Автор: Денис Аветисян
Новое исследование сравнивает возможности больших языковых моделей и автономных AI-агентов в автоматическом восстановлении и проверке вычислительных анализов в социологии и других областях социальных наук.
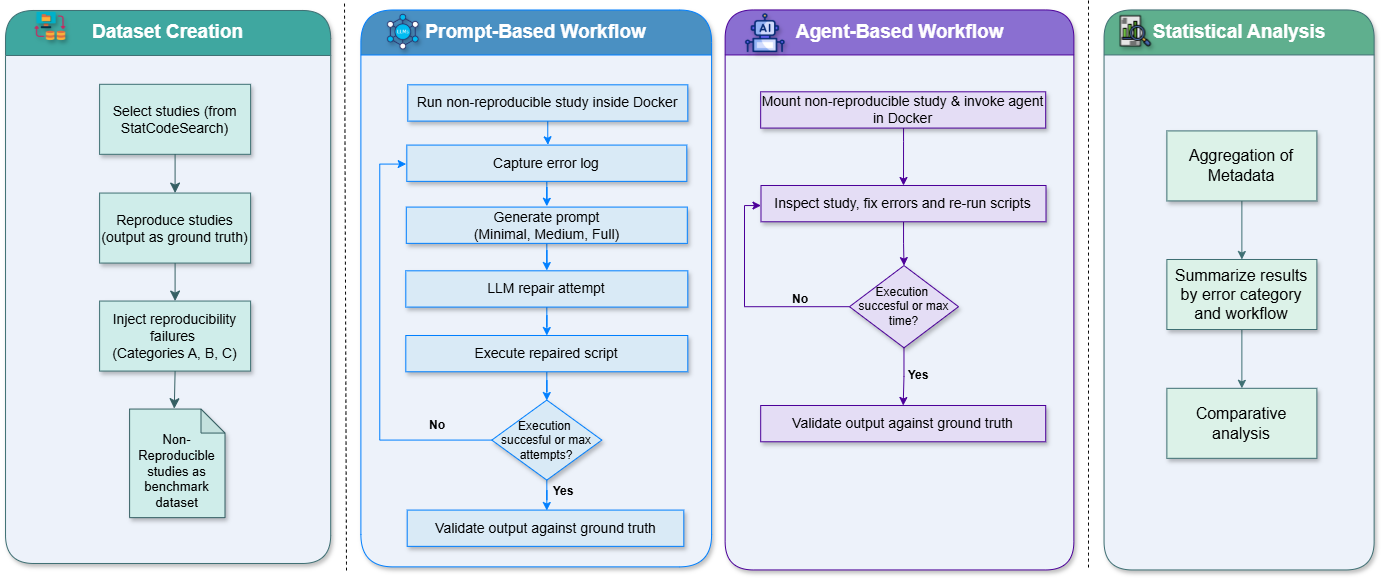
Сравнение подходов, основанных на запросах и AI-агентах, к автоматическому обеспечению воспроизводимости вычислительных исследований в социальных науках.
Воспроизводимость вычислительных исследований в общественных науках часто сталкивается с трудностями, несмотря на кажущуюся простоту повторного запуска кода. В работе ‘Automating Computational Reproducibility in Social Science: Comparing Prompt-Based and Agent-Based Approaches’ исследуется возможность автоматизации диагностики и исправления ошибок воспроизведения с помощью больших языковых моделей и AI-агентов. Полученные результаты указывают на превосходство агент-ориентированных систем над подходами, основанными на запросах к языковым моделям, в решении данной задачи. Способны ли подобные автоматизированные рабочие процессы кардинально снизить трудозатраты и повысить надежность научных результатов в различных областях?
Вызов Надежности Кода: Неизбежность Ошибок
Современное программное обеспечение, будь то операционные системы, веб-приложения или встроенные системы, характеризуется беспрецедентной сложностью кода. Эта сложность является неизбежным следствием растущих требований к функциональности и производительности, но одновременно создает благодатную почву для ошибок. Даже небольшая ошибка в коде, особенно в критически важных системах, может привести к серьезным последствиям, начиная от незначительных сбоев и потери данных, и заканчивая финансовыми потерями, угрозой безопасности или даже человеческими жертвами. Увеличение числа строк кода и взаимодействие множества компонентов делают выявление и исправление ошибок трудоемким и дорогостоящим процессом, что подчеркивает необходимость разработки новых подходов к обеспечению надежности программного обеспечения.
