Автор: Денис Аветисян
Представлен LiveMedBench — динамичный набор данных для проверки медицинских ИИ, свободный от утечек данных и учитывающий быстро меняющиеся знания.
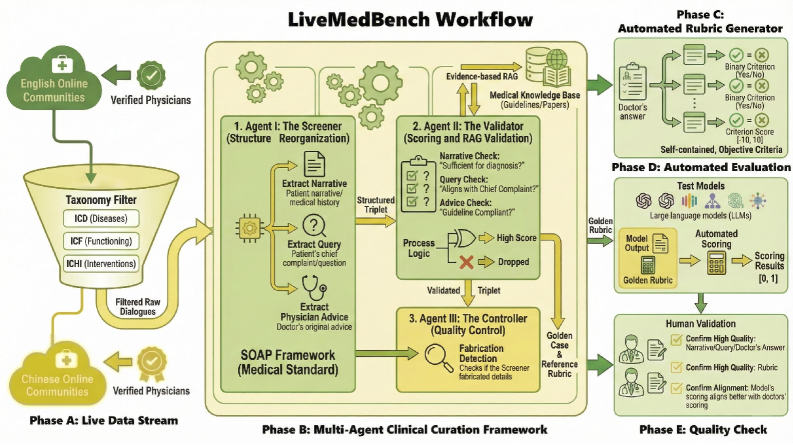
LiveMedBench — это контаминационно-устойчивый медицинский бенчмарк с автоматизированной рубрической оценкой для проверки навыков клинического мышления.
Несмотря на растущий интерес к применению больших языковых моделей (LLM) в клинической практике, надежная и объективная оценка их возможностей остается сложной задачей. В данной работе, представленной под названием ‘LiveMedBench: A Contamination-Free Medical Benchmark for LLMs with Automated Rubric Evaluation’, предлагается новый подход к оценке LLM в медицине, основанный на постоянно обновляемом наборе реальных клинических случаев и автоматизированной системе оценки на основе рубрик. Полученные результаты показывают, что даже самые передовые модели демонстрируют низкую эффективность и подвержены риску загрязнения данных, а основной проблемой является не отсутствие фактических знаний, а неспособность адаптировать их к конкретным условиям пациента. Какие перспективы открывает создание «живых» эталонов для оценки LLM и как это повлияет на внедрение искусственного интеллекта в здравоохранение?
За гранью поверхностной эффективности: кризис клинического ИИ
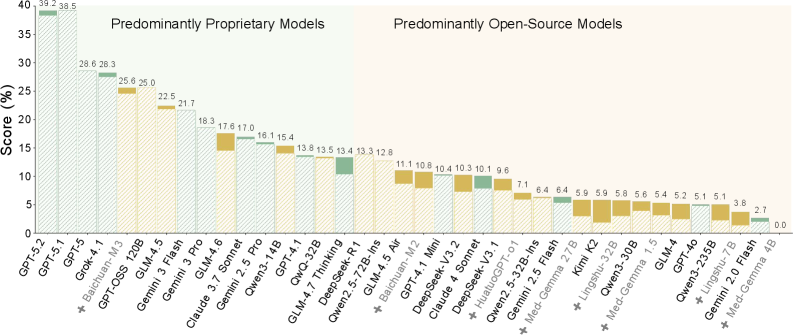
Несмотря на впечатляющие возможности больших языковых моделей, таких как GPT-5.2, их способность к сложному клиническому мышлению остается под вопросом. Исследования показывают, что, демонстрируя высокие результаты в стандартных тестах, эти модели часто испытывают трудности при анализе реальных клинических сценариев, требующих не просто извлечения информации, но и ее критической оценки, интеграции с учетом индивидуальных особенностей пациента и адаптации к изменяющимся обстоятельствам. Это связано с тем, что LLM, в основном, оперируют статистическими закономерностями в данных, а не глубинным пониманием медицинских принципов и патофизиологии, что ограничивает их способность к надежной диагностике и принятию обоснованных решений в сложных клинических ситуациях.
