Автор: Денис Аветисян
Новое исследование предлагает метод оценки корректности программного кода, созданного большими языковыми моделями, путем анализа их внутренней структуры.
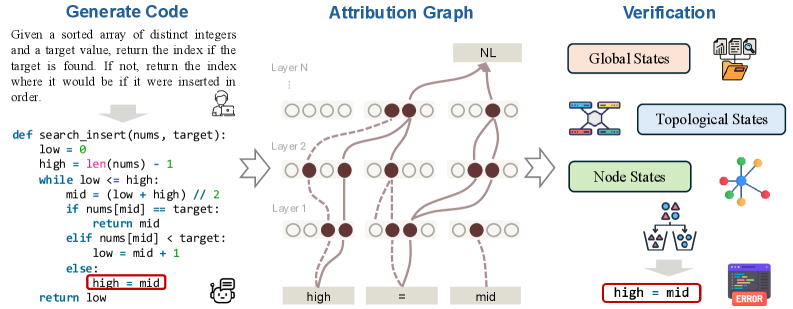
Предлагается подход к верификации кода на основе графов атрибуции и анализа ‘схем’ вычислений, не требующий внешнего тестирования или исполнения.
Существующие подходы к верификации кода полагаются на внешние механизмы, такие как модульное тестирование или LLM-оценщики, что зачастую требует значительных усилий и ограничено возможностями этих инструментов. В данной работе, ‘CodeCircuit: Toward Inferring LLM-Generated Code Correctness via Attribution Graphs’, предложен новый метод, рассматривающий верификацию кода как задачу механической диагностики, основанную на анализе внутренних вычислительных цепей больших языковых моделей. Показано, что корректность сгенерированного кода может быть оценена путем построения графов атрибуции, отражающих логическую траекторию модели, и выявления структурных сигнатур, отличающих корректные рассуждения от логических ошибок. Может ли анализ внутренних механизмов LLM стать основой для надежной и прозрачной верификации кода, не требующей внешних проверок?
Разоблачение Чёрного Ящика: Ограничения Современной Верификации Кода
Традиционные методы верификации кода в значительной степени опираются на исполняемое тестирование, однако этот подход сталкивается с серьезными ограничениями при работе со сложным и принципиально новым программным обеспечением. Суть проблемы заключается в том, что исполняемое тестирование способно выявить лишь те ошибки, которые проявляются в процессе выполнения конкретных тестовых сценариев. Для кода, содержащего сложные алгоритмы или взаимодействующего с неизвестными ранее системами, разработка исчерпывающего набора тестов становится практически невозможной задачей. В результате, критические уязвимости и непредсказуемое поведение могут оставаться незамеченными, особенно в контексте быстро развивающихся областей, таких как машинное обучение и искусственный интеллект, где новизна и сложность кода постоянно растут. Эффективность такого подхода снижается экспоненциально с увеличением сложности программного обеспечения, что требует поиска альтернативных методов верификации.
В последнее время, системы оценки кода, основанные на больших языковых моделях (LLM), приобрели популярность благодаря своей масштабируемости — возможности быстро оценивать большие объемы кода. Однако, эти системы подвержены проблеме рекурсивных зависимостей, когда модель оценивает код, сгенерированный другой моделью, а затем использует этот код для оценки следующего, создавая замкнутый цикл. Более того, LLM-as-judge часто демонстрируют недостаток прозрачности в процессе принятия решений — сложно понять, почему модель пришла к определенному выводу о корректности или некорректности кода. Это затрудняет отладку и улучшение как самого кода, так и модели оценки, лишая разработчиков возможности понять и исправить ошибки, лежащие в основе суждений.
Существующие подходы к проверке кода, генерируемого моделями искусственного интеллекта, часто оказываются недостаточными, поскольку испытывают трудности с обеспечением как масштабируемости, так и прозрачности процесса принятия решений. Традиционные методы, полагающиеся на тестирование, не способны эффективно оценивать сложные и инновационные программные решения, а современные системы, использующие большие языковые модели в качестве судей, подвержены рекурсивным зависимостям и не предоставляют чёткого понимания логики, лежащей в основе оценки. В связи с этим, возникает потребность в инструментах, способных не только быстро обрабатывать большие объемы кода, но и объяснять, почему конкретный фрагмент был признан корректным или ошибочным. Разработка CodeCircuit демонстрирует значительный прогресс в решении этой задачи, превосходя по своим показателям существующие методы и открывая новые возможности для обеспечения надежности и безопасности программного обеспечения, создаваемого с помощью искусственного интеллекта.
