Автор: Денис Аветисян
Новый фреймворк автоматизирует анализ данных экспериментов на коллайдерах, делая сложные вычисления доступнее для ученых.
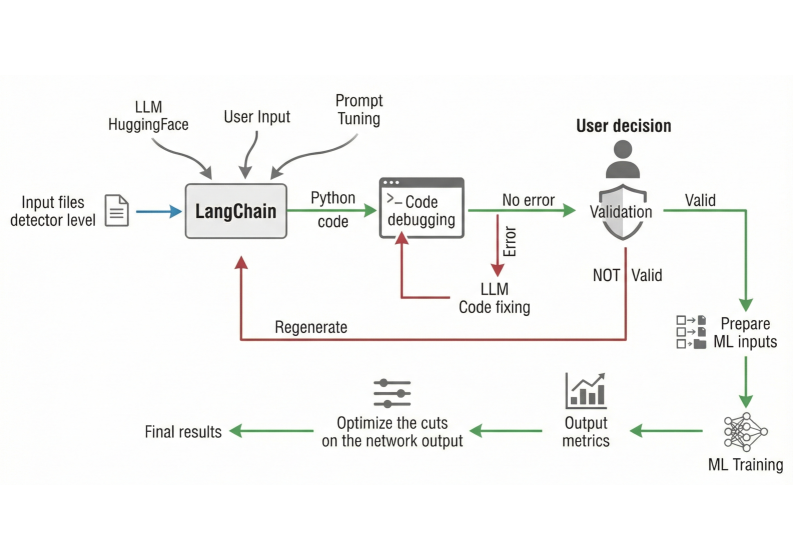
CoLLM: инструмент для создания сквозных пайплайнов глубокого обучения в анализе данных коллайдеров, использующий большие языковые модели.
С ростом сложности анализов данных, получаемых на коллайдерах, возрастает и потребность в специализированных навыках программирования и машинного обучения. В данной работе представлена система ‘CoLLM: AI engineering toolbox for end-to-end deep learning in collider analyses’, предназначенная для автоматизации полного цикла анализа данных, от отбора событий до применения методов глубокого обучения. CoLLM использует предварительно обученные большие языковые модели для генерации физически корректного кода анализа и обеспечивает удобный графический интерфейс, снижая зависимость от экспертных знаний. Сможет ли подобный подход значительно ускорить темпы научных открытий в физике высоких энергий и сделать анализ данных более доступным для широкого круга исследователей?
Вызов анализа данных в физике высоких энергий
Анализ данных, получаемых в ходе экспериментов на коллайдерах, представляет собой значительную вычислительную задачу, требующую высокой квалификации специалистов. Объемы генерируемой информации огромны, а сложность процессов, происходящих при столкновении частиц, требует применения передовых алгоритмов и специализированного программного обеспечения. Обработка этих данных не ограничивается простой статистической обработкой; необходим глубокий анализ для выделения редких событий и проверки предсказаний теоретической физики. Для этого требуется не только мощная вычислительная инфраструктура, но и экспертное знание в области физики частиц, программирования и статистического анализа, что делает данную область исследований особенно требовательной к кадровому потенциалу и ресурсам.
Традиционные методы анализа данных, получаемых в ходе экспериментов на ускорителях, исторически опирались на ручное написание программного кода. Этот подход, хотя и позволял достичь определенных результатов, оказался чрезвычайно трудоемким и подверженным ошибкам. Разработка и отладка специализированного программного обеспечения требовала значительных временных затрат и высокой квалификации специалистов. Вероятность внесения ошибок в код, особенно при работе с огромными объемами данных, была весьма велика, что приводило к необходимости повторных проверок и исправлений. Более того, ручное кодирование затрудняло масштабирование анализа и адаптацию к новым экспериментальным условиям, что делало его узким местом в процессе исследования физики высоких энергий.
Объемы данных, генерируемые современными коллайдерами, достигают астрономических величин, а их сложность требует применения автоматизированных методов анализа. Ручная обработка и анализ таких объемов попросту невозможны в разумные сроки, а также подвержены человеческим ошибкам. Автоматизация позволяет не только существенно ускорить процесс извлечения научной информации, но и повысить надежность результатов. Разрабатываемые алгоритмы и программные комплексы способны автоматически идентифицировать интересующие физики события, отфильтровывать шум и проводить статистический анализ, освобождая ученых от рутинных задач и позволяя им сосредоточиться на интерпретации полученных данных и формулировке новых гипотез. p = \frac{N}{V} — пример автоматизированного расчета, который ранее требовал значительных усилий.
