Автор: Денис Аветисян
Новая методика, основанная на анализе больших данных и семантическом сравнении, позволяет автоматизировать оценку новизны научных публикаций.
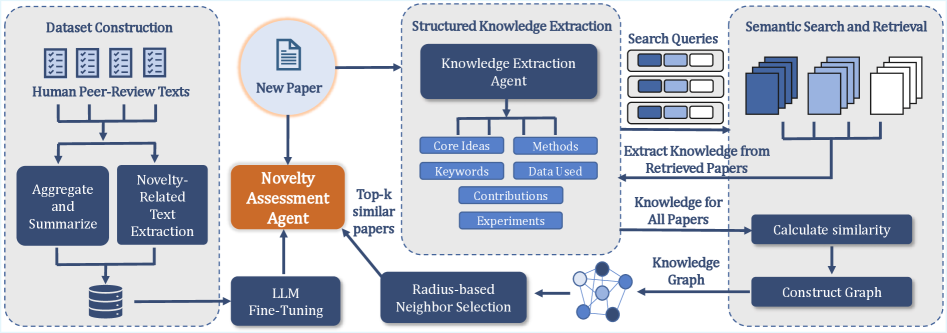
Представлена система ‘Novelty Reviewer’, использующая модели обработки естественного языка и графы знаний для объективной оценки оригинальности научных текстов.
Оценка научной новизны является ключевым, но субъективным аспектом рецензирования, часто полагающимся на неявные суждения и неполное сравнение с существующими работами. В статье ‘What Is Novel? A Knowledge-Driven Framework for Bias-Aware Literature Originality Evaluation’ представлен подход, основанный на анализе научной литературы и использующий большие языковые модели для автоматической оценки оригинальности научных рукописей. Разработанная система извлекает структурированное представление идей, методов и утверждений, сопоставляя их с существующими исследованиями и формируя откалиброванные оценки новизны. Сможет ли предложенный фреймворк повысить объективность и последовательность рецензирования, а также помочь выявить действительно новаторские научные работы?
Постановка Проблемы: За Пределами Поверхностного Сравнения
Точная оценка научной новизны является фундаментальным аспектом процесса рецензирования и, как следствие, прогресса науки, однако представляет собой сложную задачу. Неспособность адекватно определить, действительно ли исследование предлагает принципиально новые идеи или является лишь незначительной модификацией существующих, может привести к задержкам в публикации значимых результатов и неэффективному распределению финансирования. Определение новизны требует не просто сопоставления ключевых слов или поверхностного анализа, а глубокого понимания контекста, существующих знаний и потенциального вклада работы в развитие соответствующей области. Этот процесс осложняется экспоненциальным ростом объема научной информации, что делает ручной анализ все более трудоемким и подверженным ошибкам.
Традиционные методы оценки научной новизны зачастую оказываются неэффективными, поскольку полагаются на сопоставление ключевых слов или поверхностное сходство между работами. Такой подход не позволяет выявить действительно оригинальные идеи, поскольку игнорирует более глубокие концептуальные связи и инновационные комбинации существующих знаний. Исследования показывают, что простое обнаружение общих терминов в аннотациях или названиях не гарантирует выявление подлинной научной ценности, а может привести к ошибочной оценке, когда незначительные вариации представляются как прорывные открытия. Это ограничивает способность экспертов в области рецензирования точно оценивать вклад каждой новой работы и эффективно распределять финансирование научных исследований.
Неспособность эффективно выявлять подлинно новаторские исследования оказывает тормозящее воздействие на прогресс науки в целом. Затруднения в оценке инноваций приводят к тому, что перспективные разработки могут оставаться незамеченными, а ограниченные ресурсы направляются на проекты, не обладающие существенным прорывом. Это, в свою очередь, замедляет темпы научных открытий и снижает эффективность финансирования исследований, создавая ситуацию, когда действительно ценные идеи испытывают недостаток поддержки, в то время как менее значимые работы получают незаслуженное признание. В конечном итоге, подобная ситуация подрывает доверие к научной среде и препятствует развитию передовых технологий.
Построение Фундамента Знаний: Структурированное Представление Исследований
В основе нашего подхода лежит преобразование неструктурированного научного текста в структурированный граф знаний (Knowledge Graph). Этот процесс включает извлечение и формализацию ключевых концепций, используемых методов и основных результатов исследований, представленных в текстовом формате. Граф знаний позволяет представить информацию в виде взаимосвязанных узлов (сущностей) и ребер (отношений между ними), что обеспечивает возможность машинной обработки и анализа научных данных. Формализованное представление позволяет эффективно организовывать и извлекать информацию, необходимую для сравнения, обобщения и выявления закономерностей в научных публикациях.
