Автор: Денис Аветисян
В новой работе исследователи продемонстрировали успешную реализацию модели Gemma3 на архитектуре с потоковой обработкой данных, значительно повысив производительность и энергоэффективность.
Исследование посвящено оптимизации модели Gemma3 для периферийных устройств с использованием NPU-ускорения, квантизации и эффективного управления пропускной способностью памяти.
Несмотря на растущий спрос на эффективные вычисления, развертывание больших языковых и мультимодальных моделей на периферийных устройствах остается сложной задачей. В статье ‘Mapping Gemma3 onto an Edge Dataflow Architecture’ представлен первый сквозной пример развертывания семейства моделей Gemma3 на архитектуре с потоковой передачей данных (AMD Ryzen AI NPU). Предложенные аппаратные оптимизации, включая эффективную деквантизацию, оптимизированные ядра матричного умножения и новые механизмы внимания, позволяют достичь ускорения до 5.2\times для префилла и 4.8\times для декодирования по сравнению с iGPU, значительно повышая энергоэффективность. Сможет ли данный подход стать основой для создания доступных и эффективных решений для периферийных вычислений и обработки больших моделей?
Разрушая Границы: Узкое Место Инференса в Больших Языковых Моделях
Современные большие языковые модели, такие как Gemma3, демонстрируют впечатляющие возможности в обработке и генерации текста, однако их практическое применение часто ограничивается скоростью вывода результатов и потребностью в значительных вычислительных ресурсах. Несмотря на растущую мощность оборудования, обработка длинных последовательностей текста требует всё больше памяти и вычислительной мощности, что создает серьезные препятствия для развертывания этих моделей на устройствах с ограниченными ресурсами или в приложениях, требующих быстрого отклика. В результате, возникает необходимость в разработке новых методов оптимизации, позволяющих снизить вычислительную нагрузку и повысить эффективность работы больших языковых моделей без ущерба для качества генерируемого текста и способности понимать сложные запросы.
Традиционные механизмы внимания, лежащие в основе многих больших языковых моделей, сталкиваются с серьезными трудностями при обработке длинных последовательностей данных. Суть проблемы заключается в том, что для анализа каждого элемента последовательности модель вынуждена сравнивать его со всеми остальными, что приводит к квадратичному росту вычислительных затрат с увеличением длины текста. Это существенно ограничивает возможности моделей при решении задач, требующих анализа больших объемов информации, таких как суммирование длинных документов, перевод сложных текстов или понимание контекста в продолжительных диалогах. В результате, производительность моделей значительно снижается, а потребность в вычислительных ресурсах возрастает, что делает обработку длинных последовательностей неэффективной и дорогостоящей.
Существенная проблема в области больших языковых моделей заключается в тонком балансе между размером модели, вычислительными затратами и способностью поддерживать целостное понимание контекста при обработке информации. Увеличение размера модели, как правило, повышает ее точность и способность к обучению, однако это требует значительных вычислительных ресурсов и замедляет процесс инференса. Одновременно, стремление к снижению вычислительных затрат часто приводит к упрощению архитектуры модели, что негативно сказывается на ее способности к пониманию длинных последовательностей и сохранению контекста. Таким образом, разработчики сталкиваются с необходимостью поиска оптимального компромисса, позволяющего создать модели, обладающие высокой производительностью, эффективностью и способностью к глубокому пониманию сложных текстов.
