Автор: Денис Аветисян
Исследователи представляют Fine-T2I — обширный и разнообразный набор данных, призванный значительно улучшить качество и реалистичность изображений, создаваемых нейросетями по текстовому описанию.
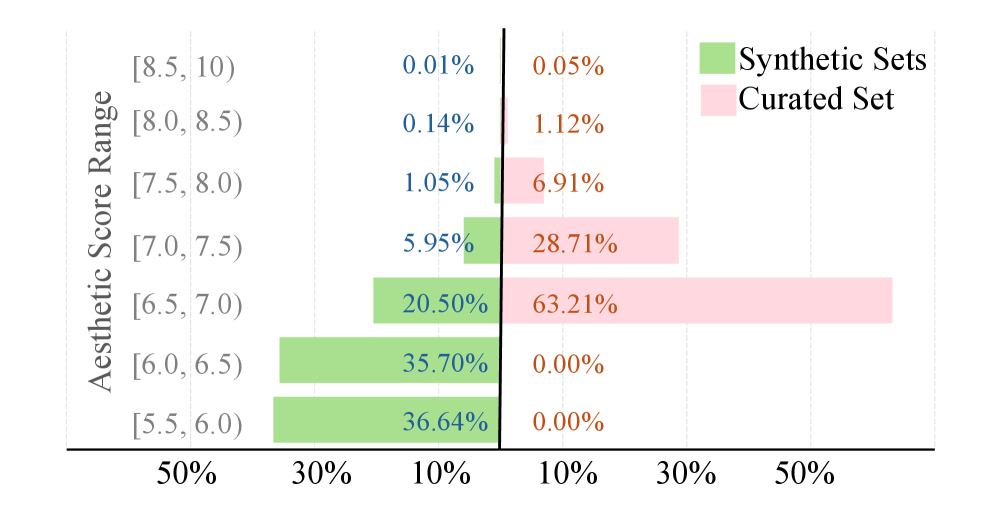
Fine-T2I — это открытый, крупномасштабный датасет для точной настройки моделей генерации изображений, демонстрирующий стабильное повышение качества на различных архитектурах.
Несмотря на значительный прогресс в архитектурах и методах обучения моделей преобразования текста в изображение, доступность высококачественных и открытых наборов данных для их тонкой настройки остается серьезным препятствием. В данной работе представлена работа ‘Fine-T2I: An Open, Large-Scale, and Diverse Dataset for High-Quality T2I Fine-Tuning’, в которой описывается Fine-T2I — масштабный, высококачественный и полностью открытый набор данных, объединяющий синтетические и тщательно отобранные реальные изображения. Эксперименты демонстрируют, что тонкая настройка на Fine-T2I последовательно улучшает качество генерации и соответствие инструкциям различных диффузионных и авторегрессионных моделей. Может ли Fine-T2I стать основой для создания более доступных и мощных моделей преобразования текста в изображение в открытом сообществе?
Масштабируемость в генерации изображений по тексту: вызовы и ограничения
Современные модели генерации изображений по текстовому описанию, несмотря на впечатляющие результаты, зачастую испытывают трудности при масштабировании. Проблема заключается в поддержании семантической согласованности и создании детализированных, высококачественных изображений при увеличении сложности и объема входных данных. Несмотря на способность генерировать реалистичные изображения для простых запросов, модели демонстрируют снижение качества и появление артефактов при попытке воссоздать сцены со множеством объектов, сложных взаимосвязей или тонких деталей. Это ограничивает их применение в задачах, требующих высокой точности и реалистичности, таких как создание визуализаций для научных исследований, разработка игрового контента или генерация изображений для профессиональных целей.
Зависимость современных моделей генерации изображений по текстовому описанию от огромных массивов данных несет в себе ряд существенных рисков. Помимо вероятности воспроизведения и усиления существующих предвзятостей, содержащихся в обучающих выборках, возникает проблема ограниченной доступности. Требование к значительным вычислительным ресурсам для обработки и использования этих данных существенно ограничивает возможности исследователей, не располагающих соответствующей инфраструктурой. Это создает барьер для инноваций и замедляет прогресс в области, препятствуя широкому распространению и адаптации передовых технологий генерации изображений.