Традиционные методы отладки программного обеспечения, несмотря на свою устоявшуюся практику, зачастую оказываются чрезвычайно трудоемкими и не всегда способны выявить все существующие уязвимости. Процесс поиска и устранения ошибок, требующий детального анализа кода и ручного тестирования, может занимать значительное время, особенно в крупных и сложных проектах. Более того, некоторые ошибки, проявляющиеся лишь в определенных условиях или при редких комбинациях входных данных, могут оставаться незамеченными в ходе стандартных процедур отладки, представляя потенциальную угрозу для стабильности и безопасности программного обеспечения. Это связано с тем, что человеческий фактор ограничивает объем и глубину тестирования, в то время как количество возможных сценариев использования программы постоянно растет.
Автоматизированное исправление кода представляет собой многообещающее направление в повышении надежности программного обеспечения и сокращении времени разработки. Вместо ручного поиска и устранения ошибок, системы автоматического исправления анализируют код, выявляют дефекты и предлагают или автоматически применяют исправления. Такой подход позволяет значительно ускорить процесс отладки, особенно в крупных и сложных проектах, где поиск ошибок может занимать значительное время. Исследования показывают, что автоматизированные инструменты способны успешно исправлять определенные типы ошибок, такие как синтаксические ошибки, ошибки типизации и даже логические ошибки в простых случаях. Внедрение подобных систем позволяет разработчикам сосредоточиться на более сложных задачах, требующих творческого подхода, и повысить общую производительность труда, снижая вероятность дорогостоящих сбоев в работе программного обеспечения.
Два Пути Автоматического Исправления Кода: Запросы и Агенты
Ремонт кода на основе запросов (prompt-based repair) использует генеративные возможности больших языковых моделей (LLM) для непосредственного предложения исправлений, основываясь на описаниях ошибок. Этот подход предполагает, что LLM, обученная на обширном корпусе кода, способна анализировать сообщение об ошибке и генерировать фрагменты кода, предназначенные для устранения выявленной проблемы. Эффективность такого подхода напрямую зависит от качества и детализации описания ошибки, предоставляемого пользователем или системой автоматической диагностики. LLM может предлагать исправления в виде полных замен ошибочных блоков кода или, альтернативно, предлагать изменения, которые необходимо внести вручную. Оценка предложенных исправлений обычно проводится с использованием автоматизированных тестов или ручной проверки.
Агентный подход к автоматическому исправлению кода предполагает использование ИИ-агентов, которые взаимодействуют непосредственно с исполняемой средой. Эти агенты не просто предлагают исправления на основе статического анализа, а динамически выполняют код, анализируют результаты выполнения, выявляют причины ошибок и применяют необходимые изменения. В процессе диагностики агенты могут использовать различные техники, такие как отладка, трассировка выполнения и анализ журналов, для локализации проблемных участков кода. Исправления могут включать изменение кода, перезапуск служб или даже автоматическую отмену ошибочных транзакций, в зависимости от типа ошибки и возможностей агента. Ключевым аспектом является способность агентов адаптироваться к текущему состоянию системы и применять исправления в реальном времени, минимизируя время простоя и обеспечивая непрерывность работы.
Оба подхода к автоматическому исправлению кода — основанные на запросах и агентские — требуют согласованной и воспроизводимой среды для обеспечения надёжного тестирования и валидации. Отсутствие стабильной среды приводит к непостоянным результатам, когда исправления, успешно прошедшие проверку в одной среде, могут оказаться нерабочими в другой. Это связано с различиями в конфигурации, версиях библиотек, операционной системе и других факторах. Воспроизводимость достигается путём использования инструментов контейнеризации, таких как Docker, или виртуальных машин, которые позволяют создать идентичные окружения для разработки, тестирования и развертывания. Автоматизация процесса создания и настройки этих сред является ключевым аспектом обеспечения надёжности и масштабируемости систем автоматического исправления кода.
