Автор: Денис Аветисян
Исследователи предлагают метод улучшения обучения больших языковых моделей в задачах с множеством целей, позволяющий более точно оценивать вклад отдельных фрагментов текста в общий результат.
В статье представлен метод блочной оценки преимуществ для многоцелевого обучения с подкреплением, использующий верифицируемые награды и декомпозицию вознаграждений на сегменты текста.
Оценка вклада отдельных действий в многоцелевом обучении с подкреплением часто усложняется из-за смешения сигналов вознаграждения. В работе, посвященной ‘Blockwise Advantage Estimation for Multi-Objective RL with Verifiable Rewards’, предлагается подход, позволяющий декомпозировать вознаграждения и применять их к конкретным сегментам генерируемого текста, что улучшает атрибуцию вклада и масштабируемость к дополнительным целям. Ключевым элементом является Outcome-Conditioned Baseline, приближающая значения промежуточных состояний на основе статистики внутри группы, что позволяет избежать дорогостоящих вложенных прогонов. Сможет ли данная методика стать основой для разработки более эффективных алгоритмов обучения для больших языковых моделей, способных решать сложные задачи с множеством взаимосвязанных целей?
Разоблачение Неустойчивости: Обучение с Подкреплением и Поиск Гармонии
Традиционное обучение с подкреплением зачастую сталкивается с проблемой высокой дисперсии, что существенно затрудняет стабильный процесс обучения, особенно в сложных средах. Эта дисперсия возникает из-за случайности в процессе взаимодействия агента со средой и может приводить к неустойчивым обновлениям политики, колебаниям в производительности и даже к полному провалу обучения. В сложных задачах, где пространство состояний и действий велико, а вознаграждения редки и запаздывают, проблема высокой дисперсии усугубляется, требуя применения специальных методов для стабилизации процесса обучения и достижения надежных результатов. Повышенная чувствительность к случайным факторам ограничивает применимость стандартных алгоритмов обучения с подкреплением в реальных, динамичных системах, где требуется надежность и предсказуемость поведения агента.
В основе метода Group Relative Policy Optimization (GRPO) лежит нормализация вознаграждений внутри групп траекторий, что позволяет значительно снизить дисперсию при обучении с подкреплением. Традиционные алгоритмы часто сталкиваются с проблемой нестабильности из-за высокой вариативности получаемых вознаграждений, особенно в сложных средах. GRPO решает эту проблему, группируя траектории и вычисляя вознаграждения относительно среднего значения внутри каждой группы. Такой подход позволяет уменьшить влияние случайных колебаний и ускорить сходимость алгоритма к оптимальной политике. В результате, обучение становится более стабильным и предсказуемым, что особенно важно при работе с большими моделями и сложными задачами, где даже небольшие флуктуации могут привести к значительным отклонениям от желаемого результата.
Ключевым нововведением GRPO является его способность эффективно масштабироваться для работы с более крупными моделями и массивами данных, что открывает возможности для применения в сложных областях. В отличие от традиционных методов обучения с подкреплением, часто испытывающих трудности при увеличении масштаба, GRPO демонстрирует стабильную производительность даже при обработке огромных объемов информации. Это достигается за счет нормализации вознаграждений внутри групп траекторий, что снижает дисперсию и позволяет модели более эффективно учиться. Такая масштабируемость особенно важна для решения задач, требующих высокой точности и способности к обобщению, например, в робототехнике, автономном вождении и сложных игровых средах, где использование больших моделей и данных становится необходимостью для достижения оптимальных результатов. Благодаря этому GRPO представляет собой перспективный подход к обучению с подкреплением, способный раскрыть потенциал более сложных и мощных моделей.