В области генерации изображений по текстовому описанию остро ощущается потребность в масштабных, высококачественных и общедоступных наборах данных. Существующие массивы информации часто страдают от предвзятости или ограничений доступа, что замедляет развитие исследований. Для решения этой проблемы представлен Fine-T2I — новый набор данных, включающий 6 миллионов примеров, разработанный с учетом баланса между объемом, качеством и открытостью. Этот ресурс призван democratize доступ к необходимым данным, стимулируя инновации и позволяя исследователям разрабатывать более эффективные и надежные модели генерации изображений.
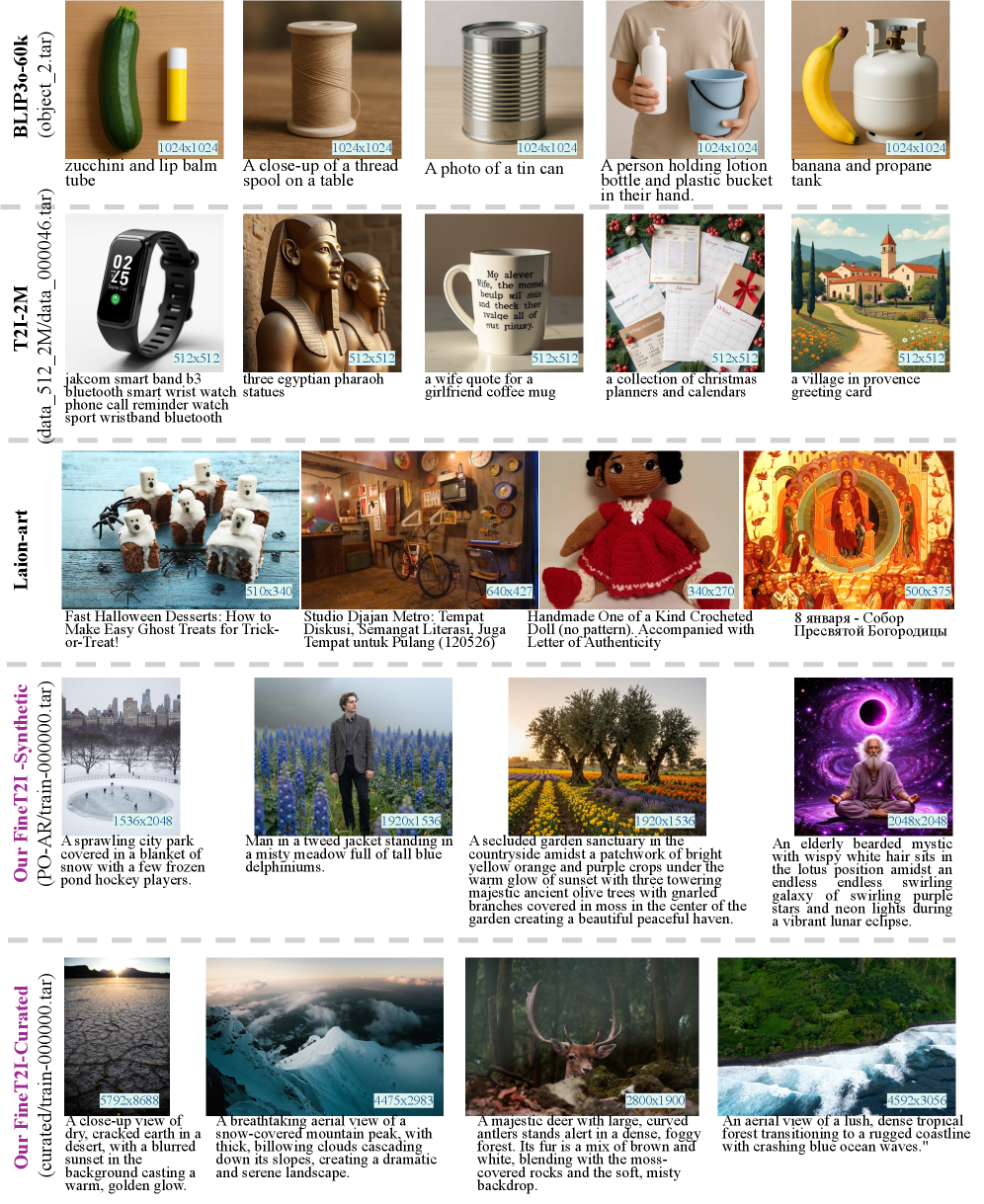
Fine-T2I: Масштабный набор данных для надежной генерации
Набор данных Fine-T2I представляет собой масштабный ресурс для обучения и оценки моделей преобразования текста в изображение, объединяющий синтетически сгенерированные данные с тщательно отобранными реальными изображениями. Использование комбинированного подхода позволяет обеспечить как разнообразие и объем обучающей выборки, необходимые для обобщения моделей, так и соответствие сгенерированных изображений реальным визуальным характеристикам. Объем набора данных предназначен для поддержки обучения сложных моделей и проведения надежных оценок их производительности в различных сценариях генерации изображений по текстовым запросам.
