Автор: Денис Аветисян
Новое исследование показывает, что успех гибридных методов, использующих нейросети для решения дифференциальных уравнений, зависит не столько от архитектуры сети, сколько от стратегии обучения и выбора парадигмы.
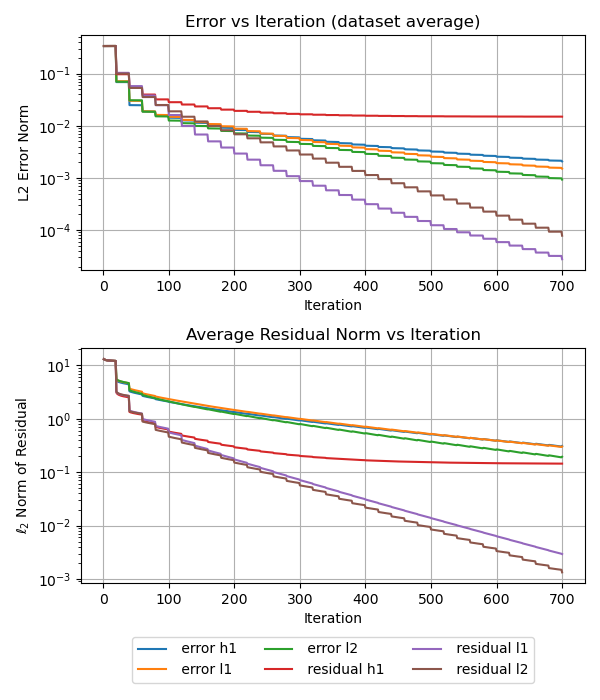
Эффективность и сходимость гибридных итерационных методов для решения уравнений в частных производных критически зависят от используемых парадигм обучения и стратегий обновления, а физически обоснованное ускорение Андерсона может помочь преодолеть застой сходимости.
Несмотря на многообещающие перспективы, гибридные итерационные методы, основанные на глубоком обучении для решения уравнений в частных производных, часто сталкиваются с проблемой ложных фиксированных точек и отсутствием сходимости. В настоящей работе, озаглавленной ‘Are Deep Learning Based Hybrid PDE Solvers Reliable? Why Training Paradigms and Update Strategies Matter’, показано, что производительность таких методов критически зависит не только от архитектуры нейронной сети, но и от парадигмы обучения и стратегии обновления. Ключевым результатом является демонстрация того, что физически обоснованная акселерация Андерсона (PA-AA) восстанавливает надежную сходимость, минимизируя физический остаток, а не обновление фиксированной точки. Могут ли новые подходы к обучению и итерациям обеспечить надежность и широкое применение AI-решений в научных вычислениях и моделировании?
Пределы Классических Итерационных Методов
Решение частных дифференциальных уравнений (ЧДУ) играет фундаментальную роль в различных областях науки и техники, начиная от моделирования потоков жидкости и тепла и заканчивая расчетами в ядерной физике и геофизике. Часто для нахождения приближенных решений таких уравнений используются итеративные методы, такие как стационарные подходы. Эти методы, основанные на последовательном уточнении начального приближения, позволяют решать ЧДУ, для которых не существует аналитических решений. Эффективность итеративных методов напрямую зависит от выбора схемы дискретизации и свойств решаемого уравнения, что делает их важным инструментом в арсенале инженера и ученого. Несмотря на свою широкую применимость, классические итеративные подходы могут сталкиваться с ограничениями, особенно при решении сложных задач с нерегулярной геометрией, что стимулирует поиск более эффективных и устойчивых численных методов.
Традиционные итерационные методы решения дифференциальных уравнений в частных производных, несмотря на свою историческую значимость и широкое применение, часто сталкиваются с проблемой медленной сходимости при анализе сложных задач. Особенно остро эта проблема проявляется при моделировании процессов в областях со сложной геометрией, где стандартные численные схемы требуют огромного количества итераций для достижения приемлемой точности. Это связано с тем, что для таких задач скорость уменьшения ошибки на каждой итерации значительно снижается, требуя экспоненциального увеличения вычислительных ресурсов. В результате, решение задач, имеющих практическую значимость в инженерии и науке, может оказаться непосильным для доступных вычислительных мощностей, что стимулирует поиск более эффективных алгоритмов и подходов к решению подобных уравнений.
