Автор: Денис Аветисян
Исследователи представили TermiGen — систему, позволяющую значительно повысить эффективность языковых моделей в задачах, требующих высокой точности и надежности.
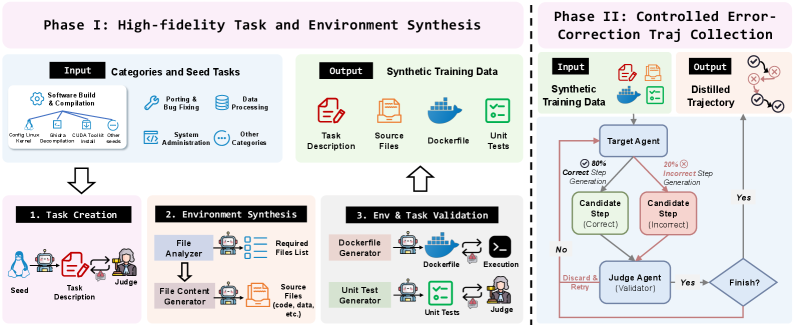
ТермиGen использует синтез данных и стратегию коррекции ошибок для достижения конкурентоспособных результатов с большими проприетарными моделями.
Выполнение сложных задач в интерактивной среде остается серьезным вызовом для современных больших языковых моделей с открытым исходным кодом. В работе ‘TermiGen: High-Fidelity Environment and Robust Trajectory Synthesis for Terminal Agents’ представлен новый подход к синтезу реалистичных сред и надежных траекторий обучения, позволяющий преодолеть ограничения, связанные с недостатком качественных данных и несоответствием между экспертными демонстрациями и ошибками, типичными для менее мощных моделей. Предложенный фреймворк TermiGen обеспечивает значительное повышение производительности, достигая конкурентоспособных результатов с более крупными проприетарными моделями на бенчмарке TerminalBench. Сможет ли этот подход стать основой для создания более надежных и универсальных агентов, способных эффективно действовать в реальном мире?
Вызов надёжных агентов в сложных средах
Создание искусственного интеллекта, способного надёжно функционировать в сложных терминальных средах, остаётся одной из ключевых проблем в области искусственного интеллекта. Непредсказуемость реального мира, с его бесконечным разнообразием сценариев и неполнотой информации, представляет серьёзные трудности для алгоритмов, обученных на ограниченных наборах данных. В отличие от контролируемых сред, характерных для большинства игровых симуляций, реальные терминальные окружения требуют от агентов способности к адаптации, обобщению полученного опыта и устойчивости к шумам и неожиданным ситуациям. Достижение надёжности в таких условиях подразумевает не только точное восприятие окружающей среды, но и способность к планированию действий, учитывающих потенциальные риски и неопределённости, а также к эффективному восстановлению после ошибок и непредвиденных обстоятельств. Разработка таких агентов требует новых подходов к обучению с подкреплением, методов трансферного обучения и разработки робастных алгоритмов восприятия.
Традиционные подходы к обучению агентов, взаимодействующих с реальными терминалами, часто демонстрируют ограниченную способность к обобщению и устойчивости к новым, ранее не встречавшимся ситуациям. Это связано с тем, что такие агенты, как правило, переобучаются на конкретном наборе данных или в специфической среде, теряя способность эффективно функционировать в условиях, отличающихся от тренировочных. Поэтому, для создания надежных терминальных агентов необходимы инновационные стратегии обучения, включающие, например, обучение с подкреплением в разнообразных и непредсказуемых средах, использование методов мета-обучения, позволяющих агенту быстро адаптироваться к новым задачам, и разработку робастных алгоритмов, устойчивых к шумам и неточностям в данных. Эти подходы направлены на повышение способности агента к обобщению и обеспечению его надежной работы в динамичных и сложных терминальных окружениях.
TermiGen: Рецепт для высокоточных сред
TermiGen использует возможности больших языковых моделей (LLM) для автоматической генерации разнообразных и проверяемых сред на основе терминала. LLM применяются для создания как базовых конфигураций окружения, включая установку необходимого программного обеспечения и настройку системных параметров, так и для генерации задач, которые должны быть выполнены в этих средах. Генерируемые окружения могут быть разнообразными по сложности и конфигурации, что позволяет создавать широкий спектр сценариев для тестирования и обучения. Важно отметить, что LLM не просто генерируют текстовые описания окружений, но и предоставляют возможность верификации сгенерированных конфигураций, обеспечивая их корректность и воспроизводимость.
