Автор: Денис Аветисян
Исследователи предлагают инновационный метод обучения, позволяющий мультимодальным моделям эффективнее обрабатывать информацию из разных источников, используя даже непарные данные.
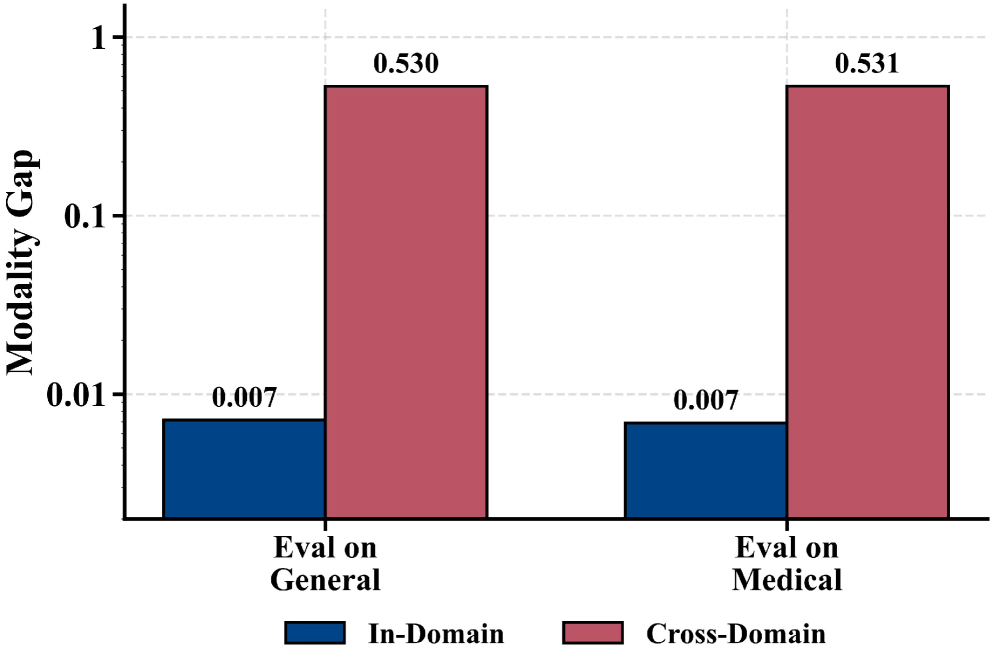
Предложенная парадигма ReVision использует геометрическое согласование и контрастное обучение для масштабирования производительности мультимодальных больших языковых моделей, снижая зависимость от дорогостоящих парных наборов данных изображения и текста.
Несмотря на успехи контрастного обучения в согласовании визуальных и лингвистических представлений, сохраняется геометрическая аномалия, известная как «разрыв модальностей», когда вложения разных модальностей, выражающие одинаковый смысл, занимают смещенные области пространства. В данной работе, ‘Modality Gap-Driven Subspace Alignment Training Paradigm For Multimodal Large Language Models’, предложен новый подход к преодолению этой проблемы, основанный на точном описании формы «разрыва модальностей» и его использовании для эффективного масштабирования моделей. Авторы представляют ReVision — парадигму обучения, позволяющую использовать статистически выровненные непарные данные для снижения зависимости от дорогостоящих пар изображений и текста, и тем самым эффективно масштабировать производительность больших мультимодальных языковых моделей. Способствует ли этот подход созданию более гибких и доступных систем мультимодального искусственного интеллекта?
Понимание Разрыва Модальностей: Ключ к Межмодальному Восприятию
Несмотря на то, что текст и изображение могут передавать одно и то же значение, между этими различными способами представления информации существуют систематические различия в их распределении — так называемый «Разрыв Модальностей». Данное явление указывает на то, что данные, полученные из разных источников, не просто отличаются по форме, но и имеют внутренние характеристики, которые влияют на их восприятие и обработку. Например, текстовые данные склонны к большей абстрактности и обобщениям, в то время как изображения часто содержат более конкретные и детализированные сведения. Это различие в распределении данных создает трудности при построении систем, способных эффективно понимать и сопоставлять информацию, представленную в различных модальностях, требуя разработки специализированных методов для преодоления этого разрыва и обеспечения полноценного межмодального взаимодействия.