Скорость сходимости итеративных методов решения дифференциальных уравнений в частных производных напрямую определяется спектральными свойствами оператора распространения ошибки. Этот оператор, по сути, описывает, как ошибка изменяется от одной итерации к другой, и его собственные значения и собственные векторы определяют, насколько быстро ошибка уменьшается или, наоборот, сохраняется. В частности, если спектр оператора содержит собственные значения, близкие к единице по модулю, это приводит к медленной сходимости, поскольку ошибка лишь незначительно уменьшается на каждой итерации. Классические итеративные подходы, такие как метод Гаусса-Зейделя или метод последовательной верхней релаксации, ограничены в своей способности эффективно уменьшать ошибку, если спектр оператора распространения ошибки неблагоприятен. Это означает, что для некоторых задач, особенно с высокой размерностью или сложной геометрией, даже самые оптимизированные классические методы могут потребовать непомерно большого количества итераций для достижения приемлемой точности, что подчеркивает необходимость разработки новых, более эффективных алгоритмов.
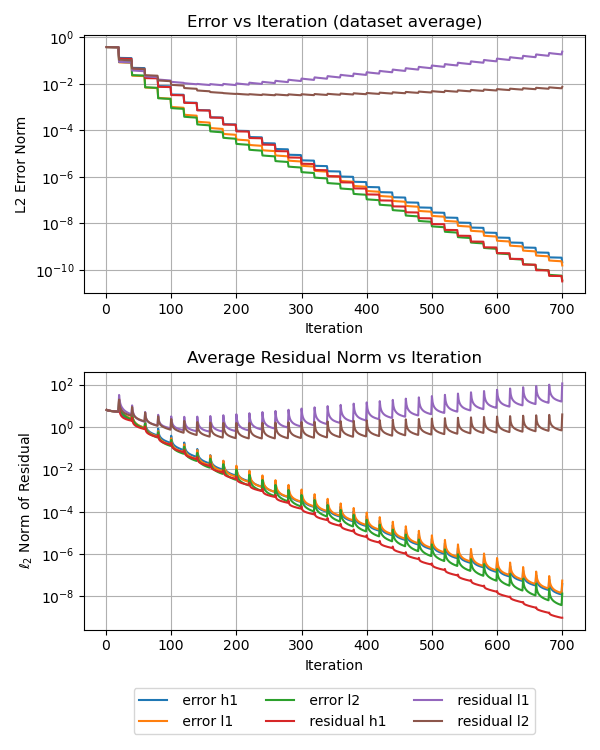
Глубокое Обучение и Гибридные Итерационные Методы: Новый Подход
Гибридные итеративные методы, основанные на глубоком обучении (DL-HIM), представляют собой перспективное направление в решении уравнений в частных производных (УЧП). Они сочетают в себе классические алгоритмы сглаживания, такие как метод Гаусса-Зейделя или последовательная чрезмерная релаксация, с нейронными операторами, такими как DeepONet или Fourier Neural Operator. В данной архитектуре нейронный оператор функционирует как обучаемый предобуславливатель, ускоряя сходимость итерационного процесса за счет адаптации к специфике решаемой УЧП. Это позволяет значительно сократить вычислительные затраты по сравнению с традиционными итерационными методами, особенно при решении сложных многомерных задач.
Интеграция методов глубокого обучения в итерационные схемы (DL-HIM) позволяет изучать сложные нелинейные отображения между пространством функций и решением уравнения в частных производных, что недоступно для традиционных итерационных методов. В отличие от классических подходов, полагающихся на заранее определенные операторы и предположения о гладкости решения, DL-HIM способны аппроксимировать сложные зависимости, возникающие в задачах с высокой размерностью или сложной геометрией. Это приводит к улучшению скорости сходимости и уменьшению количества итераций, необходимых для достижения заданной точности, особенно в случаях, когда традиционные итерационные методы сталкиваются с проблемами сходимости или требуют значительных вычислительных ресурсов. Эффективность DL-HIM обусловлена способностью нейронных сетей к автоматическому извлечению признаков и построению эффективных нелинейных моделей, что позволяет преодолеть ограничения, присущие классическим методам решения PDE.