Оптимизация Инференса: Поток и Квантизация — Путь к Эффективности
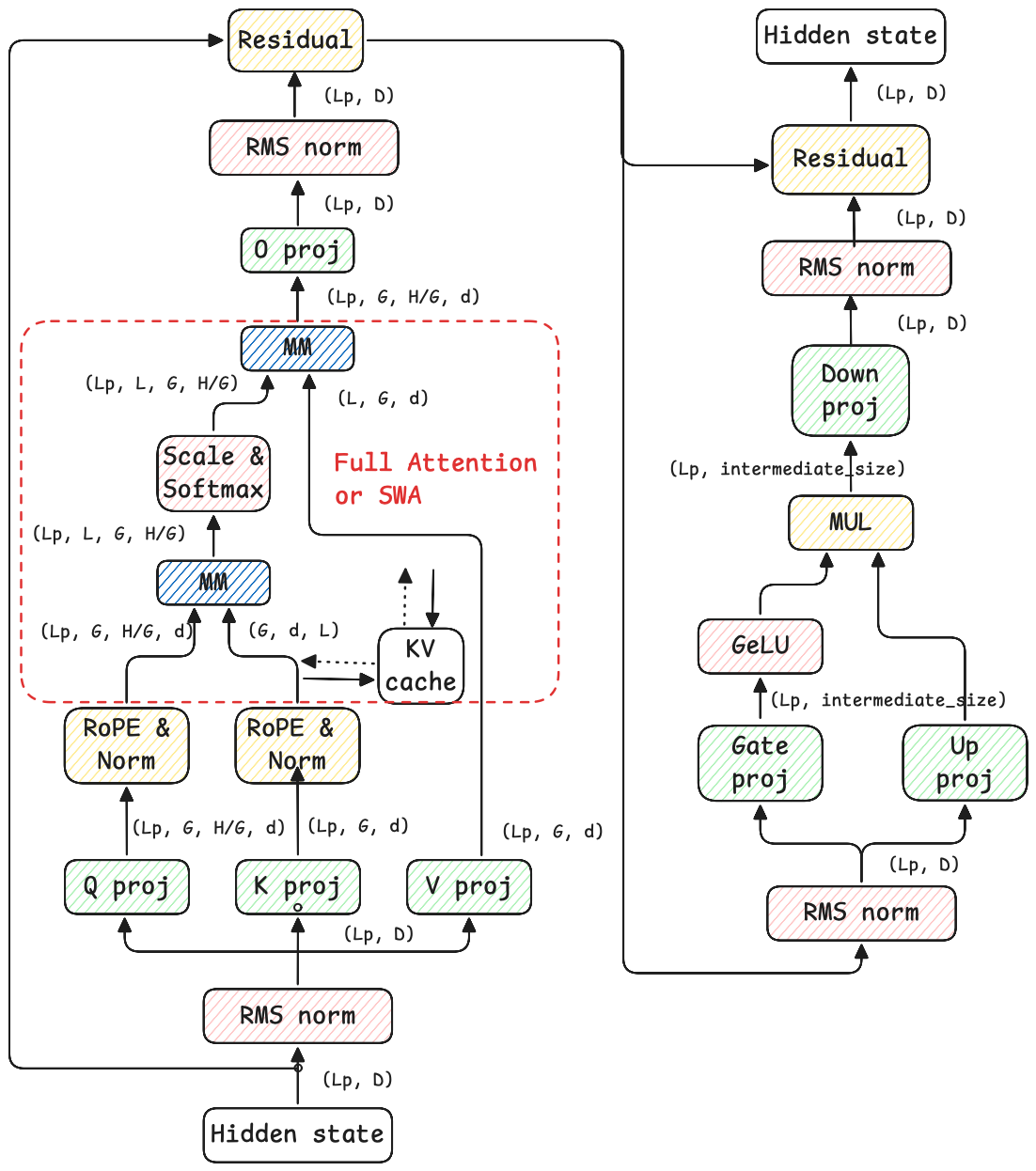
Механизм FlowQKV представляет собой аппаратное обеспечение-ориентированную реализацию внимания, предназначенную для ускорения фазы префикса (prefill) при выводе больших языковых моделей (LLM). Оптимизация доступа к кэшу ключей и значений (KV-кэшу) достигается за счет адаптации алгоритма к архитектуре целевого оборудования, что позволяет снизить задержки и увеличить пропускную способность при обработке начального запроса. В отличие от стандартных механизмов внимания, FlowQKV учитывает особенности организации памяти и конвейерной обработки данных на конкретном аппаратном обеспечении, минимизируя количество операций чтения/записи и улучшая использование пропускной способности памяти.
Механизм FlowQKV эффективно обрабатывает последовательные данные, используя принцип каузальной (однонаправленной) внимательности. В отличие от традиционных механизмов внимания, требующих обработки всей последовательности для каждого шага, FlowQKV ограничивает область внимания текущим и предыдущими токенами, что значительно снижает вычислительную сложность на начальной стадии обработки запроса (prefill). Это достигается за счет оптимизации доступа к KV-кэшу, позволяя уменьшить количество операций чтения и записи и, следовательно, сократить задержку при обработке первоначального запроса и генерации первых токенов ответа.
