Автор: Денис Аветисян
Новый подход, использующий искусственный интеллект, позволяет автоматизировать процесс выдвижения и проверки научных гипотез, открывая возможности для более глубокого понимания общественных явлений.
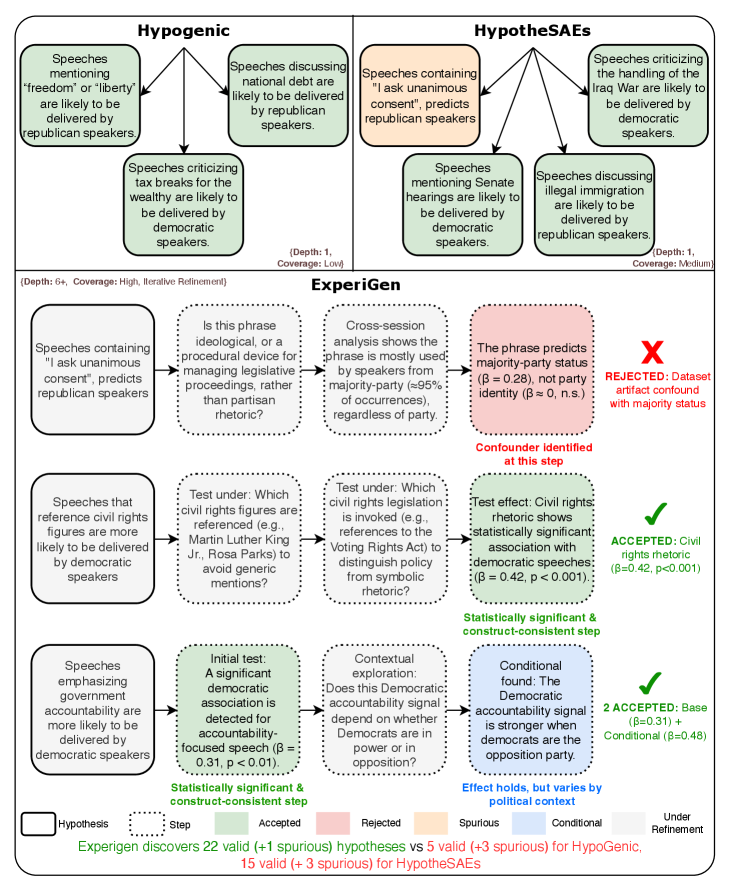
В статье представлена платформа ExperiGen, использующая агентов ИИ и итеративное уточнение для автоматизации цикла генерации и валидации гипотез на основе неструктурированных данных.
Традиционные методы социальных исследований часто сталкиваются с ограничениями в скорости и эффективности выявления новых закономерностей. В работе, озаглавленной ‘Accelerating Social Science Research via Agentic Hypothesization and Experimentation’, предложен инновационный подход, использующий агентов на базе больших языковых моделей для автоматизации цикла формирования и проверки гипотез непосредственно из неструктурированных данных. Разработанная система ExperiGen демонстрирует ускорение процесса научных открытий, выявляя в 2-4 раза больше статистически значимых гипотез с предсказательной силой на 7-17% выше, чем у существующих методов. Каковы перспективы дальнейшего развития подобных систем для углубленного анализа сложных социальных явлений и принятия обоснованных решений?
Раскрытие Скрытых Связей: Путь к Знаниям из Неструктурированных Данных
Огромные объемы ценной информации скрыты в неструктурированных данных, однако извлечение из них проверяемых гипотез представляет собой сложную задачу. Современные методы анализа часто сталкиваются с необходимостью ручной разработки признаков и требуют глубоких знаний в конкретной предметной области, что существенно ограничивает масштабируемость и объективность исследований. Неструктурированные данные, такие как текстовые документы, изображения и аудиозаписи, содержат потенциально важные закономерности, но их преобразование в формат, пригодный для количественного анализа, требует инновационных подходов и алгоритмов, способных автоматически выявлять и интерпретировать скрытые связи. Поиск эффективных способов автоматизации этого процесса является ключевой задачей для раскрытия всего потенциала неструктурированной информации и получения значимых научных и практических результатов.
