Автор: Денис Аветисян
Новая система автоматизирует подготовку научных данных, позволяя исследователям сосредоточиться на анализе и новых открытиях, а не на рутинной обработке информации.
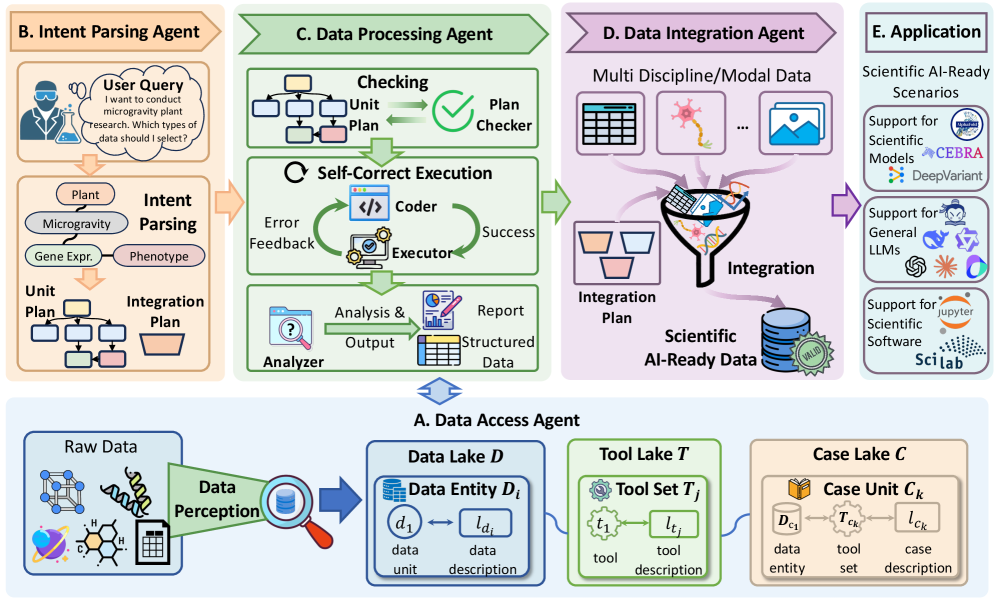
SciDataCopilot — это агентированный фреймворк, обеспечивающий стандартизацию и интеграцию разнородных научных данных для эффективного применения ИИ в научных исследованиях и повышения воспроизводимости результатов.
Несмотря на успехи искусственного интеллекта в обработке текста и генерации гипотез, подготовка и структурирование экспериментальных данных остается критическим узким местом для ускорения научных открытий. В данной работе, посвященной разработке фреймворка ‘SciDataCopilot: An Agentic Data Preparation Framework for AGI-driven Scientific Discovery’, предложен автономный агентский подход к обработке научных данных, позволяющий автоматически преобразовывать разнородные сырые данные в стандартизированные ресурсы, готовые для анализа. Данный подход позиционирует готовность данных как базовый операционный примитив, обеспечивая основу для воспроизводимых и масштабируемых систем. Сможет ли SciDataCopilot стать катализатором перехода к экспериментально-ориентированному научному общему интеллекту и значительно ускорить темпы научных исследований?
Преодоление Узких Мест: Данные в Научном ИИ
Несмотря на стремительное развитие искусственного интеллекта, существенным препятствием для его эффективного применения в науке остается сложность подготовки данных для машинного обучения. Традиционные методы обработки научных данных часто характеризуются хрупкостью, требуют значительных ручных усилий и испытывают трудности при работе с огромными объемами и разнообразием современных наборов данных. Это приводит к снижению воспроизводимости результатов и ограничивает возможности ученых в полной мере использовать потенциал искусственного интеллекта для анализа и открытия новых знаний. Подготовка данных, включающая очистку, трансформацию и форматирование, часто занимает большую часть времени исследователя, отвлекая от собственно научного поиска и замедляя темпы прогресса.
Традиционные конвейеры обработки данных в науке зачастую оказываются хрупкими и трудоемкими, не справляясь с постоянно растущим объемом и разнообразием данных, поступающих из гетерогенных источников. Современные научные исследования генерируют информацию в различных форматах — от результатов моделирования и экспериментальных данных до текстовых описаний и изображений — каждое из которых требует индивидуальной обработки и преобразования. Ручная настройка и поддержка таких конвейеров не только отнимает ценное время у исследователей, но и создает узкие места, препятствующие быстрому анализу и проверке гипотез. Эта проблема особенно остро ощущается при работе с крупными наборами данных, где даже небольшие ошибки или несоответствия могут привести к серьезным искажениям в результатах, ставя под сомнение всю научную работу.