Применение методов квантизации, таких как Q4NX, позволяет существенно уменьшить размер моделей больших языковых моделей (LLM). Q4NX представляет собой 4-битное квантование с использованием новой схемы нормализации, что снижает требования к памяти и вычислительным ресурсам. Это особенно важно для развертывания LLM на устройствах с ограниченными ресурсами, таких как мобильные телефоны, встраиваемые системы или периферийные вычислительные устройства. Уменьшение размера модели не только облегчает ее хранение и передачу, но и снижает задержки при выводе, делая LLM более доступными и эффективными для широкого спектра приложений.
Оптимизации, включающие аппаратные улучшения и методы квантизации, позволяют значительно ускорить процесс инференса больших языковых моделей (LLM) без потери точности. Сокращение вычислительных затрат и объема занимаемой памяти достигается за счет оптимизации доступа к KV-кэшу и применения техник квантизации, таких как Q4NX, что позволяет развертывать LLM на устройствах с ограниченными ресурсами. Поддержание высокой точности при снижении вычислительной нагрузки является ключевым фактором для практического применения LLM в различных областях, где важна скорость обработки и эффективность использования ресурсов.
AMD Ryzen AI NPU: Архитектура Данных для Раскрытия Потенциала LLM
Архитектура данных (dataflow) в Нейронном Процессоре Искусственного Интеллекта (NPU) AMD Ryzen позволяет выполнять высокопараллельную обработку рабочих нагрузок, связанных с большими языковыми моделями (LLM). В отличие от традиционных архитектур, ориентированных на выполнение инструкций последовательно, dataflow-архитектура NPU обеспечивает одновременное выполнение операций, как только доступны необходимые данные. Это достигается за счет организации вычислений вокруг потока данных, а не последовательности команд, что значительно повышает пропускную способность и снижает задержки при обработке матричных операций, являющихся основой LLM. Такой подход позволяет эффективно использовать вычислительные ресурсы и максимизировать производительность при минимальном энергопотреблении.
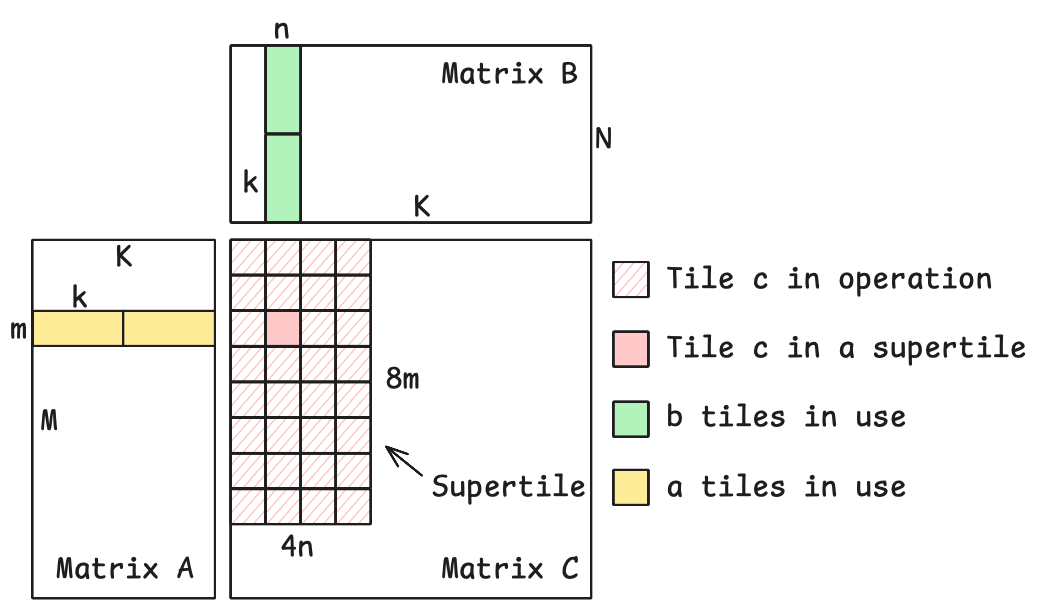
Вычислительная архитектура, используемая в AMD Ryzen AI NPU, активно применяет принцип разбиения данных на плитки (tiled compute). Это позволяет повторно использовать данные, хранящиеся в локальной SRAM (статической оперативной памяти), непосредственно в пределах вычислительных блоков, избегая частых и энергозатратных обращений к внешней памяти. Такой подход значительно снижает задержки, связанные с передачей данных, и обеспечивает существенное повышение производительности, особенно при выполнении операций, требующих интенсивной работы с матрицами, характерных для больших языковых моделей (LLM). Повторное использование данных в локальной SRAM минимизирует необходимость в постоянном обмене информацией с более медленной внешней памятью, что является ключевым фактором повышения общей эффективности системы.
