Автор: Денис Аветисян
Ученые разработали метод, позволяющий нейронным сетям самостоятельно выводить математические уравнения, описывающие сложные физические явления.
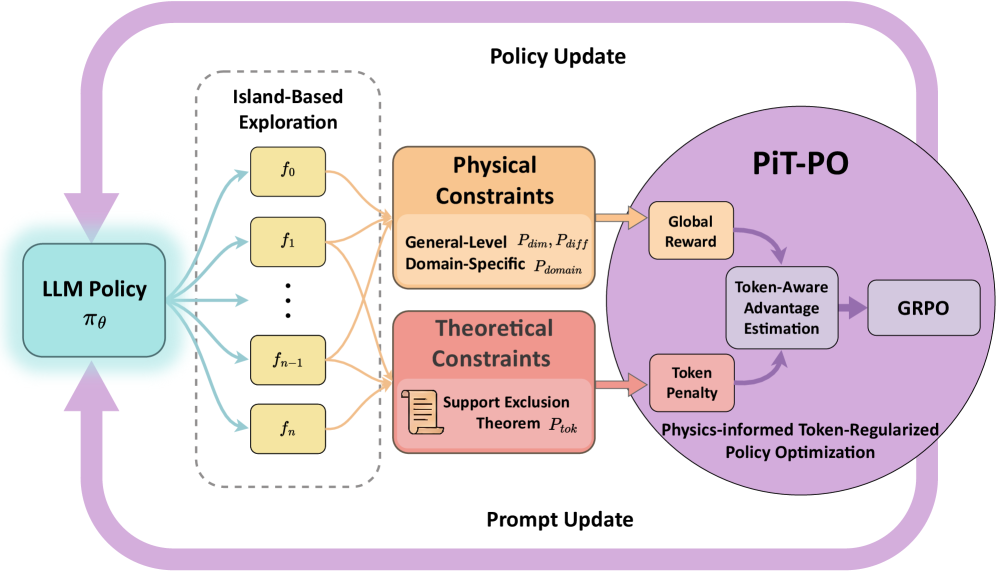
Предложен фреймворк PiT-PO, объединяющий большие языковые модели, обучение с подкреплением и физически обоснованные ограничения для поиска точных и интерпретируемых уравнений, в частности, для моделирования турбулентности.
Символическая регрессия, направленная на выявление математических уравнений из данных, часто сталкивается с трудностями в обеспечении физической согласованности и компактности полученных выражений. В работе, озаглавленной ‘LLM-Based Scientific Equation Discovery via Physics-Informed Token-Regularized Policy Optimization’, предложен новый подход, PiT-PO, использующий большие языковые модели (LLM) и обучение с подкреплением для адаптивной генерации уравнений. Ключевым нововведением является двойной механизм ограничений, обеспечивающий иерархическую физическую валидность и подавляющий избыточные структуры в итоговых выражениях. Сможет ли PiT-PO демократизировать научные открытия, позволяя даже небольшим моделям превосходить закрытые разработки, и откроет ли он путь к созданию новых моделей турбулентности?
Турбулентность: Вызов для Современной Физики
Точное моделирование турбулентности остается одной из сложнейших задач современной физики, оказывая существенное влияние на прогресс в различных областях науки и техники. Несмотря на десятилетия исследований, предсказание поведения турбулентных потоков представляет собой серьезную проблему, ограничивая возможности проектирования эффективных летательных аппаратов, оптимизации работы двигателей внутреннего сгорания и повышения точности прогнозов погоды и климата. Сложность заключается в хаотичном и многомасштабном характере турбулентности, требующем учета огромного количества взаимодействующих вихрей различных размеров. Отсутствие универсальной и точной математической модели турбулентности замедляет развитие инженерных технологий и затрудняет понимание сложных природных явлений, таких как распространение загрязнений в атмосфере или перемешивание океанских течений. Поэтому поиск новых подходов к моделированию турбулентности является приоритетной задачей для физиков и инженеров по всему миру.