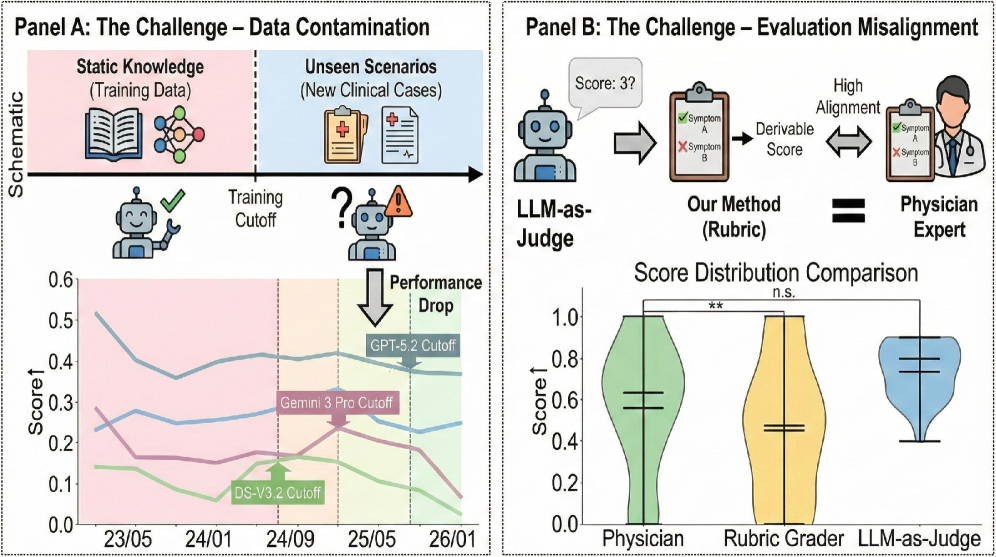
В настоящее время существующие медицинские оценочные тесты всё чаще оказываются подвержены проблеме «загрязнения» данными, что приводит к искусственному завышению показателей точности и маскировке реального уровня клинических навыков искусственного интеллекта. Это происходит из-за того, что данные, используемые для оценки, частично или полностью содержатся в обучающих выборках моделей, создавая иллюзию превосходной производительности, не отражающей способности к решению новых, ранее не встречавшихся задач. В результате, заявленные показатели эффективности могут значительно отличаться от реальной клинической применимости, затрудняя объективную оценку потенциала систем искусственного интеллекта в здравоохранении и создавая риски при их внедрении в практическую медицину.
Исследования выявили существенные недостатки в способности современных больших языковых моделей (LLM) применять медицинские знания к конкретным клиническим случаям. Критически важные ошибки, такие как игнорирование контекста и чрезмерное обобщение медицинских рекомендаций, демонстрируют, что LLM испытывают трудности с адаптацией знаний к уникальным особенностям каждого пациента. Результаты анализа показали, что у 84% протестированных моделей наблюдается значительное снижение эффективности при рассмотрении случаев, датированных позднее периода их обучения, что указывает на серьезную проблему с актуальностью медицинских знаний. Этот факт подчеркивает необходимость разработки новых подходов к обучению и оценке клинического искусственного интеллекта, направленных на обеспечение не только высокой общей производительности, но и способности к адаптации к постоянно меняющейся медицинской информации.
LiveMedBench: фундамент оценки, свободный от искажений
LiveMedBench представляет собой важный шаг вперед в области оценки больших языковых моделей (LLM) в медицинской сфере, отличаясь от существующих бенчмарков непрерывным обновлением данных. Это позволяет снизить риск загрязнения данных, когда модели обучаются на информации, которая должна быть им неизвестна во время оценки, что приводит к завышенным результатам. В отличие от статических наборов данных, LiveMedBench постоянно пополняется новыми клиническими случаями и критериями, обеспечивая более реалистичную и надежную оценку способности LLM к клиническому мышлению и диагностике. Постоянное обновление данных делает LiveMedBench более устойчивым к «запоминанию» ответов и позволяет оценивать истинные способности модели к обобщению и применению знаний в новых ситуациях.