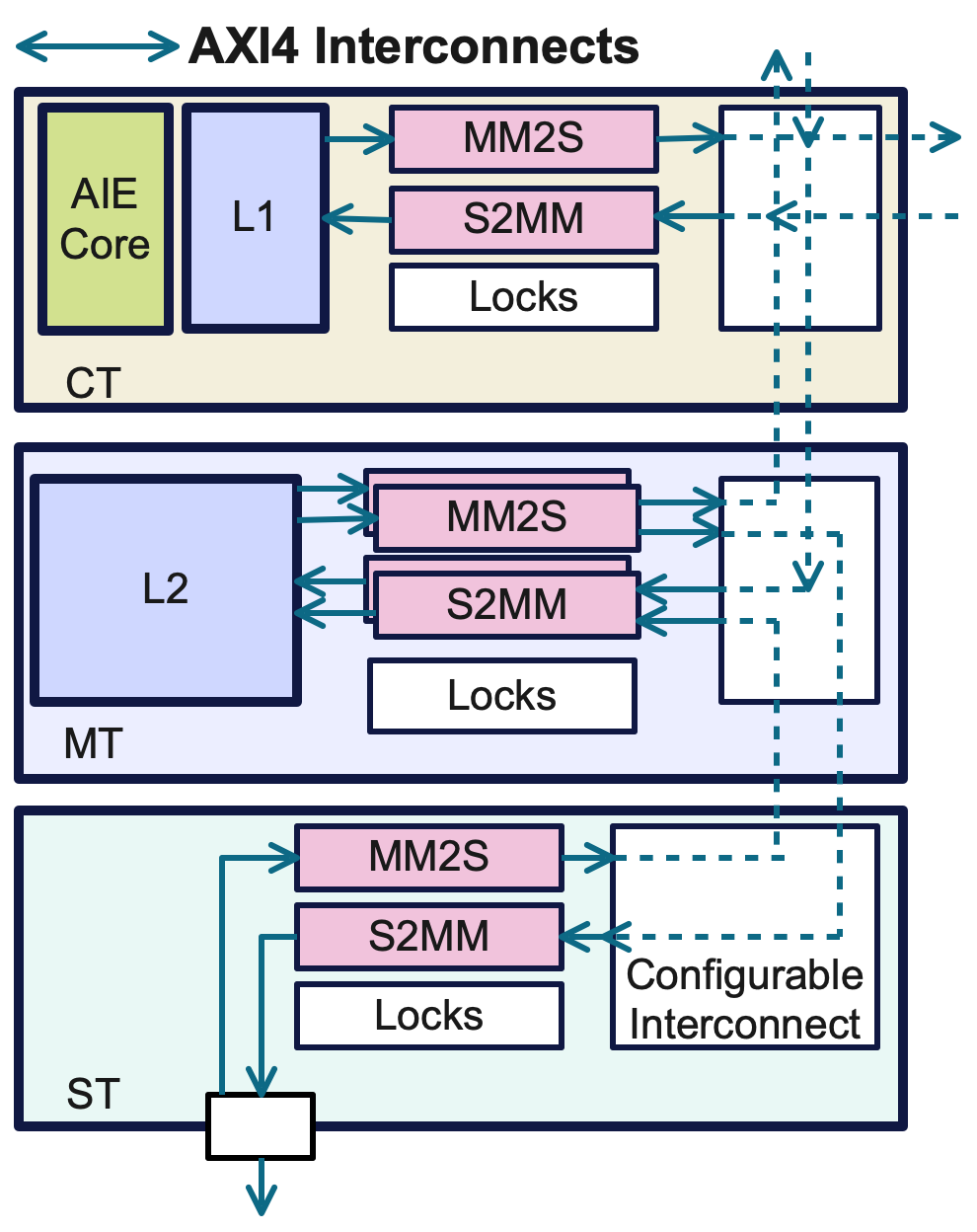
Вычислительные блоки (Compute Tiles, CT) и прямой доступ к памяти (Direct Memory Access, DMA) совместно оптимизируют операцию матричного умножения, являющуюся ключевой в большинстве слоев больших языковых моделей. DMA обеспечивает высокоскоростной перенос данных между оперативной памятью и локальной SRAM каждого CT, минимизируя задержки, связанные с доступом к памяти. CT, в свою очередь, параллельно обрабатывают данные, полученные через DMA, значительно увеличивая пропускную способность вычислений. Такая архитектура позволяет эффективно использовать локальную память для повторного использования данных, сокращая необходимость в частых обращениях к внешней памяти и, как следствие, повышая производительность и энергоэффективность.
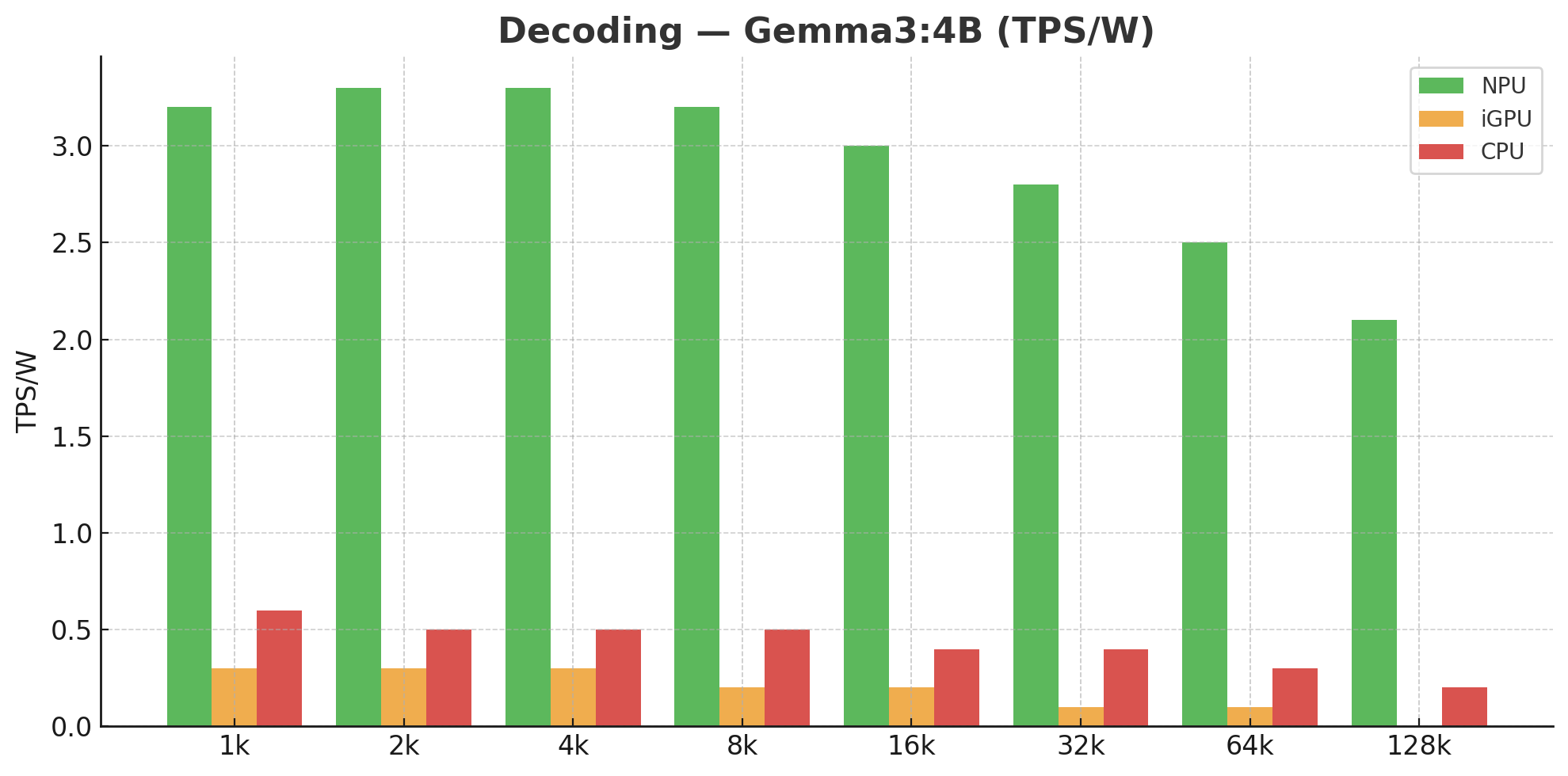
В ходе тестирования развернутая система с использованием NPU AMD Ryzen AI продемонстрировала значительное повышение эффективности обработки языковых моделей. Показатели производительности составили до 67.2-кратного ускорения в количестве обрабатываемых токенов в секунду на ватт (TPS/W) по сравнению с интегрированными графическими процессорами (iGPU) и до 222.9-кратного ускорения по сравнению с центральными процессорами (CPU). Данные результаты подтверждают существенные преимущества архитектуры NPU в задачах, требующих высокой производительности и энергоэффективности при обработке больших объемов текстовых данных.
