Автор: Денис Аветисян
Новое исследование показывает, что структурированные стратегии рассуждений позволяют языковым моделям создавать более компактные и эффективные представления данных.
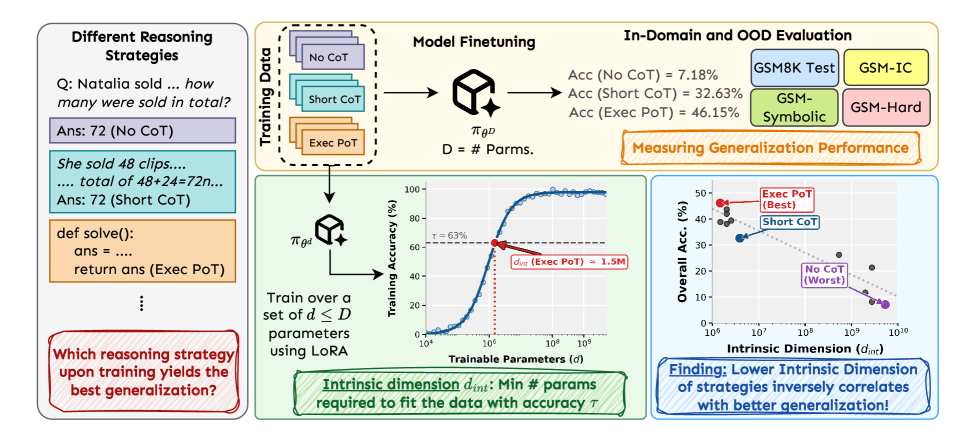
Эффективные цепочки рассуждений снижают внутреннюю размерность языковых моделей, улучшая обобщающую способность и позволяя применять методы сжатия, такие как LoRA.
Несмотря на значительные успехи в обучении больших языковых моделей, механизмы, лежащие в основе их способности к обобщению при решении сложных задач, остаются недостаточно понятными. В своей работе ‘Effective Reasoning Chains Reduce Intrinsic Dimensionality’ мы исследуем, как различные стратегии рассуждений влияют на эффективность языковых моделей. Мы показали, что эффективные цепочки рассуждений последовательно снижают внутреннюю размерность задачи, что указывает на создание более сжимаемых представлений. Может ли внутренняя размерность служить новым количественным показателем для анализа и оптимизации процессов рассуждений в больших языковых моделях?
Глубина Рассуждений: Преодоление Сложности
Несмотря на впечатляющий прогресс в области больших языковых моделей, сложная логика и рассуждения остаются серьезной проблемой. Простое увеличение размера модели и объема данных для обучения, хотя и приводит к улучшению результатов в некоторых задачах, не обеспечивает качественного скачка в решении задач, требующих глубокого анализа и вывода. Исследования показывают, что способность к сложному рассуждению не масштабируется линейно с размером модели; необходимы принципиально новые подходы, учитывающие не только объем информации, но и ее структуру, а также способность модели эффективно обрабатывать и комбинировать различные концепции. Увеличение вычислительных ресурсов само по себе не гарантирует решение этой проблемы, и для достижения значимого прогресса требуются инновационные архитектуры и методы обучения.
Традиционные подходы к решению задач, требующих рассуждений, часто сталкиваются с проблемой «внутренней размерности». Данное понятие описывает сложность задачи, обусловленную не столько ее линейной протяженностью, сколько количеством взаимосвязанных факторов и возможных путей решения. Представьте, что для поиска выхода из лабиринта необходимо учитывать не только количество поворотов, но и множество ложных следов, тупиков и скрытых переходов — это и есть проявление высокой внутренней размерности. Вследствие этого, стандартные алгоритмы, эффективно работающие с простыми задачами, оказываются неэффективными и ресурсоемкими при столкновении с задачами, обладающими значительной внутренней размерностью, что приводит к снижению производительности и замедлению процесса рассуждений. По сути, алгоритм «теряется» в пространстве возможных решений, не находя оптимальный путь к цели.
Исследования показали, что традиционная оценка сложности рассуждений, основанная на длине цепочки логических шагов — так называемой ‘Длине Траектории’ — имеет крайне слабую связь с фактической производительностью модели, демонстрируя корреляцию всего лишь в 0.31. В отличие от этого, понятие ‘внутренней размерности’ задачи, отражающее количество действительно значимых параметров, определяющих сложность рассуждений, оказалось мощным предиктором обобщающей способности моделей. Корреляция между внутренней размерностью и производительностью достигает впечатляющих 0.93, что указывает на то, что именно эта характеристика, а не просто длина цепочки рассуждений, является ключевым фактором, определяющим способность модели к эффективному решению сложных задач и переносу знаний на новые ситуации. Таким образом, фокусировка на снижении внутренней размерности задач представляется перспективным направлением для дальнейшего развития искусственного интеллекта.
