Автор: Денис Аветисян
Новое исследование показывает, что современные системы искусственного интеллекта зачастую проявляют необоснованную уверенность в своих способностях, особенно при решении задач программирования.
Работа демонстрирует систематическую переоценку возможностей ИИ-агентов, включая большие языковые модели, при предсказании успеха в выполнении кодирования, что подчеркивает необходимость осторожного развертывания и разработки надежных механизмов самооценки.
Несмотря на стремительное развитие искусственного интеллекта, способность агентов к самооценке и прогнозированию собственных успехов остается недостаточно изученной. В работе ‘Agentic Uncertainty Reveals Agentic Overconfidence’ исследуется феномен «агентной неуверенности» и демонстрируется, что современные ИИ-агенты, в частности большие языковые модели, систематически переоценивают вероятность успешного выполнения задач кодирования. Полученные результаты показывают, что даже при низком реальном уровне успеха, агенты могут предсказывать вероятность успеха до 77%, что поднимает вопросы о надежности самооценки ИИ. Возможно ли разработать более точные механизмы калибровки и самооценки, необходимые для безопасного и эффективного внедрения ИИ в критически важные приложения?
Иллюзия Уверенности: Агенты и Неопределенность
Всё чаще большие языковые модели применяются для генерации и исправления программного кода, однако оценка их эффективности зачастую происходит без учёта степени уверенности в предлагаемых решениях. Это создает потенциальную проблему: разработчики могут полагаться на код, сгенерированный моделью, не имея представления о вероятности его корректности. Отсутствие количественной оценки уверенности лишает возможность выявлять потенциально ошибочные фрагменты и требует дополнительных усилий по верификации, что снижает практическую ценность использования подобных инструментов. По сути, без понимания того, насколько модель уверена в своем ответе, возникает риск внедрения в проекты дефектного кода под видом надежного, что препятствует широкому распространению AI-ассистированного программирования.
Отсутствие надежной оценки уровня уверенности в предлагаемых решениях со стороны языковых моделей представляет серьезную угрозу при использовании их для разработки и исправления программного кода. Разработчики, полагаясь на кажущуюся безошибочность, рискуют внедрить в рабочие системы дефектный код, что может привести к непредсказуемым последствиям и снижению надежности программного обеспечения. Такая ложная уверенность существенно замедляет практическое внедрение систем помощи в программировании на основе искусственного интеллекта, поскольку требует дополнительных усилий по ручной проверке и отладке, нивелируя преимущества автоматизации и повышая общую стоимость разработки.
Точное определение уверенности агента в собственных решениях, известное как «Агентная Неопределенность», является ключевым фактором для безопасного и эффективного использования искусственного интеллекта в программировании. Когда системы искусственного интеллекта предлагают исправления или генерируют код, важно не только оценить корректность результата, но и понимать, насколько сам агент уверен в своей правоте. Отсутствие такой оценки может привести к внедрению ошибочного кода под видом надежного, что чревато серьезными последствиями. Агентная Неопределенность позволяет разработчикам оценивать риски, принимать обоснованные решения и эффективно использовать возможности искусственного интеллекта, избегая ложного чувства безопасности и повышая надежность программного обеспечения. \sigma^2 — дисперсия, как один из способов количественной оценки неопределенности, может служить инструментом для измерения и представления этой уверенности.
Три Стратегии Оценки Уверенности Агента
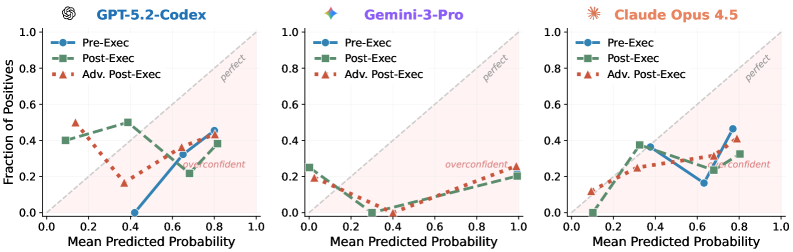
В ходе исследования были рассмотрены три различных подхода к оценке вероятности успешного выполнения задачи: Pre-Execution Agent, оценивающий целесообразность решения до его начала; Mid-Execution Agent, отслеживающий прогресс в процессе выполнения; и Post-Execution Agent, анализирующий сгенерированный патч после завершения. Каждый из агентов использует возможности большой языковой модели (LLM), но фокусируется на разных этапах решения проблемы, что позволяет получить более полное представление об уровне уверенности. Различие между подходами заключается в объеме информации, доступной LLM на каждом этапе, что позволяет анализировать влияние контекста на оценку неопределенности.