AI Engine (AIE) представляет собой архитектуру межсоединений, обеспечивающую высокоскоростную коммуникацию между вычислительными блоками (Compute Tiles) в составе NPU. AIE использует детерминированные каналы связи и локальную память для минимизации задержек и максимизации пропускной способности передачи данных между CTs. Это позволяет эффективно реализовывать параллельные вычисления, необходимые для обработки больших матриц, являющихся основой большинства слоев в больших языковых моделях (LLM). AIE спроектирован для обеспечения предсказуемой производительности и снижения энергопотребления при передаче данных между вычислительными блоками, что критически важно для повышения общей эффективности NPU.
За Пределами Текста: Gemma3 и Мощь Мультимодального Искусственного Интеллекта
Модель Gemma3 демонстрирует передовые результаты в широком спектре задач, связанных с обработкой естественного языка. Благодаря внедренным оптимизациям, она обеспечивает значительное повышение эффективности в различных областях, включая генерацию текста, перевод, ответы на вопросы и анализ тональности. Эти улучшения позволяют Gemma3 превосходить существующие модели в скорости и точности, открывая новые возможности для создания более интеллектуальных и отзывчивых приложений. Особенно заметен прогресс в сложных задачах, требующих глубокого понимания контекста и генерации связного, осмысленного текста, что делает Gemma3 ценным инструментом для исследователей и разработчиков в области искусственного интеллекта.