Ключевым элементом TermiGen является надежный синтез окружений, основанный на использовании изолированных Docker-контейнеров. Это обеспечивает воспроизводимость создаваемых сред выполнения задач, поскольку Docker-контейнеры инкапсулируют все необходимые зависимости и конфигурации. Изоляция гарантирует, что окружение, работающее на одной системе, будет функционировать идентично на любой другой системе, где установлен Docker, устраняя проблемы, связанные с различиями в операционных системах, установленных библиотеках или версиях программного обеспечения. Данный подход позволяет гарантировать детерминированное поведение задач и упрощает отладку и верификацию результатов.
В основе TermiGen лежит архитектура «Предлагающий-Оценщик», предназначенная для итеративного улучшения как формулировок задач, так и сложности создаваемых окружений. Процесс начинается с того, что модуль «Предлагающий» генерирует начальное определение задачи и соответствующее окружение. Далее, модуль «Оценщик» анализирует сгенерированное окружение и оценивает его качество с точки зрения соответствия заданным критериям и возможности выполнения поставленной задачи. Результаты оценки используются для корректировки как определения задачи, так и параметров генерации окружения. Этот цикл «предложение-оценка-коррекция» повторяется многократно, что позволяет автоматически оптимизировать сложность окружения и точность формулировки задачи, обеспечивая генерацию высококачественных и реалистичных терминальных сред.
Повышение робастности с помощью инъекции ошибок
В процессе обучения агента применяется метод инъекции ошибок, заключающийся в преднамеренном внесении возмущений в обучающие данные. Данная техника направлена на повышение устойчивости агента к непредсказуемым ситуациям и ошибкам, которые могут возникнуть в реальной среде. Искусственное создание таких возмущений позволяет модели научиться корректно реагировать на нештатные сценарии и улучшить общую надежность её работы, что особенно важно для приложений, требующих высокой степени отказоустойчивости.
Метод инъекции ошибок расширяет возможности контролируемой тонкой настройки путем генерации траекторий, устойчивых к типичным ошибкам и пограничным случаям. В отличие от обучения исключительно на смоделированных данных, инъекция ошибок намеренно вводит возмущения в обучающие данные, заставляя агента учиться справляться с непредсказуемыми ситуациями. Это позволяет создавать более надежные и отказоустойчивые системы, способные эффективно функционировать в реальных условиях, где неизбежны отклонения от идеальных сценариев. Генерация таких траекторий повышает обобщающую способность агента и снижает вероятность сбоев при столкновении с неожиданными входными данными или ошибками в процессе выполнения.
В нашей реализации в качестве базовой модели используется Qwen-2.5-Coder-32B, масштабированная с помощью DeepSpeed ZeRO-3 для повышения эффективности обучения. Проведение обучения с внедрением коррекции ошибок позволило добиться прироста производительности в 2.5% на бенчмарке TerminalBench по сравнению с обучением исключительно на симулированных данных. Использование DeepSpeed ZeRO-3 позволило эффективно распределить вычислительную нагрузку и обучить модель на больших объемах данных, что способствовало повышению устойчивости к ошибкам.
Строгая оценка с помощью TerminalBench
Для всесторонней оценки возможностей разработанного агента была использована платформа TerminalBench, представляющая собой стандартизированный комплекс тестов. Данная платформа позволяет проводить объективное сравнение с существующими моделями и измерять способность агента к обобщению и решению разнообразных задач в реалистичных условиях. Использование TerminalBench обеспечивает надежную и воспроизводимую оценку, позволяя точно определить сильные и слабые стороны агента, а также отслеживать прогресс в процессе его дальнейшей разработки и совершенствования. Такой подход к оценке позволяет не только подтвердить эффективность предложенного решения, но и выявить области, требующие дополнительного внимания.
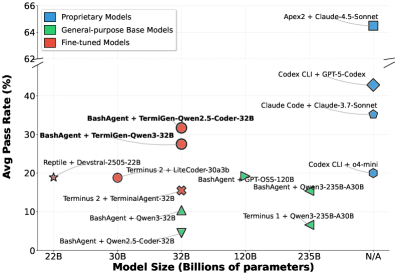
Количественная оценка, основанная на показателе успешности на платформе TerminalBench, демонстрирует существенное повышение устойчивости и обобщающей способности разработанных агентов. Достигнутый показатель в 31.3% свидетельствует о значительном прогрессе в данной области. Этот результат позволяет объективно измерить способность агентов к решению разнообразных задач в различных условиях, что особенно важно для оценки их практической применимости и надежности. Повышенная устойчивость к изменениям в окружающей среде и способность к адаптации к новым ситуациям являются ключевыми факторами, определяющими эффективность агентов в реальных сценариях использования.
Полученные результаты демонстрируют значительный прорыв в области открытых языковых моделей. Достигнутый показатель успешности в 31.3% на платформе TerminalBench устанавливает новый стандарт производительности, превосходя предыдущие решения, такие как o4-mini (20.0%). Предложенный подход обеспечивает четкую и объективную метрику для сравнения с существующими моделями, включая Reptile, а также позволяет оценить способность агентов к выполнению задач без предварительного обучения — так называемую “Zero-Shot Performance”. Это открывает возможности для более эффективной разработки и оценки агентов, способных к адаптации и решению новых задач без необходимости в дополнительной настройке.