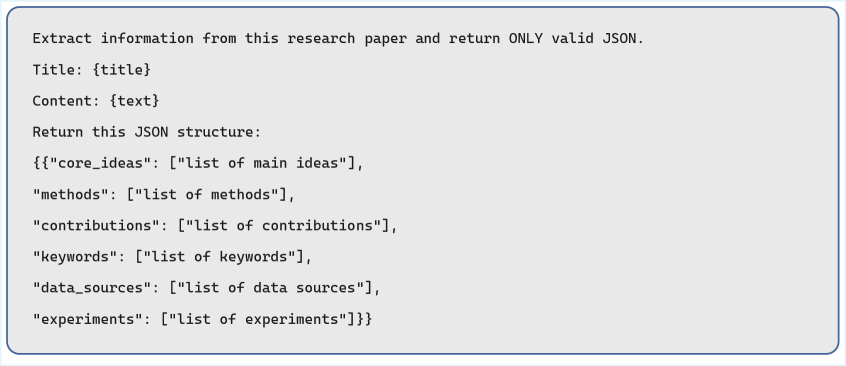
Процесс структурированного извлечения знаний автоматизирован с использованием большой языковой модели Llama-3.1-8B-Instruct. Данная модель, основанная на архитектуре Transformer, анализирует научный текст для идентификации ключевых элементов, таких как методы исследования, основные результаты и вносимый вклад. Автоматизация позволяет обрабатывать большие объемы научной литературы, выделяя релевантную информацию и представляя её в структурированном виде, пригодном для последующего анализа и построения графа знаний. Использование Llama-3.1-8B-Instruct обеспечивает высокую точность и эффективность извлечения информации по сравнению с ручными методами.
Результирующий граф знаний, построенный с использованием API Semantic Scholar, обеспечивает детализированное сопоставление между рукописями и существующей литературой. В частности, API позволяет извлекать метаданные публикаций, цитирования и ключевые слова, что используется для определения степени новизны исследования, выявления связанных работ и оценки влияния представленного материала на научное сообщество. Сравнение осуществляется по нескольким параметрам, включая тематическую схожесть, методологический подход и вклад в конкретную область знаний, что позволяет исследователям быстро оценивать релевантность и значимость новых публикаций.
Оценка с Учетом Литературного Контекста: Углубление Оценки Новизны
Наша система оценки новизны использует построенный граф знаний для проведения оценки, учитывающей литературный контекст, что позволяет выявлять семантические связи и различия между представленной рукописью и существующей научной литературой. В отличие от простых методов сопоставления ключевых слов, система анализирует взаимосвязи между концепциями, представленными в графе знаний, для определения уникальности вносимого вклада. Это позволяет системе не только идентифицировать сходства, но и выявлять новые комбинации существующих знаний или принципиально новые концепции, обеспечивая более глубокую и точную оценку новизны исследования.
В отличие от простого сопоставления ключевых слов, система оценивает новизну рукописи посредством концептуального сравнения. Этот подход анализирует семантические связи и отношения между идеями, представленными в тексте, и существующими знаниями, структурированными в Knowledge Graph. Вместо идентификации совпадений по словам, система оценивает существенные научные вклады, определяя, насколько предложенные концепции отличаются от уже известных, и выявляя оригинальность представленных идей. Это позволяет более точно оценивать реальную новизну исследования, а не просто наличие или отсутствие определенных терминов.
