Автор: Денис Аветисян
Новый подход позволяет преобразовывать визуальные задачи в логические выражения, повышая точность и прозрачность работы мультимодальных систем.
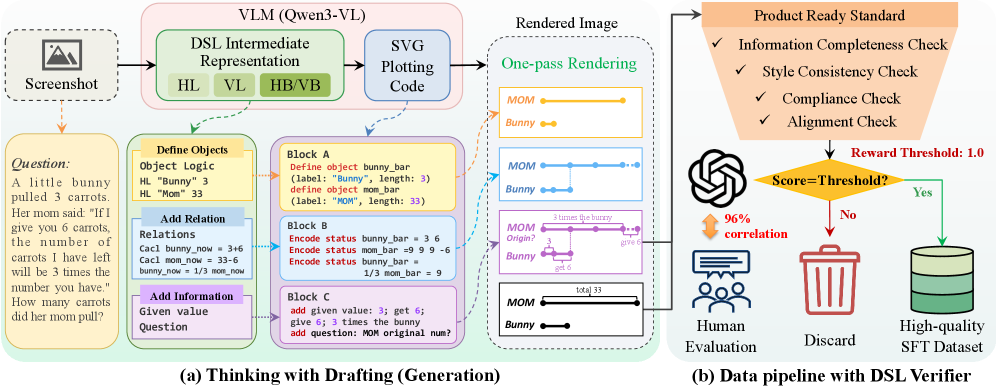
В статье представлен метод ‘Thinking with Drafting’, использующий минималистичный DSL для логической реконструкции и улучшения рассуждений на основе визуальных данных.
Существующие мультимодальные языковые модели демонстрируют впечатляющую способность к визуальному восприятию и генерации, однако сохраняется парадокс: они транскрибируют символы, не улавливая лежащую в их основе логическую топологию. В работе ‘Thinking with Drafting: Optical Decompression via Logical Reconstruction’ предложен новый подход, рассматривающий визуальное мышление как процесс логической реконструкции из сжатых визуальных токенов — «оптическую декомпрессию». Авторы предлагают парадигму «Мышление через черновики» (TwD), использующую минималистичный предметно-ориентированный язык (DSL) в качестве промежуточного представления для повышения точности и верифицируемости мультимодального рассуждения. Может ли подобный подход, основанный на создании исполняемого кода как «черновика» для визуальных доказательств, стать основой для создания более надежных и объяснимых систем визуального мышления?
От пикселей к логике: вызов визуального мышления
Традиционные методы визуального мышления часто сталкиваются с трудностями при переходе от необработанных данных изображений — простого набора пикселей — к абстрактным логическим понятиям. Существующие алгоритмы, как правило, не способны эффективно извлекать и структурировать информацию, необходимую для вывода логических связей из визуальных данных. Вместо непосредственного понимания отношений между объектами, системы полагаются на сложные статистические модели, которые могут быть подвержены ошибкам при незначительных изменениях в изображении или при наличии шума. Это приводит к тому, что даже простые задачи, требующие базового логического вывода, становятся сложными для решения, демонстрируя существенный разрыв между тем, как люди и машины воспринимают и анализируют визуальную информацию. Подобная неспособность к обобщению и адаптации ограничивает возможности применения этих систем в реальных условиях, где визуальные данные часто бывают неполными, зашумленными или непредсказуемыми.
Современные методы визуального мышления часто оказываются неспособны надежно реконструировать лежащие в основе логические структуры, основываясь лишь на визуальных представлениях. Эта неспособность существенно ограничивает возможности решения задач, требующих абстрактного мышления и логических выводов. Анализ изображений, как правило, фокусируется на распознавании объектов и паттернов, однако переход к пониманию взаимосвязей между этими объектами и их логических последствий представляет собой серьезную проблему. В результате, системы искусственного интеллекта, полагающиеся на подобный подход, демонстрируют хрупкость и неустойчивость при столкновении со сложными или неоднозначными визуальными сценариями, что подчеркивает необходимость разработки более совершенных методов, способных к глубокому логическому анализу визуальной информации.