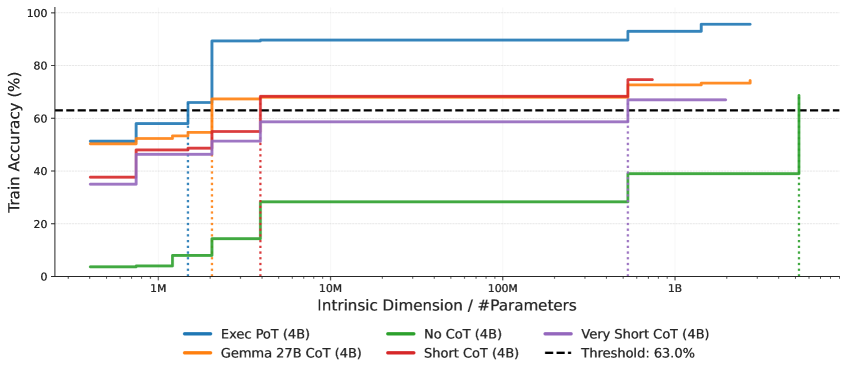
Эффективные Стратегии и Уменьшение Размерности
Наши исследования показали, что эффективные стратегии рассуждений активно снижают внутреннюю размерность задачи, что способствует улучшению обобщающей способности модели. Снижение размерности указывает на то, что модель способна представить сложную проблему в более компактной и управляемой форме, выделяя ключевые факторы и игнорируя несущественные детали. Это, в свою очередь, позволяет модели более эффективно применять накопленные знания и находить решения для новых, ранее не встречавшихся задач. Более низкая внутренняя размерность коррелирует с улучшенной способностью модели к экстраполяции и адаптации к различным условиям, что подтверждается результатами анализа, полученными на наборе данных GSM8K для решения математических задач.
Анализ с использованием метрики ‘Executed PoT’ (Executed Plan of Thought) подтверждает снижение размерности задачи в процессе эффективного рассуждения. Эксперименты, проведенные на наборе данных GSM8K, содержащем математические задачи, показали, что стратегии, приводящие к успешному решению, демонстрируют более значительное уменьшение размерности пространства поиска решений. Данные, полученные при анализе ‘Executed PoT’ на GSM8K, позволяют количественно оценить эффект снижения размерности, связанный с применением эффективных стратегий решения задач.
Анализ производительности модели Gemma-3 4B показал корреляцию на уровне 0.82 между токеновой перплексией и результатами решения задач, однако внутренняя размерность (intrinsic dimensionality) демонстрирует более тесную связь с эффективностью рассуждений. В ходе исследований было установлено, что расхождение Кульбака-Лейблера (KL Divergence) является менее надежным показателем, чем внутренняя размерность, при оценке качества рассуждений. Данный факт указывает на необходимость разработки новых критериев оценки, способных более точно отражать способность модели к эффективному решению сложных задач и обобщению полученных знаний.
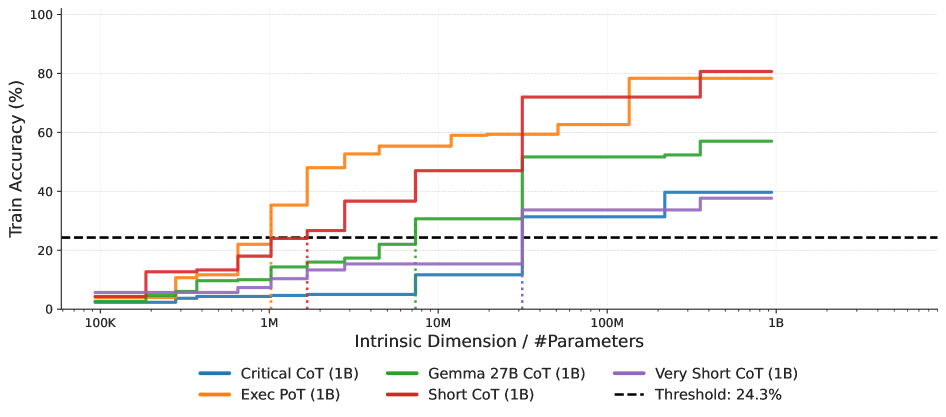
Масштаб, Данные и Сжатие Рассуждений
Исследования показали, что более крупные модели, такие как ‘Gemma-3 27B’, демонстрируют повышенную эффективность в сжатии и воспроизведении эффективных стратегий рассуждений. Это указывает на то, что увеличение емкости модели положительно влияет на способность к обобщению и применению логических цепочек. Более высокая емкость позволяет модели захватывать и кодировать сложные паттерны рассуждений с меньшими потерями информации, что приводит к улучшению производительности в задачах, требующих логического вывода и анализа.
Исследования показали, что качество примеров рассуждений в обучающих данных оказывает большее влияние на способность модели к обучению, чем просто увеличение объема этих данных. Это означает, что тщательно отобранные и хорошо сформулированные примеры, демонстрирующие логическое мышление и решение задач, более эффективны для обучения модели, чем большое количество примеров низкого качества или нерелевантных задаче. Увеличение объема данных без улучшения их качества приводит к меньшей отдаче в плане производительности модели, чем фокусировка на создании высококачественного набора обучающих данных, содержащего четкие и правильные примеры рассуждений.
