Автор: Денис Аветисян
Новая модель Voxtral Realtime обеспечивает транскрипцию речи в реальном времени с минимальной задержкой, не уступая по качеству офлайн-решениям.
Voxtral Realtime — это нативный потоковый ASR-модель, использующая каузальный энкодер, адаптивную нормализацию задержки и оптимизированные методы обучения для достижения субсекундной задержки.
Достижение качества оффлайн-транскрипции в режиме реального времени остаётся сложной задачей для систем автоматического распознавания речи. В данной работе представляется ‘Voxtral Realtime’, потоковая модель ASR, разработанная для обеспечения производительности, сопоставимой с оффлайн-системами, при задержке менее секунды. Ключевым отличием является обучение модели «с нуля» для потоковой обработки, с использованием каузального кодировщика и адаптивной нормализации RMS для улучшения устойчивости к задержкам. Сможет ли этот подход открыть новые возможности для применения ASR в задачах, требующих мгновенной реакции и обработки речи в реальном времени?
Вызов реального времени: преодоление ограничений традиционных систем
Традиционные системы автоматического распознавания речи (ASR), несмотря на свою высокую точность, зачастую требуют наличия полной аудиозаписи для проведения анализа. Этот принцип работы создает существенные трудности при реализации приложений, требующих обработки речи в реальном времени. В отличие от обработки завершенного аудиофайла, где алгоритмы могут анализировать контекст всей фразы или даже всего диалога, системы, работающие с потоковым аудио, вынуждены принимать решения на основе лишь частично полученной информации. Это приводит к увеличению количества ошибок и снижению общей надежности транскрипции, особенно в условиях шума или при быстром темпе речи. В результате, применение классических ASR-систем в задачах, таких как создание субтитров в прямом эфире или обеспечение мгновенного перевода, оказывается затруднительным и требует разработки специализированных подходов к обработке потокового аудио.
Растущий спрос на транскрипцию с минимальной задержкой обусловлен расширением областей применения, где оперативность обработки речи критически важна. В частности, системы автоматического создания субтитров в реальном времени становятся все более востребованными для обеспечения доступности контента и улучшения восприятия видеоматериалов. Виртуальные помощники и голосовые ассистенты также нуждаются в мгновенной расшифровке речи для обеспечения естественного и эффективного взаимодействия с пользователями. Кроме того, в приложениях для организации видеоконференций и онлайн-коммуникации, быстрая транскрипция позволяет оперативно создавать протоколы встреч и обеспечивать возможность поиска по голосовым записям, значительно повышая продуктивность и эффективность работы.
Существующие API для транскрипции в режиме реального времени сталкиваются со значительными трудностями в достижении качества, сравнимого с системами, обрабатывающими предварительно записанный аудиоматериал. Это несоответствие обусловлено необходимостью мгновенного анализа и преобразования звукового сигнала, что неизбежно приводит к упрощению алгоритмов и, как следствие, к увеличению числа ошибок. В то время как оффлайн-системы могут использовать более сложные модели и контекстный анализ для повышения точности, API реального времени вынуждены идти на компромисс между скоростью и качеством, создавая ощутимый разрыв в эффективности и требуя дальнейших исследований в области оптимизации алгоритмов и аппаратного обеспечения для достижения приемлемого уровня производительности.
![Архитектура Voxtral Realtime обеспечивает декодирование аудио в текст с целевой задержкой 80 мс, используя причинный аудиоэнкодер, адаптер для понижения частоты дискретизации и авторегрессивный текстовый декодер, который суммирует пониженные аудиовстраивания и встраивания ранее сгенерированных токенов с частотой 12,5 Гц, генерируя токены с задержкой до появления акустически завершенного слова, обозначенного токеном границы слова [W].](https://arxiv.org/html/2602.11298v1/figures/streaming.004.jpeg)
Voxtral Realtime: новая архитектура для потоковой обработки речи
Voxtral Realtime представляет собой архитектуру автоматического распознавания речи (ASR), разработанную для потоковой обработки аудио и транскрипции в реальном времени. В отличие от традиционных моделей, требующих полной загрузки аудиофайла перед обработкой, Voxtral Realtime обрабатывает аудио последовательно, по мере его поступления. Это позволяет значительно снизить задержку транскрипции, что критически важно для приложений, требующих мгновенного ответа, таких как субтитры в реальном времени, голосовые помощники и трансляции. Модель оптимизирована для минимальной задержки, сохраняя при этом высокую точность распознавания речи.
