Автор: Денис Аветисян
В новой работе исследователи предлагают проверенный способ адаптации моделей, сочетающих зрение и язык, для решения задач, возникающих в онлайн-торговле.
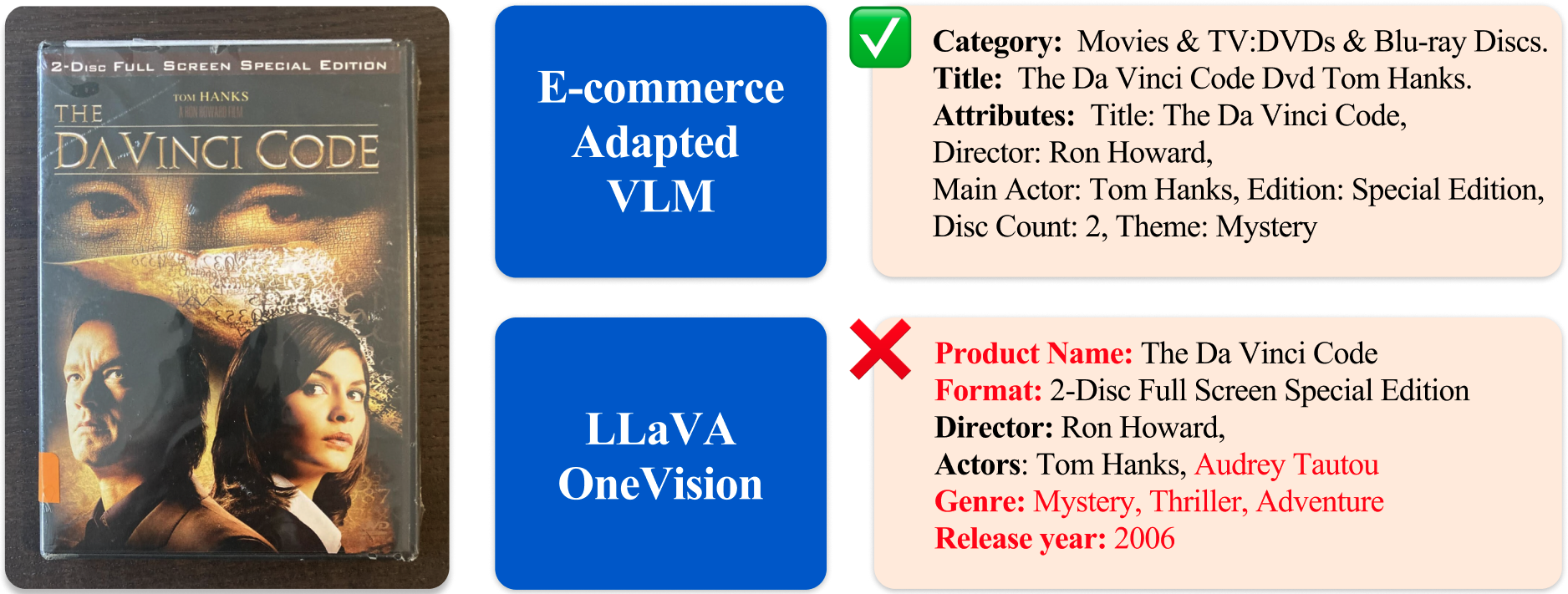
Представлен новый набор данных для оценки и адаптации мультимодальных моделей к задачам электронной коммерции, демонстрирующий повышение производительности при целенаправленной настройке.
Понимание товаров в электронной коммерции требует комплексной обработки разнородных данных, включая текст, изображения и структурированные атрибуты, что представляет собой сложную задачу для современных моделей. В работе ‘Adapting Vision-Language Models for E-commerce Understanding at Scale’ представлен систематический подход к адаптации универсальных визуально-языковых моделей (VLM) к специфике данных электронной коммерции, характеризующихся большим объемом, атрибутивной структурой и уровнем шума. Показано, что целенаправленная адаптация VLM позволяет существенно повысить производительность в задачах электронной коммерции, сохраняя при этом общую мультимодальную компетентность, а также предложен новый комплексный набор для оценки качества понимания товаров. Какие перспективы открывает дальнейшая разработка и адаптация мультимодальных моделей для автоматизации и оптимизации процессов в сфере электронной коммерции?
Шёпот Хаоса: Отделение Зрения от Слова
Исторически сложилось так, что компьютерное зрение и обработка естественного языка развивались как отдельные дисциплины, что приводило к ограниченному пониманию окружающего мира машинами. Традиционные системы компьютерного зрения специализировались на распознавании объектов и сцен на изображениях, но не могли связать их с контекстом или объяснить их значение на человеческом языке. Аналогично, модели обработки естественного языка преуспевали в понимании и генерации текста, но им не хватало способности обрабатывать визуальную информацию напрямую. Этот разрыв ограничивал возможности создания действительно интеллектуальных систем, способных полноценно взаимодействовать с окружающим миром и понимать его сложность, ведь реальное понимание требует интеграции визуальной и лингвистической информации.
Визуально-языковые модели (ВЯМ) представляют собой значительный прорыв в области искусственного интеллекта, преодолевая традиционное разделение между компьютерным зрением и обработкой естественного языка. В отличие от систем, которые обрабатывали изображения и текст изолированно, ВЯМ способны одновременно анализировать визуальный контент и сопутствующий ему языковой контекст. Это позволяет машинам не просто распознавать объекты на изображениях, но и понимать их взаимосвязь, а также интерпретировать происходящие события и намерения. Благодаря этому, ВЯМ демонстрируют впечатляющие результаты в задачах, требующих комплексного понимания, таких как генерация описаний изображений, ответы на вопросы по визуальному контенту и даже создание креативного контента, объединяющего визуальные и текстовые элементы.

