Автор: Денис Аветисян
В статье представлен всесторонний обзор стратегий распределенного обучения и инференса масштабных языковых моделей.
Сравнительный анализ и руководство по проектированию систем для оптимизации производительности, масштабируемости и энергоэффективности.
Быстрый рост масштабов больших языковых моделей (LLM) ставит перед исследователями задачу эффективного распределения вычислительных ресурсов и памяти. В работе ‘Distributed Hybrid Parallelism for Large Language Models: Comparative Study and System Design Guide’ представлен всесторонний анализ стратегий распределенного и гибридного параллелизма, включая математическое описание коллективных операций и коммуникационных издержек. Авторы демонстрируют, что оптимальный выбор стратегии зависит от архитектуры оборудования и стадии развертывания модели — обучения или инференса — и предлагают руководство по их проектированию. Какие новые подходы к автоматическому поиску оптимальных стратегий параллелизации позволят преодолеть ограничения текущих парадигм обучения LLM и обеспечить их устойчивое развитие?
Масштабируемость Больших Языковых Моделей: Вызов Эпохи
Современные большие языковые модели (БЯМ) демонстрируют впечатляющие возможности в обработке и генерации текста, однако их масштабные размеры предъявляют колоссальные требования к вычислительным ресурсам. По мере увеличения количества параметров, необходимых для достижения высокой точности и понимания языка, потребность в памяти и вычислительной мощности растёт экспоненциально. Это создает серьезные трудности для обучения и развертывания таких моделей, поскольку требует дорогостоящего оборудования и значительных энергозатрат. В результате, доступ к передовым БЯМ ограничен, а их эффективное использование становится сложной задачей для исследователей и разработчиков. Поэтому поиск решений для оптимизации размера и вычислительной сложности больших языковых моделей является ключевым направлением современных исследований в области искусственного интеллекта.
Увеличение размеров языковых моделей, соответствующее предсказаниям законов масштабирования, существенно усугубляет проблемы, связанные с объемом занимаемой памяти и необходимостью передачи данных. Законы масштабирования показывают, что для достижения более высокой производительности требуется экспоненциальный рост как количества параметров модели, так и объема обучающих данных. Это приводит к значительному увеличению MemoryFootprint — объема памяти, необходимого для хранения модели и промежуточных вычислений. Одновременно возрастает и CommunicationOverhead — затраты на обмен данными между вычислительными устройствами, особенно при распределенных вычислениях. Поскольку скорость передачи данных часто является узким местом, увеличение объема передаваемых данных напрямую влияет на скорость обучения и работы модели, создавая серьезные препятствия для дальнейшего масштабирования и эффективного использования больших языковых моделей.
Традиционные методы распределения вычислительной нагрузки испытывают значительные трудности при работе с большими языковыми моделями. Существующие подходы, разработанные для менее масштабных задач, оказываются неэффективными при попытке разделить обработку данных между множеством устройств. Это связано с тем, что передача огромных объемов информации между процессорами и памятью создает узкие места, значительно замедляя процесс обучения и вывода. В результате, масштабирование моделей до требуемых размеров становится проблематичным, ограничивая их потенциал и практическое применение. Исследователи активно ищут новые способы оптимизации распределенных вычислений, включая методы параллелизации и сжатия данных, чтобы преодолеть эти ограничения и обеспечить эффективное масштабирование больших языковых моделей.