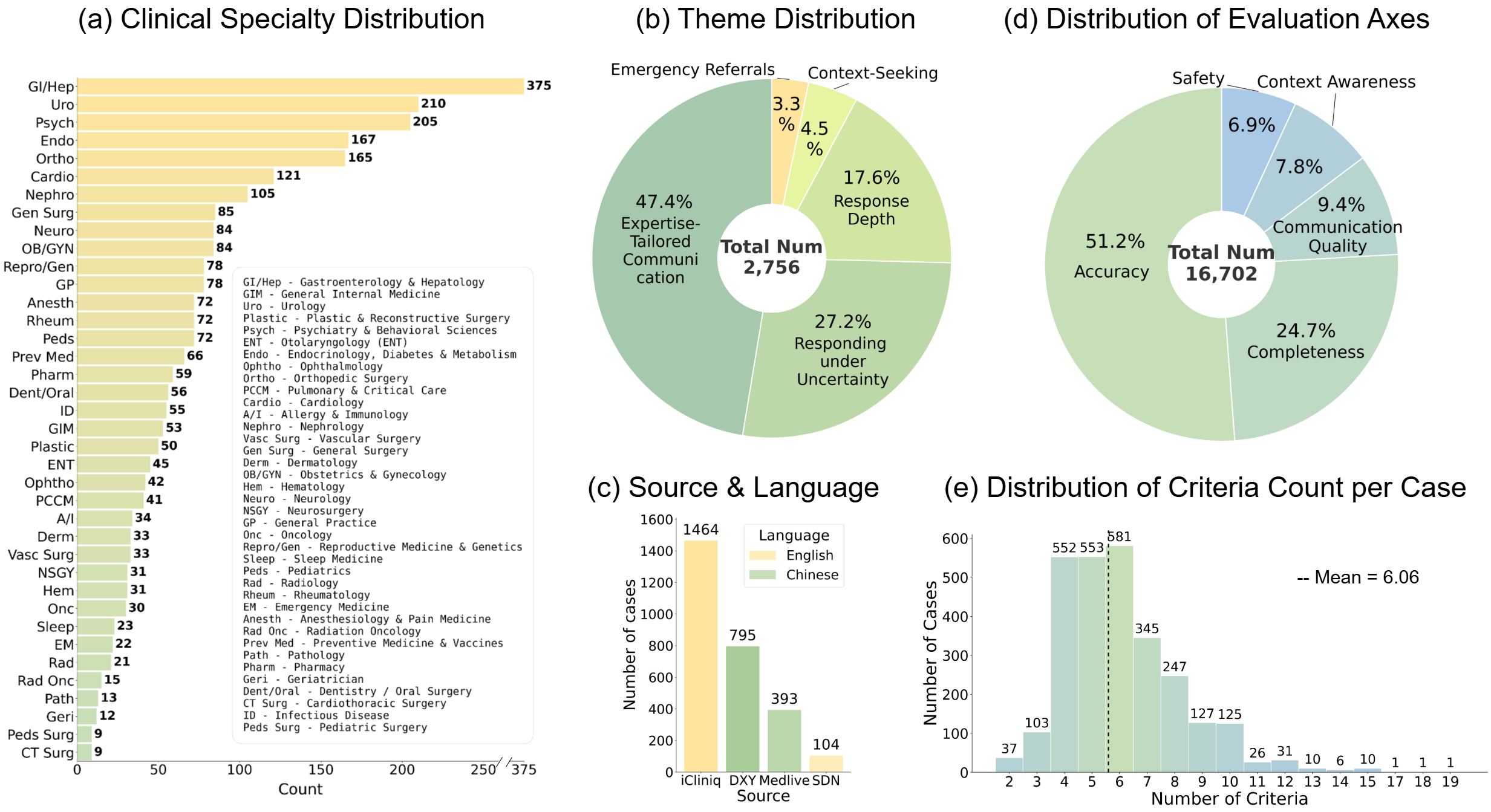
LiveMedBench включает в себя обширный набор данных, состоящий из 2756 клинических случаев и 16702 критериев оценки. Такой масштаб позволяет проводить всестороннее тестирование возможностей больших языковых моделей (LLM) в области клинического мышления. Каждый случай представлен комплексно, что позволяет оценивать не только точность ответов, но и способность модели к комплексному анализу и принятию решений в реалистичных медицинских сценариях. Большое количество критериев позволяет детализированно оценивать различные аспекты клинического рассуждения, обеспечивая более надежную и объективную оценку производительности LLM.