Несмотря на продемонстрированную эффективность, производительность GRPO (Group Relative Policy Optimization) может быть существенно зависима от корректной настройки гиперпараметров. Это означает, что для достижения оптимальных результатов в конкретной задаче требуется тщательный подбор таких параметров, как размер групп для нормализации вознаграждений и скорость обучения. Чувствительность к гиперпараметрам обуславливает необходимость дальнейших исследований, направленных на разработку более устойчивых и автоматизированных методов их оптимизации, а также на создание адаптивных алгоритмов, способных самостоятельно подстраиваться к различным условиям обучения и обеспечивать стабильную сходимость даже при неоптимальных начальных настройках.
Эволюция GRPO: От DAPO к ScaleRL
Модификация GRPO, известная как DAPO, направлена на повышение стабильности обучения за счет усовершенствованных методов оптимизации и адаптивной настройки параметров. В DAPO используются более точные алгоритмы градиентного спуска и механизмы контроля скорости обучения, которые динамически регулируются в процессе тренировки. Это позволяет избежать колебаний и расхождений, часто возникающих при обучении больших моделей, и обеспечивает более надежную сходимость к оптимальным значениям параметров. Адаптивные параметры включают в себя, например, автоматическую настройку коэффициента обучения для каждого параметра модели, основываясь на истории его обновления и текущем градиенте.
GSPO (Generalized State Policy Optimization) является усовершенствованием алгоритма GRPO, направленным на ускорение обучения и повышение производительности. В отличие от GRPO, GSPO внедряет дополнительные стратегии оптимизации, включая расширенные методы оценки градиентов и адаптивные алгоритмы шага. Эти улучшения позволяют GSPO более эффективно исследовать пространство параметров и быстрее сходиться к оптимальным решениям, особенно в сложных средах и при больших объемах данных. Внедрение дополнительных стратегий оптимизации также позволяет GSPO улучшить устойчивость обучения и избежать локальных оптимумов, что приводит к более надежным и эффективным политикам.
CISPO, как усовершенствование GRPO, фокусируется на оптимизации процесса обучения с акцентом на эффективное исследование пространства вознаграждений и использование полученных знаний. В рамках CISPO используются методы, направленные на баланс между исследованием (exploration) — поиском новых, потенциально более выгодных стратегий — и использованием (exploitation) — применением уже известных, эффективных действий. Это достигается за счет модификации алгоритма обучения, что позволяет более эффективно находить оптимальные решения в сложных средах, где традиционные методы GRPO могут испытывать трудности с поиском глобального максимума вознаграждения. В частности, CISPO использует стратегии для улучшения сходимости и стабильности обучения, избегая застревания в локальных оптимумах.
ScaleRL разработан для решения проблем, возникающих при применении GRPO к моделям экстремально больших размеров, и предоставляет подход к масштабированию для обработки обширных наборов данных. Ключевым аспектом является оптимизация использования памяти и вычислительных ресурсов за счет применения техник параллелизации и распределенных вычислений. Алгоритм ScaleRL адаптирует GRPO, разбивая процесс обучения на более мелкие, управляемые этапы, что позволяет эффективно обрабатывать большие объемы данных без значительного снижения производительности. Это достигается за счет использования градиентного спуска с мини-пакетами и динамического изменения размера пакета в зависимости от доступных ресурсов, а также за счет применения техник квантования и разрежения для снижения требований к памяти.