Стратегии Параллелизации для Эффективного Обучения БЯМ
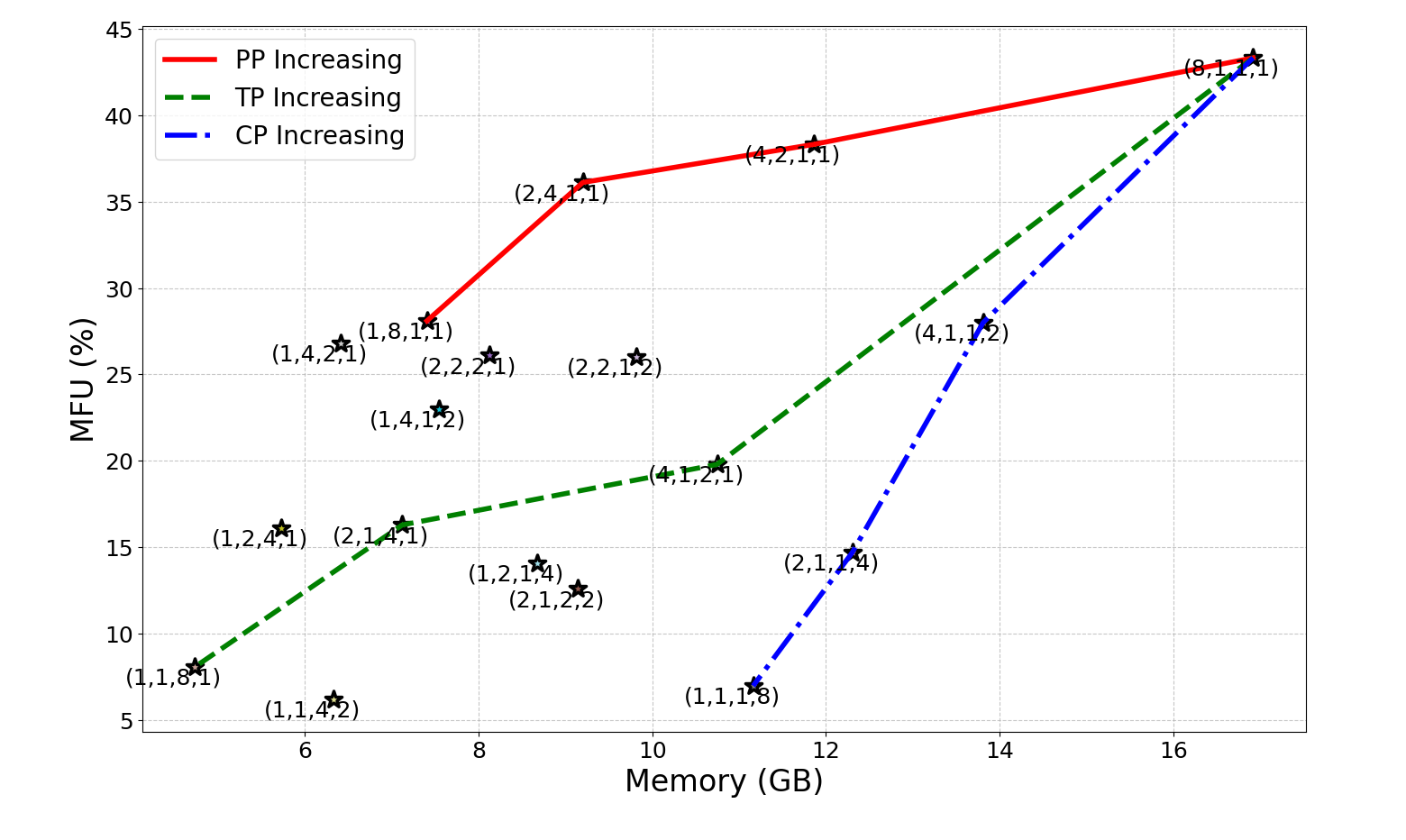
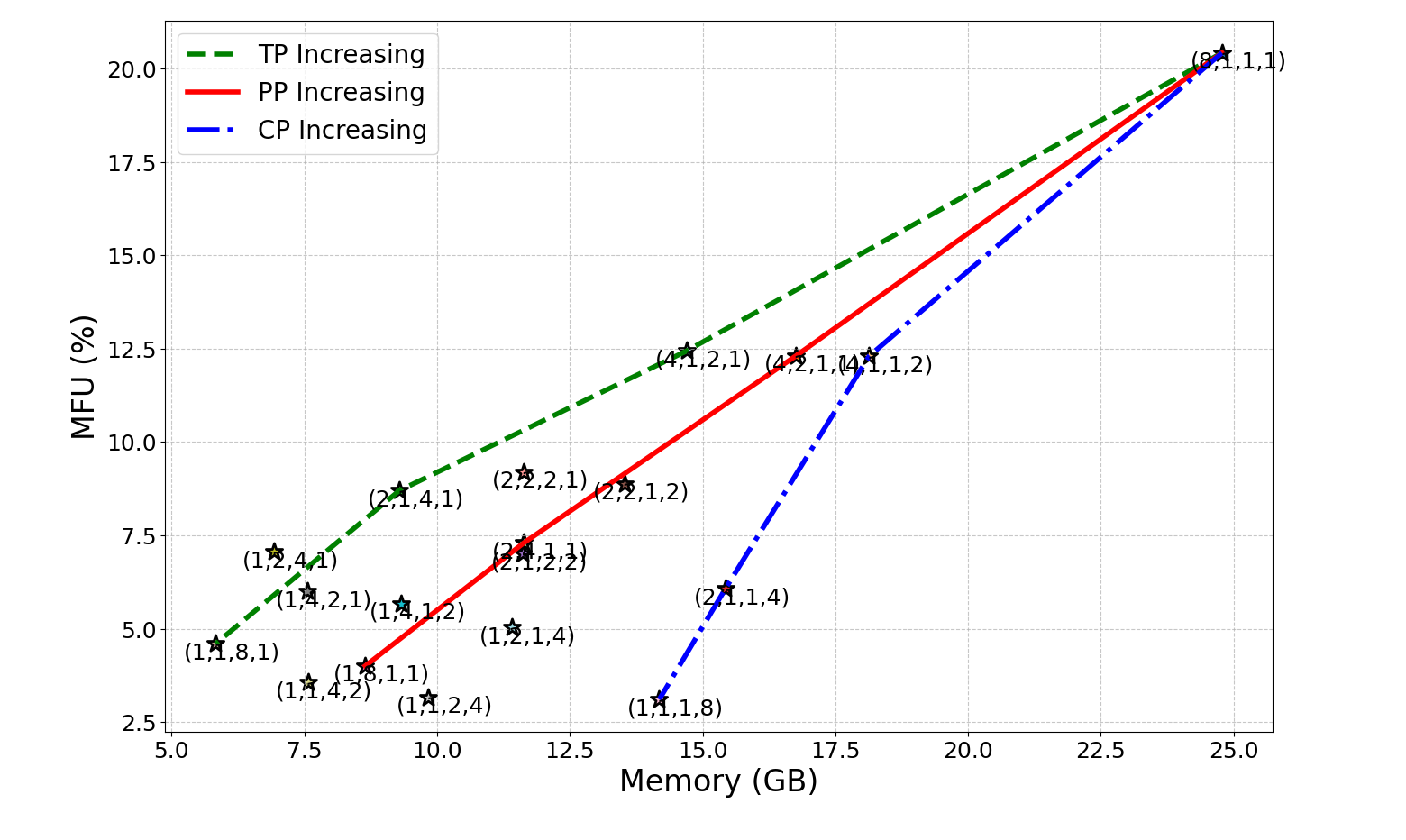
Параллелизация обучения больших языковых моделей (LLM) осуществляется посредством различных стратегий, каждая из которых имеет свои особенности. DataParallelism предполагает репликацию модели на нескольких устройствах, каждое из которых обрабатывает разные пакеты данных. PipelineParallelism разбивает модель на этапы и распределяет их по разным устройствам, позволяя одновременно обрабатывать разные части одного пакета данных. TensorParallelism разделяет отдельные тензоры модели между устройствами, уменьшая объем памяти, необходимый на каждом устройстве. Наконец, ContextParallelism разделяет последовательности входного контекста между устройствами, позволяя обрабатывать более длинные последовательности. Каждая из этих стратегий направлена на распределение вычислительной нагрузки и снижение требований к памяти, что позволяет обучать LLM большего размера и с большей эффективностью.
Гибридный параллелизм объединяет стратегии DataParallelism, PipelineParallelism, TensorParallelism и ContextParallelism для оптимизации производительности обучения больших языковых моделей. Данный подход позволяет использовать преимущества каждой стратегии, эффективно распределяя нагрузку и минимизируя узкие места. В результате, наблюдается значительное увеличение пропускной способности, достигающее до 10-кратного прироста по сравнению с использованием одной из стратегий параллелизма. Оптимальная конфигурация гибридного параллелизма зависит от конкретной архитектуры модели, размера данных и доступных вычислительных ресурсов.