Методы, такие как DeepONets и Fourier Neural Operators, функционируют как обучаемые предварительные решатели (прекондиционеры) в итеративных алгоритмах решения дифференциальных уравнений в частных производных. В отличие от традиционных, статичных прекондиционеров, эти методы используют нейронные сети для аппроксимации обратного оператора, что позволяет адаптироваться к специфике решаемой задачи. В процессе итерации, обученная нейронная сеть применяется к текущему решению, улучшая его сходимость и снижая число необходимых итераций для достижения заданной точности. Использование DeepONets и Fourier Neural Operators особенно эффективно при решении задач, где стандартные прекондиционеры демонстрируют низкую эффективность или приводят к замедлению сходимости, устраняя тем самым «узкие места» в итеративном процессе.
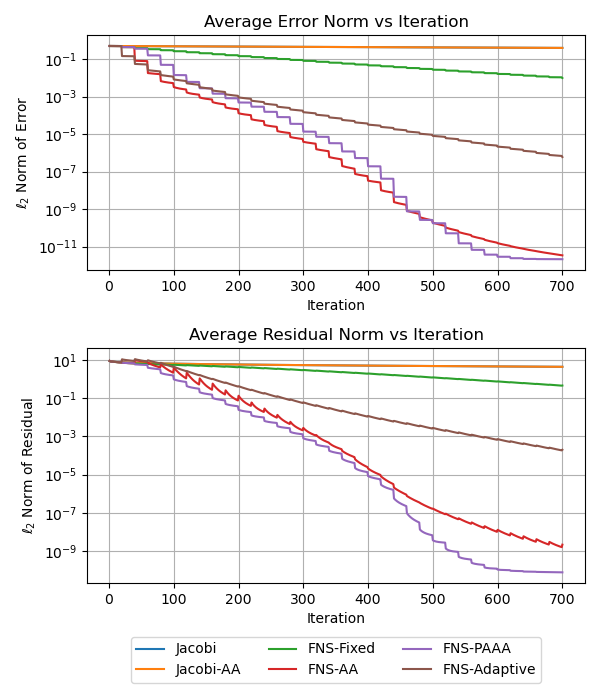
Стратегии Обучения для Надежной Работы DL-HIM
Существуют два основных подхода к обучению моделей: статический и динамический. Статическое обучение использует предварительно вычисленные наборы данных для оптимизации параметров модели. Динамическое обучение, в отличие от него, разворачивает несколько итераций решателя (solver) в процессе обучения, что позволяет модели адаптироваться в процессе оптимизации. По сути, динамический подход позволяет обучать модель непосредственно в цикле решения задачи, в то время как статический подход основывается на данных, полученных при решении задачи заранее.
Статический подход к обучению использует функции потерь, такие как функции, основанные на ошибке (error-based losses) и остаточной ошибке (residual-based losses), для минимизации расхождений между предсказанными и истинными решениями. Функции потерь, основанные на ошибке, напрямую измеряют разницу между предсказанием и целевым значением, в то время как остаточные функции потерь оценивают разницу между предсказанным решением и решением, полученным итеративным решателем. Минимизация этих функций потерь посредством градиентного спуска позволяет модели корректировать свои параметры и приближаться к оптимальному решению, уменьшая ошибки предсказания и повышая точность.
Динамическое обучение, в отличие от статического, предоставляет возможность адаптивного обучения и повышения устойчивости модели, однако требует тщательного анализа вычислительных затрат и стабильности процесса. В рамках динамического обучения происходит развертка нескольких итераций решателя в процессе обучения, что позволяет модели корректировать свои параметры на основе промежуточных результатов. Несмотря на потенциальные преимущества, увеличение числа итераций (например, K=5) приводит к значительному росту времени обучения (в 8.63 раза) и потребления памяти (в 1.27 раза), при этом не гарантируя улучшения сходимости. Поэтому при реализации динамического обучения необходимо учитывать баланс между потенциальным улучшением производительности и ресурсоемкостью, а также применять методы регуляризации для обеспечения стабильности и предотвращения ложных фиксированных точек.