Механистическая Интерпретируемость: Взгляд Внутрь Нейронной Сети
Механистическая интерпретируемость представляет собой подход к пониманию внутренней работы нейронных сетей путем анализа их вычислительных механизмов. В отличие от методов, фокусирующихся на входных и выходных данных, механистическая интерпретируемость стремится выявить, как именно сеть выполняет свои вычисления, определяя функции отдельных нейронов и их взаимодействие. Это достигается путем декомпозиции сложных операций на более простые, интерпретируемые компоненты, позволяя понять, какие конкретные признаки или закономерности используются сетью для принятия решений. Такой подход позволяет не просто предсказывать поведение сети, но и объяснять его, что критически важно для повышения доверия и надежности систем искусственного интеллекта.
Графы атрибуции представляют собой метод декомпозиции вычислений в нейронных сетях на интерпретируемые признаки, позволяя отследить поток информации внутри модели. Они визуализируют, как отдельные нейроны и слои взаимодействуют для достижения определенного результата, идентифицируя признаки, наиболее сильно влияющие на выходные данные. В рамках этого подхода, каждый признак сопоставляется с конкретной операцией или компонентом сети, что обеспечивает возможность анализа и понимания логики принятия решений моделью. Построение таких графов осуществляется путём анализа активаций и градиентов, что позволяет установить причинно-следственные связи между входными данными, внутренними представлениями и выходными значениями.
Для извлечения графов атрибуции, позволяющих визуализировать поток информации внутри нейронных сетей, применяются методы, основанные на градиентной обратной связи (gradient-based backpropagation). Этот подход позволяет отследить, как активации отдельных нейронов влияют на конечный результат. Модели, такие как Gemma-2-2B-IT, специально обучены для облегчения интерпретации внутренних вычислений и предоставляют более четкие и структурированные графы атрибуции. Анализ градиентов позволяет определить вклад каждого нейрона в процесс принятия решения моделью, что критически важно для понимания ее логики и выявления потенциальных проблем.
CodeCircuit: Белый Ящик Верификации на Уровне Строк Кода
CodeCircuit — это фреймворк, предназначенный для верификации сгенерированного кода посредством анализа графов атрибуции на уровне отдельных строк. Он исследует взаимосвязи между строками кода и их влиянием на итоговый результат, позволяя отследить, какие части кода ответственны за конкретные действия или значения. Анализ строится на построении графа, где узлы представляют строки кода, а ребра — зависимости между ними, что обеспечивает детальное понимание логики работы модели и позволяет выявлять потенциальные ошибки или нежелательное поведение. Этот подход позволяет проводить верификацию, определяя, насколько сгенерированный код соответствует ожидаемому поведению.
В основе работы CodeCircuit лежит анализ потока информации, основанный на принципах топологии электрических цепей и композиции узлов. В данном контексте, код рассматривается как граф, где отдельные строки или фрагменты кода выступают в роли узлов, а зависимости между ними — в роли соединений. Топологический анализ позволяет определить критические пути передачи данных и выявить, как изменения в одном узле влияют на другие. Композиция узлов подразумевает изучение того, как сложные операции формируются из более простых, что позволяет отследить процесс преобразования входных данных в выходные значения. Такой подход позволяет не только понимать логику работы сгенерированного кода, но и выявлять потенциальные ошибки или неоптимальные решения.
В основе CodeCircuit лежит анализ причинно-следственных связей в графе атрибуции на уровне строк кода, что позволяет получить представление о процессе рассуждений модели. Подход демонстрирует эффективность как при анализе корректного, так и некорректного кода, достигая значения площади под ROC-кривой (AUROC) до 79.89% при работе с кодом на языке Python. Высокое значение AUROC указывает на способность системы эффективно различать корректные и некорректные фрагменты кода на основе анализа потока данных и зависимостей между строками.
