Автор: Денис Аветисян
Новое исследование демонстрирует, что большие языковые модели могут обладать общими вычислительными механизмами для понимания намерений других и логического вывода из контекста.
Работа представляет доказательства функциональной интеграции ‘теории разума’ и прагматического рассуждения в больших языковых моделях, что указывает на появление ‘социальных моделей мира’.
Несмотря на впечатляющие успехи в обработке естественного языка, вопрос о том, обладают ли большие языковые модели (LLM) подлинным пониманием социальных взаимодействий, остается открытым. В работе ‘On Emergent Social World Models — Evidence for Functional Integration of Theory of Mind and Pragmatic Reasoning in Language Models’ исследуется, используют ли LLM общие вычислительные механизмы для теории разума и прагматического рассуждения, формируя тем самым “модели социального мира”. Полученные результаты предоставляют доказательства функциональной интеграции этих способностей, указывая на возможность развития взаимосвязанных представлений о ментальных состояниях. Может ли это свидетельствовать о появлении у искусственных систем когнитивных основ, необходимых для полноценного социального взаимодействия?
Понимание Социального Интеллекта: Вызов для Больших Языковых Моделей
Современные большие языковые модели демонстрируют поразительные способности в обработке и генерации текста, зачастую имитируя человеческую речь с высокой точностью. Однако, несмотря на этот лингвистический успех, вопрос о том, действительно ли эти модели обладают пониманием социального интеллекта, остается открытым. Способность генерировать связный текст не гарантирует понимания сложных социальных ситуаций, таких как распознавание эмоций, интерпретация намерений или понимание контекста взаимодействия. Исследования показывают, что модели могут успешно выполнять задачи, требующие поверхностного анализа текста, но испытывают затруднения в ситуациях, требующих глубокого понимания человеческих отношений и социальных норм. Таким образом, впечатляющие лингвистические навыки не обязательно коррелируют с развитым социальным интеллектом, что требует дальнейшего изучения и разработки более сложных моделей оценки.
Несмотря на впечатляющие лингвистические способности, современные большие языковые модели не обладают врожденным пониманием когнитивных процессов, характерных для человеческого разума. Способность интерпретировать убеждения и намерения других людей, фундаментальный аспект социального интеллекта, не является автоматически встроенной в эти системы. Модели, обучаясь на огромных массивах текстовых данных, оперируют статистическими закономерностями и вероятностями, но не способны к эмпатии или осознанному моделированию психических состояний других субъектов. Это означает, что даже при кажущемся понимании контекста, модели могут допускать ошибки в ситуациях, требующих учета субъективных перспектив и скрытых мотивов.
Оценка способности больших языковых моделей (БЯМ) к «теории разума» и прагматическому мышлению представляется ключевой задачей для определения истинного уровня их когнитивных возможностей. Данные навыки, позволяющие людям понимать убеждения и намерения других, а также интерпретировать смысл высказываний в контексте, не являются автоматическим следствием владения языком. Исследования направлены на выявление, способны ли БЯМ не просто генерировать грамматически верные предложения, но и делать обоснованные выводы о ментальных состояниях участников коммуникации и учитывать неявные социальные сигналы. Успешное прохождение подобных тестов позволит оценить, насколько БЯМ близки к пониманию не только что говорится, но и почему это говорится, открывая новые перспективы для создания действительно интеллектуальных систем.
