Автор: Денис Аветисян
Исследователи продемонстрировали высокопроизводительный симулятор квантовых цепей, оптимизированный для ARM-процессоров и использующий векторную обработку.
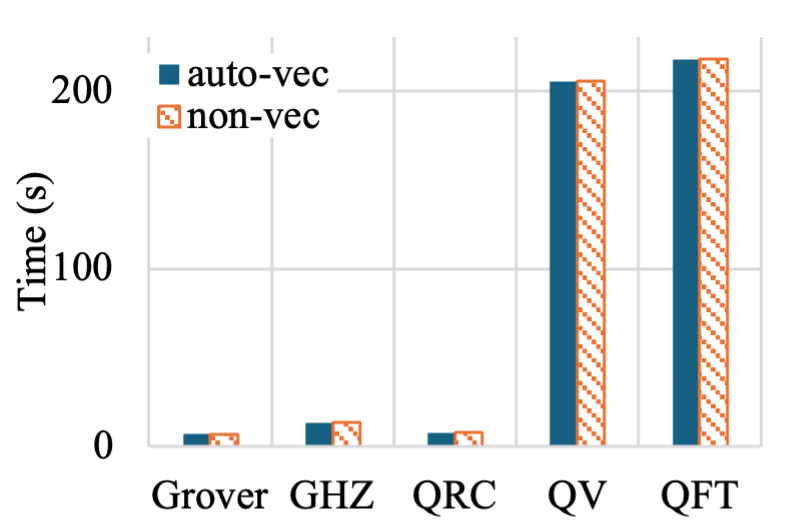
Разработанный симулятор обеспечивает переносимость и значительные улучшения скорости на различных ARM-платформах благодаря использованию векторной архитектуры SVE.
Несмотря на растущую потребность в высокопроизводительных вычислениях для квантового моделирования, обеспечение переносимости и эффективности кода на различных архитектурах остается сложной задачей. В данной работе, посвященной ‘High-performance Vector-length Agnostic Quantum Circuit Simulations on ARM Processors’, предложен векторно-агностичный подход к моделированию квантовых схем, использующий преимущества векторных расширений SVE на ARM-процессорах. Реализация, протестированная на платформах NVIDIA Grace, AWS Graviton3 и Fujitsu A64FX, демонстрирует ускорение до 4.5x по сравнению с традиционными методами. Какие дальнейшие оптимизации и архитектурные решения позволят расширить возможности переносимого квантового моделирования и раскрыть потенциал новых векторных архитектур?
Предел масштабируемости: Квантовое моделирование в эпоху экспоненциального роста
Моделирование квантовых систем играет ключевую роль в совершении научных открытий, однако сложность вычислений резко возрастает с увеличением размера рассматриваемой системы. Это связано с тем, что для точного описания квантового состояния необходимо учитывать экспоненциально растущее число параметров, что быстро превышает возможности даже самых мощных современных компьютеров. Например, для описания всего лишь нескольких десятков взаимодействующих кубитов требуется объем памяти, сравнимый с объемом памяти всех суперкомпьютеров мира. Подобное ограничение серьезно препятствует прогрессу в таких областях, как материаловедение, химия и разработка новых лекарственных препаратов, где понимание квантовых явлений имеет решающее значение для создания инновационных материалов и эффективных методов лечения. Таким образом, преодоление вычислительных ограничений является критически важной задачей для дальнейшего развития квантовых исследований.
Традиционные методы квантового моделирования сталкиваются с серьезными трудностями при увеличении размера рассматриваемой системы. Проблема заключается в экспоненциальном росте вектора состояния — математического описания квантовой системы, — требующего хранения и обработки все большего объема информации с добавлением каждого нового элемента. Например, для описания взаимодействия всего лишь нескольких атомов требуется вычислительная мощность, недоступная даже самым современным суперкомпьютерам. Этот экспоненциальный рост существенно ограничивает возможности применения квантового моделирования в таких важных областях, как материаловедение и разработка новых лекарственных препаратов, где необходимо исследовать сложные молекулярные структуры и предсказывать их свойства. Невозможность адекватного моделирования больших систем препятствует созданию новых материалов с заданными характеристиками и замедляет поиск эффективных лекарственных средств, что подчеркивает острую необходимость в разработке более эффективных алгоритмов и аппаратных решений.