Компонент «Vision Tower» значительно расширяет возможности Gemma3, позволяя модели обрабатывать и интерпретировать визуальную информацию. Это достигается за счет интеграции с существующей языковой моделью, что обеспечивает не просто распознавание изображений, но и понимание их содержания в контексте. В результате Gemma3 способна генерировать описания изображений, отвечать на вопросы, связанные с визуальным контентом, и даже создавать оригинальный контент, сочетающий текст и изображения. Такой мультимодальный подход открывает новые перспективы для приложений, требующих комплексного анализа данных, например, в области автоматической генерации контента, разработки интеллектуальных помощников и создания более интуитивно понятных интерфейсов взаимодействия человека и машины.
Механизм FlowKV представляет собой значительную оптимизацию процесса декодирования, критически важного для быстрой и точной генерации текста. В отличие от традиционных подходов, FlowKV эффективно управляет информацией о контексте, позволяя модели фокусироваться на наиболее релевантных данных при создании каждого нового токена. Это приводит к существенному снижению вычислительной нагрузки и ускорению генерации текста без потери качества. Особенно заметно влияние FlowKV при работе с длинными последовательностями, где поддержание контекста становится сложной задачей. Благодаря оптимизированному управлению памятью и эффективным алгоритмам, FlowKV обеспечивает стабильно высокую производительность и позволяет создавать более связные и логичные тексты.