Традиционные подходы к анализу данных, такие как построение моделей на основе ручного выделения признаков, зачастую требуют значительных усилий и глубоких знаний в конкретной предметной области. Этот процесс не только отнимает много времени и ресурсов, но и вносит субъективность в результаты, поскольку выбор признаков и их интерпретация зависят от опыта и предубеждений исследователя. Вследствие этого, масштабирование подобных методов для работы с большими объемами данных и обеспечение воспроизводимости результатов становятся сложными задачами. Автоматизация процесса выделения признаков и использование алгоритмов машинного обучения, способных самостоятельно выявлять закономерности в неструктурированных данных, представляются перспективным путем преодоления этих ограничений и повышения объективности анализа.
ExperiGen: Автоматизированный Двигатель Гипотез
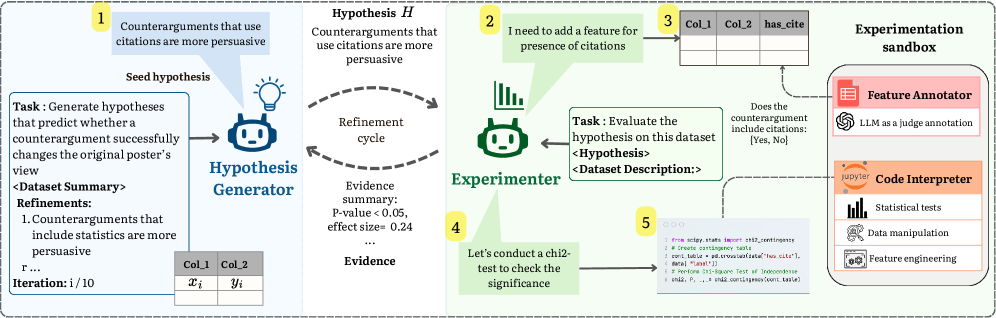
ExperiGen реализует унифицированный подход к генерации и валидации гипотез посредством двух специализированных агентов, основанных на больших языковых моделях (LLM): Агента-Генератора и Агента-Экспериментатора. Агент-Генератор отвечает за формулирование проверяемых гипотез непосредственно из неструктурированных данных, автоматизируя процесс, ранее требовавший значительного ручного труда. Агент-Экспериментатор, в свою очередь, предназначен для проведения экспериментов и оценки достоверности предложенных гипотез. Взаимодействие между этими агентами обеспечивает замкнутый цикл, позволяющий автоматизировать весь процесс научного исследования — от постановки вопроса до получения результатов.
Агент генерации ExperiGen использует большие языковые модели (LLM) для формирования проверяемых гипотез непосредственно из неструктурированных данных, что существенно снижает потребность в ручном анализе и формулировании предположений. Вместо традиционного подхода, требующего экспертной оценки и последующей разработки гипотез, система автоматически извлекает информацию из различных источников, таких как текстовые документы, базы данных и журналы, и преобразует её в формальные гипотезы, готовые к экспериментальной проверке. Это позволяет ускорить процесс научных открытий и исследований, а также повысить эффективность анализа данных за счет автоматизации рутинных задач.
Байесовская оптимизация направляет работу Generator Agent, осуществляя баланс между исследованием новых гипотез и использованием перспективных направлений. Этот метод позволяет Generator Agent не только генерировать разнообразные предположения, но и динамически корректировать стратегию поиска, отдавая предпочтение тем гипотезам, которые демонстрируют наибольшую вероятность успеха на основе предварительных результатов. В процессе оптимизации, алгоритм строит вероятностную модель, оценивающую эффективность каждой гипотезы, и использует эту модель для выбора следующей гипотезы для проверки, максимизируя ожидаемый выигрыш от эксперимента. Это обеспечивает эффективное использование вычислительных ресурсов и позволяет быстро идентифицировать наиболее перспективные направления исследований.
Строгая Валидация с Экспериментами на Основе LLM
Агент-экспериментатор автоматизирует процесс валидации, определяя полный экспериментальный план. Это включает в себя извлечение релевантных признаков из данных и выбор соответствующих статистических тестов для проверки гипотез. Агент самостоятельно конфигурирует параметры извлечения признаков, например, определяет, какие переменные будут использоваться в анализе и как они будут преобразованы. Выбор статистических тестов основывается на типе данных и формулируемой гипотезе, обеспечивая корректную оценку статистической значимости результатов. Автоматизация этого процесса минимизирует субъективность и повышает воспроизводимость экспериментов.