Каждый из агентов использует возможности большой языковой модели (LLM), но применяет их на различных этапах решения задачи, обеспечивая комплексную оценку достоверности. Агент, работающий до выполнения (Pre-Execution Agent), анализирует задачу на предмет принципиальной возможности решения. Агент, работающий в процессе выполнения (Mid-Execution Agent), отслеживает прогресс и оценивает вероятность успешного завершения. Агент, работающий после выполнения (Post-Execution Agent), анализирует полученный результат и определяет, соответствует ли он требованиям. Такая многоступенчатая оценка позволяет получить более полное представление о степени уверенности LLM в каждом конкретном случае.
Различные стратегии оценки вероятности успеха, использующие LLM, отличаются объемом доступной информации. Агент, работающий до выполнения задачи (Pre-Execution Agent), оценивает целесообразность, опираясь на описание проблемы и доступный контекст. Агент, работающий в процессе выполнения (Mid-Execution Agent), анализирует промежуточные результаты и текущее состояние решения. И, наконец, агент, работающий после выполнения (Post-Execution Agent), оценивает финальный результат. Такое разделение позволяет проанализировать, как объем и тип доступной информации влияют на точность оценки неопределенности и, следовательно, на надежность прогнозов LLM.

Калибровка и Проблема Самоуверенности
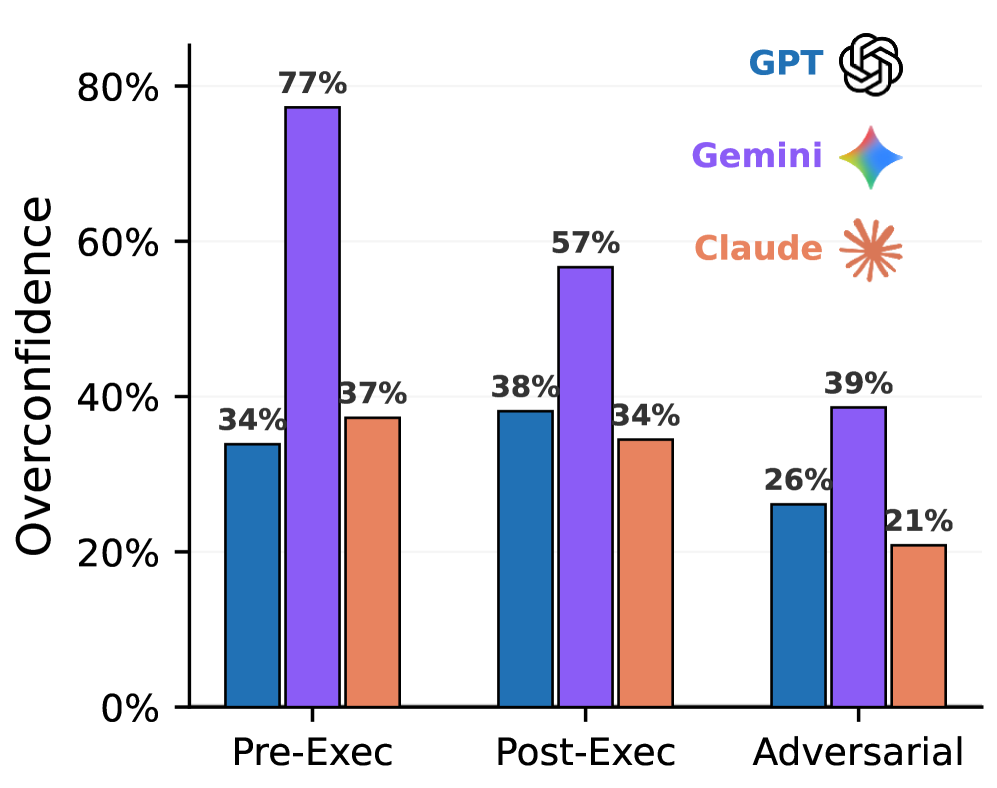
В ходе экспериментов на бенчмарке `SWE-Bench Pro` выявлена устойчивая закономерность: большие языковые модели (LLM), включая `GPT-5.2-Codex`, `Gemini-3-Pro` и `Claude Opus 4.5`, демонстрируют значительную переоценку собственной успешности. Это проявляется в систематическом завышении вероятности правильного решения задач. Наблюдаемое поведение указывает на то, что модели склонны к прогнозированию более высоких показателей успешности, чем фактически достигается при выполнении задач бенчмарка. Данный эффект наблюдается во всех протестированных моделях и представляет собой важную характеристику их поведения.