Для преодоления ограничений, связанных с моделированием квантовых систем, необходимы инновационные алгоритмы и аппаратное ускорение. Исследователи активно разрабатывают методы, снижающие вычислительную сложность, такие как тензорные сети и вариационные квантовые алгоритмы, позволяющие аппроксимировать решения, сохраняя при этом приемлемую точность. Параллельно с этим, значительные усилия направлены на создание специализированного аппаратного обеспечения, включая квантовые процессоры и FPGA-ускорители, способные эффективно выполнять необходимые вычисления. Комбинация передовых алгоритмов и аппаратных решений открывает перспективы для моделирования более сложных квантовых систем, что критически важно для прогресса в материаловедении, химии и разработке новых лекарственных препаратов. E=mc^2 Успешная реализация этих подходов позволит значительно расширить границы познания в области квантовой механики и использовать ее потенциал для решения практических задач.
Полная симуляция волновой функции, несмотря на свою точность, сталкивается с серьезными ограничениями, связанными с пропускной способностью памяти. В процессе моделирования квантовых систем, объем данных, описывающих состояние системы, растет экспоненциально с увеличением числа кубитов или частиц. Это означает, что для хранения и обработки информации о состоянии системы требуется все больше и больше памяти, и скорость, с которой данные могут быть переданы между памятью и процессором, становится узким местом. Даже при использовании самых современных технологий памяти и высокопроизводительных вычислительных систем, пропускная способность может оказаться недостаточной для эффективной симуляции сложных квантовых систем, что ограничивает возможности исследований в материаловедении, химии и разработке лекарств. Решение этой проблемы требует разработки новых алгоритмов, которые минимизируют объем необходимых данных, а также использования специализированного аппаратного обеспечения, способного обеспечить более высокую пропускную способность и параллельную обработку данных.
Векторизация вычислений: Ключ к ускорению квантовых симуляций
Использование возможностей векторизации современных процессоров является ключевым фактором для ускорения квантовых симуляций. Векторизация позволяет выполнять одну и ту же операцию над несколькими элементами данных одновременно, значительно повышая пропускную способность вычислений. Квантовые алгоритмы часто включают в себя повторяющиеся операции над большими массивами комплексных чисел, представляющих квантовые состояния. Вместо последовательного выполнения этих операций над каждым элементом, векторизация позволяет процессору выполнять их параллельно, используя SIMD (Single Instruction, Multiple Data) инструкции. Это приводит к существенному снижению времени выполнения симуляций, особенно для систем с большим числом кубитов. Эффективность векторизации зависит от архитектуры процессора, используемых компиляторов и степени оптимизации кода для использования векторных инструкций.
Ограничения пропускной способности памяти являются критическим фактором, сдерживающим производительность квантового моделирования. Методы, такие как адаптивный доступ к памяти на основе длины векторных регистров (VLEN-Adaptive Memory Access), позволяют динамически настраивать размер блоков данных, передаваемых между памятью и процессором, в соответствии с текущей длиной VLEN, оптимизируя использование пропускной способности. Дополнительно, оптимизация буферизации (Buffering Optimization) подразумевает предварительную загрузку данных, необходимых для вычислений, в более быструю память (например, кэш), что снижает количество обращений к основной памяти. Комбинация этих техник позволяет минимизировать задержки, связанные с обменом данными, и значительно повысить эффективность вычислений в квантовом моделировании.
Эффективное управление циклами, в частности, применение мелкозернистого управления (Fine-Grained Loop Control), направлено на повышение локальности данных и, как следствие, оптимизацию использования векторных инструкций. Мелкозернистое управление подразумевает разбиение итераций цикла на более мелкие блоки, что позволяет более эффективно использовать кэш-память и минимизировать задержки, связанные с обращением к основной памяти. Это достигается путем организации доступа к данным таким образом, чтобы последовательные обращения к памяти осуществлялись к соседним ячейкам, что максимизирует вероятность попадания данных в кэш первого уровня. Оптимизация структуры циклов, включая уменьшение количества ветвлений и переупорядочивание операций внутри цикла, способствует повышению эффективности использования векторных регистров и снижению накладных расходов, связанных с управлением циклом. В результате, повышается общая производительность квантового моделирования за счет более эффективного использования аппаратных ресурсов процессора.
