Автор: Денис Аветисян
Новая архитектура Step 3.5 Flash демонстрирует впечатляющую производительность в решении сложных задач, открывая путь к более эффективному и доступному искусственному интеллекту.
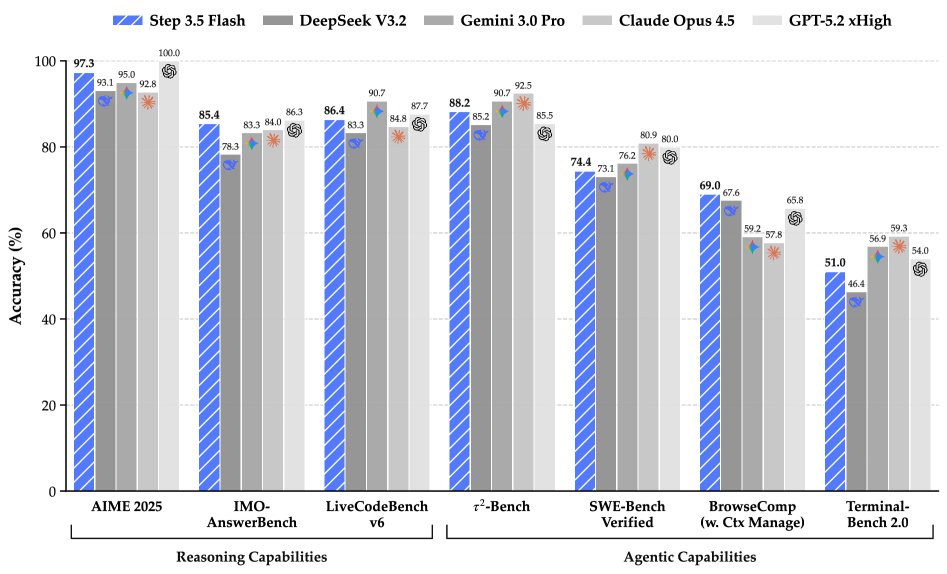
Step 3.5 Flash использует разреженную архитектуру Mixture-of-Experts с 11 миллиардами активных параметров (196 миллиардов всего) для достижения передового уровня в рассуждениях, кодировании и задачах, связанных с автономными агентами, с акцентом на масштабируемость и эффективность.
Современные языковые модели часто требуют огромных вычислительных ресурсов для достижения передовых возможностей. В данной работе представлена модель ‘Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters’, использующая разреженную архитектуру Mixture-of-Experts с 11 млрд активных параметров при общем количестве 196 млрд, что позволяет достичь сопоставимой производительности с передовыми моделями в задачах рассуждения, кодирования и агентоцентричного взаимодействия. Модель оптимизирована для снижения задержки и стоимости многораундовых взаимодействий, а также демонстрирует высокую эффективность в математических, программных и инструментальных задачах, достигая 85.4% на IMO-AnswerBench и 86.4% на LiveCodeBench-v6. Возможно ли дальнейшее повышение эффективности и масштабируемости подобных моделей для развертывания в реальных промышленных средах?
За гранью масштабирования: Потребность в новой парадигме рассуждений
Несмотря на впечатляющую мощь современных языковых моделей, их способность к решению сложных задач, требующих логического мышления, остаётся ограниченной. Существующие архитектуры испытывают трудности при обработке информации, разнесённой на большие расстояния в тексте — так называемые “дальние зависимости”. Это приводит к потере контекста и, как следствие, к неточностям в рассуждениях. Модели часто не способны установить связи между удалёнными элементами информации, необходимыми для построения целостной картины и принятия обоснованных решений. В результате, даже незначительные изменения в формулировке вопроса или предоставлении дополнительного контекста могут существенно повлиять на качество ответа, демонстрируя хрупкость их логических заключений.
Увеличение размера языковых моделей, хотя и демонстрирует определенный прогресс, не является долгосрочным решением проблемы достижения истинных способностей к рассуждению. Современные архитектуры, основанные на статистическом анализе больших объемов данных, испытывают трудности с пониманием сложных взаимосвязей и экстраполяцией знаний в новых ситуациях. Вместо дальнейшего наращивания параметров, необходим принципиально новый подход к построению искусственного интеллекта, который бы имитировал когнитивные процессы, характерные для человеческого мышления — способность к абстракции, логическому выводу и решению проблем на основе принципов, а не просто на основе запомненных шаблонов. Такой сдвиг в архитектуре позволит создавать более эффективные и надежные системы искусственного интеллекта, способные к самостоятельному обучению и адаптации к изменяющимся условиям.
