Автор: Денис Аветисян
Исследователи представили TurningPoint-GRPO, фреймворк, позволяющий эффективно настраивать модели потокового соответствия для задач обучения с подкреплением, даже при редких сигналах вознаграждения.
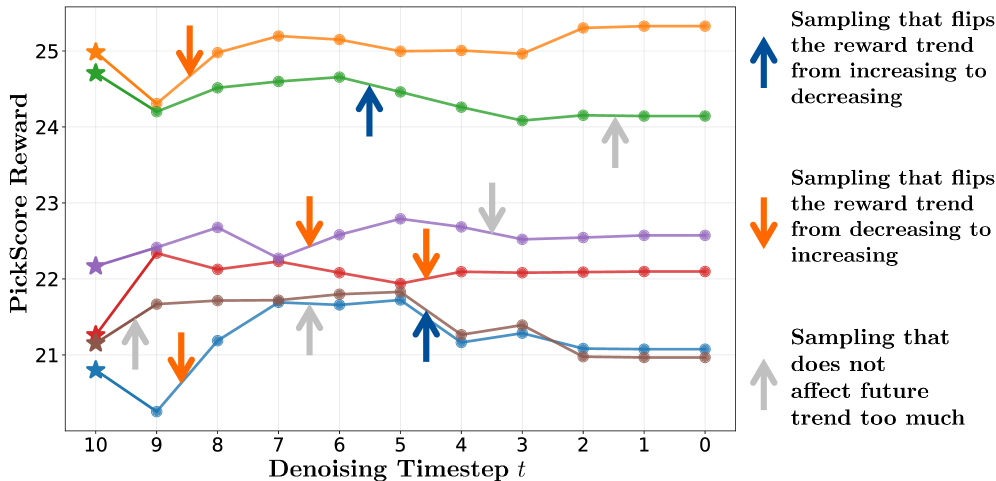
Предлагаемый подход учитывает пошаговое назначение вознаграждений и неявные взаимодействия между этапами шумоподавления для повышения производительности.
Существующие методы обучения генеративных моделей часто сталкиваются с проблемой разреженных сигналов вознаграждения, затрудняющих эффективную оптимизацию траекторий. В данной работе, посвященной теме ‘Alleviating Sparse Rewards by Modeling Step-Wise and Long-Term Sampling Effects in Flow-Based GRPO’, предложен фреймворк TurningPoint-GRPO (TP-GRPO), направленный на смягчение этой проблемы путем более точного моделирования влияния каждого шага денойзинга и учета скрытых взаимодействий между ними. TP-GRPO вводит пошаговое вознаграждение и выявляет ключевые точки перелома, определяющие долгосрочное влияние действий на итоговый результат. Позволит ли предложенный подход значительно повысить качество генерации изображений и открыть новые горизонты в области обучения генеративных моделей с подкреплением?
Разреженное Вознаграждение: Почему Обучение Генеративных Моделей — Это Боль
Генеративные модели, использующие методы вроде Flow Matching, часто сталкиваются с проблемой разреженности вознаграждения, что существенно затрудняет эффективное обучение стратегии. Данная проблема возникает из-за того, что многие шаги в процессе генерации могут не приводить к немедленному или явному сигналу вознаграждения, создавая трудности для алгоритмов обучения с подкреплением. В результате, модель испытывает сложности с определением, какие действия способствуют достижению желаемого результата, что замедляет процесс обучения и может приводить к неоптимальным политикам. По сути, разреженность вознаграждения требует от модели способности к долгосрочному планированию и обнаружению тонких связей между действиями и последующими результатами, что является непростой задачей в контексте сложных генеративных процессов.
Традиционные методы обучения с подкреплением сталкиваются с серьезными трудностями при работе с редкими или отложенными вознаграждениями. В таких ситуациях, когда положительный сигнал появляется лишь спустя значительное количество шагов, алгоритмам крайне сложно установить связь между предпринятыми действиями и полученным результатом. Это приводит к замедлению процесса обучения, поскольку агенту необходимо исследовать огромное пространство состояний, прежде чем случайно обнаружить последовательность действий, приводящую к вознаграждению. В итоге, даже после длительного обучения, политика может оставаться субоптимальной, неспособной эффективно использовать имеющиеся ресурсы и достигать наилучших результатов. Отсутствие немедленной обратной связи существенно снижает эффективность обучения и требует разработки специализированных методов для преодоления этой проблемы.
