Автор: Денис Аветисян
Новый инструмент позволяет оценить, насколько хорошо языковые модели способны подтвердить результаты исследований в области социальных и поведенческих наук.
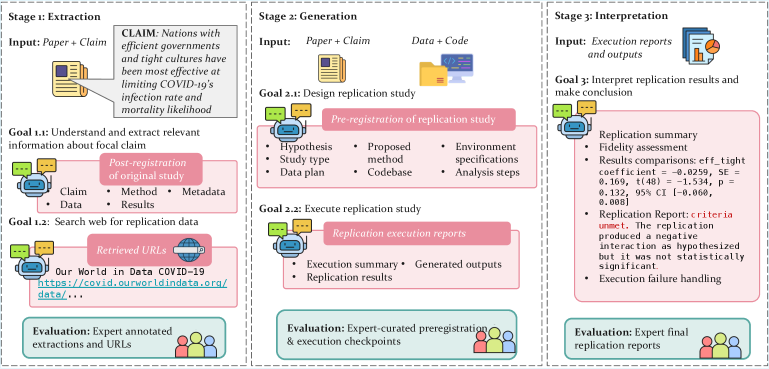
Представлен ReplicatorBench — эталон для оценки способности агентов на основе больших языковых моделей воспроизводить научные выводы, с акцентом на извлечение и интерпретацию данных.
Несмотря на растущий интерес к автоматизированной оценке научных работ с помощью ИИ-агентов, существующие бенчмарки фокусируются преимущественно на воспроизводимости результатов при наличии кода и данных. В данной работе, представленной в статье ‘ReplicatorBench: Benchmarking LLM Agents for Replicability in Social and Behavioral Sciences’, предложен новый бенчмарк ReplicatorBench, предназначенный для оценки возможностей LLM-агентов в области репликации исследований в социально-поведенческих науках, включая этапы извлечения данных, проведения экспериментов и интерпретации результатов. Полученные данные свидетельствуют о том, что современные агенты успешно справляются с проектированием и выполнением вычислений, но испытывают трудности с поиском новых данных, необходимых для репликации утверждений. Смогут ли будущие разработки в области ИИ-агентов преодолеть эти ограничения и обеспечить надежную проверку научных результатов?
Кризис воспроизводимости и автоматизация научных исследований
В современной науке все чаще отмечается проблема воспроизводимости результатов исследований, что вызывает серьезные опасения относительно достоверности накопленных знаний. Многие опубликованные работы, особенно в областях социальных и поведенческих наук, оказываются трудновоспроизводимыми при повторных попытках проверки, что ставит под вопрос их надежность и обоснованность. Это явление, получившее название «кризис воспроизводимости», подрывает доверие к научным публикациям и замедляет прогресс в соответствующих областях, поскольку требует дополнительных усилий для подтверждения или опровержения ранее полученных выводов. Неспособность подтвердить результаты может быть обусловлена различными факторами, включая методологические ошибки, предвзятость публикаций и недостаточную прозрачность исследований.
Попытки ручного воспроизведения научных результатов в области социальных и поведенческих наук часто оказываются чрезвычайно трудоемкими и затратными по времени. Каждое повторное исследование требует значительных человеческих ресурсов, включая время ученых, ассистентов и финансирование для сбора и анализа данных. Этот процесс не только замедляет темпы научного прогресса, но и ограничивает возможность всесторонней проверки существующих теорий и выводов. Особенно остро эта проблема проявляется при анализе сложных социальных явлений, требующих масштабных исследований и длительного наблюдения. В результате, ценные ресурсы тратятся не на новые открытия, а на подтверждение или опровержение уже опубликованных данных, что создает серьезное препятствие для развития науки.
Автоматизированное воспроизведение результатов исследований с использованием интеллектуальных агентов представляет собой масштабируемое решение для валидации и укрепления научной базы знаний. Данный подход позволяет значительно ускорить процесс проверки достоверности опубликованных данных, преодолевая ограничения, связанные с трудоемкостью и затратами ручного воспроизведения. В рамках проведенного исследования был разработан бенчмарк, включающий 1 568 проверяемых контрольных точек по 19 различным научным работам. Это позволило не только автоматизировать процесс проверки, но и выявить потенциальные ошибки или неточности в оригинальных исследованиях, способствуя повышению надежности и воспроизводимости научных результатов в социальных и поведенческих науках.
