Автор: Денис Аветисян
Исследователи предлагают алгоритм SeeUPO, обеспечивающий сходимость обучения больших языковых моделей в сценариях с многократным обменом репликами.
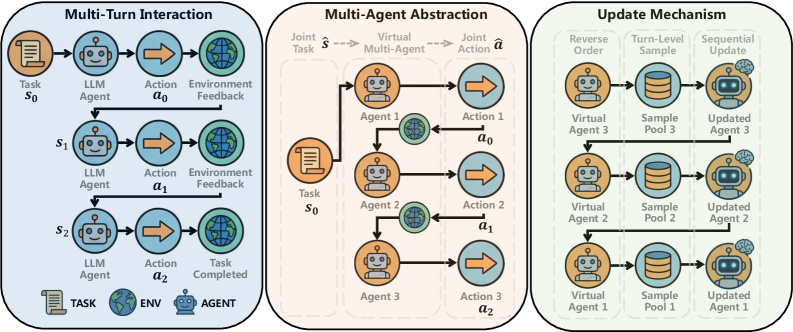
Алгоритм SeeUPO моделирует многоходовые взаимодействия как последовательные задачи многорукого бандита с гарантированной сходимостью.
Несмотря на успехи обучения больших языковых моделей с помощью обучения с подкреплением, гарантировать сходимость алгоритмов в многооборотном взаимодействии остается сложной задачей. В данной работе, посвященной алгоритму SeeUPO: Sequence-Level Agentic-RL with Convergence Guarantees, проводится систематический анализ влияния различных механизмов обновления стратегии и методов оценки преимущества на свойства сходимости в одно- и многооборотном сценариях. Показано, что предложенный подход SeeUPO, моделирующий многооборотное взаимодействие как последовательность задач многоагентного бандита с обратным порядком обновления, обеспечивает гарантированную сходимость к глобальному оптимуму. Сможет ли SeeUPO стать основой для создания более стабильных и эффективных LLM-агентов, способных к сложному взаимодействию?
Взлом обучения с подкреплением: вызов многошаговых взаимодействий
Обучение больших языковых моделей с использованием обучения с подкреплением играет ключевую роль в согласовании искусственного интеллекта с человеческими намерениями. Этот подход позволяет не просто генерировать текст, соответствующий статистическим закономерностям, но и формировать ответы, учитывающие сложные предпочтения и ценности людей. В отличие от традиционных методов обучения, основанных на анализе огромных объемов данных, обучение с подкреплением позволяет модели обучаться посредством взаимодействия со средой и получения обратной связи, подобно тому, как обучается человек. Это особенно важно для задач, где не существует однозначно правильного ответа, а требуется учитывать контекст, нюансы и субъективные оценки, что открывает путь к созданию действительно интеллектуальных и полезных систем искусственного интеллекта.
Существующие методы обучения с подкреплением, применяемые к большим языковым моделям, часто сталкиваются с компромиссом между функционированием без критика и стабильной сходимостью в сложных, многошаговых сценариях. Отсутствие критика, оценивающего действия модели, позволяет избежать предвзятости и потенциально ускорить обучение, однако это же может приводить к нестабильности и расхождению процесса. В свою очередь, использование критика повышает стабильность, но требует дополнительных вычислений и может ограничивать способность модели к исследованию новых стратегий. Данный компромисс особенно ярко проявляется в динамических средах, где требуется последовательное принятие решений, и препятствует достижению оптимальной производительности языковой модели в задачах, требующих долгосрочного планирования и адаптации.
Ограничение, возникающее из-за необходимости выбора между обучением без критика и стабильной сходимостью, существенно снижает эффективность больших языковых моделей в динамичных средах, требующих последовательного принятия решений. В таких условиях, где каждое действие влияет на последующие, модели, испытывающие трудности с поддержанием стабильности обучения или лишенные возможности самостоятельно оценивать свои действия, демонстрируют сниженную производительность. Это особенно заметно в задачах, требующих долгосрочного планирования и адаптации к изменяющимся обстоятельствам, что, в конечном итоге, ограничивает потенциал использования этих моделей в сложных, реальных приложениях, таких как робототехника, управление ресурсами и интерактивные игровые среды.