Проблема разреженности вознаграждения в генеративном моделировании возникает из-за того, что значительная часть промежуточных шагов процесса генерации может не вносить ощутимого вклада в итоговый сигнал вознаграждения. Иными словами, модель часто совершает множество действий, которые сами по себе не приводят к немедленному улучшению результата, что затрудняет обучение с подкреплением. Это особенно актуально для сложных генеративных задач, где связь между отдельными действиями и конечной целью может быть неявной и отложенной во времени. Вследствие этого, алгоритмы обучения сталкиваются с трудностями в определении, какие действия действительно способствуют достижению желаемого результата, что замедляет процесс обучения и может приводить к неоптимальным политикам генерации.
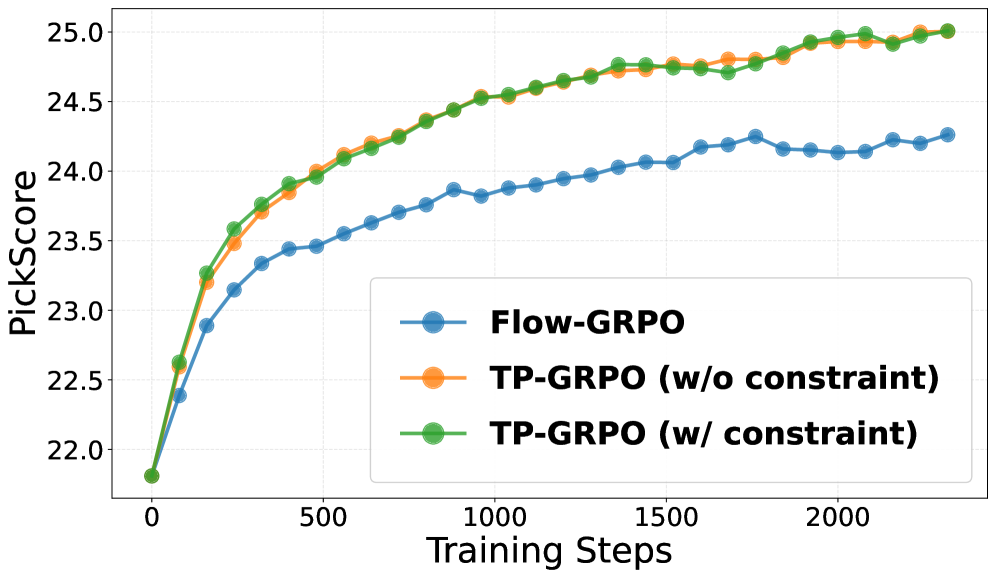
TurningPoint-GRPO: Когда Инновации Спасают Обучение
TurningPoint-GRPO (TP-GRPO) является расширением подхода Flow-GRPO и отличается использованием инкрементных вознаграждений, основанных на изменениях траектории генерации. В отличие от Flow-GRPO, где вознаграждение может быть получено только по завершении определенного этапа, TP-GRPO предоставляет промежуточные вознаграждения за каждое изменение направления траектории. Это достигается путем непрерывного мониторинга и оценки изменений в процессе генерации, что позволяет системе быстрее адаптироваться и улучшать свою производительность, особенно в задачах с длинными последовательностями действий. Использование инкрементных вознаграждений позволяет более эффективно формировать желаемое поведение модели и ускоряет процесс обучения.
Основная концепция TurningPoint-GRPO заключается в идентификации “точек перелома” — шагов в траектории генерации, где происходит значительное изменение направления — и последующем назначении вознаграждения на основе этих изменений. Определение точки перелома осуществляется путем анализа изменения вектора траектории между последовательными шагами; значительное отклонение от предыдущего направления указывает на наличие точки перелома. Вознаграждение, присваиваемое в этих точках, пропорционально величине изменения направления, что позволяет алгоритму фокусироваться на критических моментах в процессе генерации и более эффективно обучаться. Данный подход позволяет выделить и усилить сигналы, связанные с важными решениями, принимаемыми агентом, даже если непосредственный эффект от этих решений проявляется не сразу.