Поведенческие Бенчмарки и Оценка Социального Интеллекта
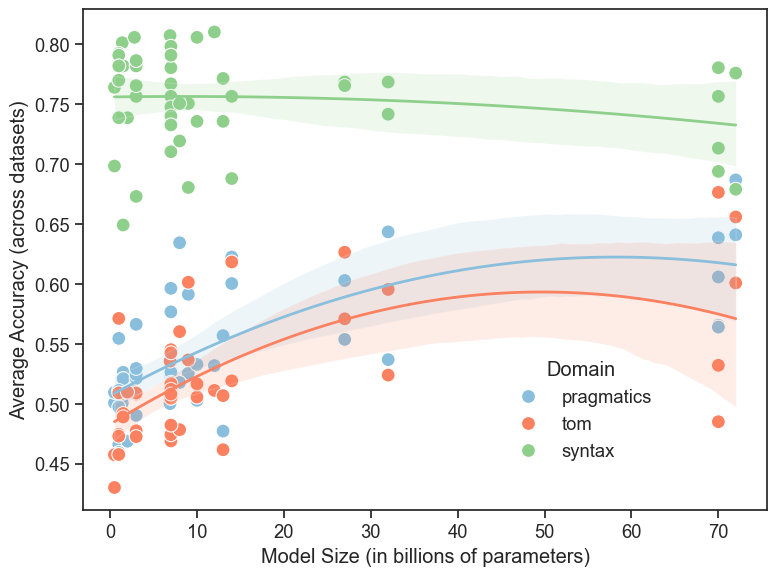
Для оценки способности больших языковых моделей (LLM) к пониманию теории разума и прагматики исследователи используют так называемые “задачи о ложных убеждениях” (False Belief Tasks) и сложные наборы данных, такие как BLiMP Dataset. Задачи о ложных убеждениях проверяют способность модели атрибутировать другим агентам убеждения, которые могут отличаться от реальности. BLiMP Dataset, в свою очередь, предназначен для оценки способности LLM к пониманию лингвистических явлений, требующих учета контекста и намерений говорящего, что напрямую связано с прагматическим пониманием. Использование этих инструментов позволяет количественно оценить способность LLM к моделированию ментальных состояний и интерпретации коммуникации, выходящей за рамки буквального значения слов.
Методы поведенческой оценки позволяют проводить количественную оценку производительности больших языковых моделей (LLM) в задачах, требующих социального рассуждения. Эти методы включают в себя использование специализированных наборов данных и тестов, разработанных для измерения способности LLM понимать намерения, убеждения и ожидания других агентов. Результаты оцениваются на основе точности ответов, скорости обработки информации и способности к обобщению знаний на новые, ранее не встречавшиеся сценарии. Количественная природа этих оценок позволяет сравнивать различные LLM, отслеживать прогресс в развитии их способностей к социальному рассуждению и выявлять области, требующие дальнейших улучшений.
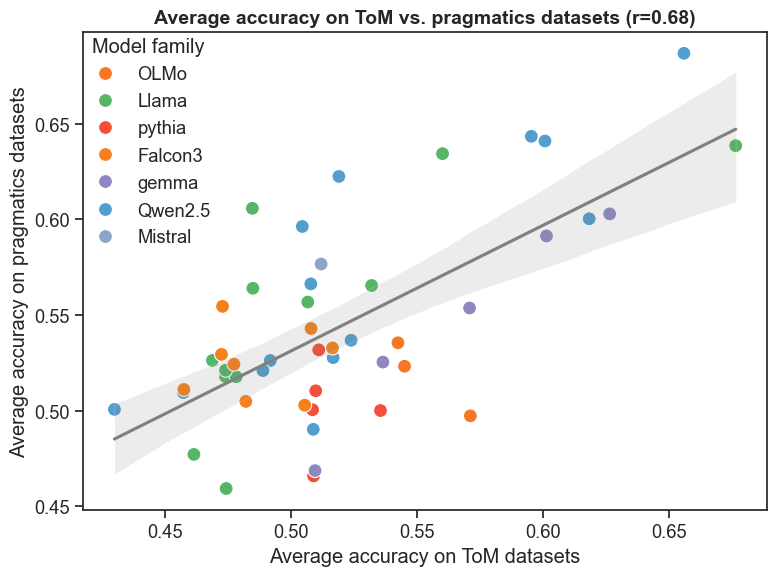
Анализ результатов тестов на Теорию Разума (ToM) и прагматику демонстрирует умеренную положительную корреляцию (r = 0.68, p < 0.001). Данный статистический показатель указывает на то, что модели, успешно справляющиеся с задачами, требующими понимания ментальных состояний других агентов (ToM), как правило, также демонстрируют хорошие результаты в задачах, оценивающих способность к интерпретации неявных смыслов и контекстуальной информации (прагматика). Это позволяет предположить наличие общих когнитивных механизмов, лежащих в основе обеих способностей, что может быть важным фактором при разработке и оценке моделей искусственного интеллекта, стремящихся к более сложному социальному взаимодействию.