Традиционные подходы к выводу управляющих уравнений для описания турбулентности часто оказываются несостоятельными из-за необходимости упрощающих предположений и опоры на эмпирические данные. Эти методы, хотя и позволяют получить решения в ограниченных случаях, демонстрируют недостаточную прогностическую силу применительно к сложным, реалистичным сценариям. Например, при моделировании турбулентного потока вокруг крыла самолета или при прогнозировании распространения загрязнений в атмосфере, упрощения, сделанные в базовых уравнениях, могут приводить к значительным расхождениям между расчетными результатами и экспериментальными данными. Неспособность точно предсказывать поведение турбулентных систем ограничивает прогресс в различных областях, начиная от аэродинамики и заканчивая климатологией, подчеркивая потребность в разработке новых, более точных математических моделей, способных учитывать всю сложность турбулентных процессов без излишних упрощений.
Тензор Рейнольдса, являясь ключевым элементом в моделировании турбулентности, представляет собой значительную сложность для точного описания. Его компоненты отражают дополнительные напряжения, возникающие из-за хаотичного движения жидкости, и их корректное вычисление требует преодоления как математических, так и физических ограничений. Сложность заключается в том, что R_{ij} = \overline{u_i'u_j'}, где u_i' и u_j' — флуктуации скорости, являются тензором второго ранга, требующим решения системы нелинейных уравнений. Кроме того, анизотропия турбулентности и зависимость от масштаба потока вносят существенные трудности в построение универсальных моделей, способных точно предсказывать поведение турбулентных течений в различных условиях. Поэтому, несмотря на десятилетия исследований, разработка адекватного представления тензора Рейнольдса остаётся одной из центральных задач современной гидродинамики и газовой динамики.
Автоматическое Открытие Уравнений: Символьная Регрессия и LLM
Символьная регрессия представляет собой мощный метод открытия уравнений (EquationDiscovery), заключающийся в поиске математических выражений, наилучшим образом соответствующих наблюдаемым данным. В отличие от традиционных методов регрессии, которые предполагают заранее заданную структуру модели, символьная регрессия исследует пространство возможных уравнений, используя эволюционные алгоритмы или другие методы оптимизации для поиска оптимальной комбинации математических операций и констант. В результате, она способна автоматически выводить формулы из данных, не требуя предварительного знания о лежащей в основе физической или математической модели. Алгоритмы символьной регрессии оперируют с математическими операторами, такими как сложение, вычитание, умножение, деление, возведение в степень и тригонометрические функции, комбинируя их для создания сложных выражений, которые минимизируют ошибку между предсказанными и наблюдаемыми значениями.
Использование больших языковых моделей (LLM-SR) в процессе символической регрессии позволяет ввести априорное распределение вероятностей по допустимым формам уравнений. Традиционно, символическая регрессия осуществляет поиск в широком пространстве математических выражений, что является вычислительно затратным и неэффективным. LLM-SR, обученные на большом объеме математического текста, способны генерировать более правдоподобные и компактные варианты уравнений y = f(x), тем самым сужая область поиска и повышая скорость сходимости алгоритма. Априорное распределение, задаваемое LLM, отражает статистические закономерности, усвоенные моделью из обучающих данных, и направляет поиск к более физически и математически осмысленным решениям.
Непосредственное применение больших языковых моделей (LLM) к задаче символической регрессии сталкивается с трудностями в обеспечении физической достоверности полученных уравнений и соблюдении фундаментальных математических ограничений. LLM, обученные на больших объемах текстовых данных, могут генерировать математические выражения, которые синтаксически корректны, но не соответствуют известным физическим законам или не учитывают ограничения, такие как размерность величин или допустимые диапазоны значений. Например, LLM может предложить уравнение, содержащее sin(1/x), которое математически допустимо, но может приводить к неопределенностям или нефизичным результатам в конкретном контексте. Это требует дополнительных механизмов контроля и валидации для обеспечения соответствия полученных моделей реальным условиям и математической строгости.