Метод TurningPoint-GRPO обеспечивает более плотный сигнал вознаграждения за счет акцентирования на ключевых точках изменения траектории генерации. Это позволяет ускорить процесс обучения и повысить эффективность политики. В традиционных подходах вознаграждение может быть редким и запаздывающим, что затрудняет установление связи между действиями и их последствиями. TP-GRPO, напротив, направляет обучение на моменты значительных изменений, предоставляя более частые и информативные сигналы, что способствует более быстрой сходимости и улучшению итоговых результатов. Более плотный сигнал вознаграждения позволяет агенту более эффективно исследовать пространство действий и оптимизировать свою политику.
Моделирование ‘скрытого взаимодействия’ в TurningPoint-GRPO основывается на признании того, что начальные состояния и действия могут оказывать существенное, но отложенное влияние на последующие шаги генеративной траектории. В отличие от подходов, ориентированных исключительно на немедленное вознаграждение, TP-GRPO учитывает, что значимость определенных состояний может проявиться лишь спустя несколько шагов. Это достигается путем анализа всей траектории и выявления корреляций между ранними состояниями и последующими изменениями в направлении генерации, позволяя системе извлекать ценную информацию из кажущихся нерелевантными на первый взгляд этапов процесса. По сути, система стремится выявить долгосрочные последствия ранних действий, что способствует более эффективному обучению и улучшению общей производительности.
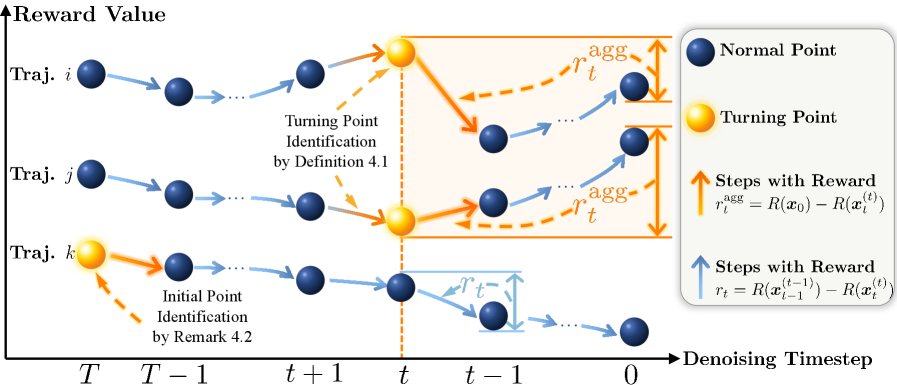
Инкрементальное Вознаграждение и Оптимизация Политики: Практика
Алгоритм TP-GRPO использует ‘Инкрементальную оценку влияния’ (Incremental Effect-Based Reward), которая рассчитывается как разница в полученном вознаграждении до и после каждого шага дискретизации стохастического дифференциального уравнения (SDE). Эта оценка позволяет точно определить вклад каждого шага SDE в общую награду, что критически важно для оптимизации траекторий. Вместо оценки награды за всю траекторию, TP-GRPO оценивает влияние каждого отдельного шага, что обеспечивает более гранулярный и эффективный процесс обучения. Reward_{incremental} = Reward_{after} - Reward_{before} — данная формула отражает принцип расчета инкрементальной награды, где Reward_{before} — вознаграждение до шага SDE, а Reward_{after} — вознаграждение после него.
Поворотные точки (Turning Points) в алгоритме TP-GRPO получают награду в виде «Агрегированной Долгосрочной Награды», отражающей их кумулятивное влияние на последующие сегменты траектории. Эта награда рассчитывается путем суммирования изменений в награде, наблюдаемых после каждого шага дискретного стохастического дифференциального уравнения (SDE), начиная с момента возникновения поворотной точки. Фактически, R_{TP} = \sum_{t=t_0}^{T} \Delta r_t, где r_t — награда на шаге t, \Delta r_t — изменение награды на этом шаге, а t_0 — момент возникновения поворотной точки. Использование агрегированной награды позволяет алгоритму учитывать отложенные эффекты действий, совершенных в этих ключевых точках, и более эффективно направлять процесс оптимизации политики.
