Автор: Денис Аветисян
Новый подход к масштабированию времени вывода позволяет существенно повысить эффективность и надежность искусственного интеллекта, работающего непосредственно на устройствах.
Представлена структура QEIL для анализа и оптимизации масштабирования времени вывода на гетерогенном оборудовании (CPU, GPU, NPU) с акцентом на безопасность и энергоэффективность.
Развертывание крупных языковых моделей на периферийных устройствах с ограниченными ресурсами осложняется недостаточным пониманием масштабирования времени вывода на гетерогенном оборудовании. В данной работе, ‘Quantifying Edge Intelligence: Inference-Time Scaling Formalisms for Heterogeneous Computing’, представлена система QEIL — унифицированный подход к характеристике и оптимизации вычислений на CPU, GPU и NPU. Установлено, что модели-трансформеры демонстрируют стабильное степенное масштабирование задержки, энергопотребления и покрытия задач, а гетерогенная оркестровка значительно повышает энергоэффективность. Может ли QEIL стать основой для создания надежного и эффективного периферийного искусственного интеллекта, способного к адаптации и самооптимизации в реальных условиях?
Вызов эффективного инференса на периферии
Современный искусственный интеллект, и в особенности архитектура Transformer, демонстрирует впечатляющие возможности в решении сложных задач, от обработки естественного языка до компьютерного зрения. Однако, эта мощь достигается ценой значительных вычислительных затрат. Модели Transformer, характеризующиеся большим количеством параметров и сложными матричными операциями, требуют огромных объемов памяти и высокой производительности процессоров для эффективной работы. Это создает серьезные препятствия для их развертывания в устройствах с ограниченными ресурсами, таких как мобильные телефоны, дроны или встроенные системы, где энергоэффективность и скорость отклика являются критически важными. Необходимость в оптимизации этих моделей для снижения вычислительной нагрузки становится ключевой задачей в развитии прикладного ИИ.
Развертывание современных моделей искусственного интеллекта, особенно сложных трансформаторных сетей, на периферийных устройствах с ограниченными ресурсами представляет собой серьезную проблему. Ограниченная вычислительная мощность и энергоэффективность этих устройств приводят к значительному увеличению задержки при обработке данных, что делает невозможным применение моделей в задачах, требующих мгновенного отклика. Кроме того, высокое энергопотребление сокращает время автономной работы устройств, а общая эффективность вычислений снижается из-за необходимости оптимизации моделей для работы на менее мощном оборудовании. Поэтому, для успешного внедрения ИИ на периферии требуется разработка инновационных подходов к оптимизации моделей и снижению их требований к ресурсам.
Традиционные методы развертывания моделей искусственного интеллекта на периферийных устройствах зачастую оказываются неэффективными из-за ограничений вычислительных ресурсов и энергопотребления. Это приводит к неприемлемой задержке обработки данных, что критически важно для приложений, требующих мгновенной реакции — например, в системах автономного вождения, роботизированной хирургии или анализе данных в режиме реального времени. Вследствие этого, возможности передовых алгоритмов, таких как трансформеры, остаются нереализованными в сценариях, где необходима оперативная обработка информации непосредственно на устройстве, а не в облаке. Неспособность обеспечить необходимую скорость и эффективность работы препятствует широкому внедрению интеллектуальных систем в различные сферы жизни.