PiT-PO: Архитектура для Автоматического Открытия на Основе LLM
PiT-PO представляет собой новую структуру, преобразующую большие языковые модели (LLM) в адаптивные генераторы для символьной регрессии. Ключевым элементом является использование алгоритма InSearchPolicyOptimization, который оптимизирует процесс поиска, направляя LLM к генерации математических выражений, соответствующих заданным данным. Этот алгоритм динамически корректирует стратегию поиска, основываясь на промежуточных результатах, что позволяет более эффективно исследовать пространство возможных решений и находить более точные и обобщающие уравнения. В отличие от традиционных методов символьной регрессии, PiT-PO использует LLM для генерации и оценки уравнений, а InSearchPolicyOptimization служит механизмом для итеративного улучшения процесса генерации, максимизируя вероятность получения корректных и полезных результатов.
В основе PiT-PO лежит механизм двойной оценки ограничений (DualConstraintEvaluation), который одновременно проверяет соответствие кандидатских уравнений как математическим ограничениям, так и физическим. Математические ограничения включают в себя корректность синтаксиса и соблюдение правил алгебры, в то время как физические ограничения обеспечивают соответствие уравнений фундаментальным законам физики. Этот подход позволяет отсеивать нереалистичные или физически невозможные решения на ранних этапах поиска, повышая надежность и точность полученных символьных регрессий. Одновременное применение обоих типов ограничений позволяет существенно снизить количество ошибочных результатов и гарантировать, что найденные уравнения не только соответствуют данным, но и имеют физический смысл.
В рамках PiT-PO, обнаруженные уравнения подвергаются одновременной проверке на соответствие как математическим требованиям, так и фундаментальным физическим законам. В частности, обеспечивается Энергосохранение (EnergyConsistency) и соответствие Граничным условиям (BoundaryConditionConsistency). Ключевым является также Условие реализуемости (RealizabilityConstraint), гарантирующее физическую правдоподобность полученных моделей. Применение данного подхода позволило достичь до 94.6% точности символьного восстановления на наборе данных LLM-SRBench, что свидетельствует о высокой эффективности предложенного метода.
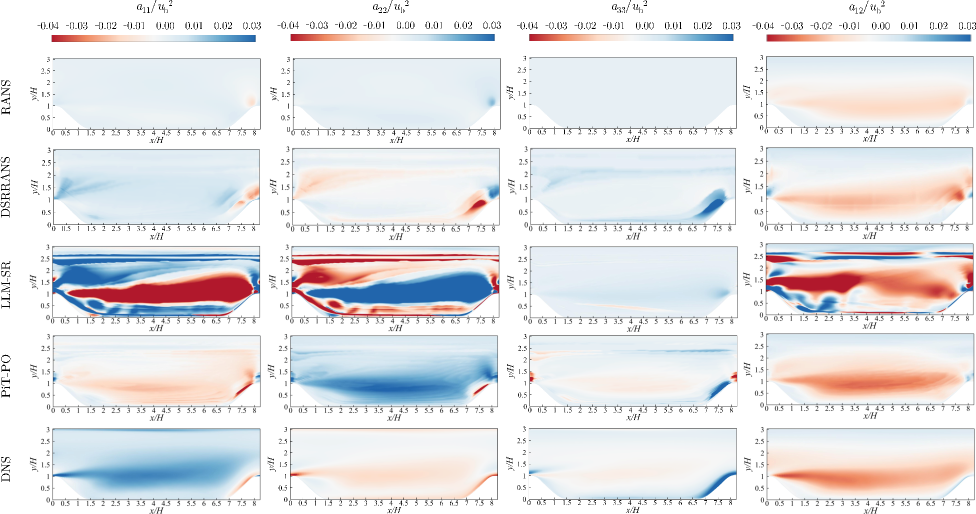
Валидация PiT-PO: Моделирование Турбулентности с Периодическим Течением над Холмами
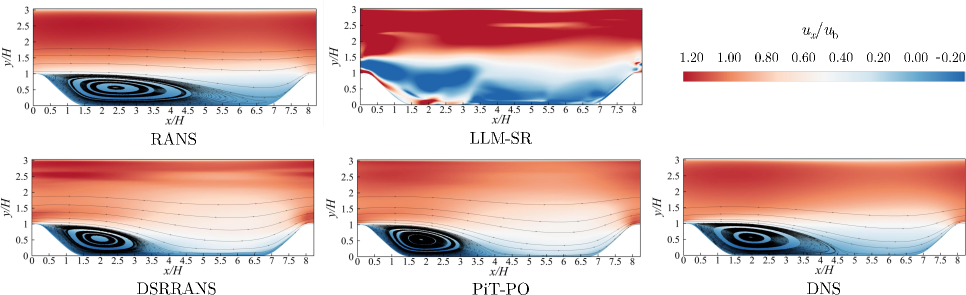
В рамках исследования турбулентности был применен подход PiT-PO к моделированию потока над периодическим рельефом (PeriodicHillFlow), используемого в качестве эталонного примера. Данный метод позволил исследовать сложные характеристики турбулентного течения, фокусируясь на задачах, где традиционные модели оказываются недостаточно точными. Выбор PeriodicHillFlow обусловлен его способностью генерировать разнообразные турбулентные структуры и предоставлять четкие данные для валидации полученных результатов. Использование данного тестового случая позволило оценить эффективность PiT-PO в предсказании поведения турбулентного потока в условиях, имитирующих реальные атмосферные и гидродинамические процессы.