Для оценки статистической значимости выдвигаемых гипотез используются методы множественной регрессии и логистической регрессии. Множественная регрессия позволяет установить взаимосвязь между зависимой переменной и несколькими независимыми переменными, оценивая влияние каждой из них с учетом других. Формула для множественной линейной регрессии выглядит как Y = β_0 + β_1X_1 + β_2X_2 + ... + β_nX_n + ε, где Y — зависимая переменная, X_i — независимые переменные, β_i — коэффициенты регрессии, а ε — ошибка. Логистическая регрессия применяется для анализа зависимой переменной, имеющей бинарный (дихотомический) характер, и оценивает вероятность наступления определенного события. Результаты анализа, полученные с помощью этих методов, позволяют определить, насколько полученные данные подтверждают выдвинутые гипотезы и обладают ли они статистической значимостью.
Агент-экспериментатор использует интерпретатор кода для выполнения вычислений и статистического анализа, что обеспечивает воспроизводимость и масштабируемость процесса валидации. Интерпретатор кода позволяет агенту динамически генерировать и выполнять скрипты на Python или R, необходимые для обработки данных, проведения статистических тестов, таких как регрессионный анализ и логистическая регрессия, и вычисления соответствующих метрик. Это устраняет зависимость от ручного выполнения вычислений и обеспечивает возможность автоматического повторения экспериментов с теми же параметрами и данными, а также масштабирования процесса обработки больших объемов данных и проведения параллельных экспериментов.
Обеспечение Надежности: Статистическая Значимость и Контроль Ошибок
Статистическая проверка является фундаментальным аспектом любого научного исследования, позволяющим отделить реальные закономерности от случайного шума. Система ExperiGen, по своей сути, опирается на строгую статистическую валидацию для обеспечения достоверности генерируемых гипотез. Без надежной статистической основы, даже кажущиеся многообещающими результаты могут оказаться ложными срабатываниями, вводящими в заблуждение исследователей и препятствующими прогрессу. ExperiGen использует передовые методы для оценки статистической значимости, гарантируя, что выделенные взаимосвязи действительно отражают существующие закономерности в данных, а не являются результатом случайности. Это позволяет исследователям с уверенностью фокусироваться на наиболее перспективных направлениях и избегать траты ресурсов на преследование ложных путей.
Основополагающим аспектом надежности научных открытий является статистическая значимость и контроль над уровнем ложных открытий. Применение строгих статистических критериев позволяет отделить реальные закономерности от случайных колебаний, что особенно важно при анализе больших объемов данных. Контроль над уровнем ложных открытий, например, посредством поправки Бенджамини-Хохберга, минимизирует вероятность ошибочных выводов и повышает доверие к полученным результатам. Это обеспечивает воспроизводимость исследований и позволяет избежать публикации необоснованных гипотез, что критически важно для дальнейшего развития науки и принятия обоснованных решений на основе полученных данных.