В ходе анализа модели Gemma-3 1B была выявлена корреляция 0.75 между внутренней размерностью модели и её производительностью. Данный факт подчеркивает важность минимизации размерности для обеспечения эффективного логического вывода. Результаты подтверждают принцип минимальной длины описания (Minimum Description Length Principle), согласно которому наиболее эффективными являются модели, способные представлять логические рассуждения с минимальным количеством параметров. Снижение внутренней размерности позволяет модели более эффективно использовать доступные параметры для кодирования и обработки информации, необходимой для решения задач логического вывода.
Эффективная Реализация и Перспективы Развития
Методы параметрически-эффективной тонкой настройки, такие как LoRA (Low-Rank Adaptation), оказались высокоэффективными при реализации стратегий снижения размерности в процессах рассуждений. Вместо полной перенастройки всех параметров модели, LoRA позволяет адаптировать лишь небольшое количество дополнительных параметров, что значительно снижает вычислительные затраты и требования к памяти. Этот подход особенно важен при работе с большими языковыми моделями, где полная перенастройка может быть непозволительной. Применение LoRA позволяет эффективно внедрять и оптимизировать стратегии, направленные на упрощение сложных задач рассуждений без существенной потери в производительности, делая их более доступными для практического применения и развертывания на различных платформах.
Способность модели эффективно применять полученные знания в ситуациях, значительно отличающихся от тех, на которых она обучалась — так называемая обобщающая способность вне распределения (Out-of-Distribution Generalization) — напрямую зависит от эффективности выработанных ею стратегий рассуждений. Более лаконичные и структурированные методы анализа информации позволяют модели избегать переобучения и лучше адаптироваться к новым, неизвестным данным. Вместо запоминания конкретных решений, эффективные стратегии рассуждений формируют общие принципы, которые могут быть применены к широкому спектру задач, что и обеспечивает высокую устойчивость и гибкость системы искусственного интеллекта в условиях неопределенности и изменений окружающей среды. Таким образом, оптимизация процессов рассуждений является ключевым фактором для создания интеллектуальных систем, способных к надежной и адаптивной работе в реальном мире.
В будущем исследования будут направлены на разработку методов автоматического обнаружения и сжатия эффективных стратегий рассуждений. Эта работа предполагает создание алгоритмов, способных самостоятельно выявлять наиболее полезные подходы к решению задач и оптимизировать их для снижения вычислительных затрат. Успешная реализация таких методов позволит создавать более надежные и адаптивные системы искусственного интеллекта, способные эффективно функционировать в различных, непредсказуемых условиях и быстро приспосабливаться к новым задачам, не требуя постоянного вмешательства человека или дорогостоящей переподготовки. Ожидается, что подобные разработки станут ключевым шагом к созданию действительно интеллектуальных систем, способных к самообучению и самостоятельному совершенствованию.
Исследование демонстрирует, что эффективные цепочки рассуждений снижают внутреннюю размерность языковых моделей, упрощая их представление и повышая обобщающую способность. Этот процесс напоминает стремление к элегантности в математике, где сложность уступает место ясности. Как однажды заметил Дональд Кнут: «Преждевременная оптимизация — корень всех зол». В контексте данной работы, это означает, что фокусировка на разработке эффективных стратегий рассуждений — таких как цепочки мыслей — позволяет создать более компактные и понятные модели, избегая ненужной сложности и улучшая их производительность. Уменьшение внутренней размерности — это не просто технический прогресс, а и шаг к более изящным и эффективным алгоритмам.
Куда же дальше?
Работа показывает, что эффективные стратегии рассуждений, подобные построению цепочки мыслей, уменьшают внутреннюю размерность языковых моделей. Это не просто технический трюк; это намек на то, что сложные системы могут быть более компактными, чем кажется на первый взгляд. Однако, следует помнить: уменьшение размерности — не самоцель, а средство повышения обобщающей способности. Попытки сжать модель до предела, игнорируя качество рассуждений, обречены на провал. Истина, как всегда, лежит посередине — в элегантной простоте.
Остается открытым вопрос: насколько универсален этот эффект? Действует ли он только для задач, требующих сложных логических построений, или же применим к более широкому спектру задач обработки языка? Кроме того, необходимо исследовать взаимодействие между различными стратегиями рассуждений и методами сжатия моделей. Возможно, существует оптимальная комбинация, позволяющая достичь максимальной эффективности. И, конечно, не стоит забывать о “черном ящике”: понимание как цепочка мыслей уменьшает размерность, остается сложной задачей.
В конечном итоге, поиск оптимального баланса между сложностью, компактностью и обобщающей способностью — это вечная задача. Не стоит гнаться за абстрактным “искусственным интеллектом”. Важнее создать системы, которые решают конкретные задачи эффективно и понятно. Простота — это не признак слабости, а признак мастерства. И это, пожалуй, самое ценное, что можно извлечь из данной работы.
Оригинал статьи: https://arxiv.org/pdf/2602.09276.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Робот-исследователь: новый подход к автономной навигации
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Искусственный интеллект: хрупкость визуального мышления
2026-02-11 19:10