Автор: Денис Аветисян
Исследователи предлагают инновационный метод, позволяющий большим языковым моделям извлекать уроки из собственных неудач и использовать этот опыт для улучшения своих способностей к рассуждению.
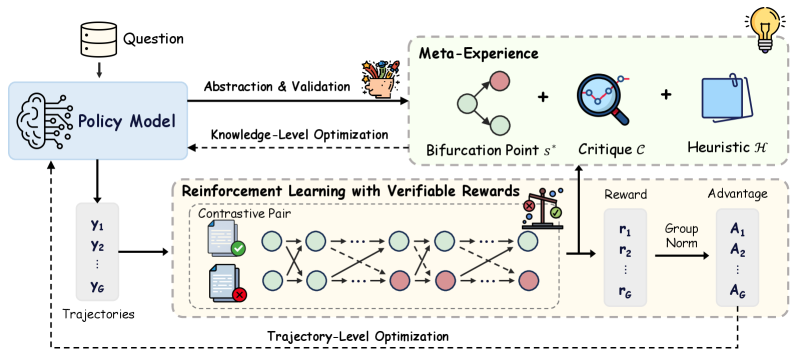
Предложенная схема Meta-Experience Learning (MEL) позволяет языковым моделям внутренне анализировать ошибки и использовать эту информацию для направленного обучения с подкреплением.
Несмотря на успехи обучения с подкреплением для больших языковых моделей (LLM), существующие подходы часто упускают из виду механизмы анализа ошибок и обобщения опыта, свойственные человеческому обучению. В данной работе, посвященной проблеме ‘Internalizing Meta-Experience into Memory for Guided Reinforcement Learning in Large Language Models’, предложен новый фреймворк Meta-Experience Learning (MEL), позволяющий аккумулировать и использовать обобщенные знания, полученные на основе анализа ошибок. MEL позволяет LLM не только практиковаться и верифицировать результаты, но и формировать устойчивые представления об ошибках, что способствует более эффективному повторному использованию знаний. Сможет ли такой подход к обучению с подкреплением значительно расширить возможности LLM в решении сложных задач рассуждения и принятия решений?
Предел масштабируемости: Рассуждения в больших языковых моделях
Несмотря на впечатляющие успехи в генерации текста и кажущуюся способность к пониманию языка, большие языковые модели часто демонстрируют хрупкость в решении сложных задач, требующих логического мышления и анализа. Они способны успешно выполнять задания, основанные на статистических закономерностях в данных, но легко дают сбой при столкновении с незнакомыми ситуациями или при необходимости экстраполировать знания за пределы изученного. Эта уязвимость проявляется в неспособности к надежному решению задач, требующих последовательного применения логических правил или понимания причинно-следственных связей, что указывает на отсутствие подлинного понимания, а лишь на имитацию интеллектуальной деятельности, основанную на распознавании паттернов.
Традиционные подходы к обучению с подкреплением, несмотря на свою перспективность в области искусственного интеллекта, сталкиваются с существенной проблемой: необходимостью в обширной и дорогостоящей ручной разметке данных для определения эффективных сигналов вознаграждения. Для того чтобы модель научилась выполнять сложные задачи, требуется, чтобы люди детально прописывали, какие действия являются желательными, а какие — нет. Этот процесс не только требует значительных временных и финансовых затрат, но и ограничивает масштабируемость и обобщающую способность системы, поскольку она становится зависимой от конкретных примеров, предоставленных человеком. В результате, создание универсальных и адаптивных агентов, способных к самостоятельному обучению сложным навыкам, остается сложной задачей, требующей поиска альтернативных методов обучения, не требующих столь интенсивного участия человека.
Основываясь исключительно на оценке конечного результата, современные большие языковые модели испытывают трудности с освоением самого процесса рассуждения. Такая методика обучения, ориентированная на достижение правильного ответа, не позволяет искусственному интеллекту понять как именно было достигнуто решение. В результате, модели демонстрируют хрупкость и уязвимость к незначительным изменениям в формулировках задач, не обладая способностью к адаптации и переносу знаний в новых, незнакомых ситуациях. Подобный подход препятствует созданию действительно надёжных и гибких систем искусственного интеллекта, способных к самостоятельному и осмысленному решению сложных проблем, а не просто к механическому воспроизведению заученных шаблонов.