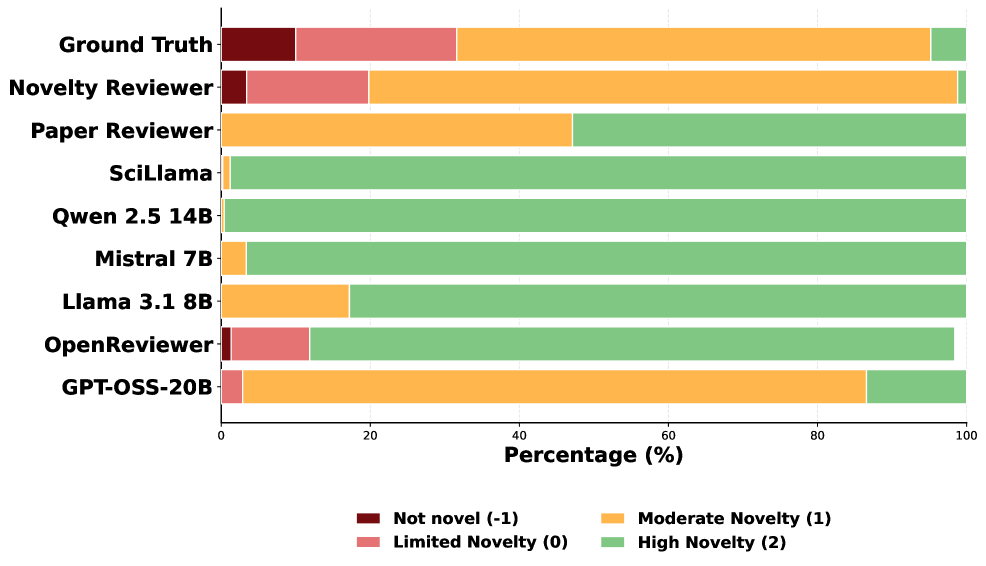
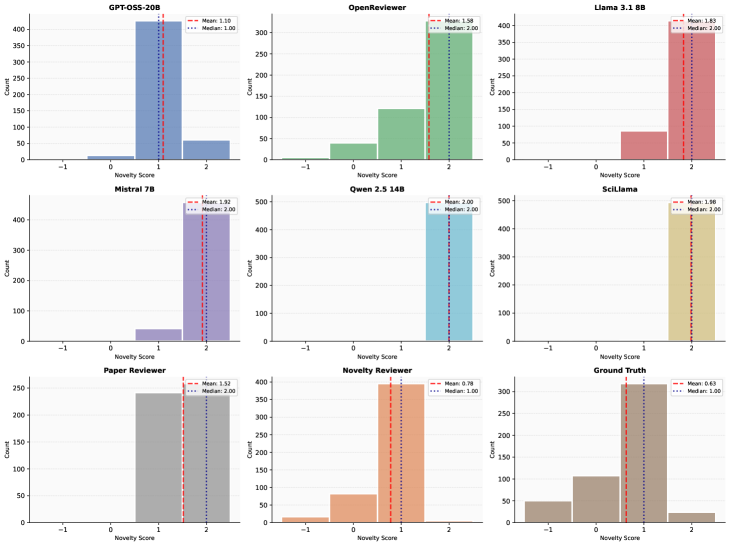
Система генерирует оценку новизны (Novelty Score) в диапазоне от -1 до 2, где отрицательные значения указывают на отсутствие новизны, 0 — на инкрементальное улучшение, 1 — на значительное улучшение, а 2 — на прорывное открытие. Проверка точности предсказания дискретных оценок новизны показала коэффициент корреляции Пирсона r = 0.78 по отношению к ранжированию новизны, выполненному экспертами-людьми. Данный результат демонстрирует высокую степень согласованности между автоматизированной оценкой и экспертным мнением, подтверждая надежность системы в определении уровня новизны представленных материалов.
Обеспечение Надежности и Устойчивости: Валидация Рамки Оценки Новизны
Для повышения достоверности оценок модели новизны были применены методы калибровки неопределенности. Эти методы позволяют скорректировать выходные вероятности модели таким образом, чтобы они лучше отражали фактическую уверенность в правильности предсказаний. Калибровка проводилась путем минимизации расхождения между предсказанными вероятностями и фактической частотой правильных ответов для различных уровней уверенности. Это позволило получить более точные и надежные оценки новизны, что критически важно для последующего анализа и принятия решений на основе результатов работы модели.
Для повышения обобщающей способности модели и улучшения её производительности на невидимых данных применялась техника аугментации данных. Данный подход включал в себя создание дополнительных обучающих примеров путём внесения незначительных изменений в существующие данные, таких как перефразирование, замена синонимов и обратный перевод. Аугментация позволила искусственно увеличить размер обучающей выборки, что способствовало снижению переобучения и повышению устойчивости модели к вариациям во входных данных. В процессе аугментации применялись различные стратегии, направленные на сохранение семантического смысла исходных данных при внесении изменений.
Результаты оценки Novelty Reviewer показали наивысший показатель Entailment-Contradiction (E-C) в рамках задачи Natural Language Inference (NLI) по сравнению с другими протестированными моделями. Этот показатель отражает степень соответствия между оценками новизны, генерируемыми моделью, и эталонными сводками новизны, подготовленными человеком. Более высокий E-C NLI score указывает на более точную и согласованную оценку новизны, что свидетельствует о лучшем понимании моделью семантических связей и более надежном определении действительно новых и значимых элементов информации.