Синтетический Бенчмарк: Контролируемая Оценка Рабочих Процессов
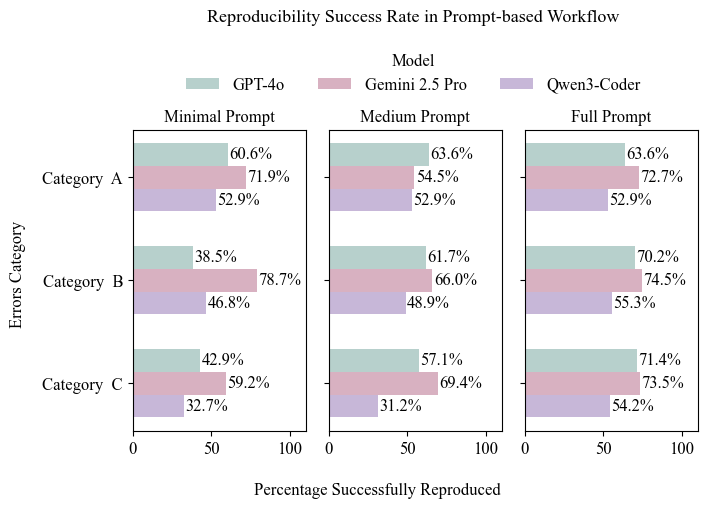
Синтетический бенчмарк, разработанный на языке R, предоставляет контролируемую среду для оценки рабочих процессов исправления ошибок. Данный подход позволяет генерировать большое количество тестовых случаев с известными дефектами, что необходимо для объективной оценки эффективности различных методов и инструментов автоматического исправления кода. Использование R обусловлено его широкими возможностями в области статистического анализа и генерации данных, что критически важно для получения надежных и воспроизводимых результатов при тестировании.
Бенчмарк использует метод инъекции ошибок для создания реалистичных сценариев сбоев в коде, что позволяет проводить всестороннее тестирование рабочих процессов восстановления. Внедрение ошибок включает в себя намеренное внесение дефектов различного типа — от синтаксических ошибок и логических неточностей до ошибок времени выполнения — в тестовый код. Это позволяет оценить способность систем восстановления обнаруживать, локализовать и исправлять эти дефекты, а также измерить эффективность различных стратегий и алгоритмов восстановления в условиях, приближенных к реальным. Интенсивность и типы внедряемых ошибок контролируются для обеспечения воспроизводимости и возможности количественной оценки производительности.
Использование Docker-контейнеров обеспечивает согласованность выполнения и воспроизводимость результатов на различных платформах. Контейнеризация позволяет инкапсулировать окружение, включая все необходимые зависимости, такие как версии интерпретатора R, установленные пакеты и системные библиотеки. Это исключает влияние различий в конфигурации хост-систем на процесс тестирования и гарантирует, что бенчмарк выполняется в идентичном окружении независимо от операционной системы или аппаратной архитектуры. Воспроизводимость обеспечивается возможностью создания и распространения Docker-образов, которые содержат все необходимые компоненты для запуска бенчмарка, что позволяет другим исследователям и разработчикам независимо подтвердить полученные результаты и повторить эксперименты.
Верификация и Воспроизводимость: Основа Доверия к Результатам
Проверка выходных данных является ключевым этапом, гарантирующим корректность исправленного кода. Без тщательной верификации невозможно убедиться, что внесенные изменения действительно устранили ошибки и не привели к новым проблемам. Этот процесс включает в себя сопоставление результатов работы исправленного кода с ожидаемыми значениями, используя заранее определенные тестовые примеры и критерии оценки. Эффективная проверка выходных данных позволяет не только подтвердить работоспособность решения, но и повысить уверенность в его надежности и устойчивости к различным сценариям использования. В контексте автоматического исправления кода, строгая валидация особенно важна, поскольку позволяет оценить эффективность различных подходов и выбрать наиболее подходящий для конкретной задачи, минимизируя риски появления непредсказуемого поведения.