В основе CodeCircuit лежит использование локальной модели замены (Local Replacement Model) с пер-слойными транскодерами (Per-Layer Transcoders), предназначенной для генерации разреженных векторных представлений признаков. Этот подход позволяет существенно повысить интерпретируемость анализа, поскольку разреженность векторов упрощает отслеживание влияния отдельных признаков на результат. Пер-слойные транскодеры обрабатывают информацию на каждом слое сети последовательно, создавая специализированные представления, а локальная модель замены фокусируется на анализе небольших участков кода, что позволяет более точно определить причинно-следственные связи и упрощает выявление проблемных участков в сгенерированном коде.
Раскрытие Инсайта: Векторные Представления Признаков и Остаточные Потоки
Создание интерпретируемых векторных представлений (feature vectors) является критически важным для понимания внутреннего состояния модели. Эти векторы служат компактным численным представлением информации, обрабатываемой на каждом слое нейронной сети. Интерпретируемость означает, что каждый элемент вектора может быть соотнесен с конкретным аспектом входных данных или промежуточным представлением, что позволяет исследователям и разработчикам анализировать, как модель принимает решения и выявлять потенциальные проблемы в её логике. Без возможности интерпретации внутреннего состояния модели, становится затруднительным отладка, оптимизация и обеспечение надежности её работы, особенно в критически важных приложениях.
Векторы признаков, получаемые из остаточных потоков (residual streams), представляют собой ключевой механизм для отслеживания распространения информации внутри слоев нейронной сети. Остаточные потоки позволяют сохранять и передавать информацию от предыдущих слоев, минуя некоторые преобразования, что облегчает анализ влияния каждого слоя на конечный результат. Эти векторы фиксируют активации и градиенты на различных этапах обработки, формируя последовательность, отражающую, как входные данные преобразуются и обогащаются по мере прохождения через сеть. Таким образом, анализ этих векторов позволяет реконструировать путь информации и понять, какие признаки оказывают наибольшее влияние на принятие решения моделью.
CodeCircuit обеспечивает детальный анализ процесса принятия решений моделью посредством сопоставления векторов признаков с конкретными строками кода в графе атрибуции. Этот подход позволяет установить прямую связь между активациями, происходящими внутри нейронной сети, и соответствующими участками исходного кода, влияющими на эти активации. В результате, исследователи и разработчики получают возможность проследить, как конкретные строки кода способствуют формированию определенных выходных данных модели, что значительно упрощает отладку и анализ её поведения.
Детальный анализ, предоставляемый CodeCircuit, позволяет выявлять потенциальные ошибки в логике модели и повышать корректность кода. В частности, при работе с Python CodeCircuit демонстрирует значение AUPR (Area Under the Precision-Recall curve) на уровне 54.77, что почти вдвое превышает показатели, достигнутые традиционными методами анализа. Данный показатель свидетельствует о значительно улучшенной способности системы точно идентифицировать и выделять проблемные участки кода, влияющие на поведение модели.
Заглядывая В Будущее: Верификация ИИ, Выходящая За Рамки Чёрных Ящиков
Система CodeCircuit знаменует собой важный прогресс в области верификации искусственного интеллекта, предлагая принципиально новый подход к обеспечению прозрачности и интерпретируемости. В отличие от традиционных “черных ящиков”, где логика принятия решений остается скрытой, CodeCircuit позволяет детально проанализировать внутреннюю работу алгоритмов. Это достигается за счет анализа кода, что дает возможность не только выявлять потенциальные ошибки и уязвимости, но и понимать, почему модель пришла к тому или иному выводу. Такой подход критически важен для сфер, где надежность и обоснованность решений имеют первостепенное значение, например, в медицине, финансах или автономных транспортных системах. Представленная реализация на языке C++ демонстрирует высокую точность, обеспечивая низкий уровень ложных срабатываний — всего 80.51%, что существенно превосходит существующие методы верификации.
В отличие от методов “черного ящика”, которые лишь констатируют результат работы искусственного интеллекта, CodeCircuit предлагает принципиально иной подход к верификации. Вместо простого определения, правильно ли работает модель, данный инструмент позволяет детально проанализировать процесс принятия решений. Исследователи получают возможность изучить, какие именно факторы и логические цепочки привели к конкретному выводу, что обеспечивает беспрецедентный уровень прозрачности. Такой подход не только повышает доверие к системам искусственного интеллекта, но и открывает возможности для выявления и исправления ошибок, а также для оптимизации алгоритмов с целью повышения их эффективности и надежности. Глубокое понимание механизмов работы ИИ становится возможным, позволяя перейти от слепого доверия к осознанному контролю и управлению.