Постоянно растущий спрос на более эффективные и действенные системы искусственного интеллекта обуславливает необходимость преодоления ограничений, присущих существующим подходам. Современные модели, несмотря на впечатляющие достижения в обработке данных, зачастую демонстрируют неспособность к решению сложных задач, требующих глубокого логического анализа и экстраполяции знаний. Это приводит к поиску принципиально новых архитектур и алгоритмов, способных обеспечить не просто увеличение вычислительной мощности, а качественно иной уровень рассуждений и принятия решений. В условиях возрастающей сложности решаемых задач и необходимости оптимизации ресурсов, дальнейшее развитие искусственного интеллекта невозможно без фундаментального пересмотра существующих методологий и смелого внедрения инновационных решений.
Архитектура Step 3.5 Flash: Основа для Фронтирного Интеллекта
Архитектура Step 3.5 Flash использует разреженный подход Mixture-of-Experts (MoE) для значительного увеличения емкости модели без пропорционального увеличения вычислительных затрат. В данной реализации, модель достигает уровня передовых решений, используя 11 миллиардов активных параметров при общей емкости MoE в 196 миллиардов параметров. Это достигается за счет активации лишь части экспертов для каждого входного токена, что позволяет эффективно масштабировать модель без существенного увеличения вычислительной нагрузки во время инференса и обучения.
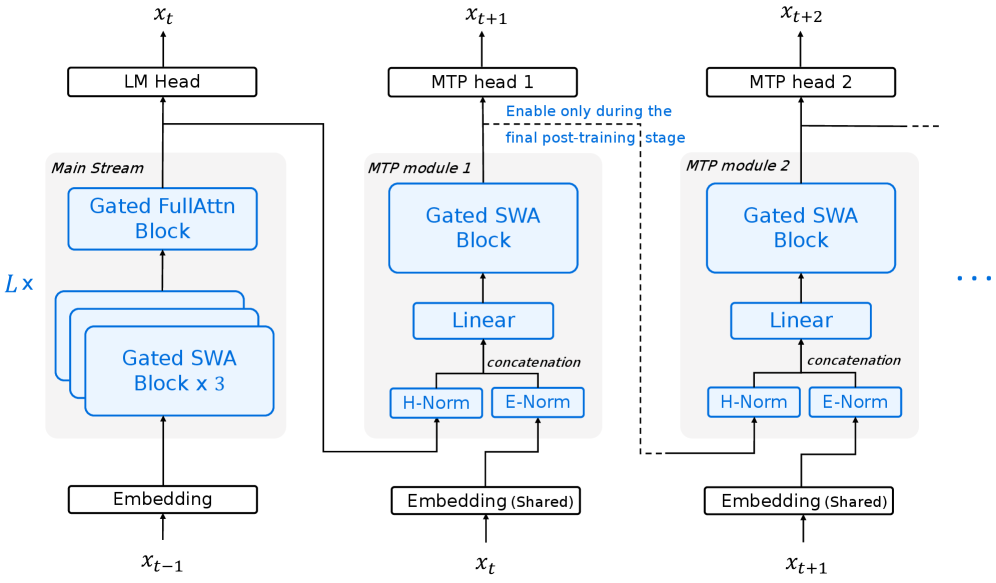
Архитектура Flash использует эффективные механизмы внимания, включая head-wise gated attention и YaRN sequence scaling, для обработки расширенных контекстов. Head-wise gated attention позволяет динамически выбирать, какие головы внимания наиболее релевантны для каждого токена, снижая вычислительную сложность. YaRN (Yet another RNN) sequence scaling — это метод масштабирования, который оптимизирует процесс обработки последовательностей переменной длины, предотвращая экспоненциальный рост вычислительных затрат при увеличении длины последовательности. В совокупности эти механизмы обеспечивают возможность модели эффективно обрабатывать контексты значительно большей длины, чем традиционные модели, без существенного увеличения вычислительной нагрузки.