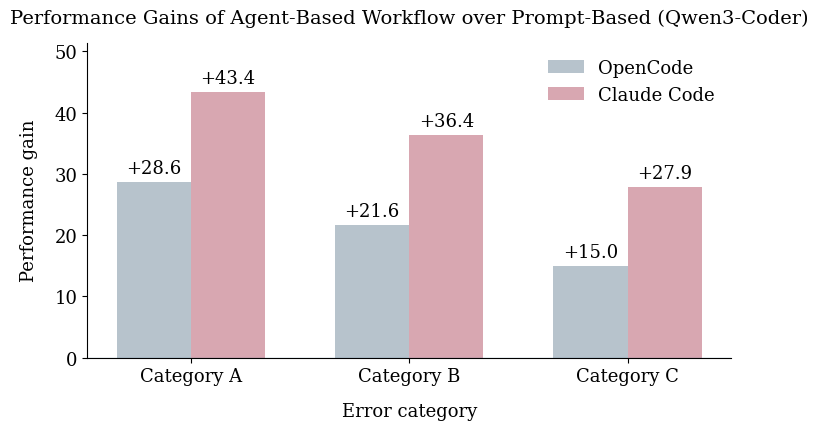
Для объективной оценки эффективности различных подходов к автоматическому исправлению кода применялся статистический анализ. Этот метод позволил количественно сравнить производительность различных рабочих процессов, выявляя существенные различия в их способности находить и устранять ошибки. Например, сравнение показателей успешности между агенто-ориентированными и основанными на запросах к большим языковым моделям (LLM) выявило, что первые демонстрируют значительное превосходство, особенно в сложных сценариях (Категория C ошибок), достигая на 27,9% более высокой доли успешных исправлений. Точные количественные оценки, полученные в результате статистического анализа, не только подтверждают преимущества определенных подходов, но и предоставляют надежную основу для дальнейшей оптимизации и развития технологий автоматического исправления кода.
Обеспечение воспроизводимости вычислений посредством тщательной документации и обмена данными является ключевым фактором для укрепления доверия к полученным результатам. В рамках данного исследования, акцент на прозрачности процесса — от исходного кода и используемых данных до конкретных параметров настройки — позволяет другим исследователям независимо подтвердить полученные выводы. Такой подход не только повышает надежность научной работы, но и способствует более широкому распространению и использованию полученных знаний, поскольку обеспечивает возможность повторного анализа и проверки результатов. Внедрение принципов открытой науки, включая публикацию исходных материалов и подробное описание методологии, является важным шагом к созданию более надежной и прозрачной исследовательской среды.
Исследования показали, что подходы, основанные на использовании автономных агентов, значительно превосходят традиционные методы, использующие прямые запросы к большим языковым моделям (LLM) при исправлении сложных ошибок в коде. В частности, при работе с ошибками Категории C — наиболее трудными для автоматического исправления — системы, построенные на базе агентов, демонстрируют на 27,9% более высокую успешность. Это указывает на то, что способность агентов к планированию, выполнению последовательных шагов и самокоррекции обеспечивает более надежное решение сложных задач по исправлению кода, чем простое предоставление инструкций языковой модели.
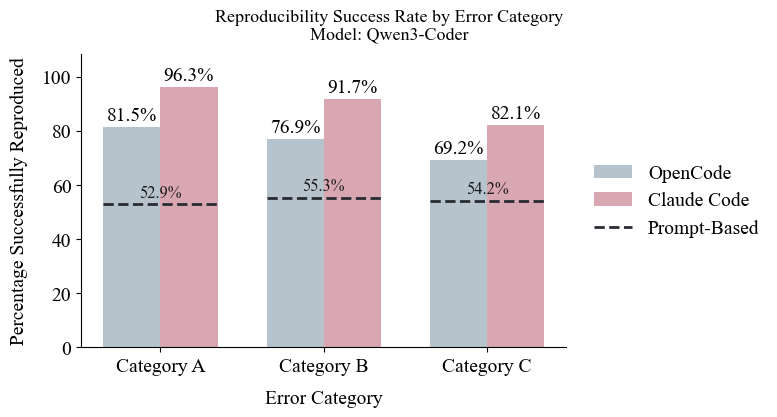
Исследования показали значительное превосходство агента Claude Code в обеспечении воспроизводимости результатов по сравнению с OpenCode, особенно при работе с ошибками категории A. Агент Claude Code достиг 96.3% успеха в воспроизведении корректной работы кода после исправления ошибок этого типа, в то время как показатель OpenCode составил лишь 81.5%. Данный результат демонстрирует более высокую надежность и стабильность Claude Code в решении задач автоматического исправления кода и подтверждает его способность последовательно генерировать воспроизводимые исправления даже в простых сценариях, что является ключевым фактором для доверия к автоматизированным инструментам разработки.