В основе архитектуры Voxtral Realtime лежит каузальный аудиоэнкодер, обрабатывающий аудиопоток последовательно, что позволяет минимизировать вычислительные затраты. В отличие от традиционных энкодеров, требующих полной загрузки аудиофрагмента перед обработкой, каузальный энкодер обрабатывает данные по мере их поступления. Это существенно снижает задержку и потребление памяти, что критически важно для задач потоковой транскрипции в реальном времени. Последовательная обработка также позволяет модели адаптироваться к изменяющимся акустическим условиям в процессе потоковой передачи.
В основе Voxtral Realtime лежит архитектура Transformer, обеспечивающая высокую производительность при обработке последовательных аудиоданных. Для эффективного управления контекстом в условиях потоковой обработки используется механизм Sliding Window Attention. Данный подход ограничивает область внимания модели определенным временным окном, что снижает вычислительную сложность и задержку по сравнению с полным вниманием (full attention), сохраняя при этом возможность улавливать важные зависимости в аудиопотоке. Это позволяет модели обрабатывать длинные последовательности аудио с минимальной задержкой, что критически важно для приложений реального времени.
В архитектуре Voxtral Realtime для управления задержкой используется адаптивная нормализация RMS (Root Mean Square). Этот метод позволяет задавать целевую задержку (Target Delay) в процессе обучения модели. Адаптивная RMS-Norm динамически масштабирует и смещает активации нейронной сети, учитывая заданный параметр задержки. Это обеспечивает оптимизацию модели для работы с конкретным уровнем задержки, необходимым для приложений реального времени, таких как транскрипция в реальном времени или голосовые помощники. Использование RMS-Norm вместо других методов нормализации обеспечивает стабильность обучения и более эффективное управление задержкой без значительного увеличения вычислительной сложности.

Под капотом: оптимизации для скорости и точности
Архитектура Voxtral Realtime, основанная на Transformer, использует механизмы SwiGLU (Switched GLU) для повышения эффективности обработки данных. SwiGLU представляет собой функцию активации, которая обеспечивает более селективное пропускание информации по сравнению с традиционными функциями, такими как ReLU, что способствует улучшению производительности модели. В дополнение, в архитектуре реализованы RoPE (Rotary Positional Embeddings) — метод кодирования позиционной информации, который эффективно обрабатывает длинные последовательности и обеспечивает лучшую обобщающую способность модели по сравнению с абсолютными или относительными позиционными вложениями. Сочетание SwiGLU и RoPE позволяет Voxtral Realtime достигать высокой скорости и точности при распознавании речи.
В качестве входных данных модель Voxtral Realtime использует логарифмический мел-спектрограмму (Log-Mel Spectrogram), представляющую собой стандартное представление аудиосигнала для систем автоматического распознавания речи (ASR). Логарифмическое преобразование позволяет снизить динамический диапазон спектральных компонентов, что улучшает устойчивость модели к шумам и вариациям громкости. Мел-спектрограмма, полученная путем применения мел-фильтров к спектру сигнала, приближает восприятие звука к человеческому слуху. Использование Log-Mel Spectrogram в качестве входных данных обеспечивает совместимость с большинством современных ASR пайплайнов и позволяет эффективно извлекать релевантную информацию из аудиосигнала для последующего анализа и транскрипции.
Voxtral Realtime достигает передовых результатов в области автоматического распознавания речи за счет использования и развития устоявшихся методов, таких как Neural Transducer (RNN-T) и Delayed Streams Modeling (DSM). RNN-T обеспечивает прямое отображение аудиопоследовательности в текстовую, обходя необходимость в выравнивании, что повышает эффективность. DSM дополнительно оптимизирует процесс, учитывая временные зависимости в аудиопотоке и позволяя модели прогнозировать будущие кадры, что снижает задержку и повышает точность транскрипции. Комбинация этих подходов позволяет Voxtral Realtime демонстрировать высокую производительность в задачах распознавания речи в реальном времени.
Оптимизированная обработка запросов в Voxtral Realtime обеспечивается за счет использования vLLM, фреймворка, реализующего оптимизированное кэширование ключей и значений (KV caching). Данная технология позволяет значительно снизить задержку и повысить пропускную способность за счет сохранения промежуточных результатов вычислений и повторного их использования. Кроме того, vLLM поддерживает потоковую обработку данных (streaming), что позволяет возвращать результаты распознавания по мере их готовности, не дожидаясь завершения обработки всего аудиосигнала. Такой подход существенно улучшает восприятие скорости работы системы, особенно в интерактивных приложениях.