Исследования в области верификации искусственного интеллекта продолжаются с целью расширения применимости разработанной платформы CodeCircuit к более сложным моделям и задачам. Экспериментальная реализация на языке C++ демонстрирует впечатляющий уровень ложноположительных срабатываний — всего 80.51%, что значительно превосходит показатели традиционных методов верификации. Этот результат указывает на потенциал подхода CodeCircuit для создания более надежных и устойчивых систем искусственного интеллекта, где прозрачность и интерпретируемость играют ключевую роль в обеспечении безопасности и предсказуемости принимаемых решений. Дальнейшее развитие данной платформы позволит не только подтверждать корректность работы нейронных сетей, но и выявлять потенциальные уязвимости, способствуя созданию более ответственного и доверенного ИИ.
Приоритет интерпретируемости в искусственном интеллекте открывает путь к раскрытию его полного потенциала, одновременно снижая связанные с ним риски. Вместо того, чтобы полагаться на непрозрачные “черные ящики”, где процесс принятия решений остается загадкой, акцент на понятности позволяет тщательно изучить логику работы алгоритмов. Это не только способствует более глубокому пониманию и доверию к системам ИИ, но и позволяет выявлять и устранять потенциальные ошибки или предвзятости. Способность проследить ход мыслей искусственного интеллекта критически важна для применения в областях, требующих высокой степени надежности и ответственности, таких как здравоохранение, финансы и автономное управление. В конечном итоге, прозрачность алгоритмов способствует созданию более надежных, безопасных и полезных систем ИИ, которые действительно служат интересам общества.
Исследование демонстрирует, что надежность сгенерированного кода можно оценить, анализируя внутреннюю структуру вычислительных цепей больших языковых моделей. Это соответствует принципу, высказанному Клодом Шенноном: «Информация — это то, что уменьшает неопределенность». Подобно тому, как Шеннон стремился к минимизации шума в сигнале, данная работа направлена на устранение неопределенности в корректности кода, выявляя структурные особенности, указывающие на его надежность. Анализ графов атрибуции позволяет «разобрать» сложную систему на элементарные компоненты, подобно реверс-инжинирингу, выявляя «узкие места» и потенциальные ошибки в логике работы модели. Такой подход к верификации, не требующий внешнего тестирования, открывает новые возможности для понимания и контроля над поведением искусственного интеллекта.
Куда Дальше?
Представленная работа демонстрирует любопытную закономерность: внутреннее устройство языковой модели, порождающей код, может служить ключом к оценке его корректности. Однако, подобно тому, как схема не гарантирует работоспособность устройства, анализ графов атрибуции — лишь первый шаг. Неизбежно возникает вопрос: насколько устойчивы эти «структурные отпечатки» к незначительным изменениям в модели или входных данных? Хаос, как известно, быстрее порождает понимание, чем документация, и необходимо проверить, не окажется ли эта «белая коробка» иллюзией порядка.
Очевидным направлением исследований является расширение применимости данного метода к более сложным задачам и языкам программирования. Но истинный вызов заключается в преодолении ограничений, связанных с масштабом моделей. Ведь чем сложнее система, тем сложнее выявить в ней закономерности. Нельзя исключать, что в конечном итоге, вместо поиска «правильного» кода, придётся научиться понимать, почему модель генерирует именно этот код, даже если он ошибочен.
В конечном счете, эта работа — не столько о верификации кода, сколько о реверс-инжиниринге интеллекта. Понимание принципов работы языковых моделей — это не просто научная задача, но и способ расшифровки самой реальности. И пусть путь к этому пониманию будет усеян ошибками и парадоксами — именно они и являются настоящими маяками на пути к истине.
Оригинал статьи: https://arxiv.org/pdf/2602.07080.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Искусственный интеллект: хрупкость визуального мышления
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Робот-исследователь: новый подход к автономной навигации
2026-02-10 21:14