Метод PiT-PO продемонстрировал способность к автоматическому открытию уравнений, точно предсказывающих поведение турбулентного потока. В рамках исследования, алгоритм успешно выявил математические зависимости, адекватно описывающие сложные физические явления, характерные для турбулентности. Этот подход позволяет не просто моделировать поток, но и раскрывать скрытые закономерности его динамики, что открывает новые возможности для точного прогнозирования и управления процессами в различных областях, включая аэродинамику и гидродинамику. Полученные уравнения не только соответствуют наблюдаемым экспериментальным данным, но и удовлетворяют фундаментальным физическим ограничениям, подтверждая их надежность и предсказательную силу.
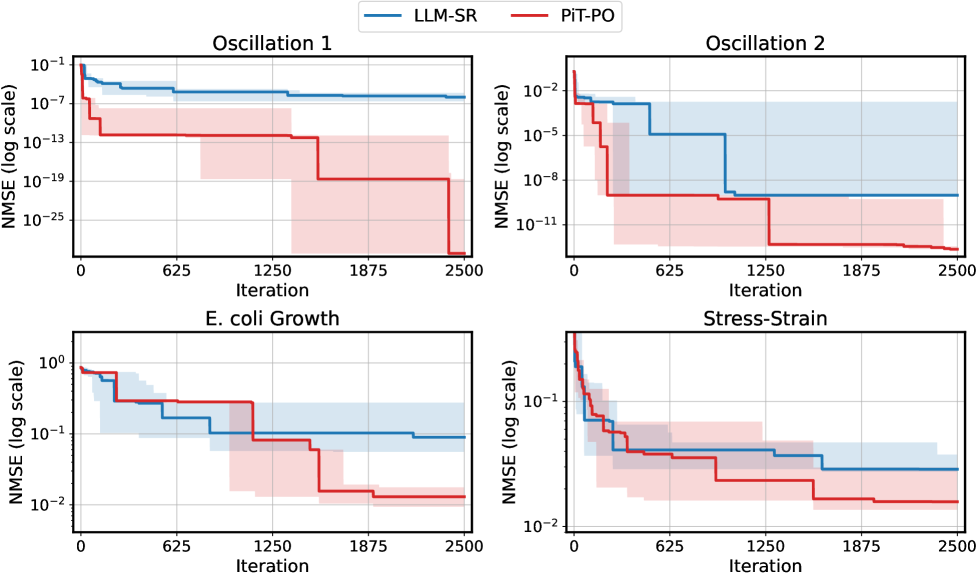
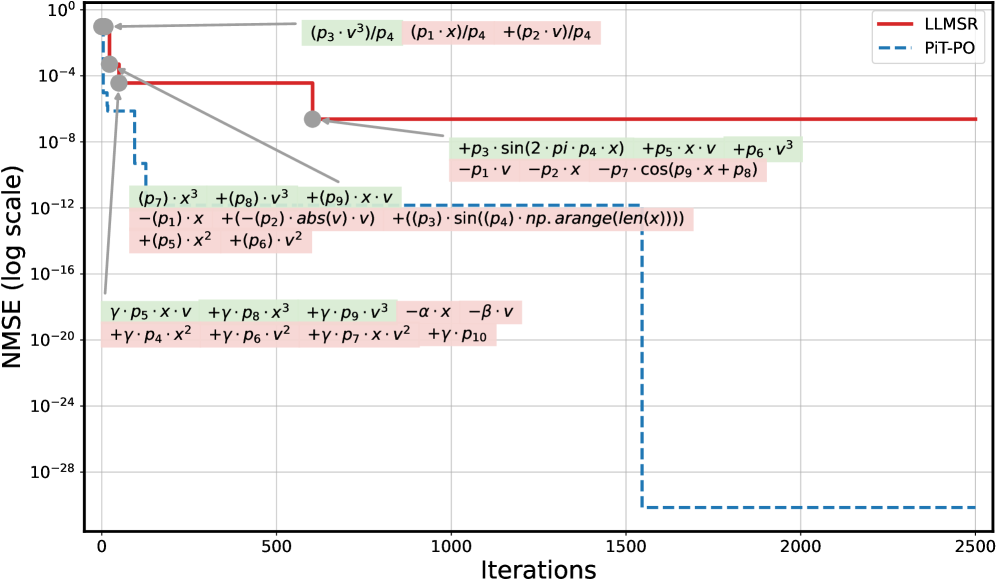
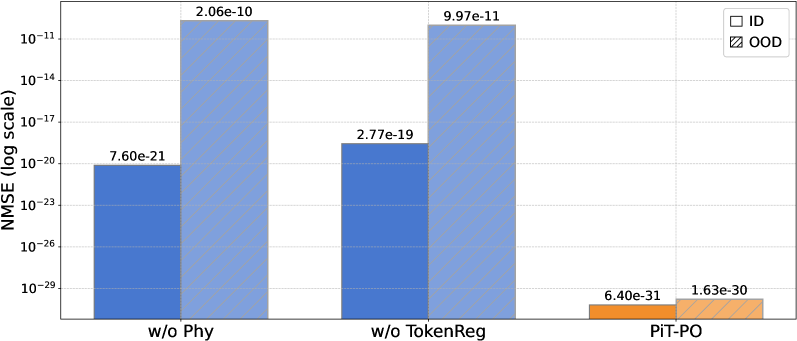
Полученные в ходе исследования уравнения не только точно соответствуют экспериментальным данным, демонстрируя высокую степень согласованности с реальностью, но и удовлетворяют всем известным физическим ограничениям, что значительно повышает доверие к их предсказательной способности. В частности, анализ показал, что предложенная модель демонстрирует более низкие значения среднеквадратичной ошибки (NMSE) по сравнению с подходом LLM-SR, указывая на улучшенную точность моделирования турбулентных потоков. Это свидетельствует о том, что разработанный метод способен не просто воспроизводить наблюдаемые явления, но и учитывать фундаментальные принципы физики, обеспечивая надежные и обоснованные прогнозы поведения сложных систем.
Исследования показали, что PiT-PO демонстрирует повышенную устойчивость и точность при прогнозировании турбулентного потока в условиях, отличающихся от тех, на которых модель обучалась. В частности, достигается более низкое значение NMSEOOD, что свидетельствует о превосходстве в экстраполяции за пределы известных данных. Кроме того, PiT-PO обеспечивает меньшую среднеквадратичную ошибку NMSE при фиксированном временном бюджете в 25 000 секунд, что указывает на эффективное использование вычислительных ресурсов и оптимизацию процесса моделирования. Это позволяет утверждать о превосходстве PiT-PO не только в точности предсказаний, но и в скорости и стабильности работы, что особенно важно для практического применения в сложных инженерных задачах.