CoLLM: Автоматизация анализа с помощью языковых моделей
Фреймворк CoLLM обеспечивает автоматизацию процесса анализа данных посредством связи между запросами, сформулированными на естественном языке, и автоматизированными конвейерами глубокого обучения. Это достигается путем преобразования текстовых инструкций в последовательность операций, необходимых для выполнения анализа, что значительно упрощает и ускоряет процесс по сравнению с ручным кодированием. Вместо непосредственного написания кода, пользователи могут описывать желаемый анализ на обычном языке, а CoLLM автоматически генерирует и запускает соответствующий код для обработки данных и получения результатов. Данный подход позволяет существенно сократить время, затрачиваемое на подготовку и запуск аналитических задач, и снизить вероятность ошибок, связанных с ручным кодированием.
В основе CoLLM лежит генерация исполняемого кода с использованием больших языковых моделей (LLM) для автоматизации анализа данных. Пользовательские запросы на анализ, сформулированные на естественном языке, преобразуются LLM в код, например, на Python, который затем может быть выполнен для обработки данных. Этот подход значительно сокращает объем ручного кодирования, необходимого для проведения анализа, позволяя исследователям и аналитикам сосредоточиться на интерпретации результатов, а не на написании кода. Автоматизация процесса кодирования повышает эффективность и снижает вероятность ошибок, связанных с ручным вводом и отладкой.
Детерминированное декодирование в CoLLM обеспечивает согласованную генерацию кода и, как следствие, воспроизводимость результатов анализа. В отличие от вероятностных методов декодирования, которые могут выдавать различные результаты при каждом запуске для одного и того же запроса, детерминированное декодирование гарантирует, что для идентичного входного запроса всегда будет генерироваться один и тот же код. Это достигается за счет строгого контроля над процессом генерации, исключающего случайные элементы. Оценка производительности CoLLM продемонстрировала высокую степень воспроизводимости, что критически важно для научных исследований и надежных аналитических приложений, требующих верификации и повторного использования результатов.
Проверка и уточнение автоматизированного конвейера
Автоматизированный конвейер включает в себя модуль PyFixer для выявления и исправления потенциальных ошибок в сгенерированном коде. PyFixer анализирует синтаксис и семантику кода, автоматически исправляя распространенные ошибки, такие как опечатки, неправильное использование операторов и несоответствия типов. Этот процесс позволяет повысить надежность и стабильность генерируемого кода, снижая необходимость ручной отладки и проверки. Модуль PyFixer интегрирован непосредственно в конвейер, что обеспечивает автоматическое исправление ошибок на этапе генерации кода.
Для верификации корректности результатов анализа используются графики валидации и таблицы cutflow. Графики валидации визуально отображают соответствие между предсказанными и наблюдаемыми значениями, позволяя оценить качество модели и выявить потенциальные отклонения. Таблицы cutflow, в свою очередь, представляют собой детализированную статистику процесса отбора событий, показывающую количество событий, прошедших через каждый этап анализа. Анализ данных в таблицах cutflow позволяет проверить, что отбор событий происходит в соответствии с ожидаемой логикой и что не происходит нежелательных потерь или искажений данных. Совместное использование графиков валидации и таблиц cutflow обеспечивает комплексную проверку корректности результатов анализа и выявление потенциальных ошибок или несоответствий.
Автоматизированный конвейер глубокого обучения использует несколько моделей классификации, включая MLP Classifier, GNN Classifier и Transformer Classifier, для обеспечения устойчивой производительности и высокой точности анализа. Успешная генерация исполняемого кода CoLLM для пяти эталонных анализов демонстрирует полную автоматизацию рабочего процесса, включая этапы от генерации кода до его выполнения и получения результатов. Данный подход позволяет автоматизировать рутинные задачи и ускорить процесс анализа данных, повышая общую эффективность исследований.