При динамическом обучении с K=5 наблюдается увеличение времени обучения в 8.63 раза и потребления памяти в 1.27 раза по сравнению со статическим обучением. Однако, несмотря на возросшие вычислительные затраты, это не гарантирует улучшения сходимости алгоритма. Экспериментальные данные показывают, что увеличение вычислительных ресурсов не всегда приводит к более эффективной оптимизации и достижению желаемой точности модели, что требует тщательного анализа и оптимизации параметров обучения.
В процессе обучения моделей DL-HIM часто возникает проблема “ложной неподвижной точки”, когда градиенты и обновления параметров стремятся к нулю, несмотря на наличие значительного остатка между предсказанным и целевым решением. Данное явление препятствует сходимости алгоритма оптимизации. Для преодоления этой проблемы необходимо применять методы регуляризации, предотвращающие чрезмерное уменьшение величины градиентов, а также тщательно подбирать веса в функции потерь, уделяя больше внимания компонентам, связанным с большим остатком. Некорректный выбор весов может привести к игнорированию значимых остатков и, как следствие, к застреванию в локальном минимуме или к замедлению сходимости.
Валидация и Широкое Применение DL-HIM
Исследования показали, что DL-HIMs (Deep Learning-based Hierarchical Iterative Methods) значительно превосходят традиционные методы при решении широкого спектра дифференциальных уравнений в частных производных (ДУЧП). В частности, отмечено существенное ускорение сходимости при решении таких сложных задач, как уравнение Гельмгольца с неопределенными граничными условиями и стохастическое диффузионное уравнение. Это достигается за счет комбинирования глубокого обучения с итеративными подходами, что позволяет DL-HIMs эффективно обрабатывать сложные физические явления и обеспечивать высокую точность результатов даже в случаях, когда классические численные методы сталкиваются с трудностями. Данные улучшения в скорости сходимости открывают новые возможности для моделирования и анализа сложных систем в различных областях науки и техники.
В рамках DL-HIM (Deep Learning-based High-order Iterative Methods) особое внимание привлекают специализированные архитектуры нейронных операторов, такие как HINTS (High-order Neural Iterative Network Solvers) и Fourier Neural Solver. Эти конструкции демонстрируют повышенную эффективность в решении дифференциальных уравнений в частных производных благодаря целенаправленному использованию априорных знаний о физике задачи. HINTS, например, интегрирует высокопорядочные численные схемы непосредственно в нейронную сеть, что позволяет ускорить сходимость и повысить точность. Fourier Neural Solver, в свою очередь, использует свойства преобразования Фурье для эффективного моделирования решений, особенно в задачах, связанных с волновыми процессами. Успешное применение этих архитектур подтверждает, что разработка нейронных операторов с учетом специфики решаемой задачи является ключевым фактором для создания эффективных и надежных методов решения уравнений в частных производных.
Исследования показали, что применение физически-обоснованной акселерации Андерсона (PA-AA) в рамках DL-HIMs позволяет достигать исключительно высокой скорости сходимости при решении неопределённых уравнений Гельмгольца. В отличие от стандартной акселерации Андерсона, которая демонстрирует стагнацию на уровне точности 10^{-3}, PA-AA обеспечивает сходимость до 10^{-9}. Этот значительный прогресс достигается благодаря учету физических свойств решаемой задачи в процессе итерационной доработки решения, что позволяет эффективно снижать погрешность и ускорять достижение необходимой точности. Такой подход открывает новые возможности для точного и быстрого моделирования сложных физических явлений, где традиционные численные методы сталкиваются с трудностями.