Разложение Сложности: Блочная Оценка Преимуществ
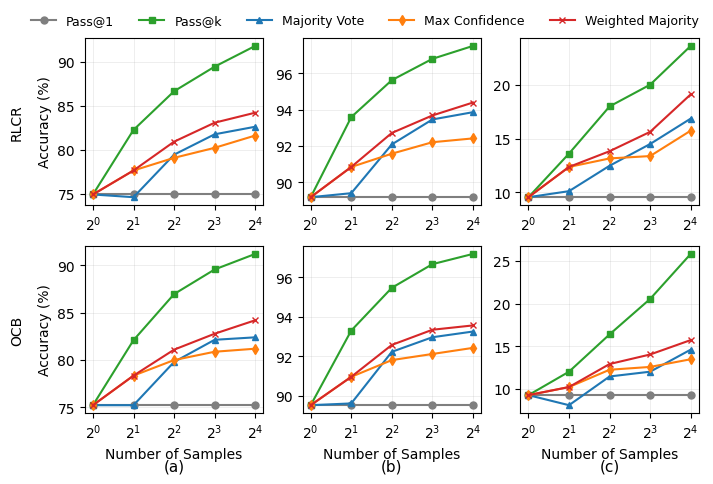
Метод блочной оценки преимуществ (Blockwise Advantage Estimation) представляет собой новый подход к декомпозиции вознаграждений, заключающийся в разделении сложных процессов генерации на управляемые сегменты. Вместо оценки общего вознаграждения за всю последовательность действий, данный подход позволяет оценивать преимущества внутри каждого сегмента, что упрощает процесс обучения и повышает его эффективность в задачах со структурированной генерацией. Разбиение на блоки позволяет более точно определить вклад каждого этапа в конечное вознаграждение и, следовательно, улучшить процесс обучения с подкреплением, особенно в задачах, где последовательность действий имеет важное значение.
Оценка преимуществ внутри сегментов при блочном подходе позволяет снизить дисперсию и повысить эффективность обучения в структурированных задачах. Традиционные методы обучения с подкреплением часто испытывают трудности с обработкой длинных последовательностей действий из-за экспоненциального роста дисперсии оценки градиента. Разбиение генерации на более короткие, управляемые сегменты и вычисление преимуществ для каждого сегмента отдельно позволяет уменьшить влияние редких, но значительных событий на общую оценку. Это, в свою очередь, приводит к более стабильному и быстрому обучению, особенно в задачах, где вознаграждение выдается только в конце всей последовательности действий, например, при решении математических задач или планировании сложных операций.
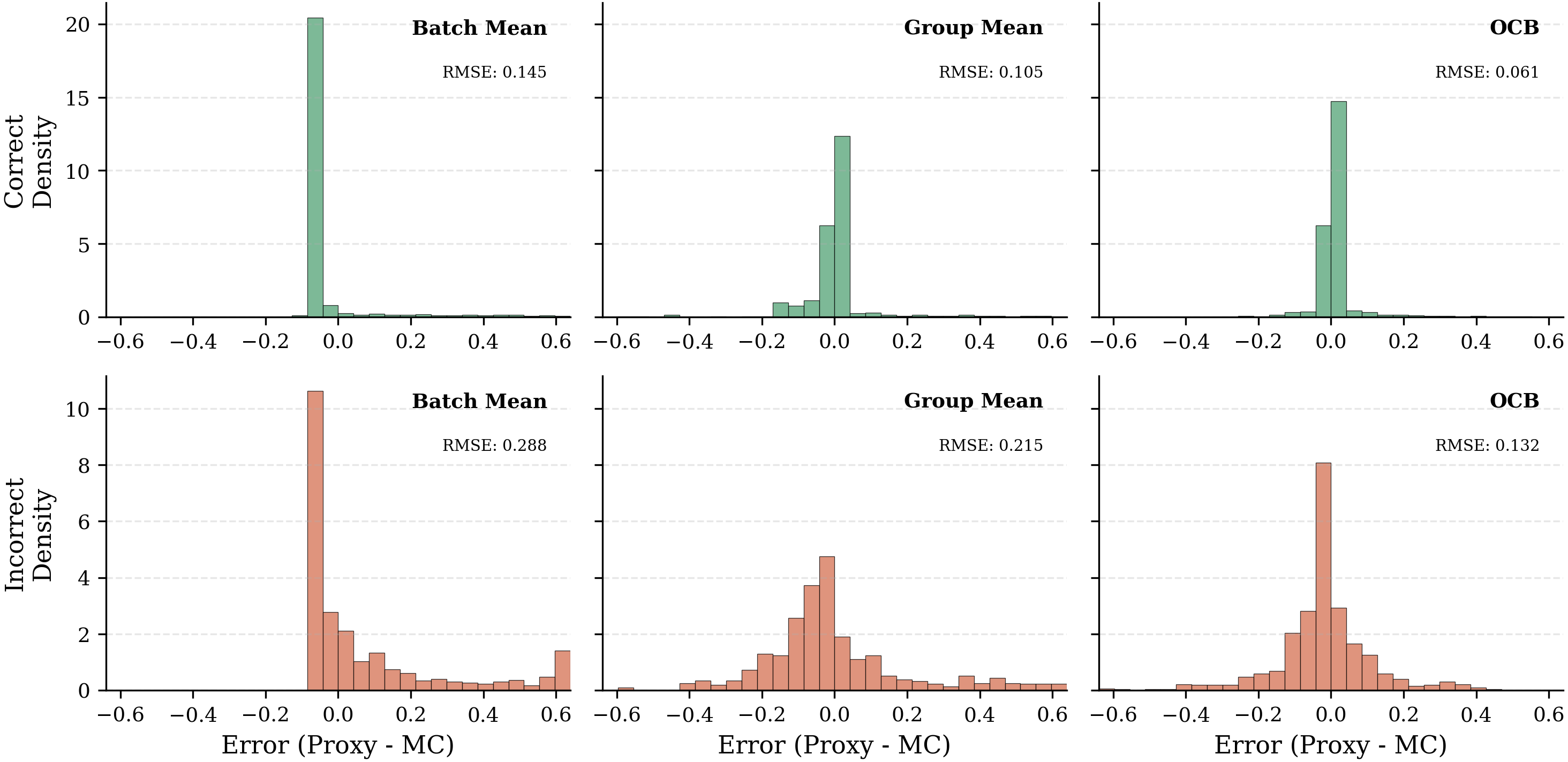