Влияние и перспективы развития
Разработанная система CoLLM значительно упрощает процесс анализа данных в физике высоких энергий, позволяя исследователям перенести акцент с рутинного программирования на саму научную задачу. Вместо того чтобы тратить время на написание и отладку кода для обработки огромных объемов информации, физики могут использовать CoLLM для автоматизации этих этапов. Это достигается за счет использования больших языковых моделей, которые способны понимать запросы на естественном языке и преобразовывать их в конкретные аналитические действия. Такой подход не только экономит драгоценное время, но и снижает вероятность ошибок, связанных с ручным кодированием, открывая новые возможности для более глубокого и эффективного исследования фундаментальных законов природы.
Архитектура разработанного фреймворка отличается высокой модульностью, что позволяет исследователям легко интегрировать новые модели и методы анализа без необходимости полной переработки существующего кода. Такой подход значительно ускоряет процесс адаптации к быстро меняющемуся ландшафту физики высоких энергий и позволяет оперативно включать последние достижения в области машинного обучения и статистического анализа. Модульная структура не только упрощает добавление новых инструментов, но и способствует более эффективной совместной работе, позволяя различным исследовательским группам разрабатывать и внедрять собственные модули, расширяя функциональность фреймворка и способствуя обмену знаниями и опытом. Это создает гибкую и масштабируемую платформу, способную адаптироваться к широкому спектру задач анализа данных и поддерживать будущие инновации в области физики.
Предстоящие исследования направлены на существенное расширение базы знаний системы, что позволит ей самостоятельно охватывать более широкий спектр физических задач. В перспективе планируется полная автоматизация цикла анализа данных — от оценки их качества и выявления аномалий до интерпретации полученных результатов и формирования научных выводов. Это не просто ускорит процесс исследований, но и откроет возможности для анализа огромных массивов данных, которые ранее были недоступны из-за трудоемкости ручной обработки. Разработчики стремятся к созданию интеллектуального инструмента, способного не только выполнять рутинные операции, но и активно участвовать в процессе научного открытия, предлагая новые гипотезы и направления для исследований.
Представленная работа демонстрирует стремление автоматизировать сложные процессы анализа данных в физике высоких энергий, что, по сути, является попыткой минимизировать влияние человеческого фактора и систематических ошибок. Этот подход перекликается с философскими взглядами Дэвида Юма, который утверждал: “Разум есть склонность к определению, а не к открытию”. CoLLM, создавая автоматизированные пайплайны глубокого обучения, как бы признает ограниченность рационального анализа в контексте огромных объемов данных. Система не просто обрабатывает информацию, но и структурирует её, предлагая исследователям готовые решения, основанные на заранее определенных алгоритмах. В конечном счете, всё поведение — это просто баланс между страхом ошибочных выводов и надеждой на получение значимых результатов, и CoLLM, автоматизируя процесс, пытается сместить этот баланс в пользу надежды.
Что дальше?
Представленный фреймворк CoLLM, автоматизирующий анализ данных в коллайдерных экспериментах, — это не триумф инженерной мысли, а лишь констатация неизбежного. Человек — не идеальный аналитик, а биологический алгоритм, склонный к систематическим ошибкам. Вместо того чтобы строить сложные модели, лучше научить машину распознавать паттерны в хаосе, и CoLLM — это шаг в этом направлении. Однако, автоматизация — это не панацея. Вопрос не в том, чтобы заменить физика-аналитика, а в том, чтобы освободить его от рутины, позволив сосредоточиться на формулировке вопросов, а не на манипуляциях с Excel-таблицами.
Очевидным ограничением является зависимость от качества обучающих данных. Большие языковые модели не создают знания, они лишь переупаковывают существующие. Поэтому, ключевой задачей видится разработка методов, позволяющих моделям выходить за рамки заученных паттернов и генерировать действительно новые гипотезы. Или, что вероятнее, более эффективно обнаруживать старые, пропущенные из-за когнитивных искажений.
В перспективе, фреймворки вроде CoLLM, вероятно, станут неотъемлемой частью анализа данных в физике высоких энергий. Но не стоит забывать: экономика — это всего лишь психология с графиками, а любой алгоритм — это отражение предубеждений тех, кто его создал. Задача — не построить идеальный инструмент, а осознать его ограничения и научиться с ними жить.
Оригинал статьи: https://arxiv.org/pdf/2602.06496.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
2026-02-09 20:06