Сигнал вознаграждения, рассчитанный на основе инкрементального эффекта, интегрируется в структуру Group Relative Policy Optimization (GRPO) для направления исследования политики. GRPO использует этот сигнал вознаграждения для оценки и корректировки политики, способствуя генерации траекторий с более высокой кумулятивной наградой. В процессе оптимизации, GRPO сравнивает производительность различных действий, основываясь на полученном сигнале вознаграждения, и корректирует параметры политики для увеличения вероятности выбора действий, приводящих к более желаемым результатам. Этот процесс позволяет алгоритму эффективно исследовать пространство политик и находить оптимальные решения, максимизирующие кумулятивную награду на протяжении всей траектории.
В ходе проведения оценки на трех задачах — генерация композиционных изображений, соответствие предпочтениям пользователей и визуализация текста — алгоритм TP-GRPO демонстрирует стабильное превосходство над базовым алгоритмом Flow-GRPO. Результаты экспериментов показывают, что применение ‘Incremental Effect-Based Reward’ и оптимизация политики на основе Turning Points позволяют TP-GRPO достигать более высоких показателей эффективности в различных областях, подтверждая его преимущества в задачах, требующих генерации и оптимизации траекторий.
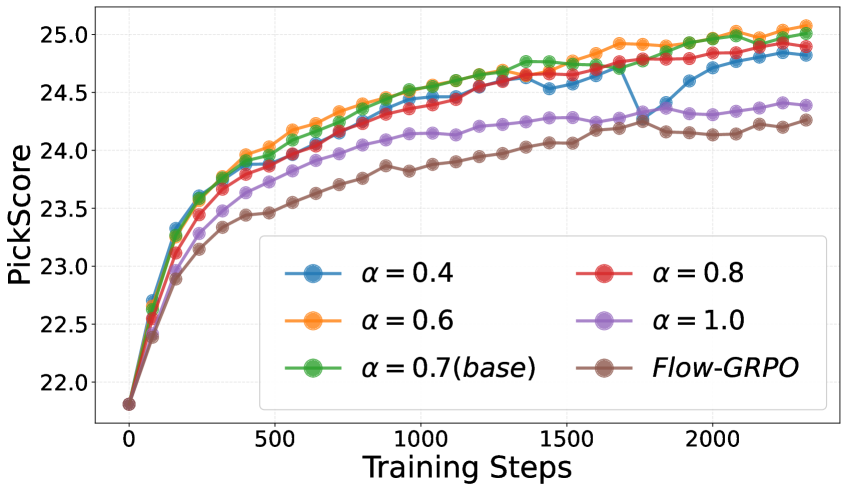
Flow Matching и Разнообразная Генерация Траекторий: Суть Метода
В основе TP-GRPO лежит методика Flow Matching — мощный инструмент генеративного моделирования, который определяет траектории посредством выученного поля скоростей. Этот подход позволяет создавать новые данные, описывая непрерывный путь в пространстве признаков, подобно движению частицы под воздействием сил. По сути, Flow Matching формирует “поток”, направляющий процесс генерации от начальной точки к целевому распределению данных. Выученное поле скоростей задает направление и скорость движения по этому потоку, обеспечивая возможность как разнообразной выборки, используя стохастические дифференциальные уравнения SDE, так и детерминированной генерации с помощью обыкновенных дифференциальных уравнений ODE. Именно эта гибкость и позволяет TP-GRPO эффективно решать сложные задачи генерации, превосходя традиционные методы по качеству и разнообразию получаемых результатов.
В основе метода Flow Matching лежит использование как стохастических дифференциальных уравнений (СДУ), так и обыкновенных дифференциальных уравнений (ОДУ) для генерации данных. СДУ обеспечивают возможность создания разнообразных образцов благодаря введению случайного элемента в процесс генерации. Это позволяет исследовать широкий спектр возможных решений и избегать застревания в локальных оптимумах. В то же время, ОДУ позволяют осуществлять детерминированную генерацию, обеспечивая воспроизводимость и предсказуемость результатов. Комбинируя эти два подхода, Flow Matching получает возможность контролировать баланс между разнообразием и точностью генерируемых данных, что особенно важно в задачах, требующих как креативности, так и соответствия заданным условиям. dX = f(X, t)dt + g(X, t)dW — эта формула отражает ключевой принцип использования СДУ, где dX — изменение состояния, f — дрифт, g — диффузия, а dW — винеровский процесс, обеспечивающий случайность.