Традиционные методы выравнивания данных, используемые при работе с различными модальностями — например, текстом и изображениями — часто опираются на упрощающее, но неточное предположение об изотропном распределении шума. Данное предположение, известное как “Изотропное Предположение”, исходит из идеи, что ошибки и неточности распределены равномерно во всех направлениях. Однако, реальные данные часто демонстрируют анизотропное распределение, когда погрешности концентрируются в определенных областях или направлениях, что искажает представление о сходстве между модальностями. Это приводит к неэффективному выравниванию и снижает качество понимания между различными типами данных, поскольку алгоритмы не способны адекватно учесть специфические характеристики шума в каждой модальности.
Предположение об изотропном характере шума, широко используемое в методах сопоставления различных модальностей данных, не отражает истинную природу несоответствий между ними, что существенно ограничивает возможности эффективного межмодального понимания. Исследования показали, что начальное расстояние между текстовыми и визуальными представлениями составляет 0.39, что свидетельствует о значительном разрыве, препятствующем успешному сопоставлению. Данный разрыв указывает на то, что простые модели, предполагающие равномерное распределение ошибок, не способны адекватно описывать сложность взаимосвязей между разными типами данных, и требуется разработка более совершенных подходов, учитывающих специфические характеристики каждой модальности.
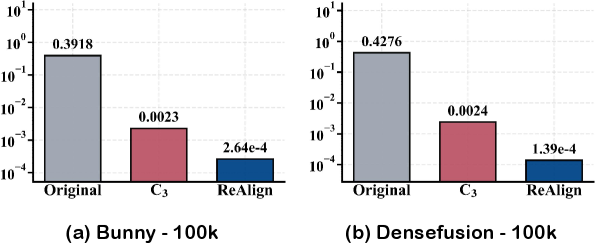
C3 и ReAlign: Новая Стратегия Преодоления Разрыва Модальностей
Фреймворк C3 предлагает более детализированное понимание разрыва между модальностями (ModalityGap), характеризуя его не как единое смещение, а как комбинацию систематического сдвига (constant displacement) и случайного шума выравнивания (random alignment noise). Данный подход предполагает, что разница между модальностями возникает не только из-за постоянной разницы в координатных системах, но и из-за случайных отклонений в выравнивании данных, что позволяет более точно моделировать и компенсировать несоответствия между различными типами данных. Это представление позволяет разрабатывать более эффективные стратегии выравнивания, учитывающие оба компонента разрыва между модальностями.
В основе предложенного подхода лежит стратегия выравнивания ‘ReAlign’, не требующая предварительного обучения. ‘ReAlign’ использует статистические характеристики непарных данных для эффективного сопоставления модальностей, избегая необходимости в дорогостоящих и трудоемких процессах создания парных наборов данных. Алгоритм оперирует непосредственно с распределениями данных, извлекая информацию о положении и масштабе признаков, что позволяет выполнять преобразования между модальностями без явного обучения модели-преобразователя. Это делает ‘ReAlign’ особенно полезным в сценариях, где доступ к парным данным ограничен или невозможен.
Стратегия ReAlign осуществляет эффективное сопоставление модальностей без использования дорогостоящих парных наборов данных, опираясь на статистические свойства неподключенных данных. В основе подхода лежит использование ВторойМоментныхХарактеристик (SecondMomentProperties), которые позволяют оценить распределение данных в каждой модальности и выявить их общие характеристики. Для обеспечения стабильности и согласованности сопоставления применяется ФиксированнаяСистемаКоординат (FixedReferenceFrame), которая служит единой точкой отсчета для всех модальностей. Комбинация этих двух элементов позволяет ReAlign эффективно выравнивать модальности, минимизируя необходимость в ручной разметке или дорогостоящих процессах обучения.
