Автор: Денис Аветисян
Исследователи разработали эффективный метод распределенного обучения больших языковых моделей, позволяющий значительно снизить требования к памяти и коммуникациям.
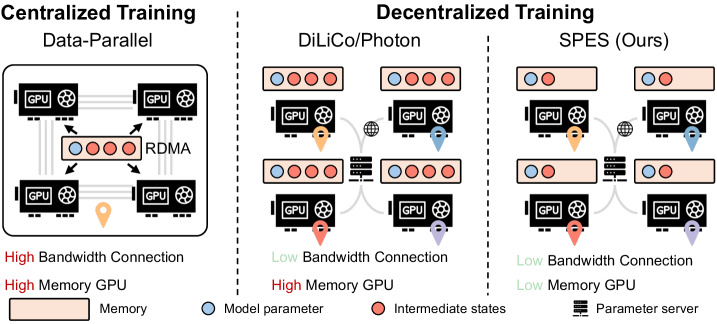
Предложена платформа SPES, использующая архитектуру Mixture of Experts и децентрализованный подход к обучению с разреженной синхронизацией.
Обучение больших языковых моделей (LLM) требует значительных вычислительных ресурсов, особенно в плане памяти GPU, что ограничивает возможности децентрализованного обучения. В работе, озаглавленной ‘Pretraining A Large Language Model using Distributed GPUs: A Memory-Efficient Decentralized Paradigm’, предлагается новый подход — SPES, децентрализованная платформа для обучения LLM на основе архитектуры Mixture of Experts, позволяющая снизить потребление памяти и коммуникационные издержки. SPES обучает лишь подмножество экспертов на каждом узле, периодически синхронизируя их, что обеспечивает эффективный обмен знаниями при ограниченных ресурсах. Может ли подобный подход стать основой для обучения действительно больших моделей, доступных для широкого круга исследователей и организаций?
Сложность как Препятствие: Масштабирование Больших Языковых Моделей
Современные большие языковые модели демонстрируют впечатляющую способность к обобщению, успешно применяясь к задачам, отличным от тех, на которых они обучались. Однако, дальнейшее увеличение их масштаба сталкивается со значительными вычислительными трудностями. По мере роста числа параметров модели, требуемые ресурсы для обучения и функционирования растут экспоненциально, что делает невозможным эффективное использование даже самых мощных вычислительных систем. Этот барьер ограничивает потенциал для захвата еще более сложных закономерностей в данных и создания моделей, способных к более глубокому пониманию и генерации текста. Исследователи активно ищут новые архитектуры и методы обучения, направленные на снижение вычислительных затрат и обеспечение возможности масштабирования больших языковых моделей без потери их эффективности и способности к обобщению.
Традиционные методы обновления плотных параметров в крупных языковых моделях сталкиваются с растущими трудностями по мере увеличения масштаба этих систем. По мере роста объемов данных и сложности задач, количество параметров, требующих обновления, экспоненциально увеличивается, что приводит к непрактичным вычислительным затратам и замедлению обучения. Это ограничивает способность моделей улавливать тонкие и сложные взаимосвязи в данных, поскольку оптимизация становится все более сложной и требует огромных ресурсов. В результате, модели могут достигать пределов своей способности к обобщению и адаптации к новым, ранее не встречавшимся данным, несмотря на все более крупные объемы обучающих данных и вычислительных мощностей, выделяемых на их обучение.
