Автор: Денис Аветисян
Новая работа исследует границы авторского права в эпоху генеративного искусственного интеллекта и предлагает новый подход к определению нарушения.
Предлагается критерий оценки нарушения авторских прав, основанный на зависимости сгенерированного контента от существующих работ и анализе структуры допустимой генерации при увеличении объема обучающего корпуса.
Существующие правовые рамки, определяющие нарушение авторских прав, оказываются недостаточными для оценки креативности, генерируемой искусственным интеллектом. В работе ‘Creative Ownership in the Age of AI‘ предложен новый критерий определения нарушения авторских прав: произведение, созданное ИИ, считается нарушающим, если его генерация была бы невозможна без использования конкретного произведения в обучающем корпусе. Авторы моделируют генеративные системы как операторы замыкания, отображающие корпус существующих работ в пространство новых произведений, и характеризуют структуру допустимой генерации в зависимости от статистических свойств исходных данных. Не приведет ли более глубокое понимание взаимосвязи между распределениями творческих работ и ограничениями, налагаемыми на генеративный ИИ, к формированию более справедливых и эффективных правовых норм?
Генезис Творчества: Переосмысление Авторства в Эпоху Алгоритмов
Современное творчество всё чаще опирается на генеративные системы, что порождает сложные вопросы об авторском праве и оригинальности контента. Использование алгоритмов для создания музыки, изображений, текстов и даже программного кода ставит под сомнение традиционные представления об авторстве, поскольку произведение формируется не исключительно человеческим интеллектом, а результатом взаимодействия человека и машины. Возникает необходимость переосмысления юридических рамок, определяющих права на интеллектуальную собственность в условиях, когда процесс создания нелинеен и включает в себя элементы автоматизированной генерации. Особенно остро стоит вопрос о том, кто несёт ответственность за нарушение авторских прав — разработчик алгоритма, пользователь, предоставивший исходные данные, или сама система искусственного интеллекта? Подобные вызовы требуют комплексного подхода и разработки новых правовых норм, учитывающих специфику генеративного творчества.
В основе любой генеративной системы лежит так называемый “Генератор” — математическое отображение, которое определяет весь спектр возможных выходных данных на основе заданного входного корпуса. Представьте себе, что входной корпус — это набор исходных материалов, а Генератор — это сложный алгоритм, который преобразует эти материалы в новые произведения. Этот алгоритм не просто копирует входные данные, а создает на их основе нечто новое, опираясь на внутреннюю логику и математические закономерности. f(x) = y — простейшая форма представления Генератора, где x — входной корпус, а y — возможный выход. Понимание свойств этого отображения — какие элементы входного корпуса сохраняются, как меняется выход при небольших изменениях во входе, и как Генератор реагирует на повторные входные данные — необходимо для оценки правовых аспектов, связанных с авторским правом и оригинальностью создаваемых произведений.
Понимание ключевых свойств генератора — сохранения, монотонности и идемпотентности — играет решающую роль в оценке потенциальных последствий для авторского права. Сохранение указывает на то, что ключевые характеристики входных данных переносятся в сгенерированный контент, что поднимает вопросы о степени оригинальности. Монотонность описывает, как изменения во входных данных влияют на выходные — предсказуемость этой связи может повлиять на определение плагиата. Идемпотентность, в свою очередь, характеризует поведение генератора при повторном использовании одних и тех же входных данных — если генератор всегда выдает один и тот же результат, это упрощает анализ на предмет нарушения авторских прав. Исследование этих свойств позволяет более точно определить, является ли сгенерированный контент производным от исходного материала или представляет собой принципиально новое произведение, что необходимо для разрешения юридических споров в эпоху широкого распространения генеративных систем.