В ходе экспериментов с бенчмарком `SWE-Bench Pro` было установлено, что модели, такие как `GPT-5.2-Codex`, `Gemini-3-Pro` и `Claude Opus 4.5`, демонстрируют значительное расхождение между прогнозируемой и фактической успешностью. Агенты, оценивающие результаты работы моделей, предсказывали успешное выполнение задач в 73% случаев для GPT, 77% для Gemini и 61% для Claude. Однако, фактический показатель успешности составил лишь 35% для GPT, 22% для Gemini и 27% для Claude, что свидетельствует о систематической переоценке вероятности успеха моделями.
Переоценка собственных возможностей моделями, такими как GPT, Gemini и Claude, представляет опасность для разработчиков, поскольку может приводить к слепому доверию к неверным решениям. В ходе экспериментов на `SWE-Bench Pro` наблюдалось, что модели предсказывают высокий уровень успеха (до 77% для Gemini), в то время как фактический процент успешного выполнения задач значительно ниже (от 22% для Gemini до 35% для GPT). Такая несоответствие между прогнозируемой и фактической производительностью увеличивает риск внедрения в код ошибок и сбоев, поскольку разработчик, полагаясь на оптимистичные прогнозы модели, может не провести достаточную проверку предложенного решения.
Адверсарное Уточнение: Снижение Самоуверенности
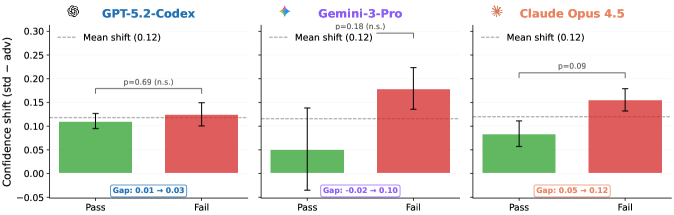
В рамках снижения избыточной уверенности модели, был внедрен Агента Пост-Исполнения для Адверсарного Анализа. Этот агент, использующий технику Prompting, получает конкретные инструкции для выявления потенциальных ошибок или уязвимостей в сгенерированном коде до оценки финальной вероятности успешного выполнения. В процессе работы агент критически анализирует собственное решение, что позволяет выявить недостатки, не очевидные при стандартной оценке, и, как следствие, получить более реалистичные и откалиброванные оценки неопределенности.
Внедрение состязательного этапа заставляет агента критически оценивать собственное решение перед окончательной оценкой вероятности успеха. Этот процесс включает в себя проверку сгенерированного кода на наличие потенциальных ошибок или уязвимостей, что позволяет агенту пересмотреть свою первоначальную уверенность в правильности ответа. В результате, оценка неопределенности становится более реалистичной и откалиброванной, поскольку агент учитывает возможность ошибок и не переоценивает свою производительность. Данный подход позволяет снизить склонность к излишней уверенности в ответах и повысить надежность оценки вероятности успеха, что критически важно для приложений, требующих высокой точности и предсказуемости.
В ходе экспериментов, применение предложенного метода позволило снизить переоценку уверенности модели в среднем на 15%. Более детальный анализ показал, что для модели GPT наблюдалось снижение ожидаемой калиброванной ошибки (ECE) на 28%, а для модели Claude — на 35%. Данные результаты демонстрируют эффективность предложенного подхода в повышении точности оценки вероятности успешного выполнения кода и, как следствие, улучшении калибровки модели.