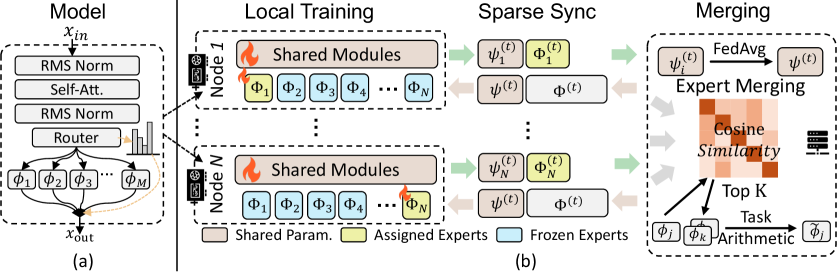
Архитектура Экспертов: Путь к Масштабируемости
Архитектура Mixture-of-Experts (MoE) расширяет возможности трансформаторов путем введения множества экспертных подсетей. В отличие от традиционных плотных моделей, MoE позволяет значительно увеличить емкость модели — количество параметров — без пропорционального увеличения вычислительных затрат во время инференса. Это достигается за счет маршрутизации каждого входного токена к подмножеству экспертов, активируя лишь небольшую часть всей модели для обработки конкретного запроса. Таким образом, общая вычислительная сложность остается управляемой, даже при значительном увеличении количества параметров, что делает MoE перспективным подходом для масштабирования моделей обработки естественного языка.
Для повышения производительности архитектур Mixture-of-Experts (MoE) применяются методы улучшения кодирования позиции и стабилизации обучения. В частности, вращающиеся позиционные вложения (RoPE) обеспечивают эффективное кодирование относительной позиции токенов, что особенно важно для длинных последовательностей. Нормализующие слои, такие как RMSNorm и QK-Norm, способствуют стабилизации процесса обучения за счет нормализации активаций и градиентов. RMSNorm использует скользящее среднее для оценки статистики нормализации, снижая вычислительные затраты, в то время как QK-Norm фокусируется на нормализации запросов и ключей в механизмах внимания, что позволяет улучшить стабильность и скорость сходимости модели. Эти методы совместно позволяют создавать более крупные и эффективные модели MoE, сохраняя при этом стабильность обучения и высокую производительность.
Эффективное обучение моделей типа Mixture-of-Experts (MoE) сопряжено с рядом сложностей, связанных с балансировкой нагрузки и накладными расходами на коммуникацию. Неравномерное распределение нагрузки между экспертами может привести к тому, что некоторые эксперты будут перегружены, в то время как другие будут простаивать, что снижает общую эффективность обучения. Высокие накладные расходы на коммуникацию возникают из-за необходимости обмена данными между экспертами и маршрутизатором, особенно в распределенных системах. Решение этих проблем требует применения специализированных техник, таких как вспомогательные потери для балансировки нагрузки и оптимизации коммуникационных стратегий, например, использование разреженной коммуникации или сжатия данных для уменьшения объема передаваемой информации.

Децентрализованное Обучение: Эффективность и Масштабируемость
Децентрализованное обучение представляет собой решение проблем, связанных с коммуникацией в моделях MoE (Mixture of Experts). Распределяя вычислительную нагрузку между несколькими узлами, система снижает требования к пропускной способности сети и задержке, возникающие при синхронизации параметров модели. Это особенно важно для MoE-моделей, которые характеризуются большим количеством параметров и сложной структурой экспертов. Распределенное обучение позволяет эффективно масштабировать процесс обучения на кластерах машин, используя параллельные вычисления и снижая зависимость от единой точки отказа. Такой подход позволяет обучать более крупные и сложные модели MoE, которые были бы непрактичны для обучения на одном устройстве.
Система Sparse Expert Synchronization (SPES) представляет собой децентрализованную структуру для обучения больших языковых моделей (LLM), основанных на архитектуре Mixture-of-Experts (MoE). Она построена на принципах распределенного обучения, позволяя эффективно использовать ресурсы нескольких узлов для параллельной обработки. SPES направлена на снижение требований к памяти при обучении MoE-моделей за счет децентрализации и оптимизации синхронизации разреженных экспертных параметров, что позволяет обучать модели большего размера, чем это возможно на одном устройстве. Ключевым аспектом является распределенное хранение и обновление параметров экспертов между узлами, минимизируя необходимость в централизованном хранилище и связанную с ним узкую точку отказа.
