Автор: Денис Аветисян
В статье рассматривается применение тензорных методов для создания интерпретируемых моделей, упрощающих процесс разработки новых материалов.
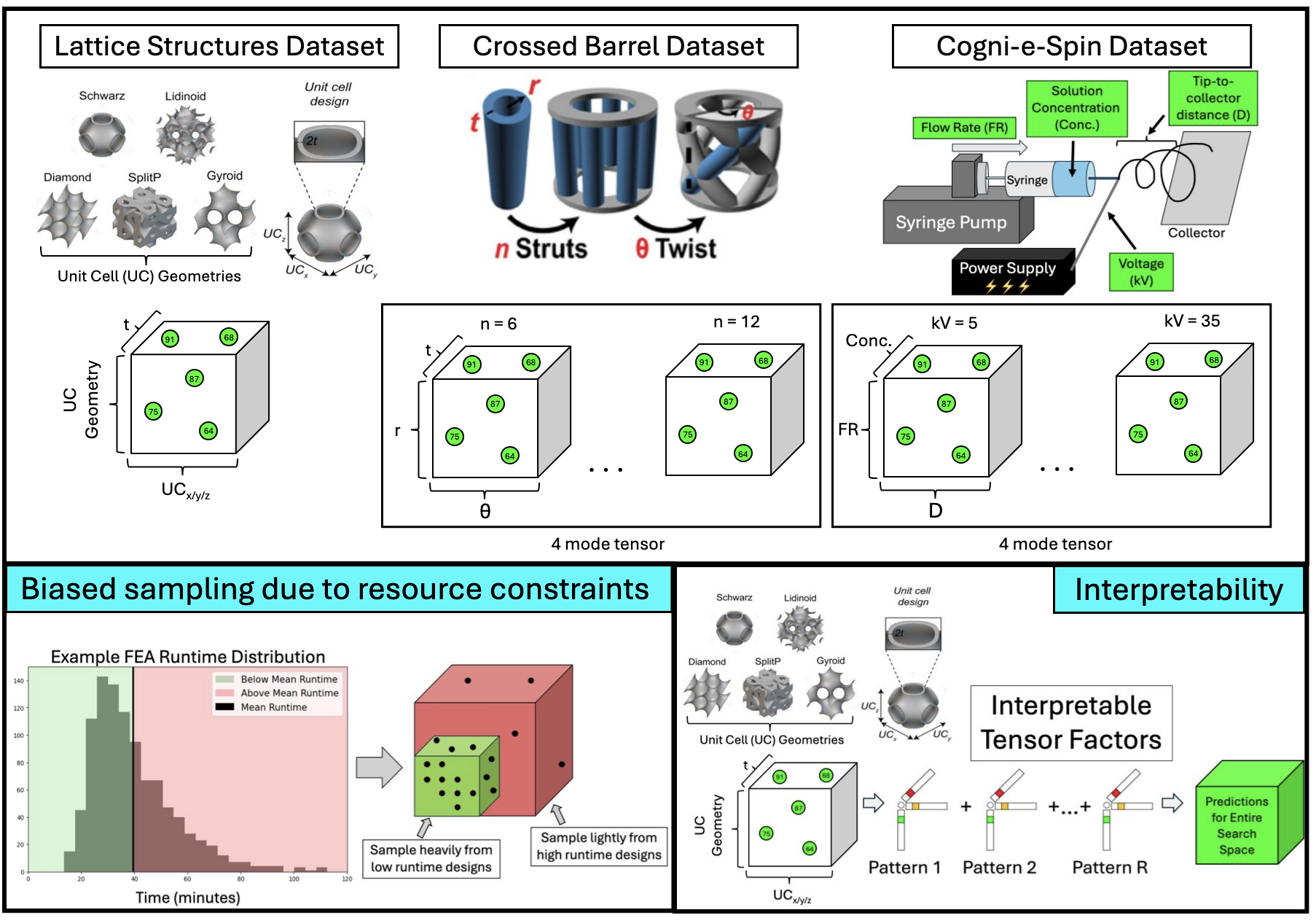
Тензорное завершение как инструмент для создания эффективных суррогатных моделей при работе с неполными и несбалансированными данными.
Поиск новых материалов с заданными свойствами часто сталкивается с экспоненциальным ростом вычислительных затрат при увеличении числа параметров дизайна. В данной работе, ‘Tensor Methods: A Unified and Interpretable Approach for Material Design’, предлагается подход на основе методов тензорного анализа в качестве интерпретируемой суррогатной модели, демонстрирующий улучшенную обобщающую способность, особенно при работе с неравномерно распределенными обучающими данными. Показано, что тензорные методы способны конкурировать с традиционными алгоритмами машинного обучения, при этом обеспечивая интерпретируемые тензорные факторы, позволяющие выявлять физические явления. Возможно ли использование этих факторов для обнаружения новых закономерностей в материалах и оптимизации процессов их разработки?