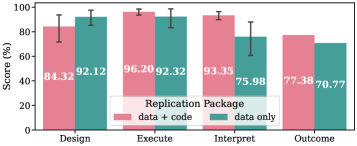
ReplicatorBench: Трехэтапная структура воспроизведения
ReplicatorBench использует трехэтапный процесс для систематической оценки способности агента воспроизводить научные утверждения. Этот процесс состоит из этапов Извлечения, Генерации и Интерпретации. На этапе Извлечения происходит сбор релевантной информации из оригинальной исследовательской работы и получение необходимых данных. Этап Генерации включает в себя настройку исполняемой среды и запуск кода, необходимого для воспроизведения результатов исследования. Наконец, этап Интерпретации предназначен для анализа полученных результатов и определения степени соответствия с исходными данными, что позволяет комплексно оценить надежность и воспроизводимость научных исследований.
Этап извлечения информации в ReplicatorBench направлен на сбор релевантных данных из оригинальной исследовательской работы и получение необходимых ресурсов для воспроизведения результатов. Оценка, полученная с использованием LLMEval, составила 66.57, что указывает на текущий уровень автоматизированного извлечения. Для сравнения, аннотаторы-люди достигли показателя в 72.14, демонстрируя превосходство человеческой оценки в точности извлечения информации из научных статей на данном этапе.
Этап генерации в ReplicatorBench включает в себя настройку исполняемой среды и запуск кода, необходимого для воспроизведения результатов исследования. Этот процесс требует создания рабочей среды, включающей установку необходимых зависимостей и библиотек, а также конфигурацию параметров, соответствующих оригинальному исследованию. После настройки среды, скрипты или программы, используемые в оригинальном исследовании, запускаются для получения результатов, которые затем сравниваются с заявленными в оригинальной публикации. Успешное выполнение этого этапа является критически важным для подтверждения воспроизводимости исследования и оценки способности агента к репликации научных результатов.
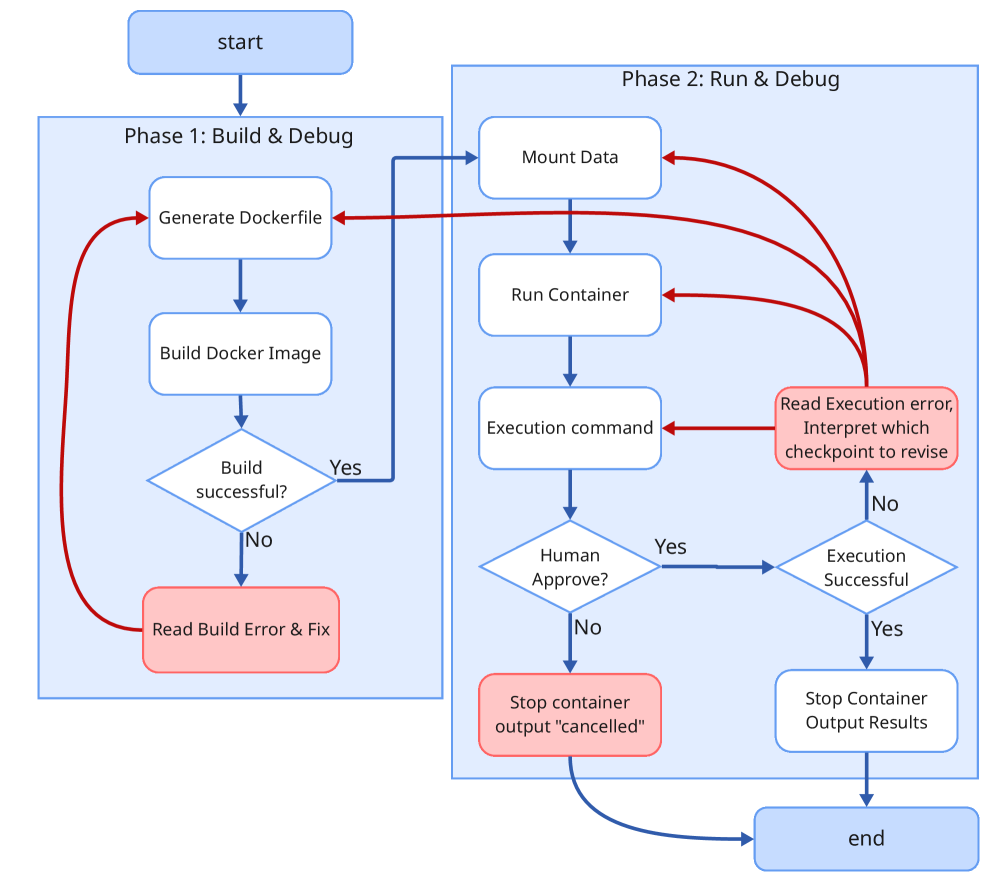
Преодоление языковых барьеров: Роль трансляции кода
Многие научные публикации содержат код, написанный на языках программирования, отличных от Python, что создает значительные препятствия для языковых моделей (LLM), в основном функционирующих в среде Python. Это связано с тем, что LLM, предназначенные для анализа и воспроизведения результатов исследований, не могут напрямую обрабатывать и выполнять код, представленный в других языках, таких как C++, Java или MATLAB. Необходимость обработки и преобразования такого ‘инородного’ кода в Python является критическим требованием для автоматизации процесса верификации и повторного использования научных результатов, представленных в этих публикациях.
