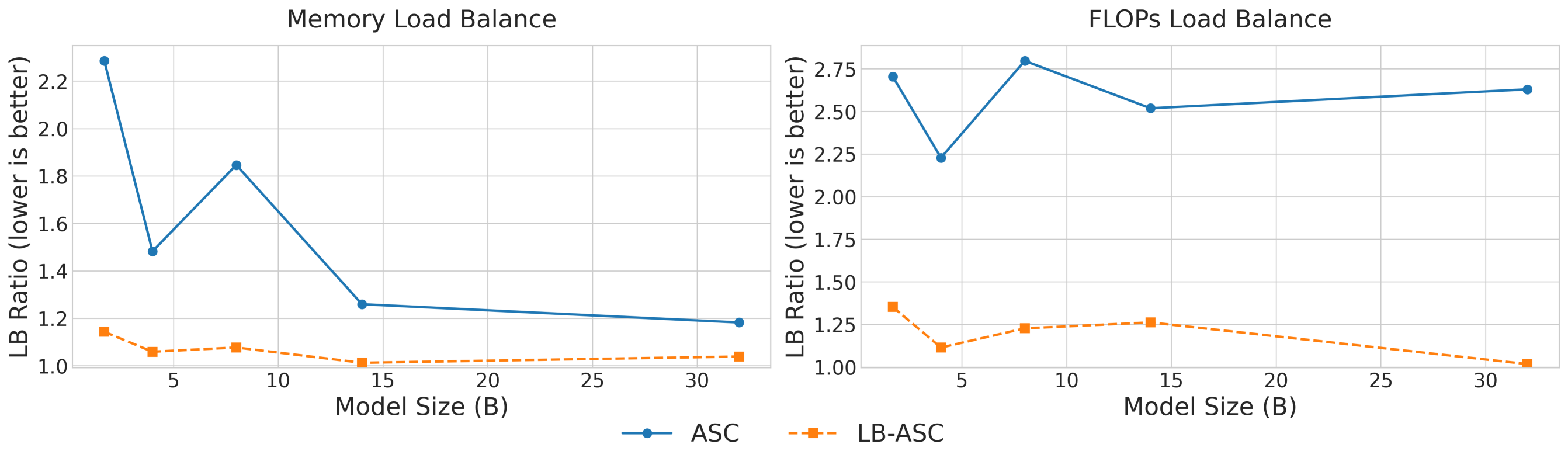
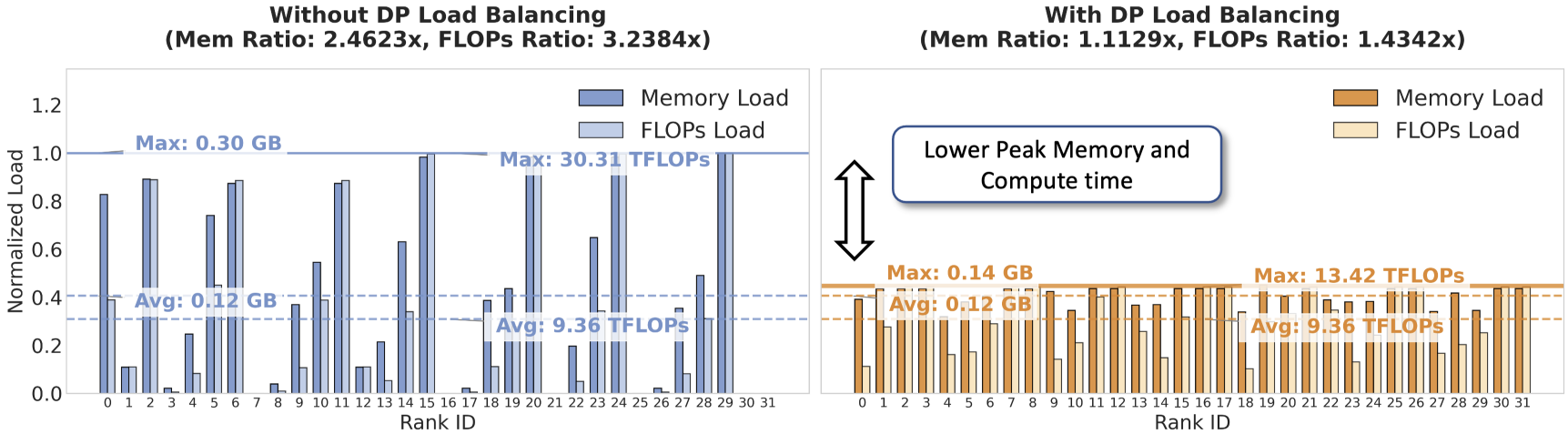
В Canzona для балансировки рабочей нагрузки используется статическое разбиение (StaticPartitioning) в сочетании с алгоритмом AlphaBalancedGreedyLPT. Данный алгоритм обеспечивает распределение задач таким образом, чтобы минимизировать разницу в объеме вычислений между отдельными процессами. В результате, достигается близкое к оптимальному распределение нагрузки, что подтверждается значением коэффициента LoadBalanceRatio, равным приблизительно 1.0. Это означает, что все процессы задействованы в вычислениях практически с одинаковой интенсивностью, что способствует повышению общей эффективности и снижению времени обучения модели.