Остро стоит задача разработки более явных и структурированных подходов к визуальному мышлению. Современные системы, сталкиваясь с визуальной информацией, часто не способны эффективно извлекать и представлять лежащие в ее основе логические связи. Необходимы методы, способные декодировать визуальные сигналы — формы, цвета, пространственные отношения — и преобразовывать их в формализованные логические выражения, такие как \forall x \in A: P(x) \implies Q(x) . Это позволит не просто распознавать объекты на изображении, но и понимать взаимосвязи между ними, делать логические выводы и решать задачи, требующие абстрактного мышления, аналогично тому, как это делает человек, анализируя визуальную информацию и формулируя логические заключения.
Мышление через черновики: реконструкция логики из визуальных данных
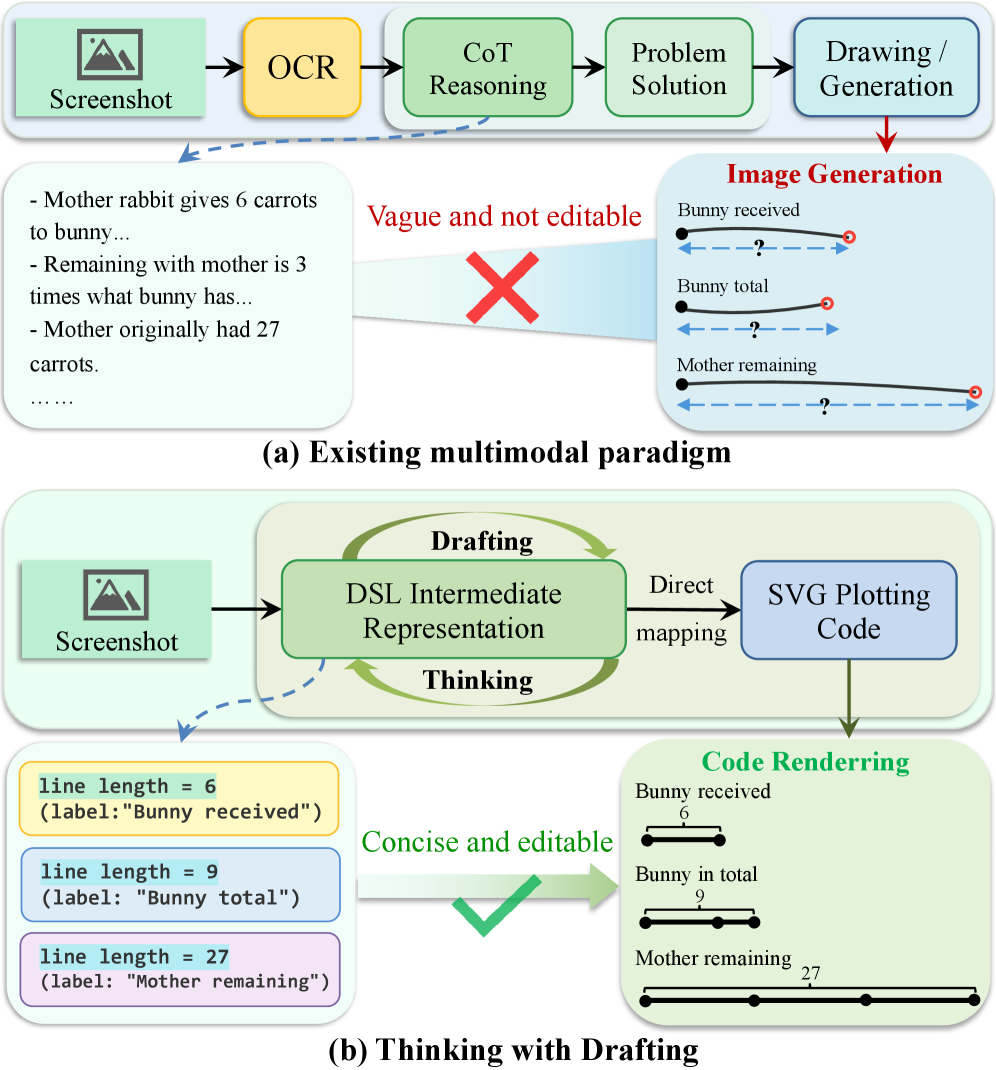
Подход “Мышление через черновики” (Thinking with Drafting) рассматривает визуальное рассуждение не как непосредственную обработку изображения, а как процесс реконструкции минималистичного графического языка логики (Logic Graphic DSL) на основе визуальных данных. Это означает, что вместо анализа пикселей и текстур, система стремится воссоздать абстрактное представление сцены в виде логических выражений и геометрических ограничений, представленных в DSL. Входные визуальные данные служат основой для построения этого логического представления, которое затем используется для выполнения рассуждений и решения задач, связанных с пониманием сцены. Такой подход позволяет отделить логическую структуру сцены от конкретных визуальных деталей, обеспечивая большую гибкость и надежность в процессе визуального рассуждения.