LiveMedBench позволяет оценивать сложные навыки клинического мышления, выходя за рамки простых вопросов и ответов и фокусируясь на диагностике и планировании лечения. Анализ показал, что современные модели машинного обучения демонстрируют более 50% ошибок по большинству оценочных параметров LiveMedBench. Данный результат подчеркивает сложность задачи, связанной с созданием искусственного интеллекта, способного к полноценному клиническому рассуждению и принятию обоснованных медицинских решений.
От шума к знанию: создание и оценка клинических случаев
Многоагентная структура курации клинических случаев преобразует неструктурированные дискуссии из онлайн-источников в формализованные, подкрепленные доказательствами клинические случаи для базы данных LiveMedBench. Этот процесс включает в себя автоматическую обработку и структурирование информации, извлеченной из различных онлайн-платформ, таких как форумы и медицинские сообщества. Целью является обеспечение высокого качества данных, необходимых для обучения и оценки больших языковых моделей (LLM) в медицинской сфере. Курация включает в себя верификацию, аннотацию и организацию информации, что позволяет создать надежный и стандартизированный набор клинических случаев для использования в исследованиях и разработке медицинских инструментов.
В рамках разработанной системы построения клинических случаев применяется метод Retrieval-Augmented Generation (RAG), позволяющий значительно расширить детализацию и релевантность предоставляемой информации для больших языковых моделей (LLM). RAG предполагает извлечение релевантных данных из внешних источников и их интеграцию в процесс генерации ответа, что обеспечивает LLM доступ к более полному контексту и повышает точность и обоснованность формируемых клинических заключений. Это позволяет преодолеть ограничения, связанные с объемом знаний, заложенных непосредственно в LLM, и динамически дополнять их актуальной информацией, необходимой для решения конкретной клинической задачи.
Для масштабируемой и объективной оценки производительности больших языковых моделей (LLM) разработана автоматизированная система оценки на основе рубрик. Анализ результатов показал, что модели демонстрируют ошибки в различных клинических сценариях, при этом среднее значение коэффициента Жаккара (Jaccard similarity) составляет всего 0.24. Этот показатель указывает на то, что выявленные ошибки не связаны с общими проблемами качества данных, а обусловлены специфическими трудностями, возникающими при обработке конкретных случаев.
Анализ ошибок, допущенных ведущими языковыми моделями при обработке клинических случаев, выявил, что от 35% до 48% этих ошибок связаны с игнорированием контекста или неспособностью интегрировать различные части информации. Данный тип ошибок указывает на ограничения моделей в понимании взаимосвязей между симптомами, историей болезни и другими релевантными факторами, что определяет необходимость улучшения способности моделей к комплексному анализу и интеграции данных для повышения точности диагностики и принятия решений.
За пределами оценки: преодоление пробелов в знаниях и перспективы развития
Разработка LiveMedBench направлена на преодоление проблемы устаревания медицинских знаний, которая представляет собой серьезную трудность для современных систем искусственного интеллекта. В отличие от статичных наборов данных, эта платформа использует механизм непрерывного обновления своей базы клинических случаев, оперативно интегрируя последние открытия, новые протоколы лечения и актуальные клинические рекомендации. Такой подход позволяет поддерживать релевантность и точность системы в динамично меняющемся медицинском мире, обеспечивая, что искусственный интеллект, обученный на LiveMedBench, способен предоставлять актуальную и надежную поддержку врачам и улучшать качество медицинской помощи. Постоянное обновление библиотеки случаев гарантирует, что система не только отражает текущее состояние знаний, но и адаптируется к будущим изменениям в медицинской практике.