Метод блочной оценки преимуществ повышает точность вычисления преимуществ, используя различные базовые оценки. К ним относятся Outcome-Conditioned (OCB), Batch Mean и Group Mean. OCB оценивает базовый уровень, основываясь на прогнозируемом исходе, что позволяет снизить смещение оценки. Batch Mean вычисляет среднее значение вознаграждений для всей партии, а Group Mean — среднее значение для группы сэмплов. Использование этих базовых оценок позволяет более эффективно отделить сигнал от шума при оценке преимуществ, что приводит к улучшению стабильности и скорости обучения в задачах со структурированными генерациями.
При использовании на наборе данных MATH500, предложенный метод, основанный на Outcome-Conditioned Baseline (OCB), достиг показателя Pass@1 в 0.64. Этот результат демонстрирует сопоставимую эффективность с передовыми подходами, использующими специально разработанные функции вознаграждения. Показатель Pass@1 отражает долю успешно решенных задач из одной попытки, что является ключевой метрикой оценки производительности в задачах математической логики и рассуждений, представленных в MATH500.
При использовании Outcome-Conditioned Baseline (OCB) в рамках Blockwise Advantage Estimation, достигается улучшенная калибровка оценки вознаграждения. На датасете MATH500, OCB демонстрирует ожидаемую ошибку калибровки (ECE) в 0.030. Это представляет собой заметное улучшение по сравнению с 0.044, наблюдаемым при использовании сопоставимых методов оценки вознаграждения. Улучшенная калибровка означает, что предсказанные вероятности соответствуют фактической точности, что повышает надежность и интерпретируемость модели.
При реализации Outcome-Conditioned Baseline (OCB) на наборе данных MATH500, наблюдается зависимость между размером группы и ошибкой калибровки (Expected Calibration Error, ECE). При размере группы равном 32, ECE составляет 0.036, в то время как при увеличении размера группы до 64, ECE снижается до 0.032. Данные результаты демонстрируют, что увеличение размера группы способствует улучшению калибровки модели, хотя и незначительно, в рамках данного эксперимента.