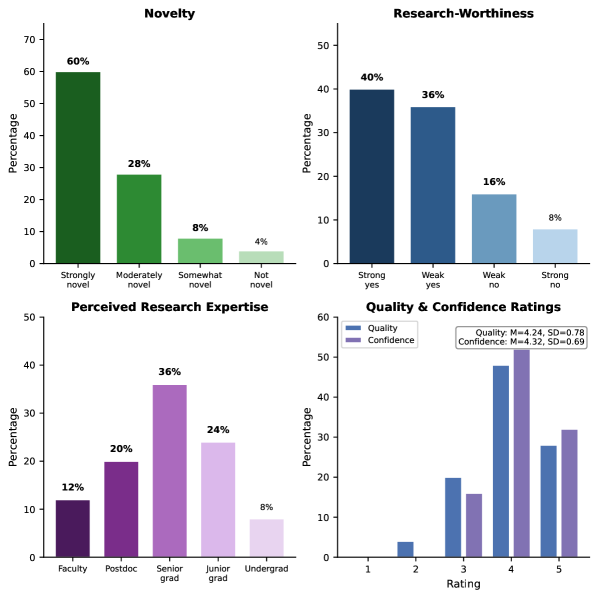
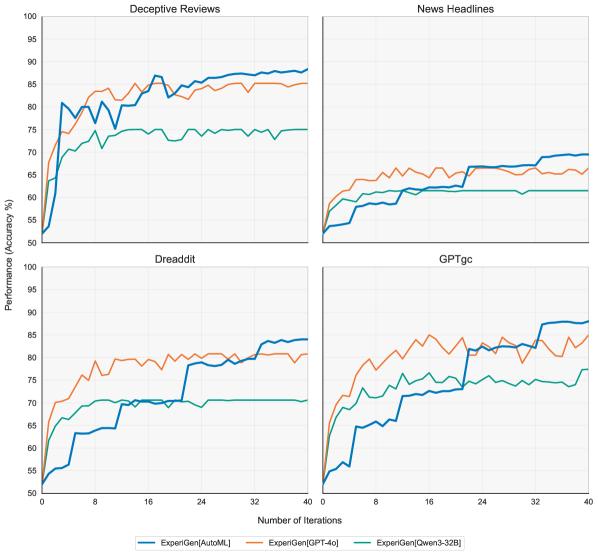
Система ExperiGen демонстрирует передовые результаты в области автоматического формирования гипотез, обнаруживая в 2-4 раза больше статистически значимых предположений по сравнению с существующими методами. Это достижение обусловлено оптимизированными алгоритмами анализа данных и повышенной чувствительностью к сигналам, скрытым в сложных наборах информации. Увеличение количества статистически подтвержденных гипотез позволяет исследователям более эффективно изучать взаимосвязи, выявлять новые закономерности и принимать обоснованные решения, основанные на надежных доказательствах. Такая эффективность особенно важна в областях, где скорость и точность анализа данных играют ключевую роль в достижении прорывных результатов.
В ходе A/B тестирования, проведенного с использованием ExperiGen, зафиксировано впечатляющее увеличение конверсии заполнения форм на 344%. Этот результат, подтвержденный крайне низким значением p-value, менее 10^{-6}, свидетельствует о статистической значимости полученного эффекта и высокой вероятности того, что наблюдаемое увеличение не является случайным. Такая существенная положительная динамика демонстрирует практическую ценность платформы ExperiGen в оптимизации пользовательского опыта и повышении эффективности маркетинговых стратегий, позволяя добиться значимых улучшений в ключевых бизнес-показателях.
Оценка экспертами в предметной области показала, что целых 88% сгенерированных ExperiGen гипотез были признаны новыми, а 76% — представляющими исследовательский интерес. Этот высокий показатель свидетельствует о способности системы не просто подтверждать известные закономерности, но и предлагать действительно оригинальные идеи, способные расширить границы знаний в соответствующей области. Полученные данные указывают на то, что ExperiGen может служить мощным инструментом для генерации инновационных направлений исследований и стимулирования научного прогресса, предоставляя экспертам ценный ресурс для выявления перспективных направлений и формирования новых гипотез.
Методы A/B-тестирования играют ключевую роль в уточнении выдвинутых гипотез и получении практических доказательств для принятия решений. Данный подход позволяет проверить влияние конкретных изменений на целевые показатели, такие как коэффициент конверсии или вовлеченность пользователей. В ходе экспериментов с использованием ExperiGen, A/B-тестирование продемонстрировало впечатляющий результат — увеличение количества регистраций в формах на 344%, при уровне значимости менее 10^{-6}. Такой уровень статистической достоверности подтверждает, что полученные результаты не случайны, а отражают реальное влияние изменений. Использование A/B-тестирования в сочетании с генерацией гипотез позволяет не только выявлять перспективные направления для улучшения, но и обосновывать принятые решения на основе объективных данных, минимизируя риски и максимизируя эффективность.