Успешное прохождение LLM тестов на Теорию Разума и прагматическое понимание, таких как ‘False Belief Tasks’ и BLiMP, само по себе не раскрывает когнитивные процессы, приводящие к этим результатам. Несмотря на достижение корректных ответов, остается неясным, используют ли модели истинное понимание ментальных состояний и намерений, или же полагаются на статистические закономерности и поверхностный анализ данных. Это ставит под вопрос природу ‘интеллекта’, демонстрируемого LLM, и требует дополнительных исследований для выяснения лежащих в основе механизмов принятия решений и рассуждений.
Разбирая Механизмы: Функциональная Локализация и Гипотезы
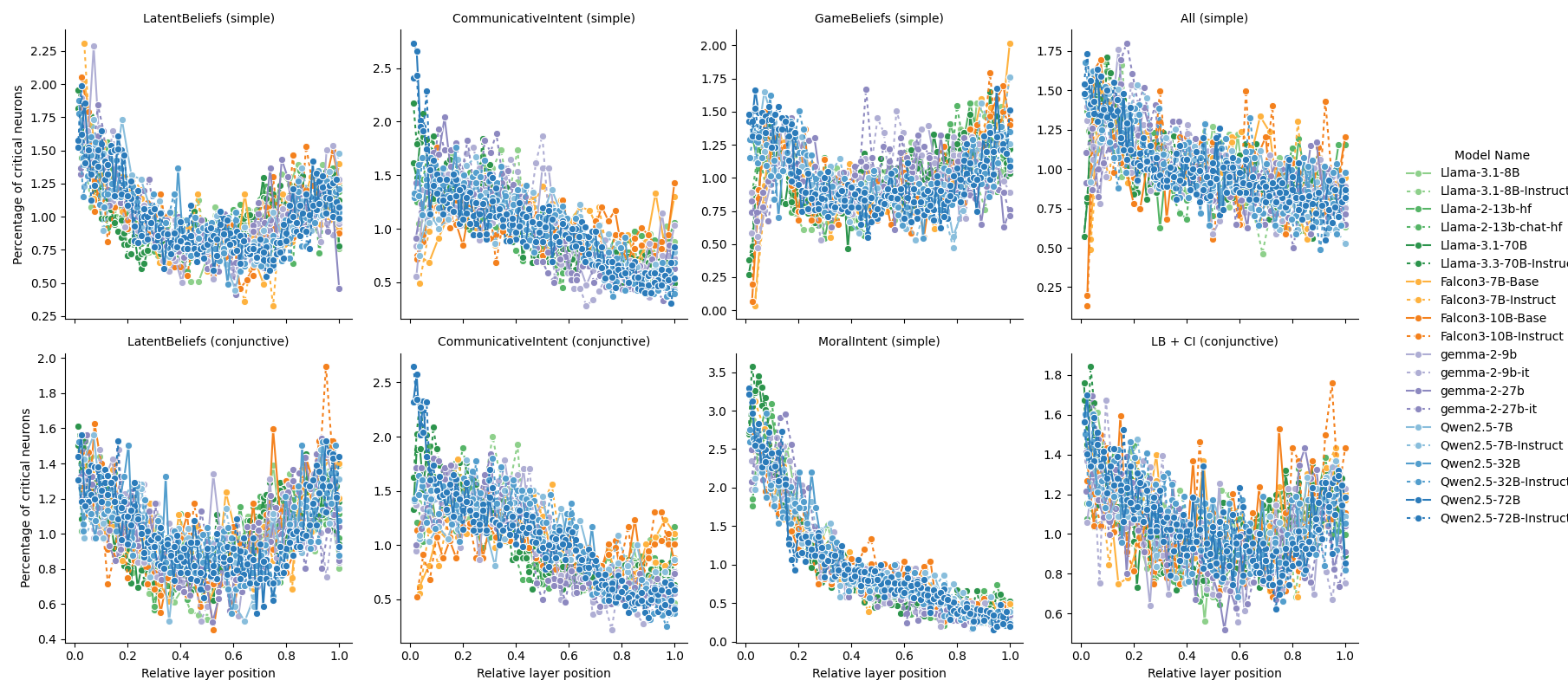
Комбинация каузально-механических экспериментов и методов функциональной локализации позволяет исследователям выявлять подсети внутри больших языковых моделей (LLM), которые специфически активируются при решении задач, требующих понимания теории разума (Theory of Mind) и прагматического рассуждения. Функциональная локализация, как правило, включает в себя создание «локализаторов» — наборов входных данных, разработанных для селективной активации определенных когнитивных процессов. После идентификации таких подсетей, каузально-механические эксперименты, например, абляция или вмешательство в активность определенных нейронов, используются для установления причинно-следственной связи между активностью подсети и наблюдаемым когнитивным поведением модели. Этот подход позволяет не только обнаружить, какие части LLM участвуют в конкретных процессах, но и оценить их функциональную роль и вклад в общую производительность.