В основе архитектуры Flash лежит комбинация предсказания нескольких токенов (Multi-Token Prediction) и скользящего внимания (Sliding Window Attention). Предсказание нескольких токенов позволяет модели генерировать сразу несколько токенов за один проход, что значительно увеличивает скорость генерации текста. Скользящее внимание ограничивает область, к которой модель обращает внимание при обработке последовательности, уменьшая вычислительную сложность и, как следствие, снижая вычислительные узкие места. Вместо того, чтобы учитывать всю входную последовательность, модель фокусируется только на ограниченном «окне», что повышает эффективность обработки длинных последовательностей и ускоряет процесс генерации.
Параллельные Рассуждения и Эффективные Стратегии Обучения
Параллельное координированное рассуждение (PaCoRE) представляет собой метод, повышающий способность модели исследовать несколько путей логических заключений одновременно. В отличие от последовательного рассуждения, PaCoRE позволяет модели генерировать и оценивать различные варианты решения задачи параллельно, что приводит к повышению точности и устойчивости. Этот подход заключается в создании множества гипотез и одновременном их тестировании, что позволяет более эффективно находить правильные ответы и избегать ошибок, возникающих при одностороннем анализе. Реализация PaCoRE предполагает использование архитектуры, поддерживающей параллельные вычисления и эффективное управление множеством активных путей рассуждений.
Самодистилляция, или self-distillation, представляет собой метод обучения, при котором модель обучается предсказывать вероятности, выдаваемые более сложной или предварительно обученной моделью, вместо прямых меток данных. Этот процесс позволяет модели обобщать знания, извлеченные из неразмеченных данных, и уменьшает зависимость от больших объемов размеченных данных. В процессе самодистилляции, «студенческая» модель обучается имитировать распределение вероятностей, генерируемое «учительской» моделью, что способствует повышению точности и улучшению обобщающей способности, особенно в условиях ограниченного количества размеченных данных. Это достигается за счет использования «мягких» меток (soft labels), которые содержат больше информации, чем жесткие метки (hard labels), что позволяет студенческой модели лучше понимать взаимосвязи между классами и более эффективно использовать неразмеченные данные.
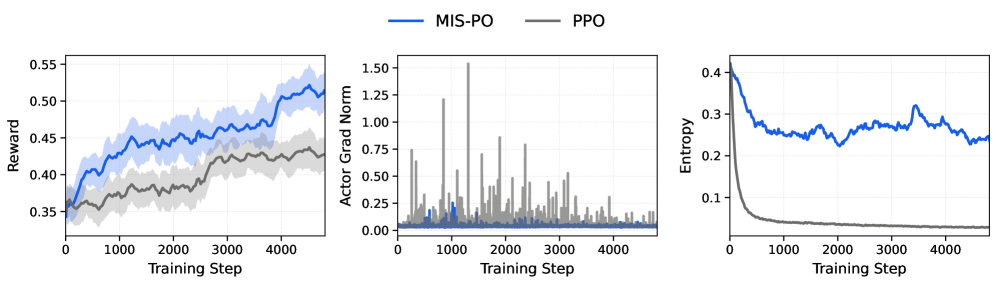
Оптимизация обучения модели достигается за счет использования оптимизатора Muon, который применяет итерацию Ньютона-Шульца для обеспечения стабильных и эффективных обновлений параметров. Данный метод позволяет ускорить сходимость и повысить устойчивость процесса обучения. Дополнительно, для дальнейшей оптимизации используются методы MIS-фильтрованной оптимизации политики (Policy Optimization) и моделирования вознаграждения (Reward Modeling), направленные на уточнение стратегии действий модели и повышение качества прогнозируемых вознаграждений, что в совокупности способствует улучшению общей производительности.