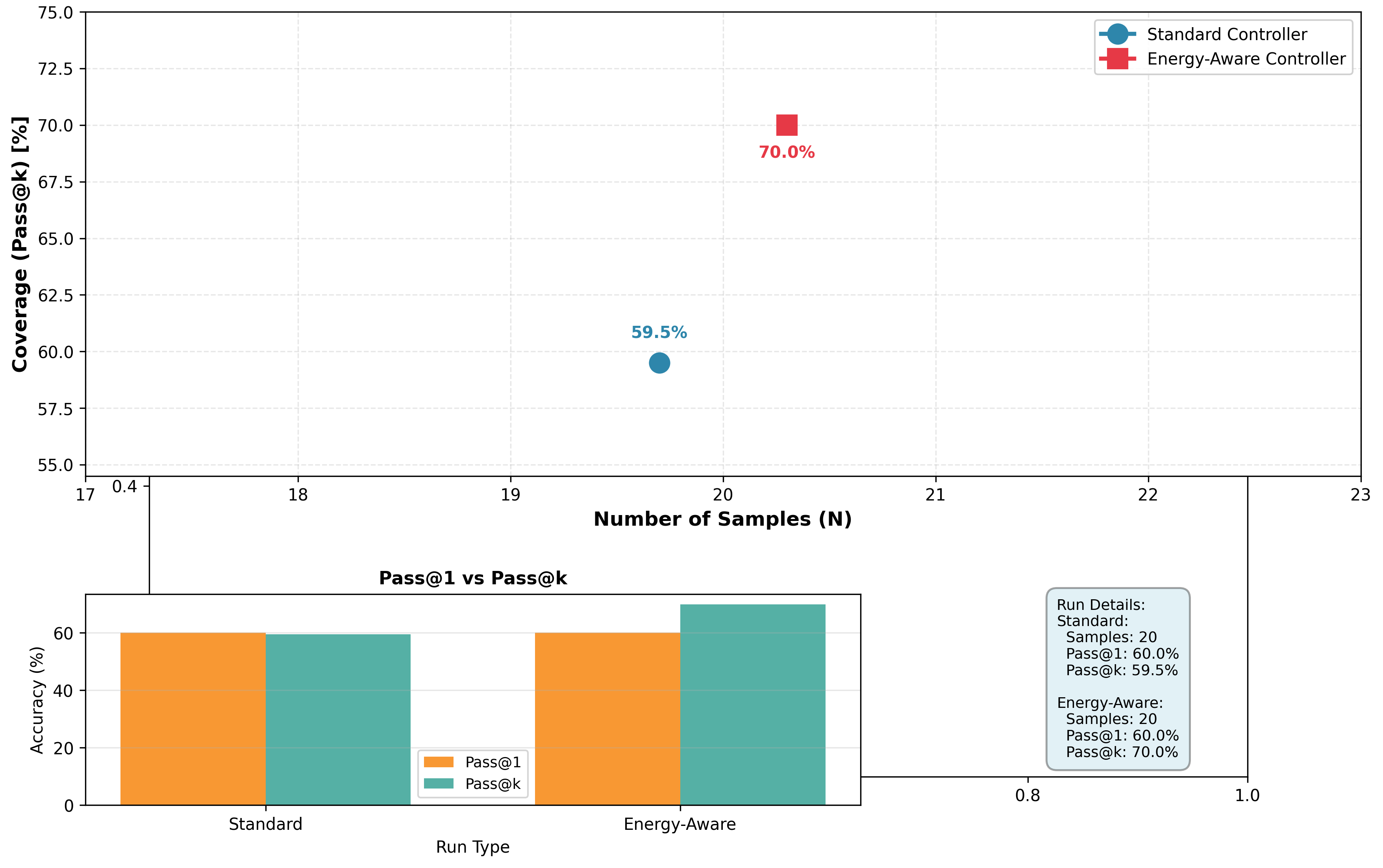
Характеристика масштабируемости инференса
Понимание взаимосвязи между масштабом модели, параметрами аппаратного обеспечения и производительностью является критически важным для оптимизации. Увеличение размера модели, как правило, приводит к повышению точности, однако требует пропорционального увеличения вычислительных ресурсов и памяти. Оптимизация требует тщательного анализа влияния различных аппаратных параметров — таких как количество ядер CPU/GPU, объем памяти, пропускная способность шин данных — на производительность модели при различных масштабах. Эффективное использование этих ресурсов позволяет достичь оптимального баланса между точностью и скоростью работы, избегая узких мест и максимизируя пропускную способность. Недостаточная оптимизация может привести к неэффективному использованию аппаратных ресурсов и, как следствие, к увеличению задержки и снижению общей производительности системы.
Формализмы масштабирования, определяемые ключевыми показателями масштабирования (Scaling Exponents), представляют собой эмпирически подтвержденные соотношения, позволяющие прогнозировать изменения производительности. Эти показатели, полученные в результате обширных экспериментов, устанавливают количественные связи между размером модели, параметрами аппаратного обеспечения и наблюдаемой производительностью. Например, изменение размера модели может приводить к предсказуемым изменениям задержки или пропускной способности, которые можно смоделировать с использованием этих показателей. Использование формализмов масштабирования позволяет оценить, как изменения в архитектуре модели или конфигурации аппаратного обеспечения повлияют на производительность, не прибегая к дорогостоящим экспериментальным измерениям. y = a * x^b — пример такого соотношения, где y — показатель производительности, x — размер модели, а b — показатель масштабирования.