Оптимизация политики в рамках предложенного подхода TP-GRPO позволяет получать разнообразные и высококачественные образцы, существенно превосходя традиционные генеративные модели. В частности, в задачах композиционной генерации изображений, данный метод эффективно решает проблемы, связанные с некорректным формированием объектов и потерей деталей. Традиционные модели часто испытывают трудности с точным воспроизведением сложных сцен, что приводит к появлению артефактов или нереалистичных элементов. TP-GRPO, за счет оптимизированной политики, обеспечивает более точное и последовательное создание изображений, сохраняя при этом детализацию и реалистичность, что особенно важно для создания визуально привлекательного и правдоподобного контента.
Исследования показали, что предлагаемый метод значительно повышает точность визуализации текста. В отличие от Flow-GRPO, он эффективно решает проблему пропусков коротких слов и наложения символов, обеспечивая более четкое и разборчивое отображение текста. Кроме того, отмечается улучшенная детализация изображений и более точное следование подразумеваемым структурам запросов, что особенно важно при согласовании с предпочтениями пользователей. Данные результаты демонстрируют способность метода создавать визуализации, которые не только технически корректны, но и соответствуют ожиданиям и эстетическим предпочтениям человека, что открывает новые возможности для применения в задачах генерации изображений по текстовому описанию.
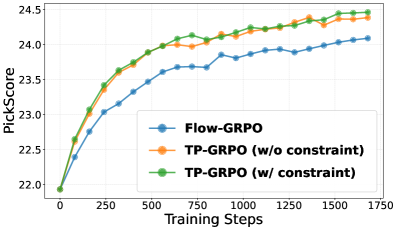
Исследование демонстрирует, что даже самые изящные теоретические конструкции, такие как flow matching, сталкиваются с суровой реальностью редких вознаграждений в процессе обучения с подкреплением. Авторы предлагают TurningPoint-GRPO — попытку обмануть систему, более точно моделируя распределение вознаграждений на каждом шаге и учитывая неявные взаимодействия между ними. Как метко заметил Дэвид Марр: «Если код выглядит идеально — значит, его никто не деплоил». В данном случае, стремление к идеальному моделированию вознаграждений — это, вероятно, признак того, что модель еще предстоит проверить в реальных условиях. Иначе говоря, элегантность теории — это прекрасно, но продукшен всегда найдет способ напомнить о технических долгах.
Что дальше?
Представленный подход, безусловно, элегантен в своей попытке обуздать разреженные награды через моделирование шагов и неявных взаимодействий. Однако, как показывает опыт, любая абстракция рано или поздно встретит суровую реальность продакшена. Сложность, присущая оптимизации траекторий, не исчезнет, она лишь приобретет новые формы. Вопрос не в том, чтобы идеально предсказать награду на каждом шаге, а в том, чтобы создать систему, устойчивую к её непредсказуемости.
Очевидно, что дальнейшие исследования должны быть направлены на повышение робастности TurningPoint-GRPO к шуму и неточностям в данных. Более того, необходимо учитывать вычислительные издержки, связанные с моделированием сложных взаимодействий. В конце концов, всё, что можно задеплоить, однажды упадёт. И вопрос лишь в том, насколько красиво это произойдёт.
Вероятно, следующей ступенью станет интеграция с другими методами обучения с подкреплением, возможно, с использованием техник, направленных на исследование пространства состояний. Или же, более прагматичный путь — создание инструментов, позволяющих оперативно диагностировать и устранять возникающие проблемы в реальных условиях эксплуатации. Ведь, как известно, даже самая изящная теория бесполезна, если она не работает.
Оригинал статьи: https://arxiv.org/pdf/2602.06422.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Самообучающиеся признаки: новый подход к машинному обучению
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Робот-исследователь: новый подход к автономной навигации
- Иллюзия Компетентности: Как ИИ Переоценивает Себя
2026-02-10 07:53