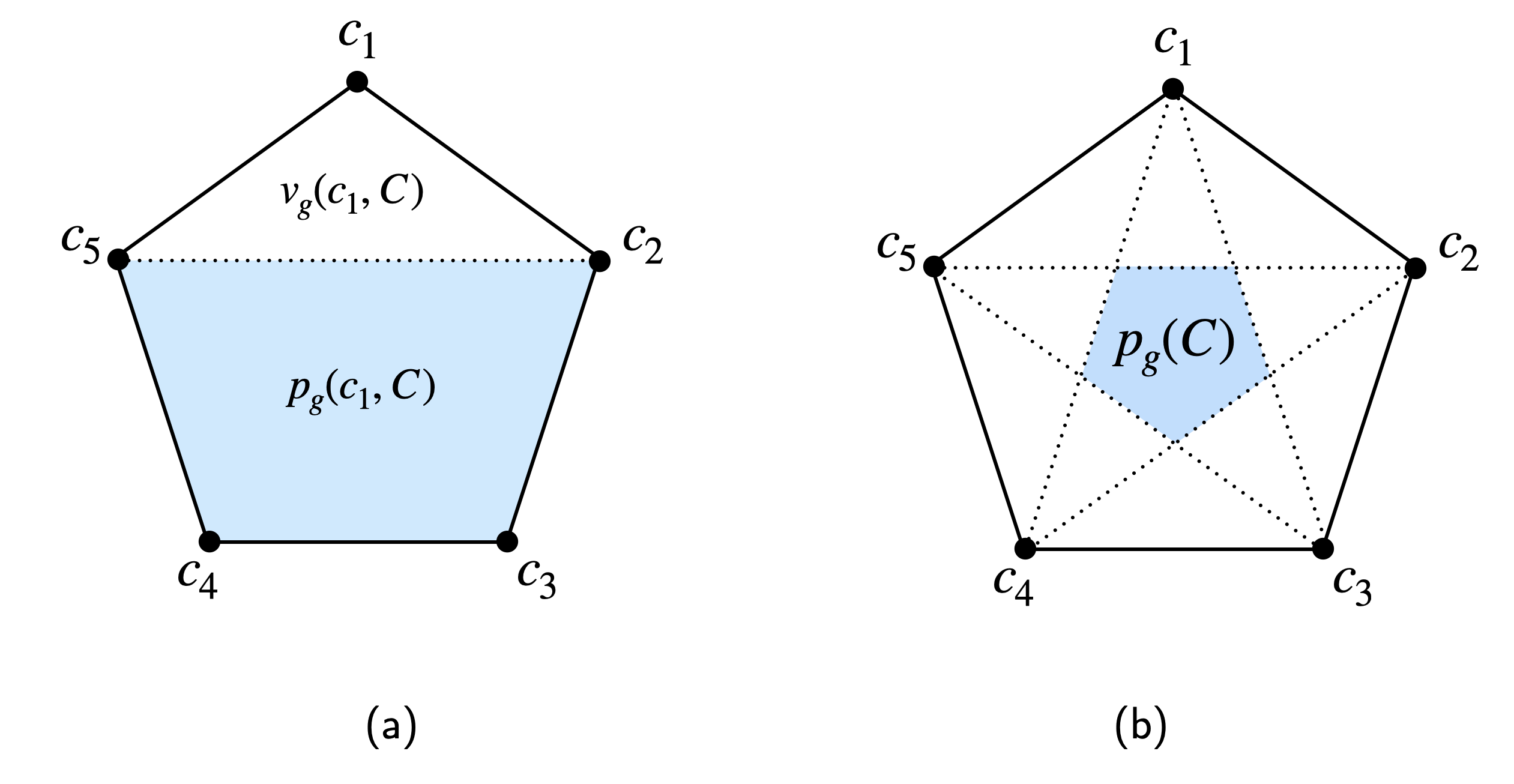
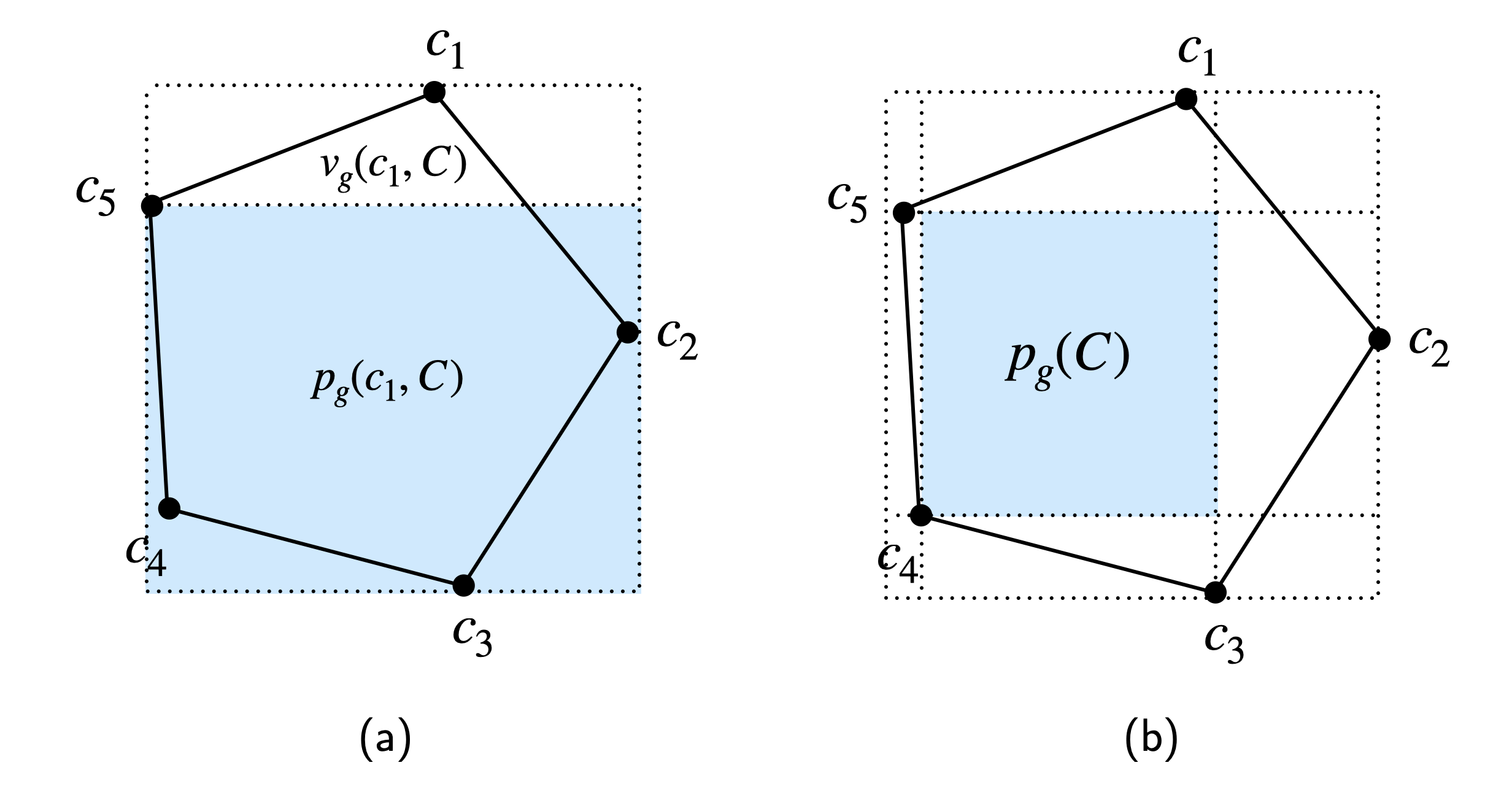
Деконструкция Генеративных Выходов: Разграничение Допустимого и Нарушающего
Генеративные модели, при создании контента, формируют два основных набора результатов: “Разрешенный набор” (Permissible Set) и “Набор нарушений” (Violation Set). “Разрешенный набор” включает в себя произведения, созданные без прямой зависимости от каких-либо конкретных защищенных авторским правом исходных материалов. В свою очередь, “Набор нарушений” состоит из результатов генерации, которые в значительной степени основаны на и воспроизводят элементы, защищенные авторским правом. Разделение на эти два набора является ключевым для оценки законности сгенерированного контента и определения потенциальных нарушений авторских прав.