Слияние вентилей (Gate Fusion) представляет собой оптимизацию, направленную на снижение количества инструкций, выполняемых в квантовом моделировании. Этот процесс заключается в объединении последовательных операций, таких как применение нескольких однокубитных вентилей или последовательность CNOT-вентилей, в единую, более сложную операцию. В результате уменьшается общее число инструкций, что напрямую влияет на повышение арифметической интенсивности — отношения количества арифметических операций к количеству операций доступа к памяти. Более высокая арифметическая интенсивность позволяет эффективнее использовать вычислительные ресурсы процессора и снижает задержки, связанные с обменом данными между процессором и памятью, что в конечном итоге приводит к значительному увеличению общей производительности симуляции.

Аппаратное ускорение и независимость от длины вектора: Путь к масштабируемым симуляциям
Симулятор Qsim предоставляет платформу для оценки оптимизаций производительности на различных аппаратных архитектурах. Он позволяет проводить измерения и анализ эффективности кода на процессорах, таких как AWS Graviton3, NVIDIA Grace и Fujitsu A64FX. Это достигается за счет использования аппаратных счетчиков производительности, что позволяет точно измерять такие показатели, как коэффициент снижения количества инструкций и средняя длина активного вектора. Такой подход обеспечивает возможность сравнительного анализа и оптимизации программного обеспечения для различных типов процессоров, а также выявления архитектурных особенностей, влияющих на производительность.
Для оценки оптимизаций производительности, платформа `Qsim Simulator` использовалась для тестирования процессоров `AWS Graviton3`, `NVIDIA Grace` и `Fujitsu A64FX`. Исследования включали измерение ключевых показателей производительности на каждой архитектуре, с целью определения эффективности оптимизаций на различных аппаратных платформах. В процессе тестирования анализировались такие параметры, как частота инструкций, использование векторных регистров и общая скорость выполнения, позволяя провести сравнительный анализ производительности между различными процессорами и выявить особенности каждой архитектуры.
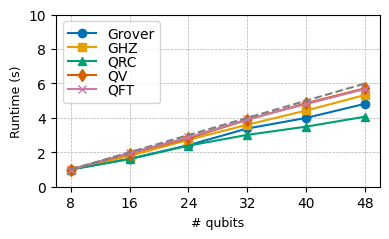
Архитектуры, не зависящие от длины вектора (Vector-Length Agnostic, VLA), такие как ARM Scalable Vector Extension (SVE) и RISC-V Vector Extension (RVV), предоставляют значительные преимущества за счет адаптации к различным аппаратным возможностям. В отличие от традиционных SIMD-инструкций с фиксированной длиной вектора, VLA позволяет коду выполняться эффективно на процессорах с разной шириной векторных регистров без необходимости перекомпиляции. Это достигается за счет динамического определения длины вектора во время выполнения, что обеспечивает оптимальное использование доступных ресурсов и повышает переносимость кода между различными платформами. Тестирование на процессорах AWS Graviton3, NVIDIA Grace и Fujitsu A64FX подтверждает эффективность данного подхода, демонстрируя существенное увеличение производительности при использовании единой кодовой базы.