Раскрытие Потенциала: Значение для ИИ и За Его Пределами
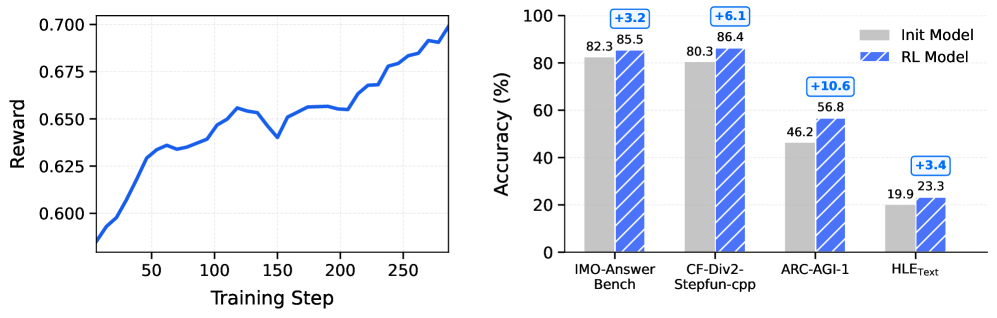
Модель Step 3.5 Flash продемонстрировала значительный прорыв в производительности, подтвержденный результатами тестов на различных бенчмарках. В частности, при решении задач SimpleQA модель достигла точности в 31.6%, что превосходит показатели DeepSeek-V3.2-Exp Base, составившие 27.0%. Данный результат свидетельствует о существенном улучшении способности модели к пониманию и обработке вопросов, требующих логических рассуждений и знаний, что открывает новые перспективы для разработки более эффективных систем искусственного интеллекта в области обработки естественного языка и вопросно-ответных систем.
Модель Step 3.5 Flash демонстрирует впечатляющие результаты в различных тестах, приближаясь к показателям лучших в своем классе. В тестах HumanEval и BBH точность модели составила 81.1% и 88.2% соответственно, уступая лидерам всего на 0.5%. В то же время, в комплексном тесте MMLU модель достигла 85.8% точности, подтверждая свою конкурентоспособность по сравнению с более крупными и ресурсоемкими аналогами. Эти результаты свидетельствуют о высокой эффективности архитектуры и методов обучения, позволяющих Step 3.5 Flash достигать сопоставимого уровня производительности при потенциально меньших вычислительных затратах.
Модель Step 3.5 Flash демонстрирует значительный прогресс в оптимизации использования вычислительных ресурсов, что открывает новые перспективы для создания более доступных и экологически устойчивых решений в области искусственного интеллекта. В отличие от традиционных подходов, требующих огромных вычислительных мощностей, Step 3.5 Flash достигает высокой производительности, эффективно распределяя имеющиеся ресурсы. Это позволяет снизить затраты на обучение и использование моделей, делая их более доступными для широкого круга исследователей и разработчиков, а также уменьшая негативное воздействие на окружающую среду, связанное с потреблением энергии. Такой подход не только способствует демократизации доступа к передовым технологиям ИИ, но и создает основу для долгосрочной устойчивости в быстро развивающейся сфере искусственного интеллекта.
Будущее Рассуждений: К Истинно Интеллектуальным Машинам
Продолжающиеся исследования в области разреженной активации, параллельной обработки и эффективных механизмов внимания направлены на существенное повышение производительности и преодоление текущих ограничений современных моделей искусственного интеллекта. Разреженная активация позволяет снизить вычислительные затраты, задействуя лишь наиболее релевантные нейроны, в то время как параллельная обработка данных значительно ускоряет процесс обучения и инференса. Усовершенствованные механизмы внимания, в свою очередь, позволяют модели фокусироваться на наиболее важных частях входных данных, улучшая ее способность к пониманию и обобщению. Сочетание этих подходов обещает создание более эффективных, масштабируемых и интеллектуальных систем, способных решать сложные задачи с высокой точностью и скоростью.
Интеграция технологии Step 3.5 Flash с многомодальными данными и обучением с подкреплением открывает перспективные возможности для развития робототехники, автономных систем и взаимодействия человека с компьютером. Сочетание высокой скорости обработки информации, обеспечиваемой Step 3.5 Flash, с возможностью анализа данных, поступающих из различных источников — зрения, слуха, тактильных ощущений — позволяет создавать системы, способные к более глубокому пониманию окружающей среды. Обучение с подкреплением, в свою очередь, позволяет этим системам адаптироваться к изменяющимся условиям и принимать оптимальные решения в реальном времени, что критически важно для функционирования автономных роботов, способных к сложным манипуляциям и навигации, а также для создания интуитивно понятных и эффективных интерфейсов взаимодействия между человеком и машиной.