Разработанные формализмы позволяют точно характеризовать эффективность инференса на различных аппаратных конфигурациях, что открывает возможности для целенаправленной оптимизации. В ходе исследований было зафиксировано стабильное улучшение метрики pass@k на 66.5%-70.0% при использовании этих формализмов для широкого спектра моделей на основе архитектуры Transformer. Это демонстрирует их применимость и эффективность в прогнозировании и улучшении производительности инференса в различных сценариях.
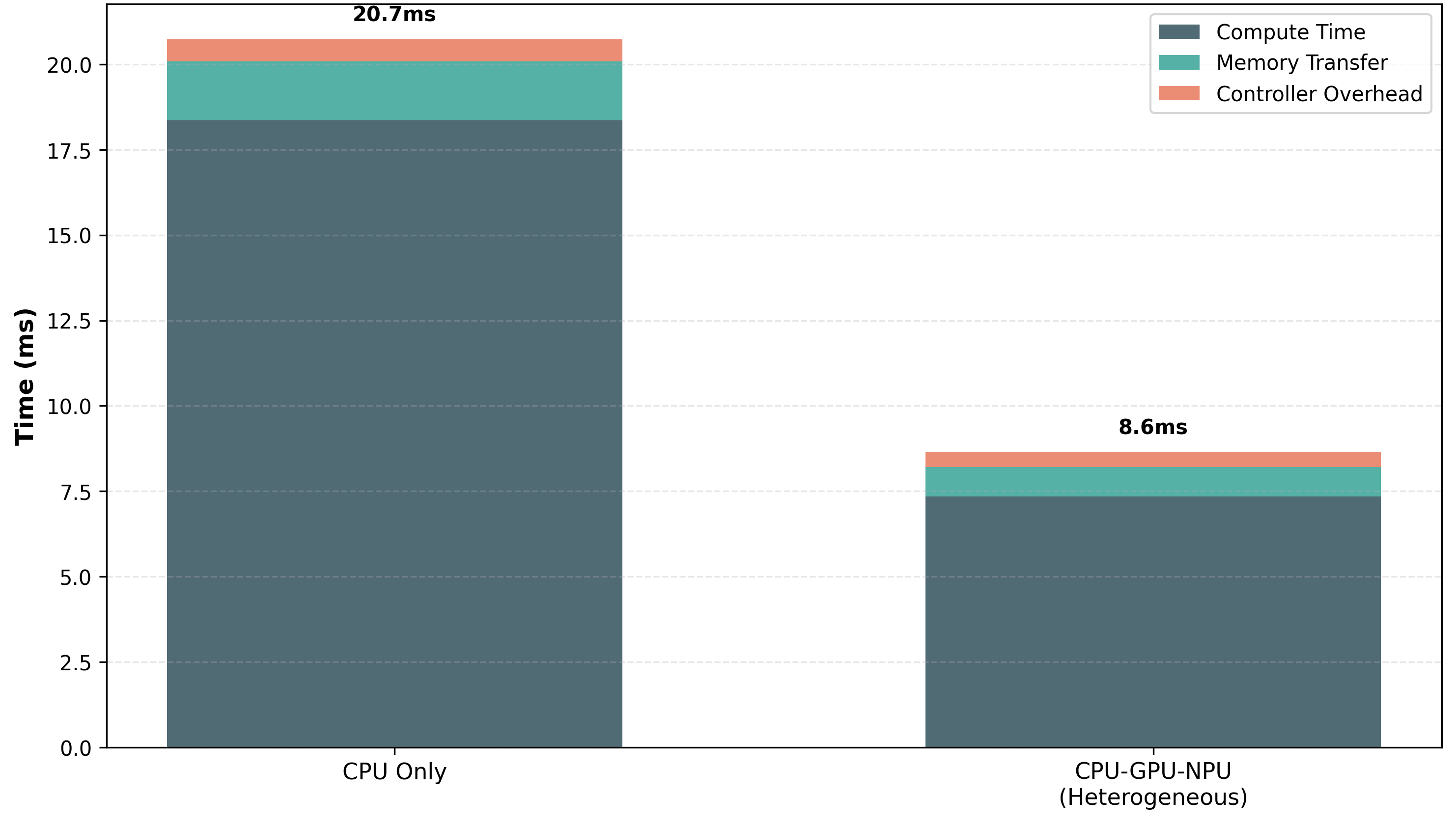
Гетерогенная оркестровка для оптимизированной производительности
Гетерогенное оркестрование использует преимущества различных аппаратных ускорителей — процессоров (CPU), графических процессоров (GPU) и нейронных процессоров (NPU) — для повышения скорости вывода (inference). Вместо использования однородной вычислительной среды, гетерогенный подход позволяет распределять вычислительную нагрузку между устройствами, оптимизированными для определенных типов операций. CPU эффективно обрабатывают задачи общего назначения и управление потоком данных, GPU превосходно справляются с параллельными вычислениями, необходимыми для глубокого обучения, а NPU специализируются на операциях, связанных с нейронными сетями, обеспечивая максимальную производительность и энергоэффективность. Такое распределение позволяет значительно ускорить процесс вывода, особенно для сложных моделей машинного обучения.