Успешная реализация и демонстрация эффективности DL-HIMs открывают принципиально новые возможности для решения дифференциальных уравнений в частных производных (ДУЧП) в широком спектре научных и инженерных областей. Эти методы, позволяющие значительно ускорить сходимость и достигать высокой точности даже для сложных задач, таких как неоднозначное уравнение Гельмгольца или стохастическая диффузия, представляют собой перспективную альтернативу традиционным численным подходам. Потенциал DL-HIMs простирается от моделирования волновых процессов и гидродинамики до анализа материалов и оптимизации инженерных конструкций. Возможность автоматизации и ускорения решения ДУЧП с помощью этих методов может привести к революционным изменениям в таких областях, как прогнозирование погоды, разработка лекарств и проектирование новых материалов, значительно сокращая время и ресурсы, необходимые для проведения сложных научных исследований и инженерных расчетов.
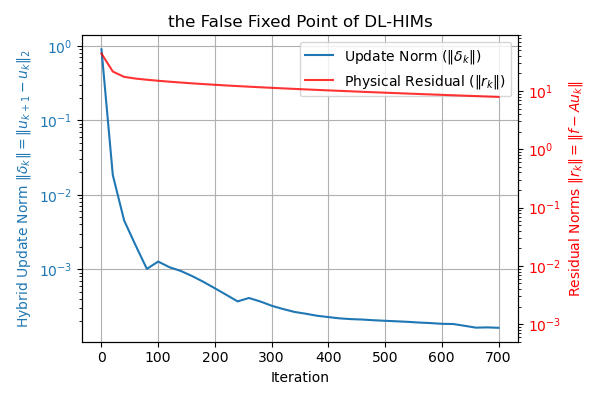
Исследование показывает, что надежность гибридных решателей уравнений в частных производных, основанных на глубоком обучении, определяется не только архитектурой нейронной сети, но и, что особенно важно, парадигмой обучения и стратегией обновления. Этот акцент на систематическом исследовании закономерностей перекликается с убеждением Вильгельма Рентгена: «Я не могу сказать, что я понимаю, что это такое, но это есть». Подобно тому, как Рентген обнаружил неизвестное явление, данная работа подчеркивает необходимость тщательного анализа границ данных и стратегий обучения, чтобы избежать ложных закономерностей и обеспечить сходимость решателей. Физически-обоснованное ускорение Андерсона, представленное в статье, является примером поиска закономерностей, позволяющих улучшить сходимость и надежность численных методов.
Что дальше?
Представленные результаты подчеркивают парадоксальную зависимость эффективности гибридных итерационных методов, основанных на глубоком обучении, не столько от изящества нейронной сети, сколько от тщательно подобранной стратегии обучения. Возникает закономерный вопрос: не упускаем ли мы из виду фундаментальные закономерности в самих решаемых уравнениях, заменяя глубокое понимание алгоритмической ловкостью? Очевидно, что дальнейшее развитие требует не только усовершенствования архитектур нейронных операторов, но и более глубокого анализа влияния начальных условий и граничных задач на сходимость и стабильность решения.
Особенно важно учитывать те аспекты, которые неявно присутствуют в данных, но могут существенно влиять на конечный результат. Шум, неточности в данных, а также пропуски информации — всё это создает скрытые ограничения, которые необходимо учитывать. Предложенное физически-обоснованное ускорение Андерсона — это шаг в правильном направлении, однако возникает вопрос о его универсальности. Действительно ли один подход может эффективно справляться с широким спектром уравнений в частных производных, или же потребуется разработка специализированных стратегий ускорения для каждого конкретного класса задач?
Будущие исследования должны быть направлены на разработку методов, позволяющих оценивать надежность полученных решений, а также выявлять потенциальные источники ошибок. Необходимо искать способы интеграции физических знаний в процесс обучения нейронной сети, чтобы обеспечить соответствие решения фундаментальным законам природы. В конечном итоге, цель состоит не в том, чтобы создать «черный ящик», решающий уравнения, а в том, чтобы получить инструмент, позволяющий глубже понять лежащие в основе физические процессы.
Оригинал статьи: https://arxiv.org/pdf/2602.06842.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
2026-02-09 20:12