Для генерации разнообразных и качественных текстовых запросов, используемых для создания синтетических данных в наборе Fine-T2I, была применена языковая модель LLaMA3. Использование LLaMA3 позволило значительно расширить спектр представленных концепций и сценариев, обеспечивая более широкое покрытие возможных вариантов в генерируемых изображениях. Это, в свою очередь, способствует повышению обобщающей способности моделей, обучаемых на данном наборе данных, и улучшает их способность генерировать реалистичные изображения по различным текстовым описаниям.
Для обеспечения высокого качества набора данных Fine-T2I применялась многоступенчатая фильтрация. Изначально собранные данные подверглись оценке эстетических характеристик с использованием модели Aesthetic Predictor V2.5, а также проверке соответствия изображения текстовому описанию с помощью Qwen-VL. Данный процесс позволил отсеять 95% исходных данных, обеспечив высокую степень согласованности между текстом и изображением и общее качество набора данных для обучения и оценки моделей преобразования текста в изображение.

Оценка эффективности: SD-XL и LoRA как инструменты валидации
Для оценки эффективности набора данных Fine-T2I была проведена дообучение диффузионной модели SD-XL с использованием LoRA-адаптеров, представляющих собой параметрически-эффективный метод. LoRA позволяет снизить вычислительные затраты по сравнению с полной дообучением, замораживая веса предобученной модели и обучая лишь небольшое количество дополнительных параметров. Это достигается путем добавления низкоранговых матриц к весовым матрицам слоев внимания, что значительно уменьшает количество обучаемых параметров без существенной потери качества генерируемых изображений. Использование LoRA позволяет добиться сопоставимых результатов с полной дообучением при значительно меньших требованиях к вычислительным ресурсам и времени обучения.
Использование LoRA-адаптеров для тонкой настройки модели SD-XL позволяет добиться значительного снижения вычислительных затрат по сравнению с полной перенастройкой модели. LoRA (Low-Rank Adaptation) замораживает предварительно обученные веса диффузионной модели и обучает лишь небольшое количество дополнительных параметров, что существенно уменьшает требования к памяти и времени обучения. Этот подход позволяет эффективно адаптировать модель к новому набору данных, сохраняя при этом большую часть знаний, полученных в процессе предварительного обучения, и минимизируя необходимость в дорогостоящих ресурсах для обучения.
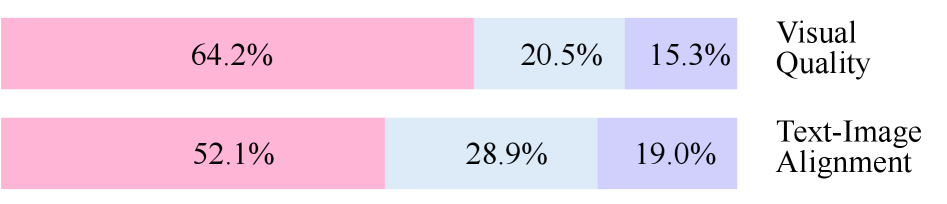
В ходе экспериментов с моделями SD-XL и LlamaGen, оценка качества генерируемых изображений проводилась с использованием Human Evaluation и Image Quality Assessment. Результаты показали существенное улучшение визуальной достоверности и соответствия изображения текстовому описанию. В частности, при оценке визуального качества с использованием LlamaGen, предпочтение было отдано генерируемым изображениям в 80.7% случаев, согласно данным Human Evaluation. Для SD-XL, оценка соответствия изображения текстовому описанию показала положительный результат в 65.3% случаев, также основываясь на данных Human Evaluation.