Фрагментация научных данных и сложность их подготовки серьезно препятствуют воспроизводимости исследований и ограничивают возможности применения искусственного интеллекта. Традиционные методы обработки данных требуют значительных временных затрат и часто не справляются с разнообразием и объемом современных научных наборов данных. SciDataCopilot решает эту проблему, обеспечивая ускорение обработки данных до 20 раз по сравнению с ручными процессами. Это позволяет ученым быстрее получать результаты, повышает надежность исследований и открывает новые перспективы для анализа сложных научных задач, используя весь потенциал современных алгоритмов машинного обучения.

Научные Данные, Подготовленные к Будущему
Вместо традиционных данных, обозначенных как “AI-Ready”, предлагается переход к концепции `ScientificAIReadyData` — наборам данных, которые не просто подготовлены для использования в алгоритмах машинного обучения, но и структурированы и валидированы с учетом специфики конкретных научных задач. Это подразумевает не только соответствие формальным требованиям к данным, но и наличие метаданных, описывающих контекст, происхождение и ограничения данных, что обеспечивает их пригодность для проведения научных исследований и анализа в соответствующей области. Такой подход обеспечивает более высокую надежность и воспроизводимость результатов, полученных с использованием данных.
В основе предлагаемого подхода лежит платформа SciDataCopilot — агентская система, предназначенная для полной автоматизации жизненного цикла подготовки данных. Данный фреймворк охватывает все этапы, начиная с извлечения и очистки данных, и заканчивая их трансформацией и валидацией для конкретных научных задач. SciDataCopilot функционирует как автоматизированный конвейер, минимизирующий необходимость ручного вмешательства и обеспечивая воспроизводимость процесса подготовки данных. В отличие от традиционных методов, требующих значительных временных затрат, SciDataCopilot позволяет значительно ускорить подготовку данных для анализа.
В основе функционирования фреймворка лежит агент IntentParsingAgent, предназначенный для анализа и интерпретации запросов пользователя, сформулированных на естественном языке. Этот агент осуществляет семантическое разложение входных данных, определяя цели и намерения пользователя относительно подготовки данных. Обеспечение соответствия (TaskAlignment) достигается за счет непрерывного сопоставления действий агента с исходным запросом, гарантируя, что все этапы обработки данных направлены на достижение поставленной задачи. IntentParsingAgent динамически адаптирует процесс подготовки данных, обеспечивая релевантность и точность результатов в соответствии с потребностями пользователя.
Автоматизация этапов подготовки данных позволяет значительно сократить время и трудозатраты на анализ. В рамках предложенного подхода достигнуто 20-кратное увеличение скорости обработки данных по сравнению с ручными методами. В качестве примера, обработка набора данных Marble Point занимает всего 3.5 минуты, в то время как квалифицированному специалисту требуется 75 минут для выполнения аналогичной задачи.
Агентский Рабочий Процесс: От Сырых Данных к Практическим Выводaм
В основе работы SciDataCopilot лежит совместный `AgenticWorkflow`, использующий специализированных агентов для обработки разнородных источников данных (`HeterogeneousDataSources`). В частности, агент `DataAccessAgent` отвечает за извлечение данных из различных форматов и систем, включая базы данных, файлы и веб-API. Это позволяет системе работать с данными, представленными в различных структурах и с разной степенью организации, автоматически адаптируясь к особенностям каждого источника. Использование специализированных агентов обеспечивает модульность и масштабируемость системы, упрощая добавление поддержки новых источников данных и типов задач.
Агент обработки данных (DataProcessingAgent) выполняет планы обработки данных, включающие стандартизацию данных (DataStandardization) для обеспечения их согласованности. Этот процесс включает в себя приведение разнородных данных к единому формату и структуре, что необходимо для последующего анализа и интеграции. Стандартизация включает в себя, в частности, нормализацию числовых значений, унификацию единиц измерения и приведение текстовых данных к единому регистру и формату. Применение стандартизации данных позволяет избежать ошибок, связанных с несогласованностью данных, и повышает надежность результатов анализа.
Агент интеграции данных (DataIntegrationAgent) осуществляет консолидацию обработанных данных в унифицированный формат ScientificAIReadyData. Этот формат предназначен для непосредственного использования в задачах научного искусственного интеллекта, обеспечивая совместимость и упрощая процесс анализа. Унификация включает в себя стандартизацию структуры данных, типов данных и единиц измерения, что позволяет объединять информацию из разнородных источников без потери информации или внесения искажений. В результате формируется единый, структурированный набор данных, готовый к использованию в алгоритмах машинного обучения и других аналитических задачах.