Методы, такие как жадный алгоритм назначения слоев (Greedy Layer Assignment) и динамическая оркестровка (Dynamic Orchestration), обеспечивают интеллектуальное распределение слоев нейронной сети на наиболее подходящие вычислительные устройства. Жадный алгоритм назначает каждый слой на устройство, обеспечивающее максимальную производительность для данного конкретного слоя в текущий момент времени. Динамическая оркестровка, в свою очередь, непрерывно отслеживает загрузку устройств и перераспределяет слои во время выполнения, оптимизируя общую производительность системы и минимизируя задержки. Данный подход позволяет эффективно использовать ресурсы различных аппаратных ускорителей — CPU, GPU и NPU — для достижения оптимальной скорости инференса.
Применение гетерогенной оркестровки позволяет значительно повысить эффективность инференса, особенно для сложных моделей. В ходе тестирования наша платформа продемонстрировала среднее снижение задержки на 15.8% и увеличение показателя Pass@k Coverage на 7-10.5 процентных пункта по различным моделям. Данные улучшения достигаются за счет оптимального распределения вычислительной нагрузки между CPU, GPU и NPU, что обеспечивает максимальную пропускную способность и минимальную задержку при выполнении задач инференса.
Безопасность прежде всего: надежный дизайн для периферийных вычислений
Периферийные устройства, функционирующие непосредственно в реальном мире, часто сталкиваются с непредсказуемыми условиями эксплуатации — колебаниями температуры, перепадами напряжения, воздействием пыли и влаги, а также потенциальными кибератаками. В связи с этим, принципы надёжной разработки становятся критически важными для обеспечения стабильной и безопасной работы. Конструкция этих устройств должна предусматривать защиту от внешних факторов и внутренних сбоев, гарантируя непрерывность работы даже в экстремальных ситуациях. Устойчивость к неблагоприятным условиям не только повышает долговечность оборудования, но и является ключевым фактором для успешного развертывания и поддержания доверия к интеллектуальным системам, работающим на периферии сети.
Принципы разработки, ориентированные на безопасность, ставят надежность краеугольным камнем функционирования периферийных устройств. В частности, защита от перегрева, обеспечивающая стабильную работу даже при повышенных температурах окружающей среды, играет ключевую роль. Не менее важна устойчивость к сбоям, позволяющая системе продолжать функционирование даже при возникновении аппаратных или программных ошибок. Наконец, защита от злонамеренных воздействий, или «adversarial robustness», гарантирует, что устройство не будет подвержено манипуляциям или взлому. Интеграция этих механизмов позволяет создавать периферийные системы, способные безотказно работать в самых сложных и непредсказуемых условиях, что критически важно для доверия к решениям, основанным на искусственном интеллекте на границе сети.