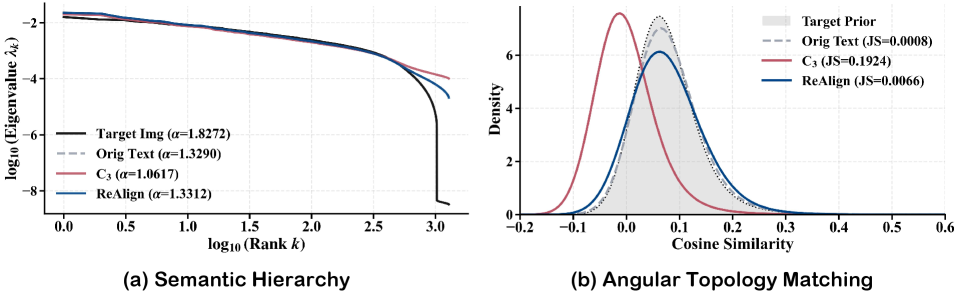
Масштабирование Мультимодального Обучения с ReVision: Новый Подход к Данным
Парадигма обучения ReVision использует ReAlign для замены парных данных на непарные, что позволяет эффективно масштабировать большие мультимодальные языковые модели (MLLM). Вместо традиционного подхода, требующего больших объемов тщательно размеченных парных данных (например, изображение и соответствующее текстовое описание), ReVision способен обучаться на значительно большем количестве непарных данных изображений и текста. Это достигается за счет использования ReAlign, механизма, который выравнивает модальности и позволяет модели извлекать полезную информацию даже из непарных данных. Такой подход существенно снижает затраты на сбор и аннотацию данных, что делает возможным обучение MLLM на более крупных и разнообразных наборах данных.
Парадигма обучения ReVision особенно эффективна в областях с ограниченными ресурсами (LowResourceDomains), где сбор больших объемов размеченных данных является непрактичным или дорогостоящим. Традиционные подходы к обучению мультимодальных моделей требуют значительных объемов парных данных — изображений с соответствующими текстовыми описаниями. В условиях дефицита таких данных, ReVision использует непарные данные, заменяя необходимость в точной синхронизации между модальностями, что существенно снижает затраты на разметку и сбор данных. Это позволяет масштабировать мультимодальные языковые модели (MLLM) в ситуациях, когда получение достаточного количества размеченных данных невозможно или экономически нецелесообразно.
Парадигма ReVision эффективно решает проблему разрыва между модальностями (ModalityGap) в задачах кросс-модального обучения, что приводит к существенному повышению производительности и эффективности. В ходе тестирования на общих бенчмарках восприятия ReVision демонстрирует точность 87.3%, превосходя результаты базовых моделей на 2-5%. Это улучшение достигается за счет более эффективного использования информации из различных модальностей, что позволяет модели лучше обобщать знания и выполнять задачи с большей точностью.

За Пределы Выравнивания: Преобразование Представлений и Новые Горизонты Мультимодальности
Метод ‘Unicorn’ демонстрирует новаторский подход к преодолению разрыва между текстовыми и визуальными представлениями, преобразуя текстовые данные в псевдовизуальные. В основе лежит идея использования “ModalityGap” — намеренного создания промежуточного представления, которое отражает семантическое содержание текста, но в формате, более близком к визуальному. Этот процесс позволяет модели воспринимать текст не просто как последовательность слов, а как своего рода “визуальный эскиз”, что значительно расширяет возможности мультимодального анализа и генерации. По сути, метод создает “иллюзию” визуального восприятия для текстовых данных, позволяя модели использовать инструменты, разработанные для обработки изображений, для анализа и понимания текста, что открывает новые перспективы в области искусственного интеллекта.
Преобразование текстовых представлений в псевдовизуальные, в сочетании с методами вроде ‘LLM2CLIP’, кодирующими обе модальности, открывает принципиально новые возможности для креативной мультимодальной генерации и глубокого понимания данных. Такой подход позволяет моделям не просто сопоставлять текст и изображения, но и создавать новые визуальные представления на основе текстовых запросов или, наоборот, генерировать текстовые описания для изображений с высокой степенью детализации и осмысленности. В результате, системы машинного обучения получают возможность не только понимать информацию, представленную в разных форматах, но и творчески взаимодействовать с ней, расширяя границы возможного в области искусственного интеллекта и мультимедийных технологий.