В ходе тестирования фреймворка на разнородных наборах данных, включая данные нейронаук, наук о Земле и катализа ферментов, продемонстрировано, что выполнение задач, связанных с нейронаукой, занимает от 9.2 до 15.6 минут, что значительно быстрее, чем время, необходимое эксперту-человеку — от 30 до 51.9 минут. Кроме того, была создана база данных катализа ферментов, содержащая 214,104 записи, что в 19.5 раз превышает объем базы данных P450Rdb-v2.0.
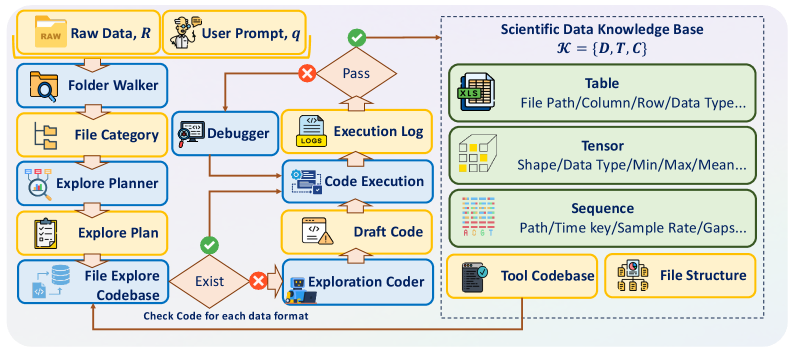
Воспроизводимость и Будущее Научных Данных
Основополагающим принципом научной достоверности является воспроизводимость результатов, и разработанный фреймворк напрямую её поддерживает, предоставляя данные в унифицированном формате — так называемые “ScientificAIReadyData”. Предоставление данных в согласованном виде позволяет другим исследователям независимо верифицировать полученные результаты, исключая погрешности, связанные с различиями в обработке и представлении информации. Это не просто упрощает процесс повторного анализа, но и позволяет строить более надежные и объективные научные выводы, формируя прочный фундамент для дальнейших исследований и инноваций. Унификация формата данных способствует повышению прозрачности научных процессов и укрепляет доверие к полученным результатам.
Автоматизация подготовки данных значительно снижает вероятность ошибок, связанных с человеческим фактором, и обеспечивает возможность независимой проверки полученных результатов. Традиционно, ручная обработка данных, включающая очистку, форматирование и преобразование, является источником многочисленных неточностей и несоответствий, которые могут повлиять на достоверность научных исследований. Автоматизированные системы, напротив, гарантируют последовательное и стандартизированное применение протоколов обработки данных, минимизируя субъективные искажения и обеспечивая воспроизводимость экспериментов. Это позволяет другим исследователям независимо верифицировать результаты, подтверждая их надежность и способствуя более быстрому и эффективному прогрессу науки.
Упрощение и стандартизация подготовки научных данных оказывает существенное влияние на возможности сотрудничества между исследователями. Когда данные представлены в единообразном и доступном формате, ученые из разных институтов и дисциплин могут легко обмениваться результатами, проверять выводы друг друга и строить совместные проекты. Это устраняет барьеры, связанные с несовместимостью форматов и необходимостью повторной обработки информации, что, в свою очередь, значительно ускоряет темпы научных открытий. Благодаря более эффективному обмену знаниями и ресурсами, исследовательское сообщество в целом получает возможность решать более сложные задачи и достигать прогресса в различных областях науки.
Предвидится, что будущее науки будет характеризоваться смещением фокуса исследователей с рутинных задач подготовки данных на формулирование ключевых вопросов и анализ результатов. Система SciDataCopilot призвана автоматизировать сложные процессы обработки и стандартизации научных данных, обеспечивая ускорение работы в 20 раз. Это позволит ученым сосредоточиться на инновациях, а не на технических деталях, и создавать значительно более крупные и унифицированные наборы данных для глубокого анализа. Такой подход обещает не только повышение эффективности научных исследований, но и ускорение темпов открытий в различных областях знаний.