Генераторы выпуклой оболочки (Convex Hull Generator) и генераторы на основе склеек (Splice Generator) представляют собой конкретные методы формирования наборов данных, составляющих основу генеративных моделей. Генератор выпуклой оболочки создает новые образцы, определяя границы пространства признаков существующего корпуса работ и генерируя данные внутри этих границ. Генератор на основе склеек, напротив, комбинирует фрагменты из исходного корпуса, создавая новые образцы путем конкатенации или смешивания существующих элементов. Оба подхода позволяют создавать как ‘Разрешенный набор’ (Permissible Set) — независимые произведения, так и ‘Нарушающий набор’ (Violation Set) — произведения, производные от защищенного материала, что демонстрирует процесс конструирования генеративных наборов из исходных данных.
Генератор “Box” представляет собой комплексный метод генерации контента, объединяющий принципы, используемые в “Convex Hull Generator” и “Splice Generator”. Он позволяет систематически исследовать границы между допустимым и нарушающим авторские права контентом, создавая как “Разрешенный набор” — произведения, не зависящие от исходных материалов, так и “Нарушающий набор” — произведения, основанные на защищенных данных. Используя комбинацию этих подходов, “Box Generator” позволяет оценить степень влияния исходного корпуса на генерируемый контент и установить четкую границу между оригинальным творчеством и производными работами, что важно для определения юридической ответственности.
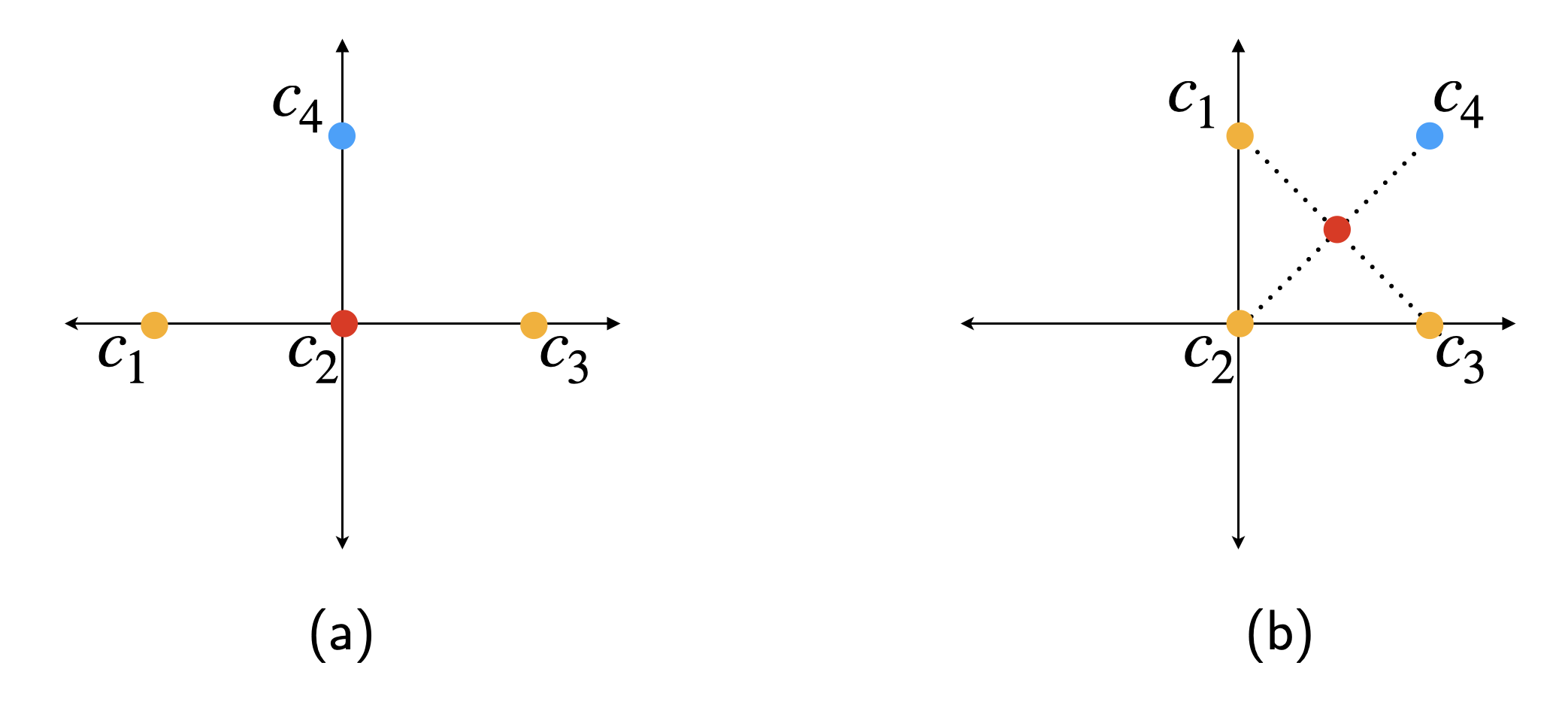
Роль Распределения в Оценке Генеративных Рисков: Вероятностный Подход
Состав множеств “Разрешенного” и “Нарушающего” контента напрямую зависит от вероятностного распределения признаков во входном корпусе данных. Чем более узкое и концентрированное распределение признаков, тем выше вероятность генерации контента, схожего с защищенными произведениями, и, следовательно, больше элементов попадает в множество “Нарушающего”. Напротив, широкое и равномерное распределение признаков способствует созданию оригинального контента, минимизируя риск нарушения авторских прав и увеличивая размер множества “Разрешенного”. Таким образом, анализ вероятностного распределения признаков является ключевым этапом оценки генеративных рисков и определения границ допустимого контента.