Данный подход использует Logic Graphic DSL для представления геометрических ограничений и логических взаимосвязей, присущих визуальным сценам. DSL позволяет формально описать такие аспекты, как взаимное расположение объектов (например, «объект A находится слева от объекта B»), их относительные размеры (A > B), а также логические отношения, такие как «если объект A виден, то объект B также виден». Это представление позволяет системе не просто распознавать визуальные элементы, но и понимать их взаимосвязи и логические зависимости, что необходимо для более надежного и интерпретируемого визуального рассуждения.
Явное кодирование логической структуры в системах визуального рассуждения обеспечивает повышение надежности и интерпретируемости их работы. Традиционные подходы часто полагаются на неявные представления, что затрудняет отладку и проверку корректности принимаемых решений. В отличие от этого, явное представление логических связей и ограничений позволяет проводить формальную верификацию и обеспечивает прозрачность процесса рассуждений. Это особенно важно в критически важных приложениях, где требуется обоснование принимаемых решений, а также для упрощения процесса отладки и модификации системы. Такой подход способствует созданию более устойчивых и предсказуемых систем визуального анализа.

Оптическая декомпрессия: выявление скрытой логической структуры
Оптическая декомпрессия обеспечивает эффективное восстановление скрытой логической структуры из визуальных входных данных, позволяя преобразовать изображения в структурированный DSL (Domain Specific Language). Процесс включает в себя анализ визуальной информации для выявления логических элементов и их взаимосвязей, что приводит к созданию программного кода на DSL, представляющего собой формальное описание исходного изображения. Это достигается путем применения алгоритмов компьютерного зрения и машинного обучения для интерпретации визуальных признаков, таких как формы, цвета и текстуры, и сопоставления их с соответствующими логическими конструкциями в DSL. В результате, визуальные данные становятся машиночитаемыми и пригодными для дальнейшей обработки и анализа в рамках DSL.
Контекстуальное оптическое сжатие (КОС) обеспечивает эффективное кодирование сложных визуальных документов во внутренние представления высокого качества. В отличие от традиционных методов сжатия, КОС ориентировано на сохранение семантической информации и логической структуры документа, а не только на уменьшение размера файла. Это достигается за счет анализа контекста визуальных элементов и построения компактной, но информативной модели, отражающей взаимосвязи между ними. Внутреннее представление, полученное с помощью КОС, позволяет выполнять сложные операции анализа и обработки визуальных данных, такие как извлечение информации, распознавание объектов и построение логических выводов, с высокой точностью и эффективностью.
Язык графической логики (DSL) использует виртуальную систему сеток для повышения эффективности геометрического рассуждения. Эта система отображает непрерывное пространство холста на дискретное логическое пространство, что позволяет более точно представлять и обрабатывать геометрические данные. Отображение на дискретную сетку упрощает определение отношений между объектами, таких как положение, размер и ориентация, что необходимо для задач анализа изображений и автоматического логического вывода. Использование виртуальной сетки позволяет DSL эффективно представлять и манипулировать геометрической информацией, что значительно улучшает возможности геометрического рассуждения.

MLLM и программное рассуждение: синергетический подход
Мультимодальные большие языковые модели (MLLM) демонстрируют впечатляющую способность к визуальному рассуждению, особенно при использовании подхода “Мышление с черновиками” (Thinking with Drafting). Этот метод позволяет модели не просто выдавать конечный ответ, но и генерировать промежуточные шаги решения, подобно тому, как человек делает наброски и заметки при решении сложной задачи. В процессе генерации черновиков MLLM последовательно уточняет свои рассуждения, выявляя и исправляя ошибки на ранних этапах. Такой подход значительно повышает надежность и точность ответов, позволяя моделям успешно справляться с задачами, требующими комплексного анализа визуальной информации и логических выводов. По сути, “Мышление с черновиками” превращает MLLM в мощный инструмент для решения задач визуального интеллекта, расширяя границы возможностей искусственного интеллекта в этой области.