Фреймворк Canzona использует асинхронные вычисления (AsynchronousCompute) и микрогрупповое планирование (MicroGroupScheduling) для снижения накладных расходов на связь (CommunicationOverhead) и повышения общей эффективности. В ходе экспериментов была продемонстрирована двукратная (2x) редукция объема передаваемых данных за счет сохранения геометрических ограничений, характерных для ZeRO-1. Такой подход позволяет минимизировать задержки, связанные с обменом данными между вычислительными узлами в распределенной среде, и оптимизировать производительность при работе с большими моделями.
В ходе тестирования, разработанный фреймворк Canzona продемонстрировал значительное увеличение производительности по сравнению с оптимизатором layerwise_optimizer от NVIDIA. В частности, зафиксировано ускорение времени выполнения одной итерации на 1.57x. Более того, время выполнения одного шага оптимизации снижено в 5.8 раза, что свидетельствует о повышении эффективности и скорости сходимости при использовании Canzona.
Влияние и Перспективы Развития
Методики Canzona и подобные им открывают новые возможности для эффективной тренировки оптимизаторов, работающих с большими матрицами. Это позволяет создавать модели, демонстрирующие улучшенную сходимость и обобщающую способность. Благодаря оптимизации вычислительных процессов, алгоритмы быстрее достигают оптимальных параметров, что ведет к повышению точности и надежности предсказаний. В частности, улучшенная сходимость означает, что модели требуют меньше итераций для достижения желаемого уровня производительности, а повышенная обобщающая способность позволяет им лучше адаптироваться к новым, ранее не встречавшимся данным. Таким образом, Canzona способствует созданию более эффективных и универсальных моделей машинного обучения, способных решать широкий спектр задач с высокой точностью и надежностью.
Достижения в области оптимизации матричных вычислений открывают перспективы для существенного повышения производительности в широком спектре приложений машинного обучения. В частности, обработка естественного языка получит выгоду от более точных и быстрых моделей, способных лучше понимать и генерировать текст. Компьютерное зрение сможет достичь новых высот в распознавании образов и анализе изображений, что крайне важно для таких областей, как автономное вождение и медицинская диагностика. В целом, эти усовершенствования потенциально способны революционизировать многие сферы, где машинное обучение играет ключевую роль, позволяя создавать более эффективные и интеллектуальные системы.
Перспективные исследования в области оптимизации матричных вычислений направлены на дальнейшее снижение коммуникационной нагрузки, что критически важно для масштабируемости алгоритмов. Особое внимание уделяется адаптации данных техник к гетерогенным вычислительным системам, включающим различные типы процессоров и ускорителей. Исследователи также рассматривают динамические стратегии разбиения матриц на подблоки, позволяющие оптимизировать использование памяти и пропускной способности в зависимости от текущей стадии вычислений и характеристик аппаратного обеспечения. Реализация этих направлений позволит значительно повысить эффективность обучения крупных моделей машинного обучения, открывая новые возможности в обработке естественного языка, компьютерном зрении и других областях.
Представленная работа демонстрирует стремление к упрощению сложной задачи распределенной оптимизации матричных вычислений. Авторы предлагают Canzona, систему, объединяющую различные стратегии параллелизма — как данные, так и тензоры — для достижения баланса нагрузки и эффективности коммуникации. Этот подход особенно важен в контексте обучения больших языковых моделей, где атомарность операций и масштабируемость являются критическими факторами. Как заметил Джон фон Нейманн: «В науке не бывает абсолютной истины, только приближения». Canzona — это еще одно приближение к оптимальному решению, основанное на тщательном анализе компромиссов между различными подходами к параллелизации и стремлением к минимизации избыточности вычислений. Данная работа подчеркивает важность ясности и структуры в решении сложных проблем.
Куда же дальше?
Представленная работа, стремясь к унификации и эффективности в обучении больших языковых моделей, неизбежно обнажает новые грани сложности. Попытка разрешить конфликт между атомарностью и распределённостью — это лишь один шаг на пути к истинной простоте. Очевидно, что дальнейшее углубление в оптимизацию параллелизма данных и тензоров, хотя и необходимо, не является самоцелью. Истинное совершенство кроется не в увеличении числа параметров или скорости вычислений, а в элегантности алгоритма, в его способности достигать результата с минимальными затратами.
Остается открытым вопрос о границах применимости предложенного подхода. Действительно ли унифицированная архитектура является оптимальным решением для всех типов матричных оптимизаторов, или же существуют специфические случаи, требующие индивидуального подхода? Более того, необходимо учитывать, что архитектура аппаратного обеспечения постоянно меняется. Решения, эффективные сегодня, могут оказаться устаревшими завтра. Поэтому, фундаментальным направлением исследований представляется разработка алгоритмов, устойчивых к изменениям в технологической базе.
В конечном счете, стремление к оптимизации — это бесконечный процесс. Однако, важно помнить, что красота заключается не в сложности, а в компрессии без потерь. Истинный прогресс достигается не тогда, когда добавляют новое, а когда убирают лишнее, создавая систему, в которой каждый элемент выполняет свою функцию с максимальной эффективностью. Будущие исследования должны быть направлены на поиск этой простоты.
Оригинал статьи: https://arxiv.org/pdf/2602.06079.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- БиоАгент: Проверка ИИ на прочность в мире геномики
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Командная работа агентов: обучение без обновления модели
- Квантовые Загадки и Финансовые Реалии
2026-02-09 13:16