Простота в Пространстве Вариантов: Вызов Сложных Проектов
Проектирование материалов и конструкций часто сопряжено с огромным и сложным пространством вариантов, что делает полный перебор всех возможных решений практически невозможным. Представьте себе задачу оптимизации формы крыла самолета или состава нового сплава — количество комбинаций параметров, влияющих на конечные характеристики, может исчисляться миллионами или даже миллиардами. Традиционные методы, требующие проведения дорогостоящих экспериментов или сложных численных расчетов для каждой комбинации, сталкиваются с фундаментальным ограничением — невозможностью исследовать все точки в этом пространстве. Это требует от инженеров и ученых разработки инновационных подходов, позволяющих эффективно ориентироваться в этих сложных ландшафтах и находить оптимальные решения, не прибегая к полному перебору вариантов. Поиск оптимальных материалов и конструкций становится задачей не просто анализа, а скорее — интеллектуального исследования, требующего новых алгоритмов и методов машинного обучения.
Традиционные методы, такие как конечно-элементный анализ (FEA), несмотря на свою точность, предъявляют значительные вычислительные требования к ресурсам. Каждая итерация моделирования, особенно для сложных конструкций и материалов, требует огромного количества процессорного времени и памяти, что существенно замедляет процесс инноваций. Этот фактор особенно критичен при исследовании обширных проектных пространств, где необходимо оценить множество вариантов для достижения оптимального решения. В результате, даже небольшие изменения в конструкции или материале могут потребовать повторного проведения ресурсоемкого анализа, что ограничивает скорость и масштабы оптимизации и делает невозможным быструю проверку гипотез и поиск принципиально новых решений в области материаловедения и инженерии.
В процессе проектирования материалов и конструкций часто возникает проблема неравномерного и ограниченного сбора данных о свойствах в исследуемом пространстве параметров. Это приводит к дисбалансу данных, когда определенные области пространства параметров изучены гораздо более подробно, чем другие, или когда данные для определенных свойств встречаются реже. Неравномерность выборки усложняет построение надежных моделей и алгоритмов машинного обучения, поскольку они могут быть смещены в сторону наиболее представленных данных. В результате, оптимизация характеристик материалов и конструкций становится затруднительной, поскольку модели могут неточно предсказывать поведение в областях, где данных недостаточно. Для решения этой проблемы применяются специальные методы, такие как активное обучение и генерация синтетических данных, направленные на более эффективное использование доступной информации и заполнение пробелов в данных.
Суррогатное Моделирование: Быстрый Путь к Оптимизации
Суррогатное моделирование представляет собой вычислительно эффективную альтернативу прямым симуляциям, особенно в задачах оптимизации и анализа чувствительности. Вместо выполнения ресурсоемких расчетов для каждой точки в пространстве параметров, суррогатная модель, являясь аппроксимацией исходной симуляции, позволяет быстро оценивать поведение системы. Это достигается путем построения математической модели на основе ограниченного набора данных, полученных в результате прямых симуляций или экспериментальных измерений. Таким образом, суррогатное моделирование значительно сокращает время вычислений и позволяет исследовать более широкий диапазон параметров, сохраняя при этом приемлемую точность результатов. В частности, это критически важно для задач, требующих многократных вычислений, таких как оптимизация формы, калибровка моделей и анализ неопределенностей.
В основе многих методов суррогатного моделирования лежат алгоритмы машинного обучения (ML), позволяющие прогнозировать поведение сложных систем и оптимизировать их параметры без проведения дорогостоящих и ресурсоемких прямых вычислений. ML-модели обучаются на ограниченном наборе данных, полученных в результате прямых симуляций или экспериментов, и затем используются для аппроксимации отклика системы в любой точке проектного пространства. Это значительно сокращает время, необходимое для поиска оптимальных решений, особенно в задачах, где каждое прямое вычисление занимает часы или дни. Алгоритмы регрессии, нейронные сети и гауссовские процессы — типичные примеры ML-методов, применяемых в суррогатном моделировании для построения эффективных и точных аппроксимаций.