Система Sparse Expert Synchronization (SPES) оптимизирует использование памяти и повышает пропускную способность за счет применения нескольких методов. В частности, используется Fully Sharded Data Parallel (FSDP) для распределения параметров модели между узлами, что снижает требования к памяти на каждом узле. Для дальнейшего снижения потребления памяти применяется активационное чекпоинтинг, позволяющий пересчитывать активации вместо их хранения. Кроме того, SPES использует смешанное обучение (Mixed Precision Training), применяя форматы данных с пониженной точностью, такие как FP16, что снижает потребление памяти и ускоряет вычисления, сохраняя при этом приемлемую точность модели. Комбинация этих техник позволяет эффективно обучать большие языковые модели на ограниченных ресурсах.
Для организации взаимодействия между узлами и управления обновлениями параметров в процессе децентрализованного обучения используется gRPC в качестве протокола удаленного вызова процедур и сервер параметров. gRPC обеспечивает эффективную и надежную передачу данных между узлами, что критически важно для масштабируемости системы. Сервер параметров централизованно хранит и обновляет параметры модели, принимая обновления от узлов и распространяя их обратно. Такая архитектура позволяет избежать необходимости полной синхронизации параметров между всеми узлами на каждом шаге обучения, снижая коммуникационные издержки и обеспечивая более высокую пропускную способность при обучении больших языковых моделей.
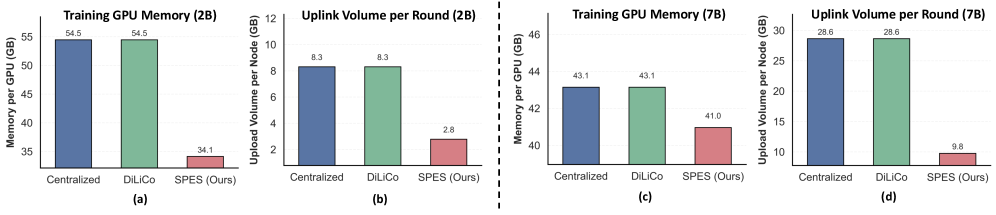
Влияние SPES: Превосходство в Производительности и Масштабируемости
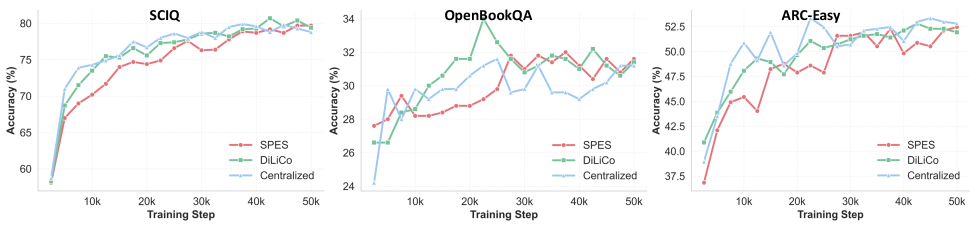
Система SPES демонстрирует существенное превосходство в скорости обучения и эффективности использования памяти по сравнению с традиционными методами централизованного обучения и другими децентрализованными платформами, такими как DiLiCo и Photon. В ходе экспериментов было установлено, что SPES позволяет значительно снизить нагрузку на графические процессоры, что особенно важно при работе с крупномасштабными языковыми моделями. Такое повышение эффективности достигается за счет оптимизированного распределения вычислений и коммуникаций между узлами, что позволяет сократить время обучения и снизить потребность в дорогостоящем оборудовании. В результате, SPES открывает новые возможности для исследователей и разработчиков, позволяя им обучать более сложные модели с меньшими затратами и в более короткие сроки.
В ходе экспериментов с 2B-моделью, система SPES продемонстрировала значительное снижение требований к памяти GPU. Вместо более чем 50GB, необходимых для традиционного централизованного обучения и альтернативного фреймворка DiLiCo, SPES успешно снизила потребление памяти до 35GB на GPU. Это достижение позволяет обучать более крупные модели на доступном оборудовании или использовать существующее оборудование для обучения большего числа моделей одновременно, открывая новые возможности для исследователей и разработчиков в области искусственного интеллекта. Такая оптимизация памяти является ключевым фактором в повышении эффективности и масштабируемости процесса обучения.