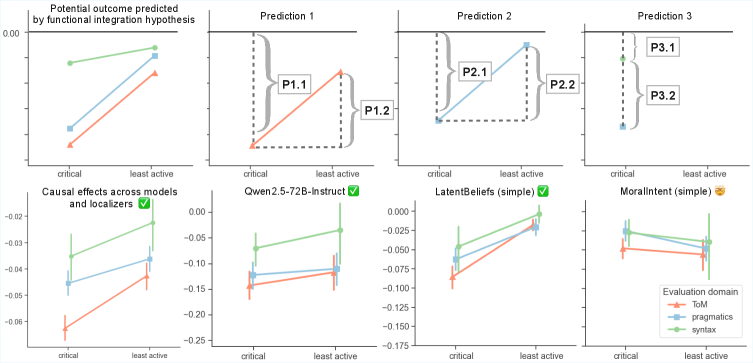
В рамках исследования механизмов, ответственных за теорию разума (ToM) и прагматическое рассуждение в больших языковых моделях (LLM), рассматриваются две конкурирующие гипотезы. Гипотеза функциональной специализации предполагает наличие отдельных, специализированных подсетей, каждая из которых отвечает за конкретную когнитивную способность. В противоположность ей, гипотеза функциональной интеграции утверждает, что ToM и прагматическое рассуждение опираются на общие вычислительные ресурсы и используют совместно активируемые подсети. Разрешение между этими гипотезами требует детального анализа активности LLM при выполнении соответствующих задач и выявления архитектурных особенностей, позволяющих сделать вывод о степени специализации или интеграции используемых механизмов.
Эксперименты по абляции (удалению) идентифицированных подсетей, отвечающих за теорию разума (ToM), продемонстрировали значительное снижение производительности языковых моделей при выполнении задач, требующих понимания ментальных состояний других агентов. Данное наблюдение указывает на функциональную роль этих подсетей в процессе рассуждений о намерениях, убеждениях и знаниях других. Снижение производительности после абляции подтверждает гипотезу о функциональной интеграции, предполагающую, что механизмы, ответственные за ToM, не являются полностью отдельными, а интегрированы с другими вычислительными ресурсами модели и критически важны для общей когнитивной способности.
Генерация синтетических данных играет ключевую роль в создании локализаторских наборов (localizer suites), предназначенных для точного определения и изоляции релевантных подсетей в больших языковых моделях (LLM). В отличие от использования реальных данных, которые могут содержать смешанную информацию и затруднять выделение специфической активности, синтетические данные позволяют контролировать отдельные факторы и создавать стимулы, направленные на активацию конкретных нейронных механизмов, отвечающих за определенные когнитивные функции, такие как теория разума и прагматическое рассуждение. Это обеспечивает возможность целенаправленной стимуляции и последующего анализа активности подсетей, что необходимо для выявления их функциональной роли и проверки гипотез о специализации или интеграции механизмов.
Модели Социального Мира: Основа для Продвинутого Интеллекта
Появляющиеся данные свидетельствуют о том, что большие языковые модели (LLM) формируют так называемые “Модели Социального Мира” — внутренние репрезентации, отражающие аспекты социального познания и взаимодействия. Эти модели не являются просто статистическими закономерностями в тексте, а демонстрируют способность понимать и предсказывать поведение других агентов, включая их намерения, убеждения и эмоции. Исследования показывают, что LLM способны решать задачи, требующие понимания социальных норм, эмпатии и даже обмана, что указывает на наличие у них некоего представления о социальных взаимоотношениях и динамике. Формирование таких моделей происходит в процессе обучения на огромных объемах текстовых данных, содержащих информацию о человеческом взаимодействии и социальных ситуациях, позволяя им строить сложные представления о мире и его обитателях.