Эффективная реализация гибридного параллелизма в обучении больших языковых моделей (LLM) критически зависит от оптимизации коллективных коммуникаций. Синхронизация между процессами, распределенными по различным устройствам, является узким местом, и минимизация времени, затрачиваемого на обмен градиентами и параметрами, напрямую влияет на общую производительность. Для этого используются алгоритмы коллективной коммуникации, такие как All-Reduce, All-Gather и Scatter/Gather, которые оптимизированы для конкретной аппаратной архитектуры и сетевой топологии. Высокопроизводительные реализации этих алгоритмов, например, использующие RDMA или NVLink, позволяют существенно снизить накладные расходы на синхронизацию и добиться максимального ускорения обучения при использовании гибридного подхода.
Применение стратегий параллелизации позволяет обучать большие языковые модели (LLM) на значительно более крупных наборах данных, что напрямую влияет на повышение эффективности использования оборудования, измеряемой как MFU (Million Frames per Second). Например, модель Mamba-1B, использующая метод параллелизма данных (Data Parallelism), достигла показателя MFU в 20.4%. Это демонстрирует, что оптимизация распределенных вычислений является ключевым фактором для масштабирования обучения LLM и повышения их производительности при работе с объемными данными.
Автопараллелизм: Автоматизация Оптимизации
Автопараллелизм автоматически определяет оптимальную стратегию распараллеливания для заданной большой языковой модели (LLM) и аппаратной конфигурации. Этот процесс включает в себя динамический анализ характеристик модели, таких как размер, сложность и требуемые вычислительные ресурсы, а также оценку доступных ресурсов оборудования, включая количество GPU, объем памяти и пропускную способность сети. Система автоматически выбирает комбинацию методов распараллеливания — DataParallelism, PipelineParallelism, ContextParallelism и TensorParallelism — для достижения максимальной производительности и эффективности использования ресурсов, исключая необходимость ручной настройки и оптимизации.
Автоматический подбор стратегий параллелизации использует CostModel — модуль, предназначенный для оценки производительности различных конфигураций. CostModel анализирует характеристики модели, такие как размер и структуру, а также спецификации аппаратного обеспечения, включая количество GPU, объем памяти и пропускную способность. На основе этого анализа, модуль прогнозирует время обучения и потребление ресурсов для каждой конфигурации, позволяя выбрать оптимальную стратегию параллелизации без необходимости ручного тестирования и настройки. Это существенно упрощает процесс оптимизации и ускоряет обучение больших языковых моделей.
Автопараллелизм основывается на концепции гибридного параллелизма, интеллектуально комбинируя различные стратегии для достижения оптимальной производительности. В частности, он объединяет DataParallelism (распараллеливание данных), PipelineParallelism (конвейерное распараллеливание), ContextParallelism (распараллеливание контекста) и TensorParallelism (распараллеливание тензоров). Выбор и комбинация этих стратегий осуществляется автоматически, что позволяет адаптироваться к различным архитектурам LLM и аппаратным конфигурациям, максимизируя эффективность вычислений и снижая время обучения.
Автоматизация, предоставляемая AutoParallelism, значительно снижает нагрузку на разработчиков, устраняя необходимость ручного подбора оптимальной стратегии параллелизации для больших языковых моделей (LLM). Это позволяет ускорить процесс обучения, как демонстрирует пример с моделью Mamba-1B, которая достигла производительности в 20% MFU (Maximum Floating Operations per Second). Достижение данной эффективности подтверждает возможность автоматической оптимизации и адаптации к различным аппаратным конфигурациям без вмешательства человека, что существенно сокращает время, необходимое для развертывания и обучения LLM.