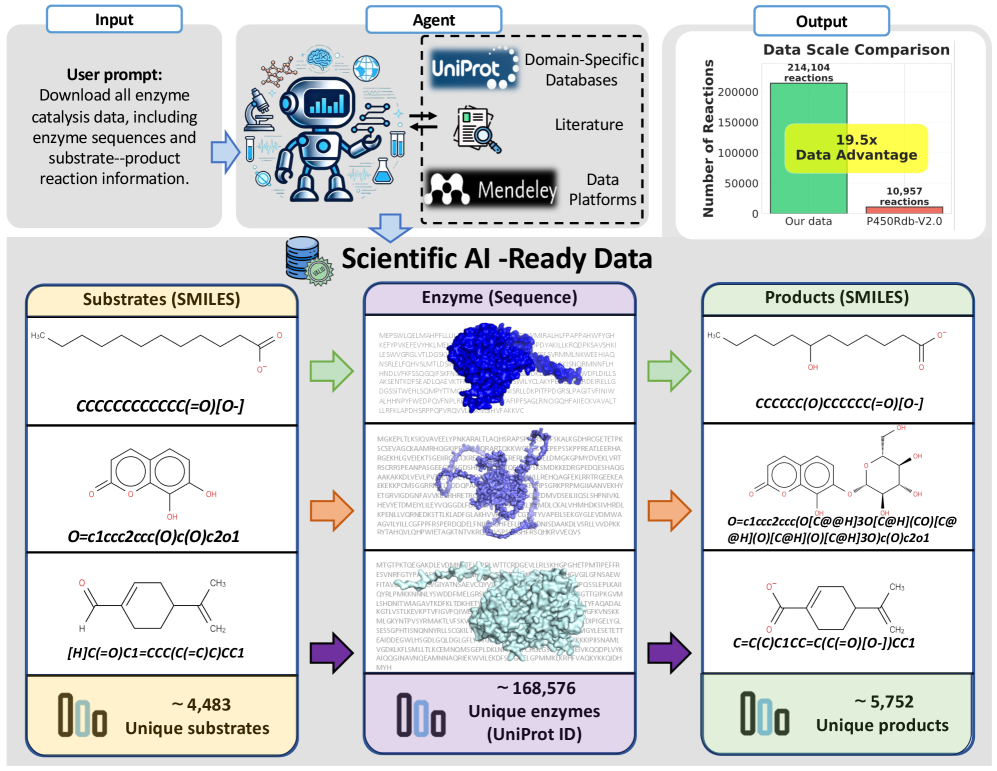
Представленная работа демонстрирует стремление к созданию систем, способных к адаптации и эволюции в условиях постоянно меняющихся данных. SciDataCopilot, автоматизируя подготовку научных данных, позволяет преодолеть ключевую проблему воспроизводимости исследований. Как однажды заметила Грейс Хоппер: «Лучший способ предсказать будущее — это создать его». Этот принцип находит отражение в SciDataCopilot, поскольку система не просто обрабатывает данные, а активно формирует основу для будущих научных открытий. Автоматизация и стандартизация, предложенные в рамках данной работы, — это не просто техническое решение, а шаг к созданию более надежной и предсказуемой научной среды.
Что дальше?
Представленная работа, автоматизируя подготовку научных данных, лишь обнажает глубину проблемы. Стандартизация — это временное решение, попытка навести порядок в хаосе, но сама природа научных данных изменчива. Каждая абстракция несёт груз прошлого, каждое преобразование — потерю информации. Попытки создать “AI-ready” данные — это, по сути, попытка зафиксировать текущее понимание, обрекая будущие исследования на необходимость повторной адаптации. Долговечность системы определяется не её функциональностью, а способностью к эволюции.
Настоящим вызовом является не создание идеальных наборов данных, а разработка систем, способных к самообучению и адаптации к новым, непредсказуемым форматам и источникам информации. Необходимо сместить фокус с жесткой стандартизации на гибкие, динамические модели представления данных, способные сохранять контекст и происхождение информации. Только медленные изменения сохраняют устойчивость, и именно в этом направлении следует двигаться, избегая соблазна быстрых, но непрочных решений.
В конечном счете, SciDataCopilot — это лишь очередной шаг в бесконечном процессе, в котором инструменты автоматизации становятся все более сложными, но фундаментальная проблема — интерпретация и интеграция знаний — остается нерешенной. Вопрос не в том, как автоматизировать научные открытия, а в том, как создать системы, способные к осмысленному диалогу с постоянно меняющимся миром данных.
Оригинал статьи: https://arxiv.org/pdf/2602.09132.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Искусственный интеллект: хрупкость визуального мышления
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Робот-исследователь: новый подход к автономной навигации
2026-02-11 12:34