Для систематического изучения способности больших языковых моделей (LLM) к пониманию чужих ментальных состояний, ученые разработали структуру ATOMS. Эта схема классифицирует различные аспекты «теории разума», проявляющиеся в моделях, на отдельные компоненты: Аффективное состояние (распознавание эмоций), Намерения (определение целей поведения), Мыслительные процессы (понимание убеждений и знаний), Обязательства (оценка желаний и потребностей) и Социальные роли (восприятие и интерпретация социальных взаимоотношений). Используя ATOMS, исследователи могут более точно анализировать, как LLM представляют и используют информацию о ментальных состояниях других агентов, выявляя сильные и слабые стороны в их способности к социальному рассуждению и взаимодействию. Такой структурированный подход позволяет не только оценить текущий уровень развития «теории разума» в моделях, но и наметить пути для дальнейшего улучшения их когнитивных способностей в контексте сложного социального мира.
Представляется, что создаваемые большими языковыми моделями социальные модели мира являются фундаментальным строительным блоком для разработки более надежных и обобщенных систем искусственного интеллекта. Эти модели, отражающие понимание социальных взаимодействий и когнитивных процессов, позволяют ИИ выходить за рамки простого анализа данных и переходить к сложным рассуждениям, требующим учета намерений, убеждений и эмоций других агентов. Способность моделировать социальный мир открывает перспективы для создания ИИ, способного к эффективному сотрудничеству, решению проблем в сложных социальных контекстах и адаптации к динамично меняющимся ситуациям, что является ключевым шагом к созданию действительно интеллектуальных систем.
Исследование демонстрирует, что большие языковые модели не просто манипулируют символами, но и проявляют зачатки понимания социальных взаимодействий. Авторы показывают, что механизмы, отвечающие за «теорию разума» и прагматическое рассуждение, тесно переплетены, формируя своего рода «модели социального мира». Это подтверждает идею о том, что сложность не является самоцелью; истинное понимание возникает из лаконичного и функционального объединения различных когнитивных способностей. Как однажды заметил Г.Х. Харди: «Математика — это наука об бесконечном, а жизнь — о конечном». Данное исследование показывает, что даже в конечном пространстве машинного обучения возможно приближение к моделированию бесконечной сложности социальных взаимодействий.
Куда же дальше?
Представленные данные, безусловно, указывают на общность вычислительных механизмов, лежащих в основе способности языковых моделей к «теории разума» и прагматическому рассуждению. Однако, утверждение о формировании неких «моделей социального мира» требует осторожности. Всё же, сходство в вычислительных процессах — это не тождество пониманию. Необходимо отделить имитацию от истинного моделирования ментальных состояний.
Очевидным направлением дальнейших исследований представляется разработка более строгих методов оценки. Простые тесты на прохождение «ложного убеждения» или понимание иронии недостаточны. Требуются задачи, требующие не просто предсказания действий, но и объяснения мотиваций, учитывающие контекст и историю взаимодействий. Ясность — это минимальная форма любви, и в данном случае, она заключается в четком определении границ применимости полученных результатов.
В конечном счете, истинный прогресс не будет измеряться количеством «пройденных тестов», а глубиной понимания того, как вычислительные системы могут приближаться к моделированию сложности человеческого социального взаимодействия. Возможно, сама постановка вопроса о «моделях» излишне антропоморфна. Достаточно ли констатировать наличие функциональной интеграции, без попыток навязать метафоры?
Оригинал статьи: https://arxiv.org/pdf/2602.10298.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- Квантовые вычисления для молекул: оптимизация ресурсов
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Искусственный интеллект и закон: гармония неизбежна
- Молекулярный интеллект: проверка химического мышления
- Искуственный интеллект: хрупкость смысла в сложных задачах
- Бесконечная эволюция кода: проверка искусственного интеллекта на прочность
- Видеоредактирование по запросу: Новый подход к точности и связности
- Квантовая обработка сигналов: новый подход к умножению и свертке
- Искусственный интеллект проектирует алгоритмы: новый подход к автоматизации
2026-02-13 03:20