Оценка и подтверждение: производительность на практике
Для объективной оценки возможностей системы Voxtral Realtime применялся комплексный бенчмарк FLEURS, представляющий собой многоязычный набор данных, специально разработанный для тестирования систем автоматического распознавания речи (ASR). Этот бенчмарк позволяет всесторонне проверить точность и надежность модели в условиях работы с различными языками и акцентами. Использование FLEURS гарантирует, что оценка производительности Voxtral Realtime производится в стандартизированной и воспроизводимой среде, что обеспечивает достоверность результатов и позволяет сравнивать ее с другими передовыми решениями в области ASR. Особенностью FLEURS является его способность выявлять слабые места модели в обработке конкретных языковых особенностей, что, в свою очередь, способствует ее дальнейшей оптимизации и улучшению качества распознавания.
Обучение модели Voxtral Realtime на обширных, общедоступных наборах данных, таких как Mozilla Common Voice, значительно повысило её устойчивость и способность к обобщению. Использование этих ресурсов позволило модели познакомиться с широким спектром акцентов, стилей речи и акустических условий, что критически важно для надежной работы в реальных сценариях. Такой подход к обучению не только увеличивает точность распознавания речи в целом, но и позволяет модели эффективно адаптироваться к новым, ранее не встречавшимся данным, обеспечивая стабильно высокие результаты даже в сложных акустических условиях и при работе с разными говорящими.
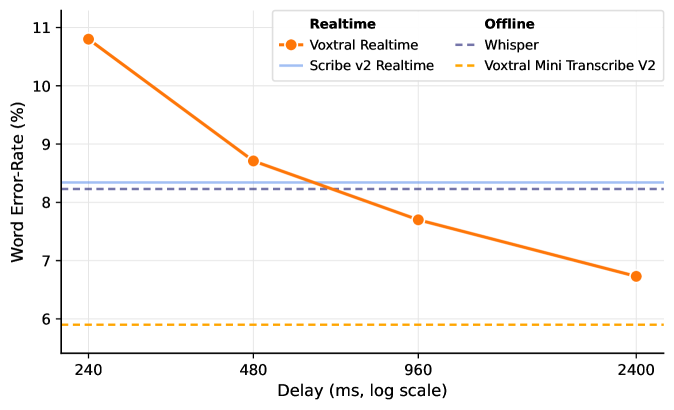
Исследования показали, что Voxtral Realtime демонстрирует сопоставимую производительность с ведущими API для распознавания речи в режиме реального времени, такими как Scribe v2 Realtime и Whisper. В частности, при задержке в 960 миллисекунд, модель достигает показателя Word Error Rate (WER) менее 5%, что превосходит результаты конкурентов при аналогичных условиях. Это свидетельствует о высокой точности и эффективности Voxtral Realtime в задачах транскрибации, обеспечивая надежное преобразование речи в текст даже при относительно небольших задержках, что особенно важно для интерактивных приложений и систем, требующих мгновенной реакции.
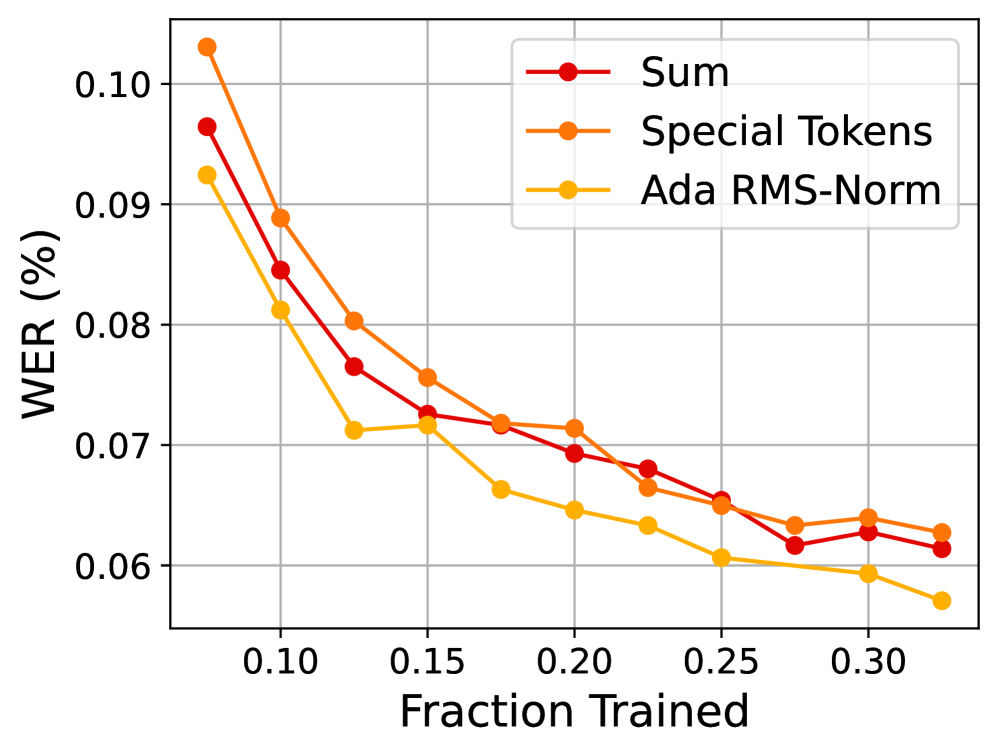
Внедрение токенов, обозначающих границы слов, значительно повышает точность транскрипции в системе Voxtral Realtime. Этот подход позволяет модели более эффективно различать отдельные слова, особенно в сложных акустических условиях или при наличии неоднозначных произношений. Благодаря этому улучшается распознавание речи, снижается количество ошибок и, как следствие, повышается общее качество пользовательского опыта. Более точная транскрипция упрощает последующую обработку текста, будь то создание заметок, расшифровка аудиозаписей или управление голосовыми командами, что делает взаимодействие с системой более плавным и интуитивно понятным для пользователя.