Калибровка Разума: Надежность и Доверие в Искусственном Интеллекте
Применение блочной оценки преимущества (Blockwise Advantage Estimation) к большим языковым моделям (LLM) позволяет значительно улучшить калибровку вероятностных прогнозов. Этот метод, основанный на разделении процесса обучения на блоки, способствует более точному соотнесению предсказанных вероятностей с реальной частотой наступления событий. В результате, модель выдает не просто вероятности, а надежные оценки, отражающие истинную уверенность в своих предсказаниях. Такая калибровка критически важна для построения доверенных систем искусственного интеллекта, поскольку позволяет оценивать риски и принимать обоснованные решения на основе предсказаний модели. Повышенная точность вероятностных оценок, достигаемая благодаря блочной оценке преимущества, открывает возможности для более эффективного использования LLM в различных областях, от финансовых прогнозов до медицинской диагностики.
Калибровка является фундаментальным аспектом создания надежных систем искусственного интеллекта, поскольку она гарантирует, что вероятности, предсказываемые моделью, точно отражают реальную вероятность наступления событий. Необходимо, чтобы уверенность модели в своих предсказаниях соответствовала фактической точности — если модель предсказывает что-либо с вероятностью 90%, то это событие должно происходить примерно в 90% случаев. Отсутствие калибровки может привести к ошибочным решениям и недоверию к системе, особенно в критически важных областях, таких как медицина или финансы. Поэтому, оценка и улучшение калибровки — ключевая задача при разработке и внедрении моделей машинного обучения, обеспечивающая их надежность и предсказуемость.
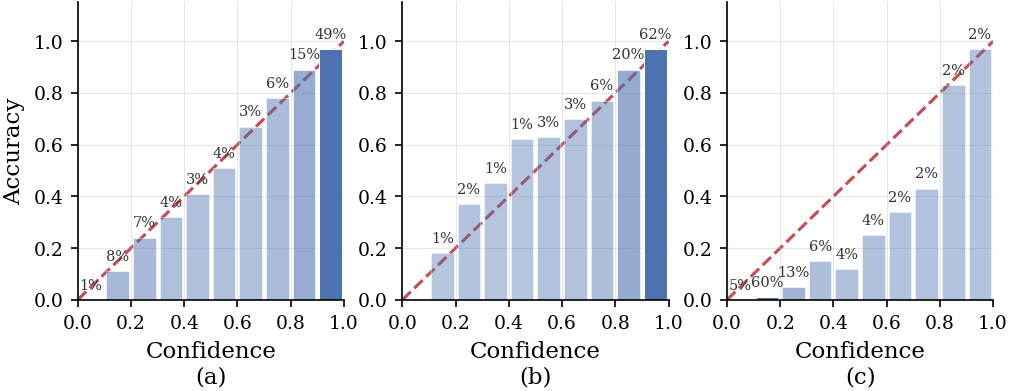
Реализация OCB продемонстрировала впечатляющую производительность на наборе данных MATH500, достигнув значения AUROC в 0.87. Этот показатель свидетельствует о высокой способности модели правильно оценивать вероятность своих предсказаний, что критически важно для построения надежных систем искусственного интеллекта. Полученный результат сопоставим с производительностью передовых существующих методов, подтверждая эффективность предложенного подхода к калибровке больших языковых моделей и его потенциал для применения в различных областях, требующих точной оценки вероятностей.
Оценка предложенной реализации OCB на наборе данных MATH500 демонстрирует высокую точность прогнозирования, подтвержденную значением метрики Brier Score, равным 0.07. Этот показатель свидетельствует о том, что предсказанные вероятности соответствуют реальным частотам событий, что является ключевым фактором для создания надежных систем искусственного интеллекта. При этом, полученное значение Brier Score сопоставимо с результатами, демонстрируемыми передовыми существующими методами, что подтверждает эффективность предложенного подхода к калибровке вероятностных предсказаний больших языковых моделей.