Метод завершения тензоров является эффективным инструментом в суррогатном моделировании, позволяющим оценивать производительность по всему пространству проектирования, используя ограниченный набор данных. В основе метода лежит представление данных о производительности в виде тензора, где каждая размерность соответствует параметру проектирования. Завершение тензоров использует методы машинного обучения для заполнения недостающих значений в тензоре, экстраполируя и интерполируя данные на основе имеющихся наблюдений. Это позволяет предсказывать производительность для комбинаций параметров, для которых прямые вычисления не проводились, значительно сокращая вычислительные затраты при оптимизации и исследовании пространства проектирования. Эффективность метода напрямую зависит от качества и объема исходных данных, а также от выбора подходящего алгоритма завершения тензоров, учитывающего особенности задачи.
За пределами Прогнозирования: Важность Интерпретируемости
Интерпретируемость суррогатных моделей является критически важным фактором для формирования доверия и понимания у разработчиков, позволяя им верифицировать и уточнять проектные решения. Отсутствие прозрачности в работе модели может привести к принятию неверных решений, особенно в критически важных приложениях. Возможность анализировать логику работы суррогатной модели позволяет выявлять потенциальные ошибки, предвзятости и нежелательные взаимодействия между параметрами. Это, в свою очередь, способствует повышению надежности и эффективности проектируемых систем, а также обеспечивает возможность обоснованного принятия решений на основе результатов моделирования.
Каноническое полиадическое разложение (CPD) представляет собой метод декомпозиции тензоров, позволяющий представить многомерные данные в виде суммы ранговых произведений. В основе CPD лежит представление тензора \mathcal{X} \in \mathbb{R}^{I_1 \times I_2 \times \dots \times I_N} в виде суммы R компонент, каждая из которых является тензорным произведением векторов. Математически это выражается как \mathcal{X} \approx \sum_{r=1}^{R} \mathbf{a}_r \otimes \mathbf{b}_r \otimes \dots \otimes \mathbf{c}_r, где \mathbf{a}_r, \mathbf{b}_r, \dots, \mathbf{c}_r — векторы-факторы. Такое разложение позволяет выявить скрытые взаимосвязи между переменными, представленными в тензоре, и упростить анализ данных, представляя их в виде более компактной и интерпретируемой формы. Факторы, полученные в результате CPD, могут рассматриваться как латентные переменные, описывающие основные паттерны в данных.
Метод Shapley Additive Explanations (SHAP) позволяет объяснить выходные данные нейронных сетей, определяя вклад каждого входного параметра в финальный результат. SHAP-значения рассчитываются на основе теории коалиционной игры, где каждый параметр рассматривается как игрок, а выход сети — как выигрыш. Вклад каждого параметра вычисляется путем усреднения его маргинального вклада по всем возможным комбинациям других параметров. Это позволяет оценить важность каждого параметра независимо от других, предоставляя информацию о том, как изменения конкретного параметра влияют на предсказание модели. Результатом является вектор SHAP-значений, который позволяет интерпретировать логику работы нейронной сети и выявлять наиболее значимые параметры, влияющие на принимаемые решения.
Эффективность восстановления тензорных данных оценивается с использованием метрик, таких как Factor Match Score (FMS). FMS представляет собой числовое значение в диапазоне от 0 до 1, которое количественно определяет степень соответствия между различными разложениями тензора. Значение, близкое к 1, указывает на высокую степень схожести между разложениями, что свидетельствует о качественном восстановлении исходной структуры данных. Более низкие значения FMS, приближающиеся к 0, указывают на существенные расхождения между разложениями и, следовательно, на менее точное восстановление тензора. Таким образом, FMS служит объективным критерием для сравнения различных методов восстановления и оценки их производительности.
Влияние и Перспективы: Ускорение Инноваций
Снижение вычислительных затрат и повышение прозрачности моделей машинного обучения открывают новые возможности для ускорения инноваций в материаловедении, инженерии и смежных областях. Традиционно, разработка новых материалов и оптимизация инженерных решений требовали значительных вычислительных ресурсов и времени, связанных с моделированием и анализом сложных систем. Предложенные методы позволяют существенно сократить эти затраты, делая возможным более быстрое и эффективное исследование широкого спектра вариантов. Кроме того, повышенная интерпретируемость моделей способствует лучшему пониманию взаимосвязей между параметрами и свойствами материалов, что, в свою очередь, позволяет инженерам и ученым более осознанно принимать решения и разрабатывать более эффективные и надежные решения. Это особенно важно в критически важных областях, где необходимо тщательно обосновывать каждый шаг и обеспечивать предсказуемость результатов.