В долгосрочной перспективе, исследования направлены на создание искусственного интеллекта, способного не просто обрабатывать информацию, но и понимать её смысл, логически рассуждать и адаптироваться к изменяющимся условиям окружающей среды. Такой подход предполагает выход за рамки простого распознавания образов и статистического анализа, стремясь к созданию систем, демонстрирующих когнитивные способности, сопоставимые с человеческими. Предполагается, что подобные системы смогут самостоятельно решать сложные задачи, делать обоснованные выводы и принимать решения в условиях неопределенности, открывая новые горизонты в различных областях — от автоматизации и робототехники до научных исследований и творчества. Реализация данного видения потребует прорыва в понимании принципов работы человеческого мозга и разработки принципиально новых алгоритмов и архитектур искусственного интеллекта.
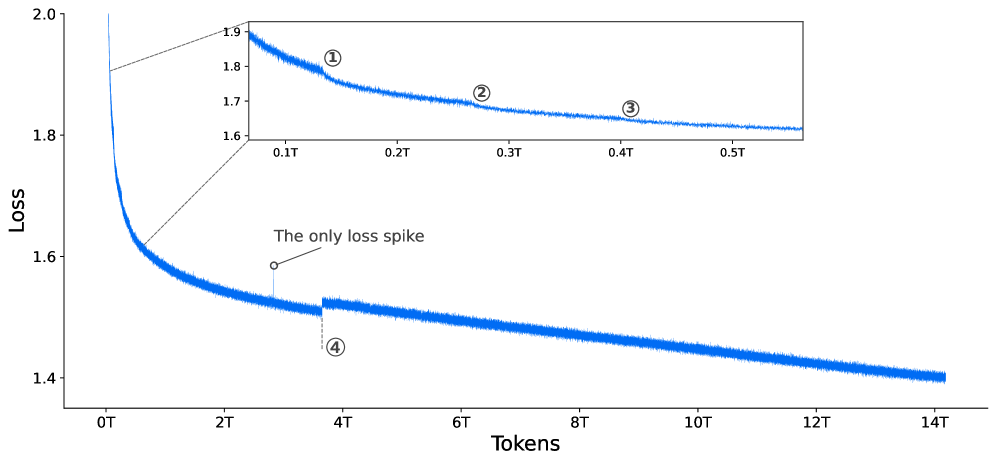
Исследование демонстрирует, что даже относительно компактные модели, такие как Step 3.5 Flash, способны достигать передовых результатов, если архитектура использует принципы разреженных смесей экспертов. Это подтверждает идею о том, что системы растут, а не строятся, и их эффективность определяется не только количеством параметров, но и способом их организации. Как однажды заметил Пол Эрдёш: «Математика — это искусство говорить правду, не будучи точным». Подобно этому, Step 3.5 Flash показывает, что «интеллект» можно достичь не только путем увеличения масштаба, но и через изящную и эффективную структуру, что подчеркивает важность поиска оптимальных решений, а не просто наращивания ресурсов.
Что Дальше?
Эта работа демонстрирует, что иллюзия интеллекта может быть достигнута даже с относительно скромным количеством активных параметров. Однако, в каждом кроне этой разреженной смеси экспертов скрыт страх перед хаосом. Попытка удержать равновесие между производительностью и эффективностью — это вечная гонка, в которой каждая победа лишь откладывает неминуемое столкновение с энтропией. Следующие шаги неизбежно приведут к усложнению инфраструктуры и алгоритмов маршрутизации, что, в свою очередь, создаст новые узкие места и потребует ещё более изощрённых решений.
Надежда на идеальную архитектуру — это форма отрицания энтропии. Более вероятным представляется поиск компромиссов между масштабом, скоростью и надёжностью. Акцент сместится с простого увеличения количества параметров на разработку методов, позволяющих эффективно использовать уже существующие ресурсы. Этот паттерн выродится через три релиза, и эта работа лишь ускорит этот процесс, сделав его более предсказуемым.
Истинным вызовом остаётся не создание искусственного интеллекта, а понимание его ограничений. Следующее поколение исследований должно быть направлено на разработку инструментов, позволяющих предсказывать и смягчать последствия неизбежных сбоев, а не на их предотвращение. Ведь, в конечном счёте, даже самая сложная система — это лишь временная организация хаоса.
Оригинал статьи: https://arxiv.org/pdf/2602.10604.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Робот-исследователь: новый подход к автономной навигации
2026-02-12 17:08