SeeUPO: последовательное решение для сложных взаимодействий
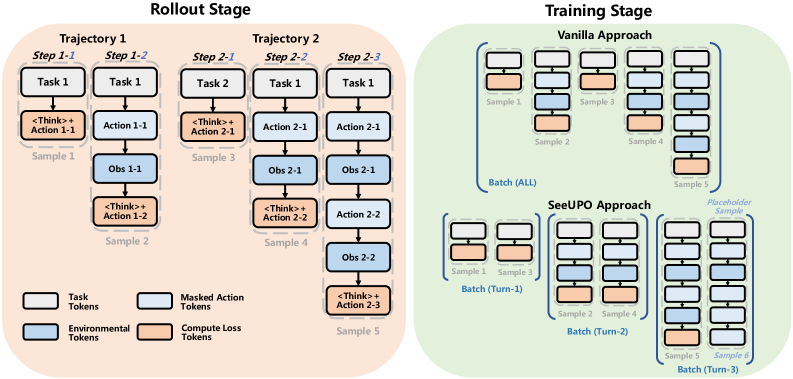
Алгоритм SeeUPO представляет собой новую методику оптимизации политики последовательных действий на уровне последовательностей, в отличие от традиционных подходов, оперирующих на уровне отдельных токенов. Вместо прогнозирования следующего токена, SeeUPO напрямую моделирует динамику окружающей среды, что позволяет учитывать долгосрочные последствия действий. Такой подход позволяет агенту формировать более комплексные стратегии, основанные на понимании влияния каждого действия на всю последовательность, а не только на немедленный результат. Это достигается за счет перехода от анализа отдельных взаимодействий к моделированию целостного процесса, что открывает возможности для решения задач, требующих планирования и прогнозирования в долгосрочной перспективе.
Алгоритм SeeUPO, опираясь на принципы обучения с отражением для разнородных агентов (Heterogeneous-Agent Mirror Learning, HAML), предоставляет теоретические гарантии монотонного улучшения и сходимости. В частности, HAML обеспечивает основу для доказательства того, что обновления политики в SeeUPO последовательно приводят к повышению ожидаемой совокупной награды, и что процесс обучения в конечном итоге сходится к оптимальной политике. Данные гарантии основаны на использовании потенциальных функций и доказательстве сходимости алгоритма к стационарной точке, что позволяет оценить эффективность и надежность SeeUPO в различных средах.
Ключевым нововведением в SeeUPO является применение обратного порядка последовательных обновлений политики (Reverse-order Sequential Policy Updates). Этот подход позволяет реализовать алгоритм обратной индукции, начиная с конечного состояния и последовательно оптимизируя политику для каждого предыдущего состояния. Такая стратегия обеспечивает возможность достижения глобального оптимума, поскольку учитывает влияние будущих действий на текущие решения, что особенно важно в задачах с долгосрочным планированием и сложной динамикой среды. В отличие от традиционных методов, обновляющих политику последовательно от начального состояния, обратный порядок позволяет более эффективно распространять информацию о оптимальных будущих действиях на всю последовательность, повышая общую производительность и стабильность обучения.