В ходе исследований продемонстрировано значительное ускорение процесса декодирования при использовании AMD Ryzen AI NPU. В частности, для 4B модели, процессор обеспечивает ускорение до 60.6x по сравнению с iGPU и 13.2x — с CPU. Для более компактной 1B модели, прирост производительности составляет 20.4x относительно iGPU и 5.2x — относительно CPU. Такое существенное увеличение скорости обработки открывает новые перспективы для приложений, требующих оперативной генерации текста, позволяя значительно сократить время отклика и повысить общую эффективность системы.
Компонент Vision Tower демонстрирует значительное ускорение обработки визуальной информации. Исследования показывают, что его производительность на 1,7 раза выше, чем у интегрированных графических процессоров (iGPU), и в 8,7 раза превосходит возможности центрального процессора (CPU). Такое существенное увеличение скорости позволяет эффективно анализировать изображения и видео, открывая новые перспективы для приложений, связанных с компьютерным зрением и мультимодальными задачами, где требуется быстрая обработка и интерпретация визуальных данных.
Интеграция аппаратных и программных решений открывает принципиально новые горизонты для приложений, работающих с искусственным интеллектом. В частности, это позволяет создавать системы, способные не только понимать содержание изображений, но и генерировать связные и осмысленные текстовые описания — от автоматического создания подписей к фотографиям до ответов на вопросы, требующие визуального анализа. Более того, подобный симбиоз технологий стимулирует развитие креативных инструментов, способных создавать уникальный контент, объединяя визуальные элементы и текстовые нарративы, что расширяет возможности в области дизайна, искусства и развлечений.
Исследование демонстрирует, что оптимизация внимания и квантование моделей Gemma3 на архитектуре AMD Ryzen AI NPU позволяет добиться существенного прироста производительности. Подобный подход к реверс-инжинирингу аппаратных ограничений и адаптации алгоритмов — это не просто техническая задача, но и философское заявление о природе вычислений. Как отмечал Андрей Колмогоров: «Математика — это искусство открывать закономерности, скрытые в хаосе». В данном контексте, обнаружение оптимального баланса между точностью, скоростью и энергоэффективностью — это и есть выявление этих закономерностей, своего рода взлом системы для достижения максимальной эффективности. Каждый патч — это философское признание несовершенства, а каждое улучшение — подтверждение того, что даже самые сложные системы можно взломать умом.
Куда же дальше?
Представленная работа, по сути, лишь подтверждает старую истину: любая система имеет пределы, а её взлом — это не деструкция, а попытка понять её внутреннюю логику. Успешная имплементация Gemma3 на архитектуре, ориентированной на потоковую обработку данных, демонстрирует потенциал переноса сложных языковых моделей на периферию, но не решает фундаментальную проблему — ограниченность пропускной способности памяти. Оптимизация механизмов внимания и квантование — это лишь временные меры, позволяющие выжать максимум из существующих ресурсов.
Будущие исследования, вероятно, сосредоточатся на разработке принципиально новых подходов к архитектуре памяти, возможно, с использованием нетрадиционных материалов или топологий. Интересно, сможет ли кто-нибудь создать систему, где данные не перемещаются, а обрабатываются непосредственно там, где они хранятся? Или, может быть, нас ждёт эра алгоритмов, способных обходиться без памяти как таковой, извлекая знания непосредственно из «шума»?
В конечном счёте, эта работа — ещё один шаг на пути к созданию действительно интеллектуальных систем, способных к самообучению и адаптации. Но не стоит забывать, что главное — не скорость вычислений, а глубина понимания. И взлом, как форма познания, всегда будет важнее, чем слепое следование правилам.
Оригинал статьи: https://arxiv.org/pdf/2602.06063.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Самообучающиеся признаки: новый подход к машинному обучению
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Навыки агентов: Новый уровень интеллекта ИИ
- Наука на Автопилоте: Система для Самостоятельных Исследований
2026-02-10 06:23