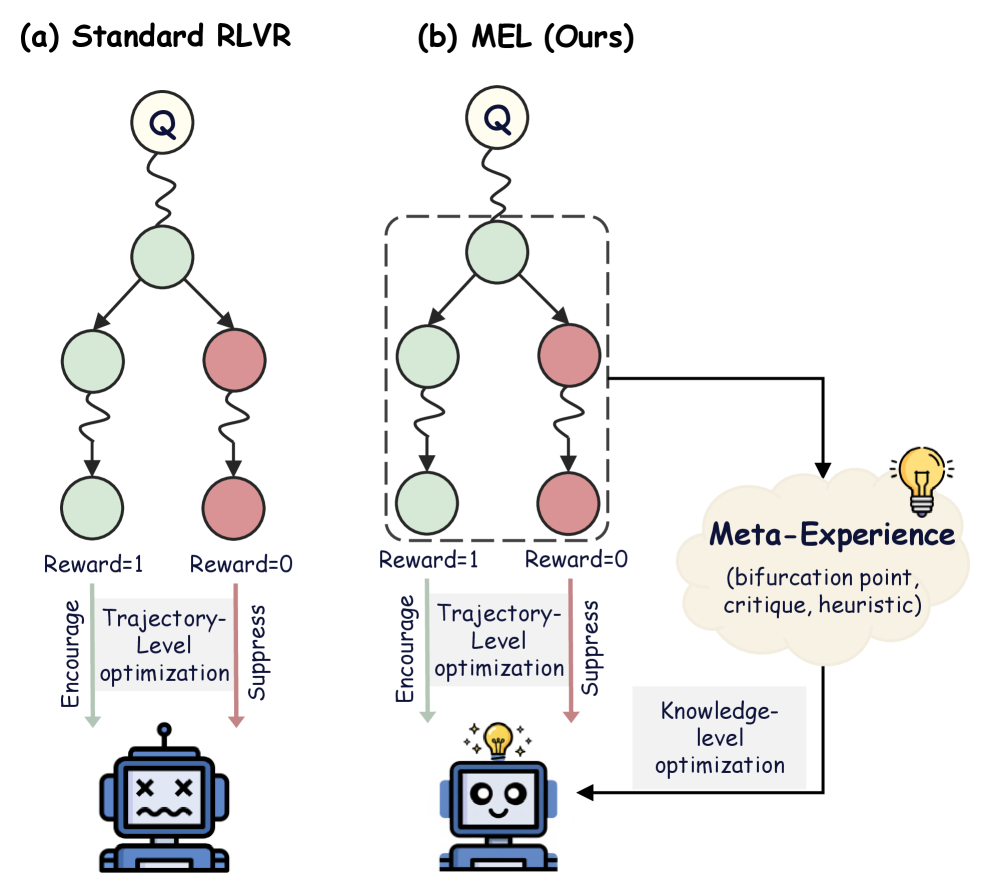
Мета-опыт: Интеграция процесса рассуждения
Мета-обучение с учетом опыта (Meta-Experience Learning) расширяет возможности обучения с подкреплением (Reinforcement Learning) за счет введения верифицируемых наград, но с акцентом на процесс рассуждений, а не только на конечном результате. Традиционное обучение с подкреплением оценивает действия на основе полученной награды, игнорируя последовательность шагов, приведших к ней. В отличие от этого, Meta-Experience Learning анализирует каждый этап рассуждений, выявляя ошибки и закономерности, что позволяет модели не просто научиться достигать цели, но и усвоить эффективные стратегии решения задач. Такой подход позволяет оценивать качество не только результата, но и самого пути, что способствует более глубокому и гибкому обучению.
В основе данной структуры лежит контрастивный анализ, позволяющий выявлять так называемые “точки бифуркации” — конкретные этапы рассуждений, на которых происходит отклонение от корректного решения. Этот метод предполагает сравнение правильных и ошибочных цепочек рассуждений для определения шагов, приводящих к ошибке. Идентифицированные точки бифуркации становятся ключевыми точками для целенаправленного обучения модели, позволяя ей корректировать стратегии рассуждений и избегать повторения ошибок в аналогичных ситуациях. Точность определения этих точек напрямую влияет на эффективность обучения и способность модели к обобщению.
Захватывая эти знания в форме “мета-опыта”, модель формирует параметрическую память эффективных стратегий рассуждений. Это позволяет ей обобщать полученный опыт и применять его к новым задачам, что подтверждено улучшением производительности во всех протестированных масштабах моделей. Параметрическая память, в отличие от непараметрических подходов, позволяет модели динамически адаптировать стратегии рассуждений, а не просто запоминать конкретные решения, обеспечивая более гибкое и эффективное обучение. Экспериментальные результаты демонстрируют, что модели, использующие мета-опыт, показывают значительное улучшение в задачах, требующих сложных рассуждений и планирования.