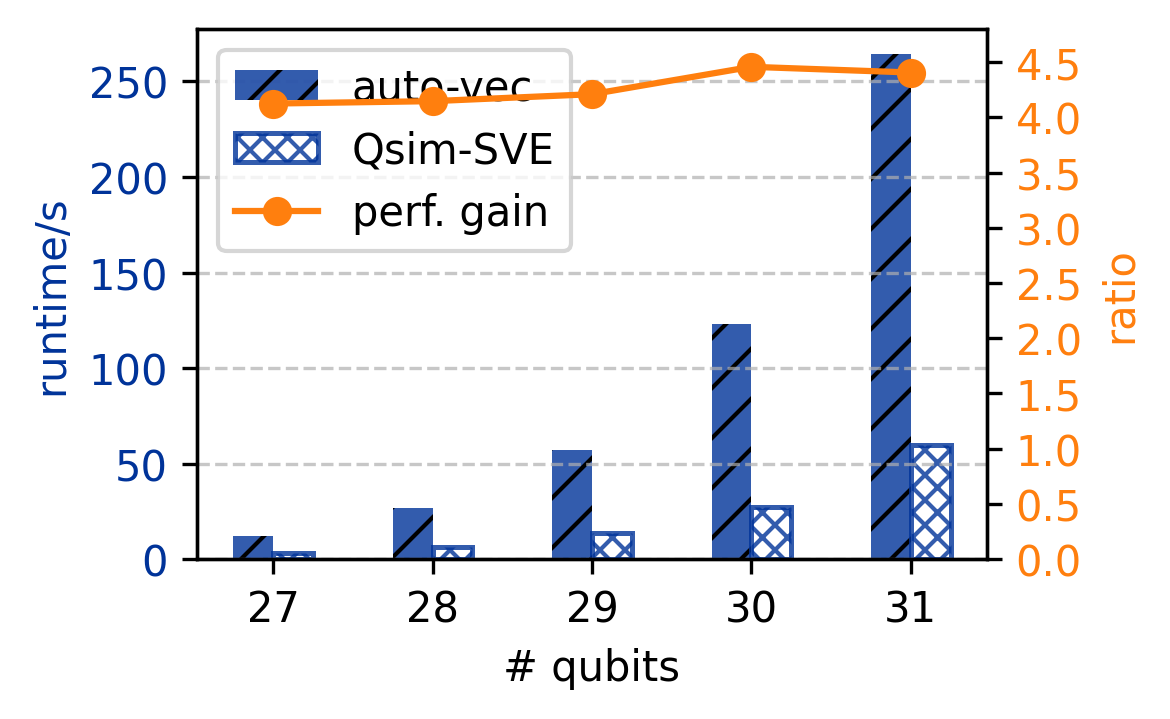
Для оценки оптимизаций производительности в симуляторе `Qsim` используются счетчики аппаратного обеспечения (Hardware Performance Counters). Измерение коэффициента снижения количества инструкций (Instruction Reduction Ratio) и средней активной длины вектора (Average Active Vector Length) позволило добиться ускорения до 4.5x на процессоре Fujitsu A64FX, 2.5x на NVIDIA Grace и 1.5x на AWS Graviton3. Важно отметить, что указанные улучшения достигнуты с использованием единой кодовой базы, что подтверждает эффективность предложенных оптимизаций на различных архитектурах.
При тестировании на архитектурах Fujitsu A64FX и NVIDIA Grace, средняя длина активно используемых векторов (Average Active Vector Length) достигла 12 из 16 и 3.5 из 4 соответственно. Это свидетельствует об эффективном использовании векторных регистров и указывает на то, что оптимизации позволяют максимально задействовать возможности векторной обработки данных на данных платформах. Высокие значения средней длины активного вектора подтверждают, что большая часть векторных инструкций оперирует значительным количеством данных, что положительно сказывается на производительности.

Влияние оптимизаций: От масштабируемых симуляций к новым научным открытиям
Сочетание оптимизированных алгоритмов и современного аппаратного обеспечения значительно улучшает так называемую «сильную масштабируемость» квантовых симуляций. В частности, это позволяет эффективно распределять вычислительную нагрузку между большим количеством квантовых битов и процессоров, сохраняя при этом высокую точность результатов. Достигается это за счет усовершенствованных методов компиляции квантовых схем, снижения ошибок, а также за счет разработки специализированных архитектур квантовых компьютеров. Благодаря этому, сложные квантовые модели, требующие экспоненциального роста ресурсов при увеличении размера системы, становятся доступными для исследования на реальном оборудовании, открывая новые возможности для моделирования сложных материалов, химических реакций и фундаментальных физических явлений. Повышение сильной масштабируемости является ключевым шагом на пути к созданию практически полезных квантовых симуляторов.