Система Voxtral Realtime демонстрирует впечатляющую производительность, достигая качества транскрипции, сопоставимого с оффлайн-решениями, при задержке менее секунды. В ходе сравнительных тестов, используя метрику Word Error Rate (WER), Voxtral Realtime показала конкурентоспособные результаты с лидирующими API реального времени, такими как Scribe v2 Realtime и Whisper, при задержке в 480 миллисекунд. При увеличении задержки до 960 миллисекунд, Voxtral Realtime превзошла этих конкурентов, что свидетельствует о ее эффективности и способности обеспечивать точную и быструю транскрипцию в режиме реального времени. Такая производительность делает систему особенно привлекательной для приложений, требующих мгновенной обработки речи, таких как видеоконференции, диктовка и создание субтитров.
![Эксперименты на наборе данных FLEURS показали, что использование единого токена границы слова <span class="katex-eq" data-katex-display="false">[W]</span> для каждой группы слов позволяет лучше сохранить возможности предварительно обученной языковой модели декодера по сравнению с использованием токена <span class="katex-eq" data-katex-display="false">[W]</span> для каждого слова.](https://arxiv.org/html/2602.11298v1/x7.png)
Исследование, представленное в данной работе, демонстрирует, что оптимизация архитектуры системы автоматического распознавания речи может привести к значительному снижению задержки без ущерба для качества транскрипции. Этот подход, фокусирующийся на адаптивном обучении и оптимизации отдельных компонентов, подтверждает идею о том, что структура определяет поведение системы. Как однажды заметил Бертран Рассел: «Всякое знание должно начинаться с сомнения». Именно критический анализ существующих решений и стремление к улучшению архитектуры позволяют создавать более эффективные и отзывчивые системы, такие как Voxtral Realtime, способные к транскрипции в реальном времени с минимальной задержкой.
Что Дальше?
Представленная работа демонстрирует, что достижение качества распознавания речи, сравнимого с офлайн-обработкой, в режиме реального времени — не пустая мечта, но и не окончательная победа. Низкая задержка — это лишь одна сторона медали. Необходимо помнить, что любая система, стремящаяся к имитации живого организма, неизбежно сталкивается с проблемой адаптации к непредсказуемости входящего сигнала. Шум, акценты, нечеткая дикция — все это требует дальнейшей проработки механизмов устойчивости и самообучения.
Важно признать, что упрощение архитектуры, достигнутое в Voxtral Realtime, не должно быть самоцелью. Иногда кажущаяся элегантность скрывает упущенные возможности. Поиск баланса между скоростью, точностью и робастностью — вот истинная задача. Будущие исследования должны быть направлены на разработку более эффективных методов обучения, позволяющих модели быстро адаптироваться к новым условиям, не жертвуя при этом качеством распознавания.
В конечном счете, вопрос не в том, насколько быстро мы можем преобразовать речь в текст, а в том, насколько хорошо мы понимаем саму природу языка и способность системы к истинному «пониманию» смысла. Стремление к совершенству в этой области требует не только технических инноваций, но и философского осмысления границ искусственного интеллекта.
Оригинал статьи: https://arxiv.org/pdf/2602.11298.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- Молекулярный интеллект: проверка химического мышления
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Квантовые вычисления для молекул: оптимизация ресурсов
- Искусственный интеллект и закон: гармония неизбежна
- Архитектура доверия: долгосрочное консультирование с адаптивной памятью.
- Математический интеллект: как улучшить навыки решения задач у больших языковых моделей
- Оптимизация 3D-печати: от хаоса к порядку
- Видео-рассуждения: готовы ли модели выйти за рамки лаборатории?
- Видеосинтез без тормозов: новый подход к генерации видео в реальном времени
2026-02-13 08:24