Распределение вероятностей признаков во входном корпусе оказывает существенное влияние на риск генерации контента, нарушающего авторские права. “Легкохвостые” распределения (light-tailed distributions) способствуют созданию оригинального контента, минимизируя зависимость от защищенных произведений, поскольку вероятность выбора редких или экстремальных значений признаков, соответствующих охраняемым объектам, низка. Напротив, “тяжелохвостые” распределения (heavy-tailed distributions) повышают вероятность генерации контента, схожего с существующими защищенными произведениями, поскольку они допускают более высокую вероятность выбора признаков, которые могут совпадать с охраняемыми объектами, тем самым увеличивая риск нарушения авторских прав. Фактически, чем более выражен “хвост” распределения, тем выше вероятность генерации контента, потенциально нарушающего авторские права.
Свойства равномерной нижней полунепрерывности и число Радона позволяют более детально оценить стабильность и предсказуемость работы генеративных моделей. Число Радона, равное d+2, является достаточным условием для непустоты допустимого множества при использовании выпуклых генераторов. Это означает, что при соблюдении данного условия, генератор способен создавать контент, который не нарушает заданные ограничения и находится в пределах допустимого пространства решений. Математически, это связано с теоремами о существовании решений для задач оптимального транспорта и гарантирует, что алгоритм генерации не приведёт к недействительным или неопределенным результатам, особенно при работе с многомерными данными, где d представляет собой размерность пространства признаков.
Авторское Право и Будущее Генеративного ИИ: Контрфактическая Оценка Творчества
Определение нарушения авторских прав неразрывно связано с понятием «контрфактической генерации». Суть заключается в том, что нарушение имеет место лишь в том случае, если конкретное произведение не возникло бы без использования защищенного авторским правом материала. Иными словами, необходимо установить, что данное произведение является прямым следствием заимствования, а не самостоятельным творением, которое могло бы возникнуть независимо. Этот принцип требует анализа не только сходства между произведениями, но и оценки вероятности создания аналогичного произведения без учета защищенного материала, что представляет собой сложную задачу, особенно в контексте генеративного искусственного интеллекта, способного создавать оригинальные работы на основе огромного массива данных.