В ходе экспериментов с 7B моделью, система SPES продемонстрировала значительное снижение затрат на коммуникацию — всего 9.8GB на узел за раунд. Это на 65% меньше, чем требуется при использовании традиционных методов централизованного обучения и альтернативного децентрализованного фреймворка DiLiCo. Такое существенное уменьшение объёма передаваемых данных позволяет значительно ускорить процесс обучения и повысить эффективность использования сетевых ресурсов, особенно в масштабных распределенных системах. Достижение подобных показателей открывает новые возможности для обучения крупных языковых моделей на ограниченном оборудовании и с меньшими затратами.
Несмотря на использование менее производительного оборудования, система SPES демонстрирует сопоставимую с централизованным обучением скорость обработки — около 3.67 тысяч токенов в секунду на GPU. Это достижение особенно важно, поскольку позволяет эффективно обучать большие языковые модели даже в условиях ограниченных вычислительных ресурсов. Подобная производительность, сохраняемая при снижении требований к аппаратному обеспечению, открывает возможности для более широкого доступа к технологиям машинного обучения и снижает затраты на обучение моделей, делая их более доступными для исследователей и разработчиков.
Внедрение методики прогрева экспертных моделей, известной как Expert Merging Warm-up, продемонстрировало заметное улучшение показателей качества. Исследования показали, что данный подход позволил повысить средний балл оценки моделей на 0.8 пункта — с 50.5 до 51.3. Это свидетельствует о том, что постепенная активация экспертных компонентов в процессе обучения способствует более эффективной адаптации модели и, как следствие, повышению ее общей производительности. Прогрев экспертных моделей позволяет более плавно интегрировать знания различных экспертов, избегая резких изменений в процессе обучения и способствуя достижению оптимальных результатов.
Исследование, проведенное на базе открытой языковой модели OLMo, подтверждает высокую эффективность разработанного фреймворка SPES в достижении передовых результатов. SPES продемонстрировал способность значительно превосходить традиционные методы централизованного обучения и другие децентрализованные подходы, такие как DiLiCo и Photon, обеспечивая не только повышение скорости обучения и снижение потребления памяти, но и существенное уменьшение коммуникационных издержек. Полученные данные указывают на то, что SPES является перспективным решением для обучения больших языковых моделей, позволяющим добиться оптимального соотношения производительности и эффективности использования ресурсов.
Будущее Масштабирования: За Пределами Текущих Ограничений
Для дальнейшего повышения эффективности SPES необходимы углубленные исследования в области оптимизации для разнородных аппаратных платформ и динамического балансирования нагрузки. Текущие реализации часто сталкиваются с ограничениями при работе на системах с различной архитектурой процессоров и графических ускорителей, что приводит к неравномерному распределению вычислительных ресурсов. Оптимизация предполагает разработку алгоритмов, способных адаптироваться к конкретным характеристикам оборудования и эффективно распределять рабочую нагрузку между доступными ресурсами. Исследования направлены на создание механизмов, которые не только максимизируют пропускную способность, но и минимизируют задержки, обеспечивая стабильную и предсказуемую производительность даже при динамически изменяющихся условиях. Успешная реализация этих оптимизаций позволит значительно расширить возможности применения SPES в масштабных системах машинного обучения и приблизить к реальности создание действительно эффективных и масштабируемых больших языковых моделей.