Для оценки и количественной оценки степени откалиброванности больших языковых моделей (LLM) применяются различные метрики. Среди них особое значение имеют Brier Score, измеряющий точность вероятностных предсказаний, и Expected Calibration Error (ECE), определяющий расхождение между предсказанными вероятностями и фактической частотой событий. Кроме того, широко используется Area Under the Receiver Operating Characteristic curve (AUROC), позволяющая оценить способность модели различать истинные и ложные результаты. Использование этих метрик позволяет не только количественно оценить откалиброванность модели, но и сравнить различные подходы к её улучшению, обеспечивая более надежные и заслуживающие доверия прогнозы.
Для дальнейшего повышения надёжности и устойчивости больших языковых моделей рассматривается внедрение методов многоцелевого обучения с подкреплением. Данный подход предполагает использование таких техник, как формирование вознаграждения (Reward Shaping), контроль процесса (Process Supervision) и самопроверка (Self-Verification). Формирование вознаграждения позволяет более эффективно направлять процесс обучения, предоставляя промежуточные сигналы, а контроль процесса обеспечивает соответствие траектории обучения заданным критериям. Самопроверка, в свою очередь, позволяет модели оценивать достоверность собственных предсказаний и корректировать их при необходимости. Сочетание этих методов открывает перспективы для создания более стабильных и предсказуемых систем искусственного интеллекта, способных к более точным и надёжным прогнозам.
Исследование демонстрирует стремление к взлому устоявшихся правил в области обучения с подкреплением. Авторы предлагают метод Blockwise Advantage Estimation, который, по сути, разделяет награду на сегменты текста, позволяя более точно определить вклад каждого из них в общий результат. Это напоминает подход инженера, разбирающего сложный механизм на составные части, чтобы понять принципы его работы. Как однажды заметил Андрей Колмогоров: «Математика — это искусство невозможного». Данная работа подтверждает эту мысль, демонстрируя, что даже в сложных системах, вроде многоцелевого обучения больших языковых моделей, возможно достичь значительных улучшений, если подходить к задаче с нестандартной точки зрения и не бояться экспериментировать с базовыми принципами.
Куда же это всё ведёт?
Представленный подход к оценке преимуществ, разбивая задачу на блоки, словно препарирует чёрный ящик обучения с подкреплением. Это, конечно, прогресс, но лишь убирает симптомы, а не лечит болезнь. Проблема кредитного распределения в многоцелевой оптимизации остаётся: как гарантировать, что «награда» действительно достанется тому сегменту текста, который её заслужил, а не пойдёт блуждать по нейронным сетям, словно потерянный сигнал? Требуется более радикальный пересмотр самой концепции «награды» — возможно, переход от дискретных сигналов к непрерывным полям влияния, отображающим вклад каждого элемента в общий результат.
Более того, предложенный метод, как и большинство современных решений, полагается на эмпирические данные и требует значительных вычислительных ресурсов. Где гарантия, что полученные улучшения масштабируются на более сложные языковые модели и задачи? Необходимы теоретические инструменты для анализа устойчивости и обобщающей способности подобных алгоритмов. Простое увеличение размера модели — это не решение, а лишь отсрочка неизбежного столкновения со сложностью.
В конечном счёте, исследование открывает дверь к более тонкому пониманию процессов обучения языковых моделей, но и подчеркивает, насколько далеки мы от создания действительно «разумных» систем. Вместо того, чтобы слепо оптимизировать метрики, стоит задуматься о принципиально новых подходах к моделированию когнитивных процессов — о создании систем, которые не просто имитируют интеллект, но и способны к самостоятельному познанию и адаптации. И, возможно, тогда «награда» станет не целью, а лишь инструментом на пути к истинному пониманию.
Оригинал статьи: https://arxiv.org/pdf/2602.10231.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Робот-исследователь: новый подход к автономной навигации
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Искусственный интеллект: хрупкость визуального мышления
2026-02-12 13:40