Проблема дисбаланса данных является критически важной для обеспечения обобщающей способности и надежности прогнозов во всем пространстве проектирования. Неравномерное представление различных состояний или материалов в обучающем наборе может привести к тому, что модели машинного обучения будут склонны к наиболее часто встречающимся вариантам, игнорируя при этом редкие, но потенциально важные решения. Эффективное решение этой проблемы требует применения специализированных методов, таких как взвешивание классов, генерация синтетических данных или использование алгоритмов, устойчивых к дисбалансу. В конечном итоге, преодоление трудностей, связанных с дисбалансом данных, позволяет создавать более точные и универсальные суррогатные модели, способные успешно работать в широком диапазоне условий и повышать эффективность инноваций в материаловедении и других областях.
Результаты исследований демонстрируют, что применение моделей завершения тензоров значительно повышает обобщающую способность по сравнению с традиционными методами машинного обучения. В частности, зафиксировано увеличение показателя R^2 на 5% в среднем, что свидетельствует о более точных прогнозах. Особенно заметно улучшение в областях, не представленных в обучающей выборке — ошибка в этих “неизведанных” участках пространства параметров снижается вдвое. Это позволяет создавать более надежные и универсальные суррогатные модели, способные эффективно исследовать и оптимизировать сложные системы в материаловедении, инженерии и других областях, где важна предсказуемость и точность.
Оценка производительности суррогатных моделей требует применения строгих метрик, и в данной работе ключевую роль играет коэффициент детерминации R^2. Использование R^2 в сочетании с другими показателями, такими как среднеквадратичная ошибка (MSE) и коэффициент корреляции, позволяет провести всесторонний анализ точности и надежности предсказаний модели в различных областях пространства параметров. Такой подход не только обеспечивает объективную оценку текущих результатов, но и служит основой для дальнейшего совершенствования алгоритмов и разработки более эффективных моделей, способных к точным прогнозиям и обобщению данных. Полученные данные, основанные на количественных показателях, предоставляют ценную информацию для определения направлений будущих исследований и оптимизации методов машинного обучения в материаловедении и смежных областях.
В данной работе исследуются методы тензорного завершения как интерпретируемые суррогатные модели для разработки материалов. Авторы подчеркивают важность обобщающей способности этих моделей, особенно при работе с неравномерно выбранными обучающими данными. Это согласуется с высказыванием Тима Бернерса-Ли: «Данные, которые не связаны, бесполезны». Действительно, эффективность предложенного подхода заключается в умении структурировать и использовать разрозненные данные о материалах, выявляя скрытые взаимосвязи и обеспечивая более точные прогнозы. Простота и ясность в представлении информации, как подчеркивают авторы, являются ключевыми факторами успеха в материаловедении.
Что дальше?
Представленные методы, несомненно, предлагают шаг к более осмысленному проектированию материалов. Однако, необходимо признать, что сама идея “интерпретируемости” часто является лишь тенью стремления к полному пониманию. Тензорное завершение — инструмент, и его эффективность измеряется не в сложности алгоритма, а в ясности полученных результатов. Пределы применимости остаются очевидными: насколько хорошо этот подход масштабируется к системам с ещё большей размерностью и сложностью? И, что более важно, насколько адекватно он отражает фундаментальные физические принципы, а не просто воспроизводит статистические закономерности?
Очевидным направлением является упрощение. Вместо добавления новых слоёв абстракции, следует стремиться к минимальному набору параметров, достаточных для адекватного описания свойств материала. Решение проблемы несбалансированности данных, безусловно, важно, но не стоит забывать о первопричине: стоит ли вообще стремиться к моделированию всех возможных комбинаций, или же более продуктивным является поиск принципиально новых, упрощённых представлений о взаимосвязи между структурой и свойствами?
В конечном счёте, ценность этого подхода будет определяться не его математической элегантностью, а способностью предсказывать свойства материалов, которые действительно полезны. И в этом поиске, как и во всём остальном, простота — не ограничение, а доказательство понимания.
Оригинал статьи: https://arxiv.org/pdf/2602.10392.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- Молекулярный интеллект: проверка химического мышления
- Искусственный интеллект и закон: гармония неизбежна
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Квантовые вычисления для молекул: оптимизация ресурсов
- Долгосрочная память для умных агентов: новый подход к сложным задачам
- Визуальное мышление с языком: новый взгляд на 3D-понимание
- Оптимизация процессов: симбиоз классических и квантовых вычислений
- Освобождая потенциал мультимодальных моделей: метод развёртывания контекста
- Коллидер как квантовый процессор: новый взгляд на взаимодействие частиц
2026-02-13 01:36