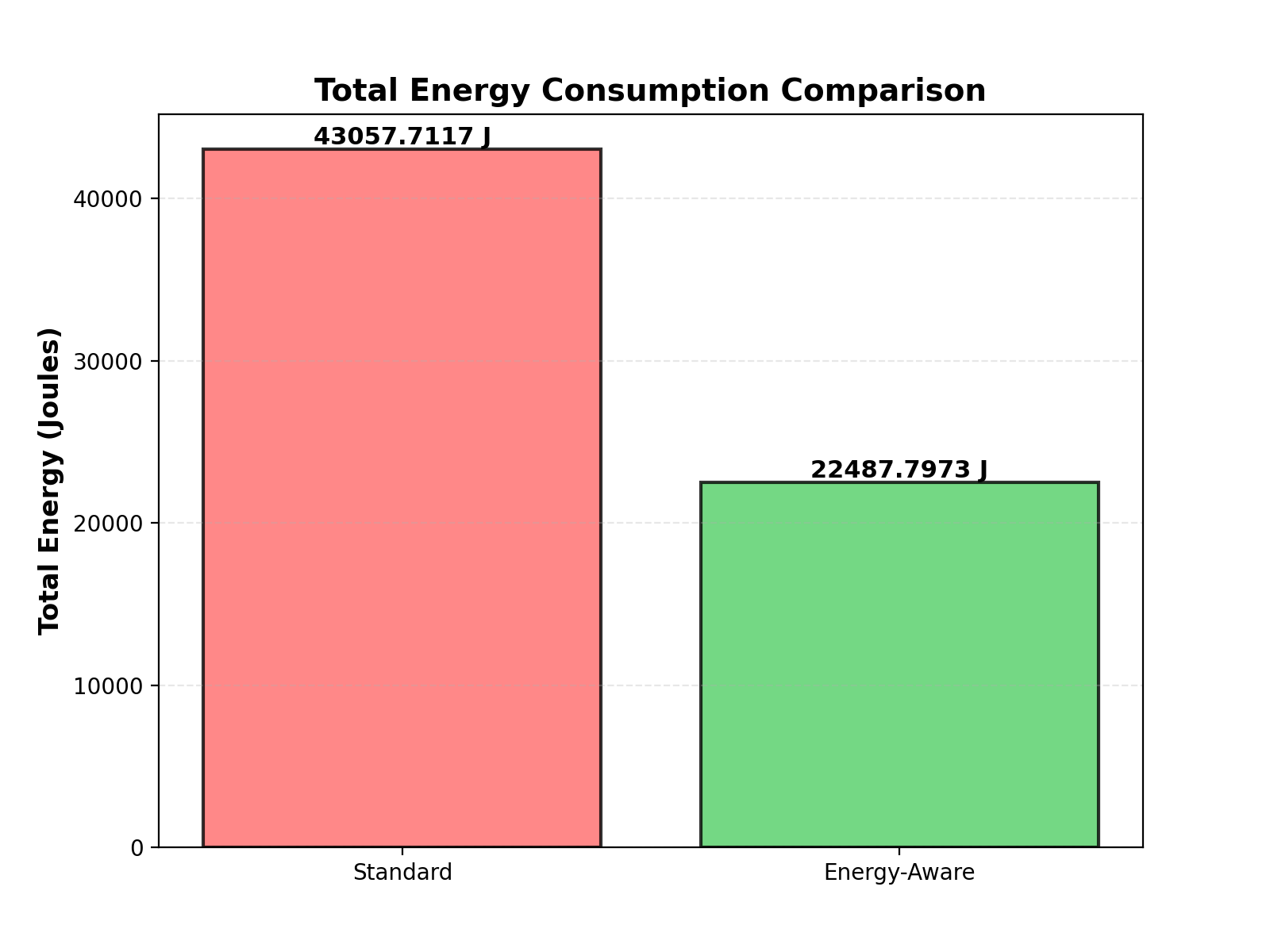
Интеграция принципов отказоустойчивости, защиты от неблагоприятных условий и обеспечения безопасности позволяет создавать периферийные вычислительные системы, способные стабильно и надежно функционировать даже в самых сложных условиях эксплуатации. Разработанная платформа демонстрирует 100%-ное восстановление после сбоев, что гарантирует непрерывность работы критически важных приложений. Более того, оптимизация энергопотребления позволила снизить его на 68%, доведя диапазон потребляемой мощности до 75-84 Вт, что делает систему экономичной и подходящей для развертывания в условиях ограниченных ресурсов. Такой подход формирует доверие к решениям периферийного искусственного интеллекта, подтверждая их надежность и предсказуемость.