Исследования показали значительное превосходство агента Claude Code в обеспечении воспроизводимости результатов, особенно при работе со сложными ошибками, классифицируемыми как категория C. В частности, данный агент продемонстрировал улучшение показателя успешной воспроизводимости на 27,9% по сравнению с подходами, основанными на прямых запросах к большим языковым моделям. Это означает, что решения, предложенные Claude Code для исправления таких ошибок, с большей вероятностью будут успешно повторены и подтверждены другими исследователями или в различных условиях, что повышает доверие к полученным результатам и способствует более надежному развитию технологий автоматического исправления кода.
Применение принципов открытой науки значительно повышает надежность и значимость данного исследования. Публикация исходного кода, наборов данных и подробная документация позволяют другим исследователям воспроизвести результаты, проверить их достоверность и использовать их в дальнейших разработках. Такой подход не только укрепляет доверие к полученным данным, но и способствует более быстрому прогрессу в области автоматизированного исправления программных ошибок, стимулируя коллективное знание и инновации. Открытость обеспечивает прозрачность процесса, позволяя сообществу оценивать сильные и слабые стороны предложенных методов и вносить свой вклад в их улучшение, что в конечном итоге повышает ценность и воздействие данной работы.
Исследование демонстрирует стремление к автоматизации воспроизводимости вычислений в социальных науках, что, по сути, является попыткой формализовать процесс анализа данных. Это созвучно идеям Клода Шеннона: «Наилучный способ держать информацию в секрете — не хранить ее вовсе». В контексте данной работы, это можно интерпретировать как необходимость минимизации ручного вмешательства и субъективных решений в процессе воспроизведения вычислений. Агент-ориентированный подход, превосходящий prompt-based LLM, представляет собой шаг к созданию самодостаточной и доказуемо корректной системы, где ошибка выявляется и устраняется автоматически, а не полагается на интерпретацию или «исправление» человеком. Подобная автоматизация способствует повышению надежности и прозрачности научных исследований.
Что дальше?
Представленная работа, хотя и демонстрирует превосходство агентных подходов над прямым использованием больших языковых моделей в обеспечении воспроизводимости вычислений, лишь слегка отодвигает завесу над фундаментальной проблемой. Пусть N стремится к бесконечности — что останется устойчивым? Не сама способность «исправить» код, а его внутренняя непротиворечивость. Автоматическое исправление — это, по сути, временное решение, замаскировавшее недостаточно четкую постановку задачи. Необходимо сместить фокус с поверхностного «запускается ли код» на доказательство его корректности в рамках заданных аксиом и ограничений.
Ограничения текущего исследования, связанные с синтетическим бенчмарком, являются очевидными. Реальный мир социальных наук характеризуется не только ошибками в коде, но и нечеткостью исходных данных, противоречивыми предположениями и, что самое важное, отсутствием однозначного «правильного» ответа. Будущие исследования должны сосредоточиться на разработке метрик, способных оценивать не только воспроизводимость, но и обоснованность результатов в контексте сложной социальной реальности.
Следующим шагом представляется разработка формальных методов верификации для кода, используемого в социальных науках, а также интеграция этих методов с инструментами автоматического исправления, управляемыми агентными системами. Иначе, мы обречены вечно латать дыры в кораблях, построенных на зыбучих песках неявных предположений. Элегантность решения, как и истина, заключается не в отсутствии ошибок, а в их предсказуемости.
Оригинал статьи: https://arxiv.org/pdf/2602.08561.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Робот-исследователь: новый подход к автономной навигации
2026-02-10 16:13