Для дальнейшего увеличения масштабов языковых моделей критически важным представляется разработка инновационных протоколов разреженной коммуникации и адаптивных стратегий выбора экспертов. Существующие методы обмена данными между вычислительными узлами становятся узким местом при работе с огромными моделями, требуя значительного снижения объема передаваемой информации без потери точности. Адаптивный выбор экспертов, позволяющий динамически перенаправлять вычисления к наиболее компетентным подмоделям в зависимости от входных данных, способствует более эффективному использованию ресурсов и снижению вычислительных затрат. Исследования в этой области направлены на создание систем, способных самостоятельно оптимизировать процесс коммуникации и распределения нагрузки, обеспечивая тем самым масштабируемость и производительность даже при работе с чрезвычайно сложными задачами и огромными объемами данных.
Сочетание децентрализованного обучения, разреженных активаций и параметрически эффективных архитектур открывает перспективы для демократизации доступа к мощным языковым моделям. Традиционно обучение и развертывание крупных моделей требовало значительных вычислительных ресурсов, доступных лишь ограниченному кругу организаций. Однако, используя децентрализованные методы, обучение может быть распределено между множеством устройств, снижая зависимость от централизованных дата-центров. Разреженные активации, позволяющие активировать лишь часть нейронов в сети, существенно снижают вычислительные затраты и потребление памяти. Параметрически эффективные архитектуры, такие как адаптеры и LoRA, позволяют обучать лишь небольшую часть параметров модели, сохраняя при этом ее производительность. В результате, появляется возможность создавать и использовать мощные языковые модели на более скромном оборудовании, делая их доступными для более широкого круга исследователей и разработчиков, и стимулируя инновации в области искусственного интеллекта.
Представленная работа стремится к упрощению сложного процесса обучения больших языковых моделей, фокусируясь на эффективности и доступности. Разработчики SPES предлагают децентрализованный подход, основанный на архитектуре Mixture of Experts, что позволяет снизить требования к памяти и коммуникациям. Этот подход созвучен философии Пола Эрдеша: «Математика — это не только наука, но и искусство». Он верил в элегантность и простоту решений, в стремление к наиболее лаконичному выражению идеи. Подобно тому, как SPES стремится к оптимизации ресурсов, Эрдеш искал наиболее изящные доказательства, избегая излишней сложности. Работа демонстрирует, что достижение прогресса возможно не через усложнение, а через продуманное упрощение и эффективное использование доступных инструментов.
Что дальше?
Представленный подход, хоть и демонстрирует снижение затрат памяти и коммуникации при обучении больших языковых моделей, лишь отодвигает, но не устраняет фундаментальную сложность. Стремление к увеличению числа “экспертов” в архитектуре Mixture of Experts — это, по сути, бесконечная гонка, где каждое добавление требует всё более изощрённых методов синхронизации и распределения. Истинная эффективность, возможно, кроется не в наращивании масштаба, а в более глубоком понимании принципов, лежащих в основе интеллекта, и в создании моделей, способных к более компактному и элегантному представлению знаний.
Очевидным направлением является исследование альтернативных парадигм обучения, отходящих от слепого масштабирования параметров. Необходимо обратить внимание на методы, позволяющие модели учиться не только на огромных массивах данных, но и на небольшом количестве тщательно отобранных примеров, имитирующих процесс обучения человека. Поиск оптимального баланса между децентрализацией и координацией, между свободой “экспертов” и общей согласованностью, — это задача, требующая не только технических, но и философских размышлений.
В конечном счете, ценность любого метода обучения заключается не в его способности создавать всё более сложные системы, а в его способности создавать системы, которые можно понять. Убрать лишнее — вот ключ к ясности. И в этом, возможно, и заключается истинный прогресс.
Оригинал статьи: https://arxiv.org/pdf/2602.11543.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые вычисления для молекул: оптимизация ресурсов
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- Молекулярный интеллект: проверка химического мышления
- Стиль сквозь века: математика искусства
- Искусственный интеллект и закон: гармония неизбежна
- Диалоги с Искусственным Интеллектом: Как Проверить Надежность?
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Оптимизация процессов: симбиоз классических и квантовых вычислений
- Квантовая устойчивость к ошибкам: новый взгляд на исправление вставок и удалений
- Топoлогические формы и тайны Вселенной
2026-02-13 14:53