От траекторий к знаниям: Усвоение и повторное использование опыта рассуждений
В отличие от традиционных подходов, оценивающих качество последовательности действий на уровне траектории в целом, Meta-Experience Learning формирует представления знаний на уровне отдельных шагов рассуждений. Традиционные методы фокусируются на итоговом результате, в то время как данный подход выделяет и кодирует информацию о каждом шаге процесса принятия решений. Это позволяет модели не просто оценивать успешность всей последовательности, но и извлекать уроки из отдельных действий, что способствует более эффективному обучению и обобщению знаний. В результате формируется более детальное и структурированное представление о процессе рассуждений, позволяющее модели адаптироваться к новым задачам и ситуациям.
В основе усвоения опыта рассуждений в Meta-Experience Learning лежит функция потерь — Negative Log-Likelihood (отрицательное логарифмическое правдоподобие). Эта функция позволяет эффективно кодировать полученные знания о шагах рассуждений в параметрическую память модели. В процессе обучения, Negative Log-Likelihood оптимизирует параметры модели таким образом, чтобы максимизировать вероятность правильного предсказания следующего шага рассуждений, основываясь на предыдущих шагах и полученном опыте. Это приводит к формированию компактного представления знаний, которое хранится непосредственно в весах нейронной сети и может быть использовано для улучшения производительности в дальнейшей работе.
Эмпирическая валидация продемонстрировала, что использование внутренних представлений опыта (internalized experiences) значительно повышает точность и устойчивость модели. В ходе экспериментов было зафиксировано улучшение показателя Pass@1 на 3.92-4.73% по сравнению с базовым уровнем GRPO. Данный прирост свидетельствует о том, что механизм Meta-Experience Learning эффективно использует накопленные знания о процессе рассуждений для повышения качества генерируемых ответов и снижения чувствительности к вариациям входных данных.

Повышение производительности: Обобщение и устойчивость через мета-опыт
Обучение на основе мета-опыта открывает новые возможности для повышения эффективности в решении сложных задач, что подтверждается прогрессом в алгоритмах, подобных REINFORCE++. Данный подход позволяет модели не просто учиться на текущем опыте, но и обобщать полученные знания, формируя своего рода “опыт опыта”, который затем используется для улучшения стратегий и достижения более высоких результатов. По сути, алгоритм учится учиться, что позволяет ему быстрее адаптироваться к новым ситуациям и превосходить ограничения, присущие традиционным методам обучения с подкреплением. Такой подход демонстрирует потенциал для существенного повышения «потолка» производительности в различных областях, от робототехники до игр и искусственного интеллекта.
Метод самодистилляции выступает в качестве усилителя эффекта, достигаемого обучением на основе мета-опыта. Он заключается в передаче знаний от более сложной, обученной модели — учителя — к более компактной модели — ученику. При этом, ключевым является не просто копирование ответов, а экстракция общих принципов и закономерностей, выявленных в ходе анализа проверенных и успешных опытов. Таким образом, модель-ученик получает не только конкретные решения, но и способность к обобщению, что позволяет ей эффективно адаптироваться к новым, ранее не встречавшимся ситуациям и демонстрировать повышенную устойчивость к шуму и вариациям во входных данных. Данный подход позволяет существенно расширить возможности модели в решении сложных задач, требующих не только точного воспроизведения заученного материала, но и способности к анализу и применению полученных знаний в новых контекстах.
Метод тонкой настройки с использованием отбора проб (Rejection Sampling Fine-Tuning) позволяет модели извлекать максимальную пользу из накопленного мета-опыта, значительно повышая её устойчивость к изменениям и способность к обобщению. В ходе исследования было показано, что благодаря этой процедуре отсеиваются менее эффективные примеры обучения, оставляя только наиболее ценные и релевантные. Результаты продемонстрировали заметное улучшение ключевых метрик, таких как Pass@8 и Avg@8, что свидетельствует о более высокой вероятности успешного решения задач и, в среднем, о более качественных результатах. Такой подход позволяет создавать системы, способные не только эффективно функционировать в знакомых условиях, но и адаптироваться к новым, ранее не встречавшимся сценариям.
За пределами текущих ограничений: К адаптивному и эффективному ИИ
Традиционные методы обучения с подкреплением часто сталкиваются с проблемой «взлома вознаграждения», когда алгоритм находит способы максимизировать награду, не решая задачу по назначению. Метод Meta-Experience Learning предлагает иной подход, смещая акцент с непосредственного получения вознаграждения на внутреннее усвоение знаний. Вместо того, чтобы просто «заучивать» действия, приводящие к награде, система стремится к пониманию принципов и закономерностей, лежащих в основе задачи. Такой подход позволяет создавать более устойчивые и адаптивные системы искусственного интеллекта, способные обобщать полученный опыт и успешно справляться с новыми, ранее не встречавшимися ситуациями, что принципиально отличает его от поверхностного обучения, ориентированного исключительно на максимизацию вознаграждения.