Открытая наука и перспективы развития генерации изображений
Публикация набора данных Fine-T2I в открытом доступе призвана обеспечить равные возможности для исследователей в области генерации изображений по текстовому описанию. Это позволяет преодолеть барьеры, связанные с дороговизной и ограниченностью ресурсов, традиционно затрудняющие проведение передовых исследований. Предоставляя высококачественный набор данных в свободное пользование, создатели надеются стимулировать более широкое участие в развитии технологий преобразования текста в изображения, что, в свою очередь, способствует появлению новых творческих подходов и научных открытий в данной перспективной области. Такой подход способствует децентрализации инноваций и позволяет исследователям из различных учреждений и стран внести свой вклад в общее дело.
Опубликованный набор данных Fine-T2I призван стимулировать совместную работу и ускорить инновации в различных областях. Открытие доступа к высококачественным ресурсам для преобразования текста в изображения открывает новые возможности для создателей контента, позволяя им разрабатывать визуально привлекательные материалы с беспрецедентной легкостью. Художники получают мощный инструмент для воплощения своих идей и экспериментов с новыми формами выражения. Кроме того, потенциал использования технологии простирается на научную визуализацию, где сложные данные могут быть представлены в наглядных и интуитивно понятных изображениях, способствуя более глубокому пониманию и новым открытиям в различных дисциплинах. Подобный открытый доступ к ресурсам является катализатором для прогресса, позволяя исследователям и практикам совместно решать сложные задачи и расширять границы возможного.
В дальнейшем планируется существенное расширение набора данных Fine-T2I за счет включения более разнообразных текстовых запросов и визуальных представлений, что позволит охватить более широкий спектр концепций и стилей. Особое внимание будет уделено совершенствованию методов фильтрации данных, направленных на повышение их качества и устранение потенциальных смещений, обеспечивая тем самым более надежные и объективные результаты генерации изображений. Помимо этого, исследователи намерены изучить новые области применения технологии преобразования текста в изображения, включая создание персонализированного образовательного контента, разработку инструментов для визуализации научных данных и поддержку творческих процессов в искусстве и дизайне. Такой подход призван не только расширить возможности текущих моделей, но и открыть новые горизонты для инноваций в сфере искусственного интеллекта.

Исследование представляет собой стремление к математической чистоте в области генерации изображений по текстовому описанию. Авторы, создавая Fine-T2I, акцентируют внимание на необходимости тщательно отобранных данных для тонкой настройки моделей, что напрямую соответствует идее о минимизации избыточности и потенциальных ошибок. Как однажды заметил Ян Лекун: «Машинное обучение — это математика, и всё остальное — просто инженерное дело». Этот принцип находит отражение в представленном датасете, где каждый пример призван повысить точность и эффективность алгоритмов, приближая их к идеальному решению. Создание масштабного и открытого набора данных для тонкой настройки — это шаг к более доказуемым и надёжным системам генерации изображений.
Куда Далее?
Представленный набор данных, Fine-T2I, безусловно, представляет собой шаг вперёд в решении проблемы ограниченности качественных данных для тонкой настройки генеративных моделей «текст-изображение». Однако, элегантность решения не измеряется объёмом набора данных, а скорее его внутренней согласованностью и устойчивостью к непредсказуемым входным данным. Остаётся открытым вопрос: насколько хорошо этот набор данных справляется с «длинным хвостом» запросов — с редкими, необычными, и по-настоящему сложными описаниями? Простое увеличение масштаба не гарантирует принципиального улучшения качества, если не будет решена проблема внутренней репрезентативности.
Следующим логичным шагом представляется не только создание ещё больших наборов данных, но и разработка формальных методов оценки их «глубины» и «ширины». Необходимо выйти за рамки субъективных оценок и разработать метрики, способные количественно оценить способность модели обобщать знания на основе ограниченного набора данных. Иначе, мы рискуем создать лишь иллюзию прогресса, заменяя реальное понимание принципов генерации изображений на простое накопление статистики.
В конечном счёте, истинная ценность Fine-T2I и подобных инициатив будет определена не количеством скачиваний, а способностью вдохновить на разработку алгоритмов, которые смогут доказуемо создавать изображения, соответствующие заданным критериям — не просто «красивые картинки», а осмысленные визуальные репрезентации заданных концепций. И это, как известно, задача, требующая не только больших данных, но и глубокого математического понимания.
Оригинал статьи: https://arxiv.org/pdf/2602.09439.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Робот-исследователь: новый подход к автономной навигации
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Искусственный интеллект: хрупкость визуального мышления
2026-02-11 22:33