Многомодальные большие языковые модели (MLLM) демонстрируют значительно улучшенные способности к решению задач при использовании методов рассуждений, таких как «Цепочка мыслей» (Chain-of-Thought, CoT) и «Программа мыслей» (Program-of-Thought, PoT). Метод CoT позволяет модели последовательно генерировать промежуточные шаги рассуждений, что имитирует человеческий подход к решению сложных проблем и повышает точность ответа. В свою очередь, PoT идет еще дальше, представляя решение в виде исполняемого кода или программы, что особенно эффективно для задач, требующих точных вычислений или логических операций. Использование этих техник позволяет MLLM не просто выдавать ответы, а демонстрировать процесс мышления, делая их более надежными и интерпретируемыми, а также способными к решению задач, ранее недоступных для подобных систем.
Сочетание структурированного представления данных в виде предметно-ориентированного языка (DSL) и мощных возможностей логического вывода больших языковых моделей (LLM) демонстрирует значительное улучшение результатов при решении сложных задач визуального анализа. Такой подход позволяет LLM не просто «видеть» изображение, но и преобразовывать визуальную информацию в формальное, структурированное описание, с которым модель может эффективно работать. DSL выступает в роли своеобразного «переводчика», упрощающего понимание визуальных данных и позволяющего модели применять логические правила и рассуждения для достижения решения. Эксперименты показывают, что подобные системы демонстрируют повышенную точность и надежность при решении задач, требующих не только распознавания объектов, но и понимания их взаимосвязей и контекста, что открывает новые перспективы в области компьютерного зрения и искусственного интеллекта.
VisAlg и за его пределами: бенчмаркинг и будущие направления
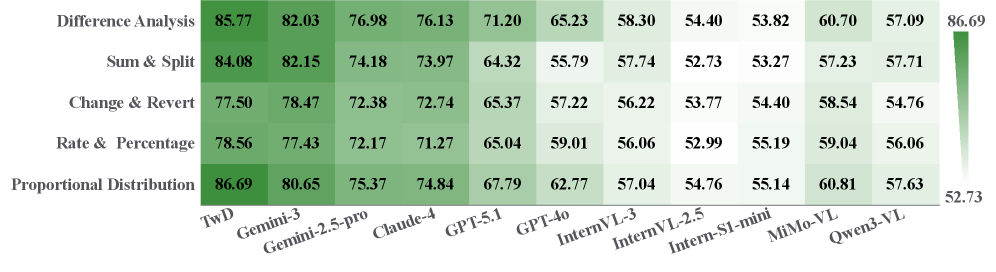
Набор данных VisAlg представляет собой надежную платформу для оценки возможностей логического визуального рассуждения, позволяя проверить производительность систем при решении задач, требующих логического вывода. В его основе лежит принцип проверки способности алгоритмов не просто распознавать объекты на изображениях, но и устанавливать между ними логические связи, делать умозаключения и находить решения, основанные на дедуктивном мышлении. Разнообразие задач в VisAlg охватывает широкий спектр сценариев, требующих анализа визуальной информации и применения логических правил, что делает его ценным инструментом для развития и оценки искусственного интеллекта, способного к сложному рассуждению.
Автоматизированная оценка сгенерированных ответов, реализованная посредством подхода LLM-as-Judge, обеспечивает надёжность и качество процесса логического рассуждения. Вместо ручной проверки, большая языковая модель выступает в роли беспристрастного судьи, анализируя каждое решение на соответствие логическим правилам и предоставленным данным. Этот метод позволяет не только существенно ускорить процесс оценки, но и минимизировать субъективность, часто присущую человеческому анализу. Использование LLM-as-Judge гарантирует, что каждое заключение, полученное в ходе визуального рассуждения, подвергается строгой и последовательной проверке, что критически важно для построения надёжных и воспроизводимых систем искусственного интеллекта.