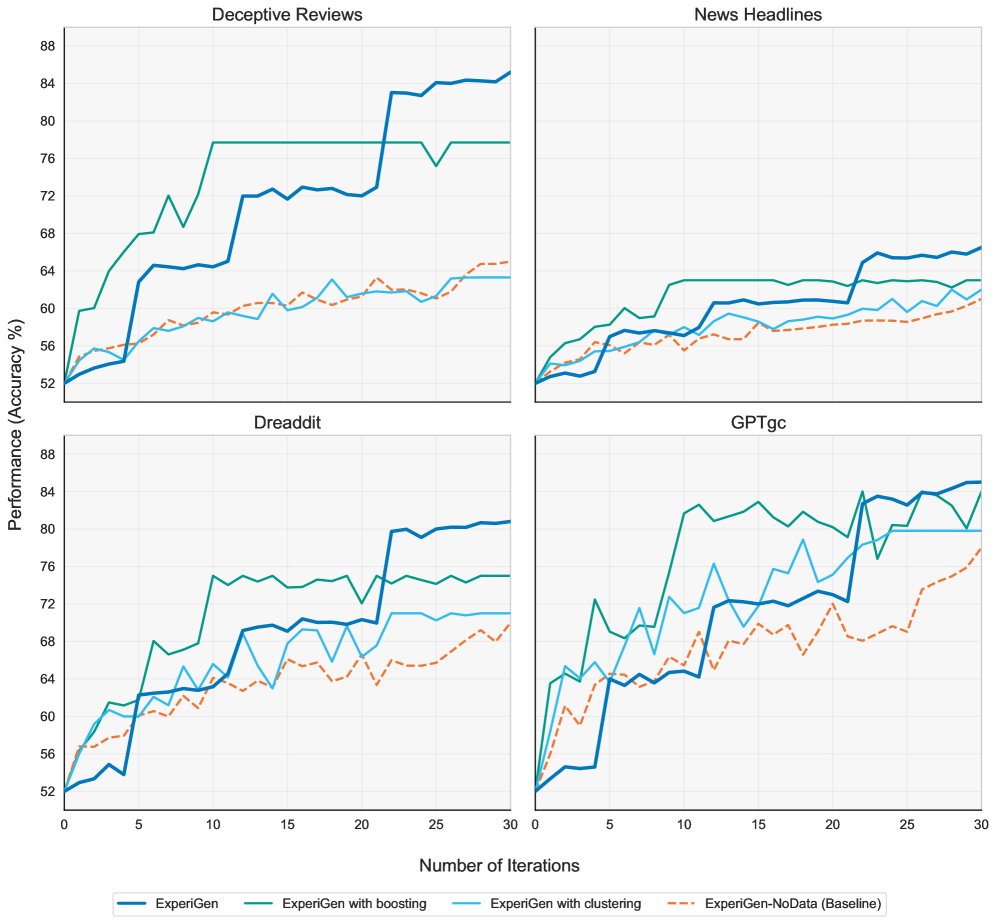
Предложенная ExperiGen, подобно садовнику, взращивает гипотезы из необработанных данных, а не строит их по заранее заданному плану. Эта система автоматизированного цикла генерации и валидации, основанная на LLM-агентах, напоминает о неизбежном хаосе в научном поиске. Каждое уточнение, каждая итерация — это признание сложности исследуемых явлений. Как заметила Грейс Хоппер: «Лучший способ предсказать будущее — это создать его». ExperiGen стремится не предсказать научные открытия, а активно участвовать в их создании, позволяя агентам итеративно совершенствовать гипотезы и подтверждать их статистическую значимость. Это не просто ускорение исследований, а изменение самой парадигмы научного поиска.
Что дальше?
Представленная работа, подобно любому садовнику, посадившему семя, открывает скорее вопросы, чем даёт окончательные ответы. Автоматизация цикла выдвижения и проверки гипотез — шаг вперёд, но не следует забывать: система научных знаний — это не машина, а сложный сад, где каждое вмешательство имеет последствия. Эксперименты, проводимые агентами, неизбежно несут в себе отпечаток предвзятости, заложенной в данных и алгоритмах. Вместо стремления к полной автоматизации, представляется более плодотворным поиск способов интеграции возможностей LLM-агентов с интуицией и критическим мышлением исследователя.
Основным вызовом остаётся проблема верификации. Статистическая значимость — лишь один аспект надёжности. Истинная устойчивость системы научных знаний не в изоляции компонентов, а в их способности прощать ошибки друг друга, выявлять противоречия и адаптироваться к новым данным. Необходимо разрабатывать методы оценки не только точности, но и объяснимости, воспроизводимости и этичности полученных результатов.
Подобно любому архитектурному решению, автоматизация научного поиска — это пророчество о будущих сбоях. Вместо того, чтобы стремиться к созданию идеальной системы, следует сосредоточиться на её способности к самовосстановлению и адаптации. Иначе, рискуем вырастить не сад открытий, а заросли технического долга.
Оригинал статьи: https://arxiv.org/pdf/2602.07983.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Искусственный интеллект: хрупкость визуального мышления
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Робот-исследователь: новый подход к автономной навигации
2026-02-10 19:44