QEIL: целостный фреймворк для интеллектуальных вычислений на периферии
Разработанный комплексный фреймворк QEIL (Quantified Edge Inference Lifecycle) представляет собой целостный подход к разработке и развертыванию интеллектуальных приложений на периферии сети. Он объединяет в себе три ключевых аспекта: характеристику масштабируемости, позволяющую оптимизировать производительность в различных условиях; гетерогенную оркестровку, эффективно использующую разнородные вычислительные ресурсы; и проектирование с приоритетом безопасности, обеспечивающее надежную и устойчивую работу системы. В результате, QEIL позволяет добиться значительного повышения эффективности использования ресурсов и снижения энергопотребления, что особенно важно для устройств с ограниченным питанием и вычислительной мощностью, открывая путь к созданию более интеллектуальных и отзывчивых периферийных устройств.
Применение фреймворка QEIL позволяет разработчикам существенно оптимизировать работу приложений искусственного интеллекта на периферийных устройствах. Исследования демонстрируют значительное снижение задержки обработки данных, что критически важно для приложений, требующих мгновенной реакции, таких как автономные системы или промышленная автоматизация. Одновременно с этим, QEIL обеспечивает снижение энергопотребления, продлевая срок службы батарей и снижая эксплуатационные расходы. Более того, фреймворк повышает надежность работы приложений за счет комплексного подхода к проектированию и управлению ресурсами, что особенно важно для критически важных систем, где сбои недопустимы. В результате, QEIL открывает возможности для создания более эффективных, экономичных и надежных решений в области периферийных вычислений.
Реализация целостного подхода, представленного QEIL, открывает новые возможности для периферийных вычислений, способствуя созданию принципиально нового поколения интеллектуальных и оперативно реагирующих устройств. Проведенные исследования демонстрируют значительное повышение эффективности: показатель «Интеллект на Ватт» увеличивается в 4.8-5.6 раза, а общее энергопотребление снижается на 47-78% в сравнении с однородными системами. Более того, комплексная оценка, учитывающая цену, мощность и производительность (PPP), показывает в среднем 39%-ное улучшение, что свидетельствует о значительном повышении экономической целесообразности и эффективности развертывания интеллектуальных приложений на периферийных устройствах.
Представленная работа демонстрирует стремление к математической строгости в области периферийных вычислений. Авторы, подобно тем, кто ищет элегантность в коде, фокусируются на формализации масштабирования времени вывода, стремясь к доказуемой эффективности и надёжности. В частности, подход QEIL, предложенный в статье, подчеркивает важность оптимизации распределения задач между разнородными вычислительными устройствами (CPU, GPU, NPU) с учётом ограничений по энергопотреблению и безопасности. Как отмечал Андрей Колмогоров: «Математика — это искусство открывать закономерности, скрытые в хаосе». Эта работа, стремясь к формализации масштабирования времени вывода, находит закономерности в сложном ландшафте периферийных вычислений, обеспечивая возможность создания более эффективных и надёжных систем искусственного интеллекта.
Куда же дальше?
Представленная работа, хоть и демонстрирует формализацию масштабирования времени вывода для гетерогенных вычислений, всё же оставляет ряд вопросов без ответа. Упор на безопасность, безусловно, похвален, однако его интеграция с динамически меняющимися условиями эксплуатации — задача, требующая дальнейшего исследования. Неизбежно возникает вопрос о компромиссе между абсолютной надёжностью и допустимым уровнем риска, особенно в сценариях, где ресурсы ограничены. Предлагаемые метрики эффективности, хоть и полезны, пока не учитывают в полной мере стоимость обслуживания и обновления моделей на периферии сети.
Будущие исследования должны быть направлены на разработку алгоритмов, способных к самооптимизации и адаптации к меняющимся условиям окружающей среды. При этом необходимо помнить, что эвристические подходы — это лишь временные решения, маскирующие недостатки в фундаментальном понимании проблемы. Истинная элегантность заключается не в скорости достижения результата, а в математической чистоте и доказуемости алгоритма. Просто “работающий” код — это лишь иллюзия, а не решение.
Очевидно, что переход к полностью автономным периферийным системам требует не только улучшения аппаратного обеспечения, но и разработки принципиально новых методов верификации и валидации моделей. Следует помнить, что безопасность — это не просто свойство системы, а непрерывный процесс, требующий постоянного внимания и контроля.
Оригинал статьи: https://arxiv.org/pdf/2602.06057.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Квантовая запутанность спиновых кубитов: новый резонансный подход
- Табулярные данные: новый взгляд на обучение без учителя
2026-02-10 08:05