Автоматизированная оценка моделей искусственного интеллекта, осуществляемая посредством использования больших языковых моделей (LLM) в роли судьи, представляет собой перспективный путь для повышения эффективности и масштабируемости тестирования. Однако, полагаться исключительно на LLM-as-a-Judge не представляется возможным без тщательного анализа и сопоставления с экспертной оценкой специалистов. Существует риск воспроизведения и усиления существующих предвзятостей, заложенных в обучающих данных языковой модели, что может привести к ошибочным результатам и негативно повлиять на качество медицинской диагностики и лечения. Поэтому, интеграция автоматизированной оценки с человеческим контролем является необходимым условием для обеспечения надежности и справедливости при оценке потенциала искусственного интеллекта в сфере здравоохранения.
Представленная работа создает надежный и исключающий утечки данных эталон для оценки искусственного интеллекта в медицине, что открывает перспективы для разработки систем, способных не просто имитировать, но и расширять возможности клинического мышления. Этот строгий подход к тестированию позволяет создавать алгоритмы, которые могут помогать врачам в диагностике и лечении, повышая качество медицинской помощи и ускоряя темпы научных открытий. Благодаря такому эталону, исследователи получают возможность более эффективно оценивать прогресс в области медицинского ИИ, выявлять слабые места и создавать более надежные и полезные инструменты для улучшения здоровья пациентов и развития медицинской науки в целом.
Представленная работа демонстрирует стремление к редукции сложности в оценке медицинских больших языковых моделей. Авторы осознанно отказались от статических наборов данных, подверженных загрязнению, и предложили динамический, непрерывно обновляемый бенчмарк LiveMedBench. Этот подход позволяет оценить не только текущие знания модели, но и её способность к адаптации и клиническому мышлению. Как заметил Анри Пуанкаре: «Наука не состоит из ряда истин, а из методов их открытия». LiveMedBench, с его автоматизированной рубрикой оценки, представляет собой не просто набор вопросов, а именно метод проверки и совершенствования медицинских ИИ-систем, фокусируясь на процессе, а не только на результате.
Что дальше?
Представленная работа, несомненно, снижает уровень шума в оценке медицинских языковых моделей. Однако, избавление от одного изъяна лишь обнажает другие. Автоматизированная оценка, основанная на рубриках, — это, в лучшем случае, приближение к истине, упрощение сложной клинической задачи до набора проверяемых признаков. Иллюзия объективности, порождаемая алгоритмом, не должна затмевать фундаментальную субъективность медицинской практики.
Настоящая сложность заключается не в создании более обширных наборов данных или более изощренных метрик, а в признании границ применимости этих моделей. Необходим переход от оценки «знаний» к оценке способности к разумному сомнению, к умению признавать неопределенность — качествам, столь важным для настоящего врача, но чуждым текущему поколению алгоритмов. Попытка «закодировать» клиническое мышление — занятие тщеславное, ибо сама суть этого процесса заключается в постоянном пересмотре и адаптации.
Будущие исследования должны быть направлены не на увеличение объема, а на уменьшение избыточности. Простота — не ограничение, а доказательство понимания. Следует сосредоточиться на создании минимальных, но репрезентативных наборов задач, позволяющих выявить фундаментальные недостатки в рассуждениях моделей, а не просто измерять их способность к запоминанию. И, возможно, тогда мы сможем приблизиться к созданию не просто «умных» алгоритмов, а действительно полезных инструментов для поддержки принятия решений в медицине.
Оригинал статьи: https://arxiv.org/pdf/2602.10367.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- Искусственный интеллект и закон: гармония неизбежна
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Квантовые вычисления для молекул: оптимизация ресурсов
- Молекулярный интеллект: проверка химического мышления
- Квантовая обработка сигналов: новый подход к умножению и свертке
- Повышение точности AI-детекторов MIMO: новый подход к снижению неопределенности
- Искусство видеть: Как нейросети распознают стили в живописи?
- Документы под контролем: извлечение данных нового поколения
- Спектральная триада: Новая связь между запутанностью, петлями Вильсона и топологическими свойствами
2026-02-13 03:14