К Устойчивому ИИ: Альтернативные Архитектуры
Появляющиеся архитектуры, такие как Mamba, представляют собой перспективную альтернативу традиционным Трансформерам, особенно в отношении вычислительной эффективности. В отличие от механизмов внимания в Трансформерах, требующих квадратичного роста вычислительных затрат с увеличением длины последовательности, Mamba использует селективное состояние, что позволяет обрабатывать длинные последовательности данных с линейной сложностью. Это достигается благодаря использованию аппаратной оптимизации и эффективной работе с памятью, что значительно снижает потребление энергии и время обработки. В результате, Mamba демонстрирует превосходство в задачах, требующих анализа длинных контекстов, таких как обработка текста и временных рядов, открывая возможности для создания более быстрых и экономичных моделей искусственного интеллекта.
Стремление к устойчивому развитию искусственного интеллекта обуславливает необходимость снижения его вычислительных затрат. Новые архитектуры, такие как Mamba, демонстрируют потенциал в этом направлении, существенно уменьшая объём необходимых вычислений по сравнению с традиционными Transformer-моделями. Данное снижение не только способствует экономии ресурсов, но и является ключевым элементом инициатив GreenAI, направленных на создание экологически ответственного искусственного интеллекта. Уменьшение энергопотребления и требований к оборудованию открывает возможности для более широкого доступа к мощным языковым моделям и снижает их негативное воздействие на окружающую среду, делая искусственный интеллект не только эффективным, но и устойчивым в долгосрочной перспективе.
Помимо разработки новых архитектур, таких как Mamba, значительное повышение энергоэффективности больших языковых моделей достигается за счет применения передовых методов параллелизации вычислений. Техники, подобные CommunicationOverlap, позволяют оптимизировать взаимодействие между вычислительными узлами, минимизируя время простоя и максимизируя использование ресурсов. Вместо последовательной передачи данных, CommunicationOverlap позволяет накладывать операции передачи данных на вычисления, что существенно снижает общие затраты энергии. Данный подход не только уменьшает финансовые издержки, связанные с обучением и эксплуатацией моделей, но и способствует более ответственному использованию вычислительных мощностей, делая искусственный интеллект более доступным и экологически устойчивым.
Снижение вычислительных затрат и энергопотребления, достигаемое благодаря новым архитектурам и методам параллелизации, имеет далеко идущие последствия. Это не только существенно сокращает финансовые издержки, связанные с обучением и эксплуатацией больших языковых моделей (LLM), но и открывает возможности для более широкого доступа к этим технологиям. Ранее требующие огромных ресурсов и, следовательно, доступные лишь крупным организациям, LLM становятся все более применимыми для небольших исследовательских групп, стартапов и даже индивидуальных разработчиков. Кроме того, повышение экологической ответственности за счет уменьшения углеродного следа способствует более устойчивому развитию искусственного интеллекта и смягчает негативное воздействие на окружающую среду, делая технологии более приемлемыми для общества в целом.
Будущее БЯМ: Эффективность и Устойчивость
Постоянное стремление к повышению эффективности больших языковых моделей (LLM) становится мощным двигателем инноваций как в сфере аппаратного обеспечения, так и в разработке программного обеспечения. Для достижения этой цели активно исследуются новые архитектуры чипов, оптимизированные для задач машинного обучения, а также совершенствуются алгоритмы, позволяющие сократить вычислительные затраты и энергопотребление. Разработка специализированных ускорителей, способных параллельно обрабатывать огромные объемы данных, и создание более эффективных методов квантования и прунинга моделей — лишь некоторые примеры направлений, в которых ведется работа. Одновременно с этим, совершенствуются программные инструменты и фреймворки, позволяющие оптимизировать код и использовать ресурсы более рационально, что в конечном итоге способствует созданию более мощных и доступных систем искусственного интеллекта.
Развитие больших языковых моделей (LLM) неразрывно связано с прогрессом в методах параллелизации вычислений, инновациях в архитектуре сетей и усовершенствовании механизмов внимания. Особое значение приобретают подходы, такие как GQA (Grouped-query attention), позволяющие значительно снизить вычислительную нагрузку и объем памяти, необходимых для обработки информации. Параллелизация позволяет распределять задачи между множеством процессоров, ускоряя обучение и инференс моделей. Новые архитектурные решения направлены на оптимизацию структуры нейронных сетей, делая их более эффективными и масштабируемыми. Усовершенствованные механизмы внимания, в свою очередь, позволяют моделям фокусироваться на наиболее релевантных частях входных данных, повышая точность и скорость обработки. Сочетание этих факторов открывает путь к созданию более мощных, быстрых и доступных LLM, способных решать сложные задачи в различных областях.