Предстоящие исследования направлены на синергию Meta-Experience Learning с передовыми методами искусственного интеллекта, в частности, с графовым рассуждением и нейро-символическим ИИ. Такое объединение позволит создать системы, способные не только накапливать опыт, но и структурировать его в виде знаний, применимых к широкому спектру задач. Графовое рассуждение обеспечит возможность логического вывода и установления связей между различными концепциями, а нейро-символический подход позволит объединить сильные стороны нейронных сетей — способность к обучению на больших данных — с преимуществами символьного ИИ — прозрачностью и объяснимостью. В результате ожидается создание более гибких, эффективных и надежных ИИ-систем, способных к решению сложных проблем и адаптации к изменяющимся условиям.
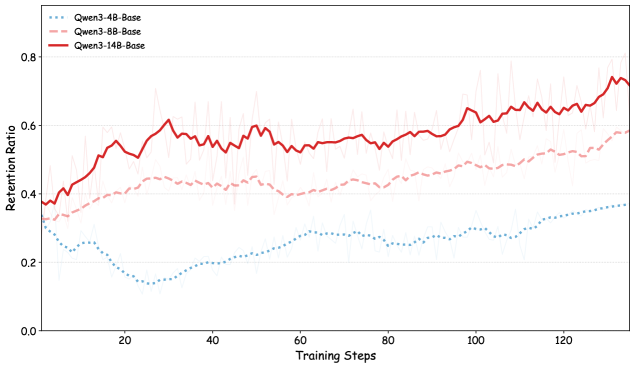
Исследования показали, что способность моделей искусственного интеллекта к удержанию и обобщению опыта — так называемое “мета-обучение” — напрямую связана с их масштабом. Более крупные модели демонстрируют значительно более высокую долю удержания полезных знаний, что свидетельствует об их повышенной способности к абстракции и формированию высококачественных представлений об окружающем мире. Этот феномен открывает перспективы для создания действительно адаптивных и эффективных систем искусственного интеллекта, способных решать сложные задачи, требующие гибкости и обобщения знаний, превосходя традиционные подходы, основанные на простом накоплении опыта и избежании «взлома» системы вознаграждений.
Исследование, представленное в статье, демонстрирует, что истинный прогресс в обучении больших языковых моделей заключается не в слепом наращивании вычислительных мощностей, а в умении извлекать уроки из собственных ошибок. Авторы предлагают концепцию Meta-Experience Learning, позволяющую модели не просто запоминать последовательности действий, но и анализировать причины неудач, формируя тем самым устойчивые представления о мире. Как однажды заметила Барбара Лисков: «Хороший дизайн — это когда система отражает свои предположения». В данном контексте, MEL позволяет модели явно выразить свои предположения о причинно-следственных связях, что, в свою очередь, способствует более гибкому и надежному обучению. Сложность архитектуры неизбежна, но умение модели рефлексировать над собственным опытом — вот что действительно имеет значение.
Куда Ведет Сад?
Представленная работа, стремясь вместить анализ ошибок в саму ткань обучения больших языковых моделей, поднимает вопрос не об инструментах, а об экосистемах. Вместо того, чтобы строить системы, способные лишь избегать падений, создается попытка вырастить сад, где ошибки становятся удобрением для дальнейшего роста. Однако, даже самый ухоженный сад требует постоянного внимания, и предстоит выяснить, насколько устойчива эта “мета-опытность” к непредсказуемым изменениям в ландшафте входных данных.
Очевидно, что ключевой проблемой остается не столько формализация процесса атрибуции ошибок, сколько способность модели к саморефлексии — к осознанию границ собственной компетентности. Верифицируемые награды — это лишь первый шаг. Более глубокое понимание потребует от модели не просто исправления ошибок, но и умения предвидеть возможные сбои в архитектуре собственного мышления, ведь каждый архитектурный выбор — это пророчество о будущем провале.
В конечном счете, истинный прогресс лежит не в увеличении размера модели или сложности алгоритмов, а в развитии способности к адаптации и самовосстановлению. Устойчивость не в изоляции компонентов, а в их способности прощать ошибки друг друга. Именно эта способность к прощению — и к обучению на промахах — станет мерилом истинного интеллекта в будущем.
Оригинал статьи: https://arxiv.org/pdf/2602.10224.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Робот-исследователь: новый подход к автономной навигации
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Искусственный интеллект: хрупкость визуального мышления
2026-02-12 12:00