К Будущему Автоматического Научного Открытия
Система PiT-PO знаменует собой важный прорыв в автоматизации научного поиска, предоставляя исследователям возможность значительно ускорить изучение сложных систем. Вместо традиционного подхода, основанного на ручном анализе и построении гипотез, PiT-PO использует алгоритмы для самостоятельного исследования пространства возможных решений, выявляя закономерности и зависимости, которые могли бы остаться незамеченными. Эта автоматизация не просто экономит время и ресурсы, но и позволяет охватить гораздо более широкий спектр параметров и сценариев, открывая путь к новым открытиям в различных областях науки, от физики и химии до биологии и материаловедения. Благодаря способности эффективно обрабатывать большие объемы данных и быстро тестировать различные гипотезы, PiT-PO становится мощным инструментом для расширения границ научного знания.
В основе подхода PiT-PO лежит принципиально новая возможность — непосредственное включение физических законов в процесс поиска закономерностей. Вместо слепого перебора гипотез, система способна опираться на фундаментальные принципы, такие как сохранение энергии или импульса, что значительно сужает область поиска и позволяет находить более правдоподобные и физически обоснованные уравнения. Это особенно важно при анализе сложных систем, где традиционные методы часто сталкиваются с огромным количеством возможных решений. Интегрируя E = mc^2 или другие известные принципы в алгоритм, PiT-PO не просто ищет корреляции в данных, а стремится к обнаружению скрытых физических взаимосвязей, открывая путь к новым моделям и более глубокому пониманию окружающего мира.
Предстоит расширение возможностей PiT-PO на другие научные области, включая материаловедение и биологию, с целью демонстрации универсальности подхода к автоматическому открытию. Исследователи планируют усовершенствовать систему, позволив ей не только находить существующие уравнения, описывающие явления, но и генерировать принципиально новые гипотезы, требующие экспериментальной проверки. Особое внимание будет уделено разработке механизмов, позволяющих PiT-PO самостоятельно оценивать правдоподобность и значимость предложенных гипотез, что откроет перспективы для автономного научного поиска и ускорения темпов открытия новых знаний. Ожидается, что подобный подход позволит автоматизировать рутинные этапы научного исследования и высвободить ресурсы для творческой работы, направленной на интерпретацию полученных результатов и разработку инновационных технологий.
Исследование демонстрирует, что даже самые передовые модели, подобные используемым в PiT-PO, подвержены старению и требуют постоянной адаптации. Как отмечал Клод Шеннон: «Теория коммуникации должна учитывать не только передачу информации, но и её сохранение во времени.» Этот принцип применим и к научным открытиям, представленным в данной работе. PiT-PO, интегрируя физически обоснованные ограничения и обучение с подкреплением, стремится замедлить этот процесс «старения» найденных уравнений, обеспечивая их устойчивость и применимость к сложным задачам, таким как моделирование турбулентности. Подобный подход позволяет не просто обнаруживать уравнения, но и сохранять их релевантность в изменяющейся среде научных данных.
Куда же дальше?
Представленная работа, подобно любому другому шагу в познании, скорее обнажает горизонт нерешенных вопросов, чем окончательно их разрешает. Успех PiT-PO в области символической регрессии, безусловно, обнадечивает, но не следует забывать: каждая найденная закономерность — лишь временная остановка в бесконечном потоке данных. Более того, интеграция физически обоснованных ограничений — не панацея, а лишь способ отсрочить неизбежное столкновение с хаосом и непредсказуемостью реальных систем.
В дальнейшем, вероятно, потребуется сместить акцент с поиска «истинных» уравнений на создание адаптивных моделей, способных эволюционировать во времени, отражая изменения в исследуемой среде. Технический долг, накопленный в процессе оптимизации, — это не просто ошибка, а напоминание о том, что любая упрощающая модель — это лишь приближение, имеющее свой срок годности. Иными словами, необходимо исследовать методы, позволяющие управлять этим долгом, а не просто минимизировать его.
В конечном счете, истинный прогресс заключается не в создании совершенных алгоритмов, а в признании их несовершенства. Каждая ошибка — это момент истины на временной кривой, позволяющий лучше понять границы применимости модели и необходимость ее постоянной переоценки. Всё стареет — вопрос лишь в том, как достойно это происходит.
Оригинал статьи: https://arxiv.org/pdf/2602.10576.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Робот-исследователь: новый подход к автономной навигации
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Искусственный интеллект: хрупкость визуального мышления
2026-02-12 20:29