Сложность определения границ нарушения авторских прав значительно возрастает в случаях, когда права принадлежат не одному, а нескольким создателям — так называемое коллективное авторство. В подобных ситуациях, выявление “множества нарушений” — конкретных элементов, заимствованных из защищенных произведений — становится крайне затруднительным. Невозможность четко установить, какая часть сгенерированного произведения является результатом оригинального творчества, а какая — результатом влияния множества правообладателей, расширяет потенциальный охват нарушений. Это создает правовую неопределенность и требует разработки новых подходов к оценке степени заимствования и установлению ответственности в контексте генеративного искусственного интеллекта, поскольку каждый участник коллективного произведения может претендовать на часть сгенерированного результата, увеличивая риск юридических споров.
Генеративные системы искусственного интеллекта, по самой своей природе, оперируют принципом контрфактической генеративности, что требует тонкого понимания связанных с этим юридических границ. По мере расширения обучающего корпуса и развития инноваций, характеризующихся небольшим «хвостом» распределения, отношение между допустимыми и генерируемыми произведениями стремится к единице. Это означает, что вероятность нарушения авторских прав постепенно снижается и, в долгосрочной перспективе, может стать пренебрежимо малой. Подобная тенденция ставит перед правовой системой задачу адаптации к новой реальности, где традиционные представления о плагиате и авторстве требуют переосмысления в контексте алгоритмического творчества и экспоненциального роста контента.
Представленное исследование затрагивает сложную проблему определения границ допустимого в эпоху генеративного искусственного интеллекта. Авторы предлагают рассматривать нарушение авторских прав не как простое совпадение, а как зависимость сгенерированного контента от существующих работ, оценивая эту зависимость через призму геометрических понятий, таких как выпуклые оболочки и числа Радона. Эта методология, стремящаяся к строгости, напоминает слова Людвига Витгенштейна: «Предел моего языка — предел моего мира». Подобно тому, как язык формирует наше восприятие реальности, так и границы допустимого генерирования определяются корпусом существующих работ, а анализ этой зависимости требует предельной ясности в определении критериев и методов оценки. Игнорирование этого факта приводит к субъективным интерпретациям и, как следствие, к неверным выводам о степени нарушения авторских прав.
Куда же дальше?
Предложенный подход, определяющий нарушение авторских прав через зависимость от существующих работ, не является, конечно, окончательным решением. Скорее, это попытка структурировать вопрос, который, судя по скорости развития генеративных моделей, будет только усложняться. Определение “зависимости” — область, требующая дальнейшей детализации. Необходимо учитывать не только поверхностное сходство, но и глубинную структуру, лежащую в основе как исходного произведения, так и сгенерированного. Особенно остро встает вопрос о роли случайности и о том, где заканчивается вдохновение и начинается плагиат, когда алгоритм, по сути, “перебирает” вероятности.
Идея анализа допустимого генерирования через призму растущего корпуса работ и связанных с этим метрик, таких как выпуклая оболочка и число Радона, выглядит перспективно, но пока остается скорее теоретической конструкцией. Практическое применение этих инструментов потребует значительных вычислительных ресурсов и, вероятно, разработки новых алгоритмов для эффективного анализа больших объемов данных. К тому же, предположение о распределениях с «легкими хвостами» требует эмпирической проверки — реальные данные могут оказаться гораздо менее предсказуемыми.
Ошибка в построении модели — не проблема, а информация. Возможно, в конечном итоге, ключом к решению проблемы авторских прав в эпоху ИИ окажется не поиск абсолютных критериев, а создание гибкой системы, способной адаптироваться к постоянно меняющимся условиям и учитывать контекст каждого конкретного случая. Иначе говоря, признание того, что идеального решения просто не существует.
Оригинал статьи: https://arxiv.org/pdf/2602.12270.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые вычисления для молекул: оптимизация ресурсов
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Искусственный интеллект и закон: гармония неизбежна
- Молекулярный интеллект: проверка химического мышления
- Квантовый свет в помощь машинному обучению
- Квантовая устойчивость к ошибкам: новый взгляд на исправление вставок и удалений
- Видеоредактирование по запросу: Новый подход к точности и связности
- Квантовый скачок или технологический тупик? Анализ новостей о квантовых технологиях
- Наука на грани: ускорение вычислений с помощью AI-ускорителей
2026-02-13 18:23