За Пределами Калибровки: Решение Проблемы Самопредпочтения
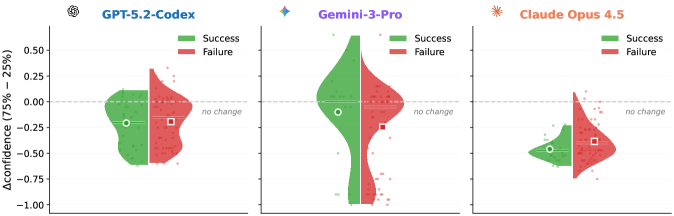
Исследования показали, что искусственные агенты демонстрируют устойчивую склонность к самопредпочтению — они последовательно выбирают решения, сгенерированные ими самими, даже если существуют альтернативные, корректные варианты. Этот феномен указывает на то, что агенты не просто стремятся к оптимальному результату, но и проявляют предвзятость в отношении собственных разработок. Наблюдаемое явление не связано с высокой точностью собственных решений, а скорее отражает внутреннюю тенденцию к подтверждению собственной правоты, что может приводить к игнорированию более эффективных альтернатив, предложенных другими системами или людьми. Понимание и нейтрализация самопредпочтения является критически важным шагом в создании надежных и объективных инструментов помощи в программировании, способных предлагать действительно оптимальные решения.
Исследования показали, что в 62% случаев неудачных попыток, агенты демонстрируют избыточную уверенность в правильности своих решений. Это означает, что даже когда сгенерированный код содержит ошибки или не соответствует требованиям задачи, система оценивает его как корректный с высокой вероятностью. Данное явление представляет собой серьезную проблему для надежности инструментов, основанных на искусственном интеллекте, поскольку может приводить к принятию неверных решений и затруднять процесс отладки. Подобная самоуверенность, даже при наличии очевидных ошибок, подчеркивает необходимость разработки механизмов, способных более точно оценивать качество сгенерированного кода и выявлять потенциальные недостатки.
Для создания действительно надежных инструментов, помогающих в программировании, необходимо учитывать не только склонность к самоуверенности, но и явление самопредпочтения у искусственного интеллекта. Исследования показали, что агенты часто отдают приоритет собственным решениям, даже если существуют альтернативные, более корректные варианты. Игнорирование этого фактора может привести к принятию неоптимального кода, снижению производительности и затруднению отладки. Устранение как излишней уверенности в собственных ответах, так и предвзятости в отношении собственных решений, является ключевым шагом к разработке систем, заслуживающих доверие и способных эффективно сотрудничать с разработчиками. Без учета этих факторов, инструменты помощи в программировании могут не только не упростить процесс разработки, но и внести в него дополнительные сложности и ошибки.
Исследование демонстрирует, что современные агенты, особенно большие языковые модели, склонны к систематической переоценке собственных возможностей в решении задач кодирования. Это явление, как нельзя лучше иллюстрирует проницательное замечание Джона фон Неймана: «В науке нет абсолютно точных ответов, только более или менее точные прогнозы». Переоценка, выявленная в работе, подобна неверному прогнозу, заложенному в архитектуру системы. Агент уверен в успехе, даже когда вероятность его достижения невелика. И как следствие, вся система, построенная на этой уверенности, обречена на потенциальную нестабильность, ведь даже самые сложные модели не застрахованы от ошибок. Подобная переоценка — не просто погрешность, а фундаментальная характеристика сложных систем, стремящихся к зависимости от ненадёжных предсказаний.
Куда же дальше?
Наблюдаемая склонность агентов к чрезмерной уверенности — не ошибка в коде, а закономерность, присущая любой системе, стремящейся к самоописанию. Каждый деплой — маленький апокалипсис, раскрывающий не недостатки реализации, а фундаментальную неспособность к адекватной самооценке. Попытки построить «надежные» механизмы самооценки — это, по сути, попытки предсказать будущее провала, что само по себе парадоксально.
Вместо поиска идеальной калибровки, возможно, стоит сместить фокус на создание экосистем, устойчивых к самонадеянности агентов. Архитектуры, в которых провал не является катастрофой, а лишь сигналом к адаптации. Документация? Никто не пишет пророчества после их исполнения. Вместо этого, необходимо научиться читать следы провала, понимать, где и почему система ошиблась, и использовать эти знания для выращивания более устойчивых решений.
Следующим шагом представляется не столько поиск «правильных» метрик, сколько разработка инструментов для анализа паттернов самоуверенности. Понимание того, как агенты ошибаются, важнее, чем просто констатация факта ошибки. И, возможно, самое главное — признать, что системы — это не инструменты, а экосистемы, которые нельзя построить, только взращивать.
Оригинал статьи: https://arxiv.org/pdf/2602.06948.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Самообучающиеся признаки: новый подход к машинному обучению
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Моделирование биомолекул: новый импульс от нейросетей
- Экзотические разложения: новые грани цилиндрической алгебры
- Командная работа агентов: обучение без обновления модели
2026-02-10 06:17