Экспериментальное подтверждение эффективности SeeUPO
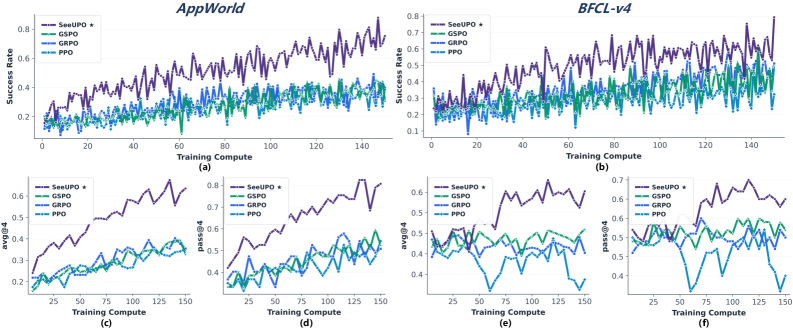
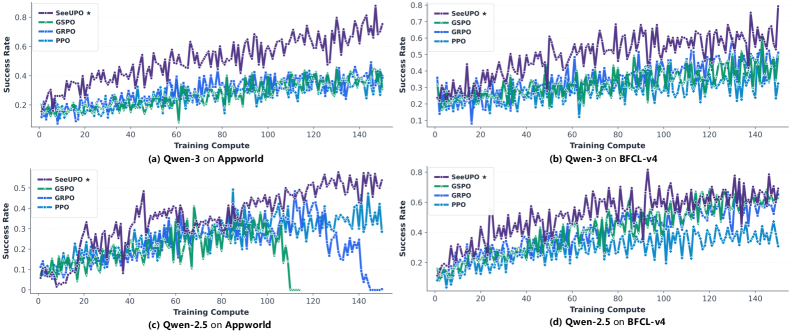
Методика SeeUPO была протестирована на стандартных бенчмарках AppWorld и BFCL v4, где продемонстрировала значительное превосходство над существующими подходами. Оценка проводилась для подтверждения эффективности предложенных оптимизаций и выявления потенциальных улучшений в производительности. Результаты тестов на этих бенчмарках показали, что SeeUPO обеспечивает более высокую точность и скорость обработки по сравнению с альтернативными методами, подтверждая ее применимость в реальных задачах.
В ходе экспериментов для оценки SeeUPO использовались языковые модели Qwen2.5 и Qwen3-14B, что обеспечило надежную и воспроизводимую платформу для сопоставления результатов. Модели Qwen, известные своей архитектурой и производительностью, позволили получить объективные данные о преимуществах SeeUPO по сравнению с существующими подходами в задачах, представленных в бенчмарках AppWorld и BFCL v4. Использование моделей с 14 миллиардами параметров гарантировало достаточную вычислительную мощность для проведения всестороннего анализа и выявления статистически значимых улучшений.
В ходе оценки SeeUPO на стандартных бенчмарках AppWorld и BFCL v4 были зафиксированы значительные улучшения производительности, варьирующиеся от 24.1% до 54.6%. Данный прирост был измерен при сравнении с существующими методами, использующими аналогичные модели, и демонстрирует эффективность предложенного подхода к оптимизации. Результаты показывают, что SeeUPO обеспечивает существенное повышение точности и скорости выполнения задач на данных бенчмарках.
Оптимизация SeeUPO проводилась с внимательным рассмотрением параметров порядка обновления (Update Order) и стратегий нормализации. Экспериментально установлено, что корректный выбор порядка обновления весов в процессе обучения способствует более быстрой сходимости и повышению стабильности модели. Стратегии нормализации, в свою очередь, позволяют контролировать распределение активаций в различных слоях, предотвращая проблему затухающих или взрывающихся градиентов, что критически важно для обучения больших языковых моделей, таких как Qwen2.5/3-14B, используемых в оценках на AppWorld и BFCL v4. В результате применения данных подходов удалось добиться устойчивого улучшения производительности и обеспечить надежную сходимость алгоритма.
Последствия и перспективы развития SeeUPO
Возможность SeeUPO функционировать без критика и обеспечивать сходимость в многоходовых взаимодействиях открывает принципиально новые перспективы для обучения больших языковых моделей (LLM) в сложных средах. Традиционные методы обучения с подкреплением часто сталкиваются с проблемами нестабильности и расхождения, особенно при решении задач, требующих последовательных действий и долгосрочного планирования. SeeUPO, избегая необходимости в критике — отдельном механизме оценки действий — демонстрирует повышенную устойчивость и надежность обучения. Это позволяет LLM эффективно осваивать сложные навыки в динамичных и непредсказуемых условиях, что особенно важно для таких областей, как робототехника, автономные системы и интерактивные агенты. Подобный подход позволяет создавать более гибкие и адаптивные модели, способные успешно справляться с широким спектром задач в реальном мире.