Для обеспечения возможности выполнения и воспроизведения результатов, агентам необходимо обладать функциональностью перевода кода, написанного на языках, отличных от Python, в Python. Этот процесс, называемый трансляцией ‘Native Code’, позволяет интегрировать логику, реализованную на других языках программирования, в среду, ориентированную на Python. Эффективная трансляция требует не только синтаксического преобразования, но и сохранения семантической эквивалентности, чтобы обеспечить корректное функционирование переведенного кода и достоверность результатов, полученных при его исполнении. Возможность автоматической трансляции является ключевым фактором для расширения области применения LLM-агентов в задачах, требующих анализа и воспроизведения исследований, представленных на различных языках программирования.
В условиях “Data-Only Setting” агенты искусственного интеллекта сталкиваются с задачей воссоздания функционального кода исключительно на основе текстового описания исследования, без доступа к исходному коду, представленному в научной работе. Этот сценарий позволяет оценить пределы возможностей агента в понимании алгоритмов, представленных в текстовом виде, и их способности к самостоятельной реализации этих алгоритмов на языке Python. Отсутствие исходного кода исключает возможность прямого копирования или адаптации, требуя от агента глубокого анализа и интерпретации описания для генерации работоспособной реализации. Оценка производительности агента в “Data-Only Setting” предоставляет важные данные о его способности к решению задач, требующих не только обработки данных, но и самостоятельного программирования.
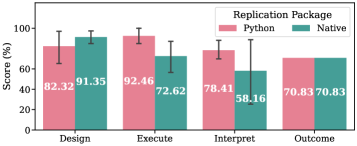
Валидация воспроизводимости: Интерпретация и сила LLM-агентов
На этапе интерпретации результатов, агенты обязаны проводить статистический анализ полученных данных для оценки успешности воспроизведения экспериментов. Этот анализ включает в себя расчет соответствующих статистических показателей, таких как p-value, доверительные интервалы и размеры эффекта, для определения степени согласованности между исходными и воспроизведенными результатами. Статистический анализ необходим для объективной оценки достоверности репликации и выявления возможных систематических ошибок или отклонений, позволяя отделить случайные колебания от значимых различий между результатами. Использование статистических методов позволяет агентам формировать обоснованные выводы о надежности воспроизведенных результатов и предоставляет количественную оценку степени успешности репликации.
Метод “LLM как судья” предоставляет возможность оценки производительности агентов и проверки точности воспроизведения результатов. В рамках данного подхода, большая языковая модель (LLM) используется для анализа результатов, полученных агентами при попытках репликации экспериментов, и определения степени соответствия между исходными и воспроизведенными данными. LLM оценивает как количественные показатели, так и качественные аспекты репликаций, позволяя выявить различия и неточности. Этот метод обеспечивает автоматизированную и объективную оценку, снижая зависимость от субъективных интерпретаций и повышая надежность процесса валидации реплицируемости.
Агентский фреймворк ‘ReplicatorAgent’ функционирует как базовая платформа, поддерживающая и оценивающая весь процесс ReplicatorBench. Его основная задача — воспроизведение научных результатов и оценка успешности этого воспроизведения. В ходе тестирования, ‘ReplicatorAgent’ достиг Macro F1 Score в 0.5476 при оценке результатов воспроизведения, что свидетельствует об умеренной эффективности в автоматизированном воспроизведении научных экспериментов и служит отправной точкой для дальнейшей оптимизации и сравнения с другими агентскими системами.