В настоящее время, разработка и внедрение больших языковых моделей (LLM) требует значительных вычислительных ресурсов и, как следствие, приводит к существенному потреблению энергии. Принципы GreenAI, направленные на минимизацию этого воздействия, становятся ключевыми для ответственного развития искусственного интеллекта. Эти принципы охватывают оптимизацию алгоритмов, снижение точности вычислений без существенной потери качества, использование энергоэффективного оборудования и выбор источников энергии с низким уровнем выбросов. Внедрение GreenAI не только способствует снижению углеродного следа LLM, но и открывает возможности для более широкого доступа к технологиям искусственного интеллекта, поскольку снижение вычислительных требований делает их более доступными для организаций и отдельных лиц с ограниченными ресурсами. Таким образом, осознанное применение принципов GreenAI является необходимым условием для создания устойчивых и социально ответственных систем искусственного интеллекта.
Сочетание инноваций в области аппаратного обеспечения, оптимизации алгоритмов и принципов GreenAI открывает путь к созданию принципиально новых поколений искусственного интеллекта. Развитие параллельных вычислений и архитектурных решений, таких как GQA, позволит значительно повысить производительность больших языковых моделей при одновременном снижении энергопотребления. Это, в свою очередь, не только сделает передовые технологии более доступными для широкого круга пользователей и организаций, но и обеспечит их экологическую устойчивость, уменьшая негативное воздействие на окружающую среду. В результате, ожидается появление более мощных, эффективных и ответственных ИИ-систем, способных решать сложные задачи в различных областях, от науки и медицины до образования и промышленности.
Исследование распределённого гибридного параллелизма для больших языковых моделей выявляет сложную картину оптимизации. Авторы подчеркивают необходимость баланса между вычислительной мощностью и накладными расходами на коммуникацию. Это напоминает о стремлении к ясности, где избыточность скрывает истинный смысл. Как однажды заметил Бертран Рассел: «Чем больше я узнаю, тем больше понимаю, как мало я знаю». Эта фраза отражает суть работы: даже в области передовых технологий, стремление к совершенству требует постоянного упрощения и отсеивания лишнего, чтобы выявить наиболее эффективные стратегии, особенно в контексте оптимизации памяти и достижения устойчивого развития в сфере искусственного интеллекта.
Что дальше?
Представленный анализ распределённых стратегий обучения больших языковых моделей выявляет не столько решения, сколько пределы текущего подхода. Стремление к увеличению масштаба, словно самоцель, неизбежно наталкивается на ограничения, связанные с коммуникационными издержками и потреблением ресурсов. Оптимизация памяти и ускорение вычислений — это лишь временное облегчение симптомов, а не устранение причины. Истинный прогресс требует переосмысления самой парадигмы обучения.
Очевидным направлением представляется отказ от универсальных моделей в пользу более специализированных, адаптированных к конкретным задачам. Возможно, будущее за архитектурами, способными к динамической перестройке и выборочному обучению, а не за бездумным увеличением числа параметров. Необходимо исследовать альтернативные подходы к представлению знаний, не требующие колоссальных объёмов данных и вычислительных мощностей.
Ирония заключается в том, что стремление к созданию «искусственного интеллекта» всё больше напоминает безумную гонку за увеличением энтропии. Поиск «зелёного» искусственного интеллекта — это не просто вопрос экологической ответственности, а признание того, что истинная эффективность заключается не в количестве, а в качестве, не в масштабе, а в точности. Иногда, самое сложное — это понять, что нужно убрать, а не добавить.
Оригинал статьи: https://arxiv.org/pdf/2602.09109.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Робот-исследователь: новый подход к автономной навигации
2026-02-12 03:52