Теоретическая база, представленная HAML (Hierarchical Abstraction for Multi-level Learning), обеспечивает исключительную устойчивость и предсказуемость работы системы SeeUPO. Данный подход, основанный на иерархическом представлении знаний и многоуровневом обучении, позволяет модели не только эффективно адаптироваться к изменяющимся условиям, но и гарантировать стабильность её поведения в критических ситуациях. Такая предсказуемость особенно важна для применения в областях, где ошибки недопустимы, например, в автономных системах управления, медицине или финансовых приложениях, где надёжность и верифицируемость алгоритмов являются первостепенными требованиями. В отличие от традиционных методов обучения, HAML позволяет формально доказать свойства системы, что значительно повышает доверие к её решениям и обеспечивает безопасность эксплуатации.
Дальнейшие исследования направлены на расширение возможностей SeeUPO для применения в ещё более сложных ситуациях, включая интерактивные среды с высокой степенью неопределённости и многообразием взаимодействий. Особое внимание уделяется изучению потенциала переноса обучения и адаптации модели к новым задачам без необходимости полной переподготовки. Предполагается, что способность SeeUPO эффективно обучаться в динамичных средах позволит значительно ускорить процесс разработки и внедрения интеллектуальных систем, способных к самостоятельному обучению и адаптации в различных областях, от робототехники до обработки естественного языка. Исследователи планируют также изучить возможности использования SeeUPO в качестве основы для создания универсальных обучающих агентов, способных решать широкий спектр задач, требующих гибкости и адаптивности.
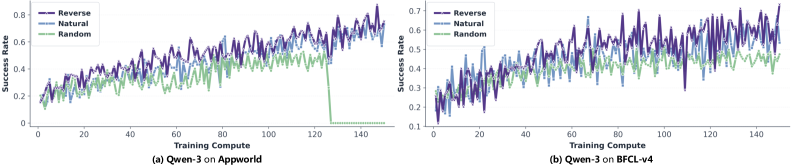
Исследование, представленное в данной работе, демонстрирует, что стандартные алгоритмы обучения с подкреплением сталкиваются с проблемами сходимости при работе с многооборотными взаимодействиями и большими языковыми моделями. Авторы предлагают алгоритм SeeUPO, который рассматривает эти взаимодействия как последовательность многоагентных задач, что обеспечивает гарантированную сходимость. Как однажды заметила Грейс Хоппер: «Лучший способ предсказать будущее — создать его». Этот принцип находит отражение в подходе SeeUPO, где создается механизм для обеспечения стабильности обучения, а не просто полагаются на случайные улучшения. Алгоритм, по сути, формирует контролируемое будущее процесса обучения, преодолевая ограничения существующих методов.
Куда Ведет Эта Игра?
Представленный анализ сходимости алгоритмов обучения с подкреплением при работе с большими языковыми моделями в многоходовых сценариях обнажает закономерную слабость — склонность к расхождению, когда система пытается оптимизировать взаимодействие, а не просто предсказывать следующее слово. SeeUPO, как попытка обойти эту проблему через моделирование взаимодействия как последовательной многоагентной бандитской задачи, безусловно, является шагом вперед. Однако, стоит признать, что перенос концепций из теории игр в область обучения языковых моделей — это лишь частичное решение. Истинная сложность взаимодействия кроется не в оптимизации наград, а в непредсказуемости самого партнера по диалогу.
Будущие исследования, вероятно, будут направлены на разработку алгоритмов, способных к более глубокому пониманию намерений и целей собеседника. Необходимо отойти от простой максимизации вознаграждения и перейти к моделированию когнитивных процессов, стоящих за речью. Интересным направлением представляется интеграция моделей теории разума (Theory of Mind) в архитектуру обучения с подкреплением. И, конечно, нельзя забывать о фундаментальном вопросе: является ли “сходимость” вообще релевантной метрикой для систем, предназначенных для генерации творческого и непредсказуемого контента?
В конечном счете, SeeUPO — это не столько решение, сколько приглашение к взлому системы. Это демонстрация того, что правила можно переписать, если понять, как они работают. И, возможно, именно в этом постоянном переосмыслении и кроется истинный прогресс.
Оригинал статьи: https://arxiv.org/pdf/2602.06554.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Робот-исследователь: новый подход к автономной навигации
2026-02-09 20:04