Перспективы масштабирования воспроизводимости с использованием продвинутых LLM
Ключевую роль в работе ReplicatorAgent и повышении его способности к воспроизведению результатов играют передовые языковые модели, такие как GPT-5, GPT-4o и o3. Исследования показывают, что GPT-5 демонстрирует значительное превосходство над GPT-4o, обеспечивая на 20% более высокую точность извлечения релевантной информации — показатель, известный как “recall”. Это означает, что при попытке воспроизвести научные результаты, GPT-5 способен более полно и корректно идентифицировать ключевые аспекты оригинального исследования, что, в свою очередь, существенно повышает надежность и эффективность процесса репликации.
Автоматизированное воспроизведение результатов исследований с помощью ReplicatorBench обладает потенциалом для существенного ускорения научного прогресса. Система способна не только выявлять наиболее надёжные и воспроизводимые научные открытия, но и эффективно помечать исследования, вызывающие сомнения в корректности или надёжности полученных данных. Такой подход позволяет отсеивать ложные или ошибочные результаты, тем самым повышая общую достоверность научного знания и способствуя более эффективному использованию ресурсов для дальнейших исследований. В перспективе, ReplicatorBench может стать незаменимым инструментом для проверки и валидации научных утверждений, стимулируя более ответственную и прозрачную научную практику.
Автоматизированное воспроизведение научных результатов, осуществляемое с помощью подобных систем, открывает перспективы для повышения достоверности и надежности научного знания. Традиционные методы проверки и подтверждения исследований часто ограничены ресурсами и субъективностью оценок. Внедрение систем, способных независимо воспроизводить эксперименты и анализировать данные, позволяет выявлять как устойчивые, воспроизводимые результаты, так и потенциально ошибочные или предвзятые исследования. Это, в свою очередь, способствует укреплению доверия к научным публикациям и формированию более объективной картины мира, основанной на подтвержденных данных и прозрачных методологиях. Повышение воспроизводимости, таким образом, становится ключевым фактором для развития науки и укрепления ее авторитета в обществе.
Исследование, представленное в данной работе, подчеркивает важность не только корректности кода, но и способности агентов, основанных на больших языковых моделях, к точному извлечению и интерпретации данных — ключевой аспект воспроизводимости в социальных и поведенческих науках. Это созвучно высказыванию Роберта Тарьяна: «Структура определяет поведение». ReplicatorBench, как новый инструмент оценки, выявляет сложности, возникающие при попытках воспроизведения научных утверждений, что требует от разработчиков систем учитывать целостность данных и контекст их использования. Недостаточно простого выполнения кода; необходимо понимание лежащей в основе структуры информации, чтобы гарантировать надежность и воспроизводимость результатов.
Куда же дальше?
Представленная работа, демонстрируя хрупкость воспроизводимости в социальных и поведенческих науках даже при использовании, казалось бы, всемогущих языковых моделей, лишь обнажает глубину проблемы. Очевидно, что способность агента выполнить код — лишь вершина айсберга. Настоящая сложность заключается в интерпретации данных, в понимании контекста, который, как показывает ReplicatorBench, часто ускользает даже от самых продвинутых систем. Как можно «пересадить сердце», не понимая всей системы кровообращения? Так и здесь: оценка агента по одной лишь способности выполнить инструкции — упрощение, которое игнорирует сложную сеть взаимосвязей между данными, методами и выводами.
Следующим шагом представляется не просто улучшение алгоритмов поиска данных, а создание моделей, способных к более глубокому пониманию предметной области. Необходимо двигаться от «вычислительной репликации» к «когнитивной репликации» — к способности агента не только повторить действия исследователя, но и понять почему эти действия были предприняты. Иначе, мы рискуем создать армию послушных, но бессмысленных исполнителей, которые воспроизводят ошибки с той же легкостью, что и правильные результаты.
Остается надеяться, что ReplicatorBench станет не просто инструментом оценки, но и катализатором для разработки новых, более осмысленных подходов к воспроизводимости в науке. Ведь элегантный дизайн рождается из простоты и ясности, а устойчивая система — из понимания целого, а не просто починки отдельных частей.
Оригинал статьи: https://arxiv.org/pdf/2602.11354.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- Квантовые вычисления для молекул: оптимизация ресурсов
- Молекулярный интеллект: проверка химического мышления
- Стиль сквозь века: математика искусства
- Искусственный интеллект и закон: гармония неизбежна
- Диалоги с Искусственным Интеллектом: Как Проверить Надежность?
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Оптимизация процессов: симбиоз классических и квантовых вычислений
- Квантовая устойчивость к ошибкам: новый взгляд на исправление вставок и удалений
- Освобождая потенциал мультимодальных моделей: метод развёртывания контекста
2026-02-13 11:39