Алгоритмы, такие как кванформулы преобразования Фурье и алгоритм Гровера, демонстрируют значительное ускорение благодаря оптимизированным методам вычислений. В частности, повышение эффективности достигается за счет сокращения числа необходимых квантовых операций и минимизации ошибок, возникающих в процессе вычислений. Например, оптимизация схемы реализации QFT позволяет существенно снизить время выполнения, что критически важно для моделирования сложных квантовых систем. Алгоритм Гровера, используемый для поиска в неструктурированных данных, также выигрывает от оптимизаций, позволяющих уменьшить количество итераций, необходимых для достижения желаемой точности, тем самым открывая возможности для решения задач, ранее считавшихся недоступными для квантовых компьютеров.
Значительно возросшая производительность квантовых симуляций открывает двери для решения задач, ранее считавшихся непосильными. В материаловедении это позволяет моделировать сложные структуры и предсказывать свойства новых материалов с беспрецедентной точностью, ускоряя разработку инновационных технологий. В области разработки лекарств, симуляции на качественно новом уровне позволяют исследовать взаимодействия молекул и предсказывать эффективность потенциальных препаратов, сокращая время и затраты на клинические испытания. Кроме того, расширенные возможности квантовых вычислений позволяют углубить понимание фундаментальных физических явлений, таких как высокотемпературная сверхпроводимость и динамика элементарных частиц, приближая науку к ответам на ключевые вопросы мироздания.
Эффективность подхода, известного как параллелизм по группам состояний, проявляется в тесной взаимосвязи между аппаратным и программным обеспечением. Данный метод позволяет распараллеливать вычисления, распределяя обработку различных групп квантовых состояний между отдельными вычислительными узлами. Реализация такого подхода требует не только специализированного аппаратного обеспечения, способного эффективно обрабатывать квантовые данные, но и оптимизированного программного обеспечения, которое обеспечивает эффективное распределение задач и минимизирует накладные расходы на коммуникацию между узлами. Синхронизация и координация работы этих узлов, осуществляемые посредством грамотно разработанного программного обеспечения, критически важны для достижения максимальной производительности и масштабируемости при моделировании сложных квантовых систем. Совместная разработка аппаратной и программной частей позволяет полностью раскрыть потенциал параллелизма по группам состояний, открывая новые возможности для решения задач, ранее недоступных из-за вычислительных ограничений.
Исследование демонстрирует, что стремление к абсолютной производительности часто приводит к созданию хрупких систем. Авторы, работая над симулятором квантовых состояний, столкнулись с необходимостью баланса между скоростью и адаптивностью. Это напоминает слова Кena Thompson: «Всё, что оптимизировано, однажды потеряет гибкость». Использование векторной архитектуры ARM SVE позволяет добиться значительного ускорения, однако, как показывает практика, истинная ценность заключается не в мгновенном выигрыше, а в возможности адаптироваться к меняющимся требованиям и различным платформам. В конечном итоге, архитектура, лишенная гибкости, подобна замкнутому циклу — она может быть быстрой сейчас, но не способна к эволюции.
Что дальше?
Представленная работа демонстрирует не триумф оптимизации, а скорее осознание её преходящего характера. Создание высокопроизводительного симулятора квантовых состояний, адаптируемого к различным архитектурам ARM, — это не постройка крепости, а взращивание сада. Каждый выбор, касающийся векторизации и использования SVE, — это пророчество о будущей точке отказа, о новом поколении процессоров, требующем новых компромиссов. Важно понимать, что производительность — это не абсолютная величина, а относительная, зависящая от экосистемы, в которой функционирует симулятор.
Очевидным направлением дальнейших исследований представляется отказ от представления квантового состояния как единого вектора. Вместо этого, стоит обратить внимание на подходы, позволяющие декомпозировать состояние на более мелкие, независимо обрабатываемые фрагменты. Устойчивость системы не в изоляции компонентов, а в их способности прощать ошибки друг друга, в возможности динамически перераспределять нагрузку и адаптироваться к изменяющимся условиям.
В конечном счете, ключевым вопросом остаётся не скорость симуляции, а её способность к масштабированию и адаптации. Симулятор — это не машина для вычислений, а инструмент для исследования, и его ценность определяется не тем, как быстро он решает известные задачи, а тем, какие новые вопросы он позволяет задать.
Оригинал статьи: https://arxiv.org/pdf/2602.09604.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Робот-исследователь: новый подход к автономной навигации
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Искусственный интеллект: хрупкость визуального мышления
2026-02-11 12:40