Методики геометрической коррекции играют ключевую роль в повышении эффективности ReAlign, обеспечивая устойчивое и точное выравнивание между различными модальностями данных. Эти техники позволяют компенсировать искажения и несоответствия, возникающие при сопоставлении информации, представленной в различных форматах, например, текста и изображений. За счет применения сложных алгоритмов, учитывающих геометрические характеристики данных, достигается более надежное сопоставление семантических понятий, что критически важно для мультимодального анализа и генерации контента. Улучшенная точность выравнивания, достигнутая благодаря геометрической коррекции, позволяет моделям более эффективно использовать информацию из различных источников, значительно повышая их производительность в задачах, требующих комплексного понимания и обработки данных.
Достижения в области межмодального переноса информации значительно расширяют возможности многомодальных больших языковых моделей (MLLM). Система ReVision демонстрирует впечатляющую точность в 75.1% при решении сложных задач, превосходя базовые модели на 3-7%. Важно отметить, что данная система позволяет существенно снизить затраты на сбор данных: стоимость составляет 476.05 единиц, в то время как для метода Unicorn этот показатель равен 176.10, а для использования только изображений — всего 1.0. Такое сочетание высокой производительности и экономичности открывает новые перспективы для разработки более эффективных и доступных MLLM, способных к комплексному анализу и обработке информации из различных источников.
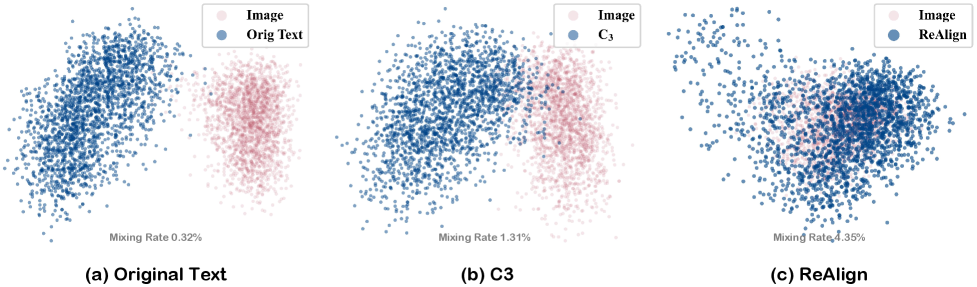
Исследование демонстрирует, что эффективное обучение мультимодальных больших языковых моделей требует преодоления разрыва между различными модальностями данных. Предложенный подход ReVision акцентирует внимание на геометрическом выравнивании представлений, что позволяет модели более точно сопоставлять текст и изображения даже при использовании непарных данных. Как однажды заметил Эндрю Ын: «Мы приближаемся к тому, чтобы машины могли учиться, как учатся люди, используя гораздо меньше данных.» Эта мысль находит отражение в ReVision, поскольку парадигма обучения позволяет достичь высокой производительности, снижая зависимость от дорогостоящих парных наборов данных, что делает мультимодальное обучение более доступным и эффективным.
Куда Далее?
Представленная парадигма обучения, фокусирующаяся на выравнивании подпространств и использовании непарных данных, безусловно, открывает новые горизонты в области мультимодальных больших языковых моделей. Однако, не стоит забывать, что геометрия представления — лишь один из аспектов сложной проблемы понимания. Вопрос о том, насколько точно выровненные представления действительно отражают семантическую близость, остается открытым. Неизбежно возникает потребность в более строгих метриках оценки, выходящих за рамки традиционного сравнения изображений и текста.
Очевидным направлением дальнейших исследований представляется изучение возможности адаптации предложенного подхода к другим модальностям — аудио, видео, тактильным данным. Более того, вопрос о масштабируемости данного метода при работе с экстремально большими объемами непарных данных требует тщательного анализа. Успешное решение этих задач может привести к созданию действительно универсальных мультимодальных систем, способных к комплексному пониманию окружающего мира.
Не стоит также упускать из виду ироничный факт: стремление к идеальному выравниванию представлений может оказаться иллюзией. Возможно, истинная сила мультимодальных моделей заключается не в точности соответствия между модальностями, а в способности к креативному комбинированию информации, порождающему новые смыслы. Исследование этой «несовершенной» стороны мультимодальности — задача, достойная внимания.
Оригинал статьи: https://arxiv.org/pdf/2602.07026.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Моделирование биомолекул: новый импульс от нейросетей
- Самообучающиеся признаки: новый подход к машинному обучению
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Облачные вычисления для науки: гибкость и масштабируемость
2026-02-10 09:36