К верифицируемым ИИ-агентам
Исследования демонстрируют возможность применения формальной верификации, используя инструменты наподобие `Coq` и `SMT Solver`, для обеспечения корректности работы интеллектуальных агентов. Данный подход позволяет предоставить математически строгие гарантии относительно поведения агента в критически важных приложениях, таких как автономное управление или системы принятия решений в медицине. Используя формальные методы, разработчики могут доказать, что агент будет действовать предсказуемо и безопасно в заданных условиях, избегая нежелательных или опасных последствий, что особенно важно для систем, где ошибка недопустима. По сути, это переход от тестирования, которое может лишь показать наличие ошибок, к доказательству отсутствия таковых.
Возможность предоставления формальных гарантий относительно поведения агентов искусственного интеллекта имеет решающее значение для применения в критически важных областях, таких как автономное вождение, здравоохранение и финансовые системы. В этих сценариях даже небольшие ошибки могут привести к серьезным последствиям, поэтому недостаточно полагаться только на тестирование и эмпирическую оценку. Формальная верификация, использующая математически строгие методы, позволяет доказать, что агент будет вести себя предсказуемо и безопасно в заданном диапазоне условий. Этот подход гарантирует, что система соответствует определенным спецификациям, исключая возможность возникновения непредвиденных и потенциально опасных ситуаций. Например, можно формально доказать, что агент никогда не нарушит определенные ограничения безопасности, даже при столкновении с необычными входными данными или непредсказуемыми обстоятельствами, обеспечивая тем самым повышенную надежность и доверие к системе.
Сочетание обучения на данных и формальных методов открывает путь к созданию искусственного интеллекта, отличающегося не только высокой надежностью, но и возможностью верификации его работы. Традиционные подходы к обучению ИИ часто приводят к системам, поведение которых сложно предсказать и доказать. Однако, интегрируя статистические методы обучения с логическими системами и математическими доказательствами, исследователи стремятся создавать агентов, чьи действия могут быть формально подтверждены и гарантированы. Этот симбиоз позволяет построить системы, способные адаптироваться к новым данным и одновременно предоставлять гарантии корректности, что особенно важно в критически важных областях, таких как автономное управление, медицина и финансы. Результатом является ИИ, который не просто функционирует, но и предоставляет доказательства своей надежности и предсказуемости.
Представленная работа демонстрирует стремление к математической чистоте в области обучения агентов. Разработчики TermiGen, подобно тем, кто стремится к доказательству корректности алгоритма, а не полагается лишь на эмпирические результаты, создали фреймворк, основанный на синтезе высококачественных данных и стратегии коррекции ошибок. Такой подход позволяет достичь сопоставимых результатов с более крупными проприетарными моделями, подтверждая, что надежность и точность достигаются не размером модели, а качеством данных и алгоритмов. Как однажды заметил Брайан Керниган: «Отладка — это процесс удаления ошибок; программирование — процесс их добавления». В контексте TermiGen, процесс отладки заключается в систематической коррекции ошибок в синтезированных данных, что позволяет создать действительно надежного агента.
Что Дальше?
Представленная работа, несомненно, демонстрирует возможность создания эффективных агентов на базе открытых языковых моделей посредством тщательной генерации данных и коррекции ошибок. Однако, за кажущейся элегантностью решения скрывается фундаментальный вопрос: насколько действительно «интеллектуальна» система, достигшая успеха за счет искусственно созданной среды? Истинное мерило — не победа на синтетических тестах, а способность к обобщению и адаптации в условиях, далеких от идеализированных.
Будущие исследования должны сосредоточиться на преодолении разрыва между синтетической точностью и практической надежностью. Необходимо разработать метрики, оценивающие не просто производительность, но и устойчивость к непредсказуемым воздействиям реального мира. Иначе говоря, алгоритм должен быть доказуемо корректным, а не просто «работать в лаборатории».
Более того, важно осознавать, что текущий подход, хотя и эффективен, требует значительных вычислительных ресурсов для генерации данных. Поиск алгоритмов, способных к самообучению и адаптации с минимальным объемом предварительно размеченных данных, представляется задачей, достойной внимания. В конечном счете, красота алгоритма заключается не в его сложности, а в его способности решать задачу наиболее простым и элегантным способом.
Оригинал статьи: https://arxiv.org/pdf/2602.07274.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Искусственный интеллект: хрупкость визуального мышления
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Робот-исследователь: новый подход к автономной навигации
2026-02-11 05:43