К Автоматизированному Научному Открытию: Последствия и Перспективы
Автоматизированная оценка научной новизны, реализованная в предложенной системе, способна значительно ускорить процессы рецензирования. Традиционно требующее значительных временных затрат, рецензирование часто замедляется субъективными оценками и потенциальными предубеждениями. Система, анализируя сходство представленной работы с существующим корпусом научных знаний, предоставляет объективную метрику новизны, что позволяет редакторам и рецензентам более эффективно расставлять приоритеты и концентрироваться на действительно оригинальных исследованиях. Подобный подход не только сокращает время, необходимое для оценки рукописи, но и минимизирует влияние личных предпочтений, способствуя более справедливому и прозрачному процессу принятия решений в научной сфере. В перспективе, интеграция подобной автоматизации в существующие платформы рецензирования может привести к существенному повышению эффективности и качества научной публикации.
Интеграция данной системы с платформами, такими как OpenReview, открывает новые возможности для повышения эффективности и объективности рецензирования. Предлагаемый подход позволяет предоставлять рецензентам дополнительную информацию о новизне представляемой работы, что существенно облегчает процесс оценки и выявления действительно оригинальных исследований. Система способна выявлять сходство с существующими публикациями, предоставляя рецензентам контекст и помогая им аргументированно обосновать свою оценку. В результате, рецензенты получают поддержку в принятии взвешенных решений, а качество научных публикаций в целом повышается за счет более тщательной и всесторонней оценки.
Результаты проведенного анализа демонстрируют значительное семантическое соответствие между автоматизированной оценкой научной новизны и экспертными заключениями рецензентов. Коэффициент косинусного сходства, равный 0.78, указывает на то, что система способна выявлять аспекты, которые люди также считают важными при оценке оригинальности исследования. Это подтверждает потенциал автоматизированного подхода в качестве вспомогательного инструмента для оценки научных работ, способного фиксировать и выделять ключевые элементы, определяющие вклад исследования в существующую область знаний. Данный показатель свидетельствует о высокой степени согласованности между машинным анализом и экспертным суждением, открывая возможности для повышения эффективности и объективности процесса рецензирования.

Данное исследование, стремящееся автоматизировать оценку новизны научных работ, неизбежно наталкивается на проблему интерпретации ‘знания’. Авторы предлагают использовать графы знаний и модели обработки естественного языка для выявления схожести с существующими исследованиями, что, в конечном счете, сводится к формализации субъективного восприятия. Как метко заметил Марвин Минский: «Лучший способ предсказать будущее — изобрести его». В контексте ‘Novelty Reviewer’, это означает, что попытка алгоритмически определить ‘новизну’ — это, по сути, попытка предсказать, что будет признано значимым в будущем. И, вероятнее всего, эта система начнет выдавать ложные срабатывания сразу после первой же крупной миграции в области научных данных. Документация, конечно, будет утверждать обратное.
Что дальше?
Представленная работа, безусловно, элегантна в своей попытке формализовать понятие научной новизны. Однако, история показывает, что каждая автоматизированная система оценки неизбежно сталкивается с потоком манипуляций и «оптимизаций под алгоритм». Авторы справедливо используют семантическое сходство и графы знаний, но следует помнить: база знаний всегда неполна, а семантика — вещь субъективная. Завтра появятся новые методы «обмана» системы, и всё придётся начинать сначала.
Наиболее сложной задачей остаётся оценка реального вклада работы, а не просто её отличия от существующей литературы. Легко определить, что статья не повторяет уже опубликованные результаты; гораздо сложнее — оценить, насколько значимо само добавление к корпусу знаний. Автоматизация этого этапа представляется утопией. Скорее всего, «Novelty Reviewer» станет ещё одним инструментом в руках рецензентов, облегчающим рутинную работу, но не заменяющим критическое мышление.
Если тесты покажут высокую точность — это, вероятно, означает лишь то, что система обучена на тривиальных примерах. Будущие исследования, вероятно, будут направлены на интеграцию с более сложными моделями оценки, учитывающими контекст, влияние и потенциальную применимость работы. Но, как показывает опыт, всё это уже было в 2012-м, только называлось иначе.
Оригинал статьи: https://arxiv.org/pdf/2602.06054.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Искусственный интеллект: хрупкость визуального мышления
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Иллюзия Компетентности: Как ИИ Переоценивает Себя
2026-02-10 01:17