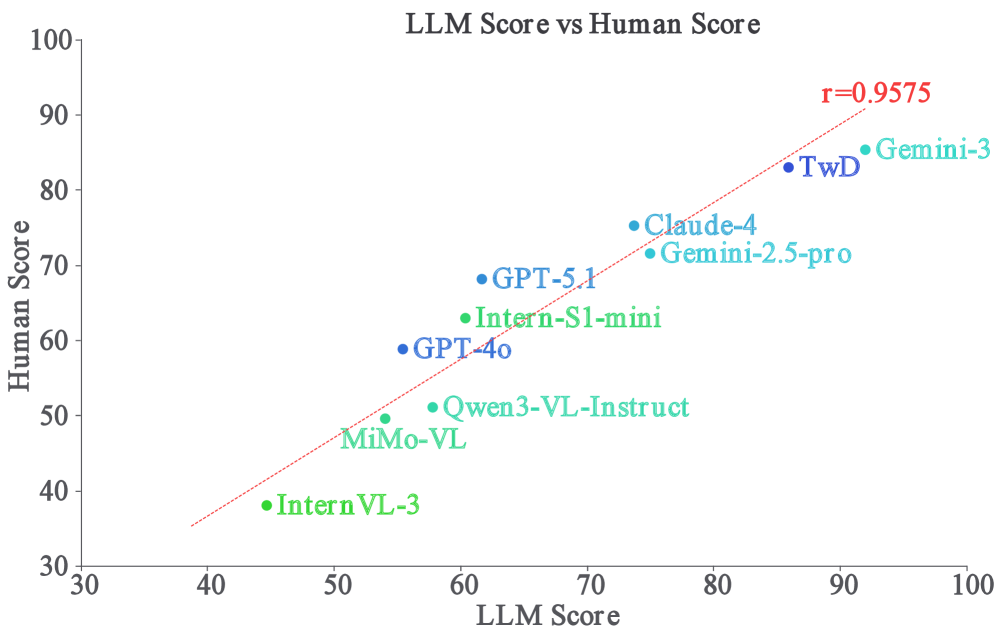
Представленный подход демонстрирует передовые результаты на эталонном наборе данных VisAlg, достигая показателя в 82.63 балла. Это значительно превосходит производительность мощных моделей Gemini-3-Pro (79.96) и Gemini-2.5-Pro (74.12), подтверждая эффективность разработанной методологии в задачах логического визуального рассуждения. Полученный результат свидетельствует о значительном прогрессе в области искусственного интеллекта и открывает новые возможности для создания систем, способных к сложным умозаключениям на основе визуальной информации.
Представленная работа демонстрирует стремление к упрощению сложных систем, что находит отклик в словах Грейс Хоппер: «Лучший способ объяснить — это продемонстрировать». Авторы, подобно опытному архитектору, стремятся к «минималистичному DSL», избавляясь от избыточности в представлении визуальной информации. Парадигма «Thinking with Drafting» (TwD) акцентирует внимание на логической реконструкции, что позволяет перевести восприятие в структурированный вид. Этот подход, направленный на устранение ненужного, не просто повышает точность мультимодального рассуждения, но и делает его более прозрачным и проверяемым, воплощая принцип: совершенство достигается не когда нечего добавить, а когда нечего убрать.
Что Дальше?
Представленный подход, хоть и демонстрирует элегантность в стремлении к минимализму, не является панацеей. Иллюзии простоты часто скрывают сложность реализации. Необходимо признать, что перевод визуальной информации в формальную логику — задача, требующая не только точного синтаксиса DSL, но и глубокого семантического понимания. Текущие модели, хоть и способны к реконструкции, всё ещё подвержены ошибкам, особенно в случаях неоднозначности или неполноты исходных данных.
Будущие исследования должны быть сосредоточены на преодолении этой хрупкости. Интересным направлением представляется разработка механизмов самокоррекции и верификации логических реконструкций. Важно сместить акцент с простого получения ответа на доказательство его корректности. Необходимо исследовать возможность интеграции с другими формальными системами, позволяющими проверять согласованность рассуждений и выявлять логические ошибки.
В конечном счёте, истинный прогресс не в создании более сложных моделей, а в создании более простых и понятных. Цель — не имитировать интеллект, а создать инструменты, позволяющие человеку мыслить яснее и точнее. И, возможно, когда-нибудь, мы сможем построить систему, способную не просто решать задачи, а объяснять, почему она это делает.
Оригинал статьи: https://arxiv.org/pdf/2602.11731.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Квантовые вычисления для молекул: оптимизация ресурсов
- Молекулярный интеллект: проверка химического мышления
- Искусственный интеллект и закон: гармония неизбежна
- Топoлогические формы и тайны Вселенной
- Квантовые вычисления на GPU: новый подход к моделированию сложных молекул
- Освобождая потенциал мультимодальных моделей: метод развёртывания контекста
- Квантовая обработка сигналов: новый подход к умножению и свертке
- Favia: Искусственный интеллект на страже безопасности кода
2026-02-13 21:44