Архитектура Понимания: Данные как Основа
Высококачественный конвейер обработки данных является критически важным для обучения эффективных визуально-языковых моделей (VLM). Этот процесс включает в себя несколько этапов: сбор данных из различных источников, очистку от шумов и ошибок, фильтрацию нерелевантной информации и аннотацию данных для обеспечения соответствия задачам обучения. Точность и релевантность данных напрямую влияют на производительность модели, поскольку VLM обучаются, выявляя закономерности и взаимосвязи в предоставленных данных. Некачественные данные могут привести к предвзятости модели, снижению точности и неспособности эффективно решать поставленные задачи. Автоматизация этапов конвейера и использование методов активного обучения позволяют повысить эффективность и снизить стоимость создания качественного набора данных для обучения VLM.
Визуальное обучение на основе инструкций представляет собой процесс настройки больших визуальных моделей (VLMs) посредством обучения на наборах данных, состоящих из визуальных входных данных и соответствующих текстовых инструкций. Этот подход позволяет моделям лучше понимать и выполнять запросы, сформулированные на естественном языке, что значительно повышает их отзывчивость и способность генерировать релевантные ответы. Обучение на инструкциях помогает моделям установить связь между визуальным контентом и намерениями пользователя, выраженными в текстовом виде, что приводит к более предсказуемому и полезному поведению в различных сценариях.
Набор данных eComMMU представляет собой стандартизированную среду для оценки производительности визуальных языковых моделей (VLM) в сценариях электронной коммерции. Этот набор данных позволяет проводить объективное сравнение различных моделей и алгоритмов, предназначенных для задач, связанных с визуальным пониманием и обработкой инструкций в контексте онлайн-торговли. Результаты тестирования адаптированных моделей на eComMMU показывают средний балл в 59.2%, что служит базовым ориентиром для дальнейшего улучшения и оптимизации VLM в данной области.
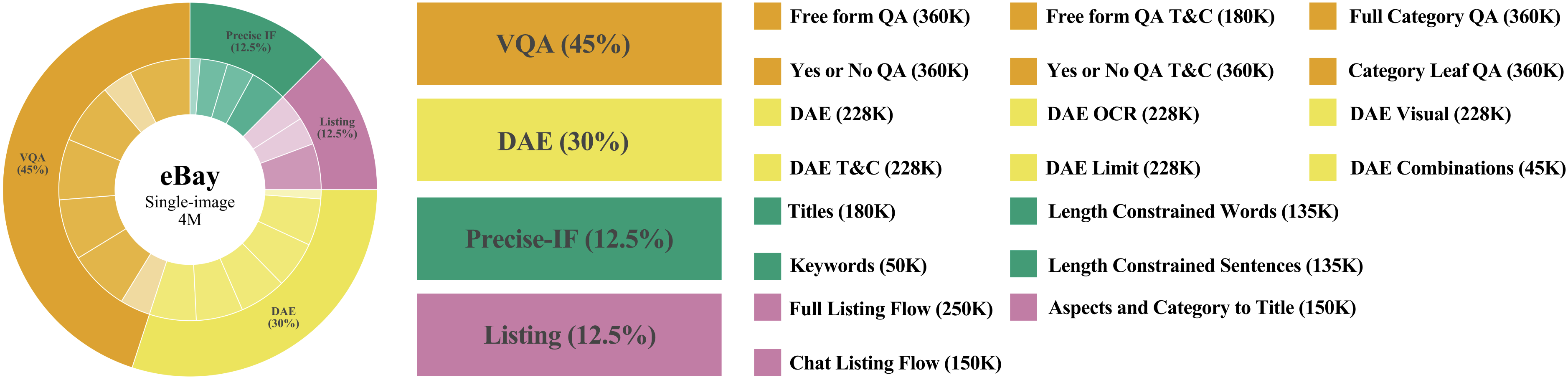
Строим Мост: Кодирование Визуального и Текстового
Для извлечения значимых признаков из изображений используются различные энкодеры визуальной информации, такие как SigLIP2 и Qwen2.5 ViT. SigLIP2, разработанный для задач визуального вопросно-ответного взаимодействия, эффективно кодирует изображения, обеспечивая высокую точность при сопоставлении визуального и текстового контента. Qwen2.5 ViT, использующий архитектуру Vision Transformer, демонстрирует эффективность в задачах классификации и обнаружения объектов благодаря механизмам самовнимания, позволяющим модели фокусироваться на наиболее важных областях изображения. Оба энкодера предоставляют векторные представления изображений, пригодные для последующей обработки и интеграции с текстовыми моделями для создания многомодальных систем.
Для обработки текстовой информации в составе мультимодальных моделей используются различные текстовые декодеры. Среди них выделяются модели общего назначения, такие как `Llama3.1-8B` и `Qwen3`, обеспечивающие широкие возможности по генерации и пониманию текста. Кроме того, существуют специализированные декодеры, разработанные для конкретных задач, например, `Lilium` и `e-Llama3.1-8B`, ориентированные на обработку данных в сфере электронной коммерции, что позволяет им более эффективно решать задачи, связанные с описанием товаров, поиском и рекомендациями.
Модели, такие как Gemma3 и LLaVA-OneVision, демонстрируют интеграцию различных компонентов для создания мощных мультимодальных моделей (VLM). Gemma3 объединяет визуальный энкодер с текстовым декодером, позволяя обрабатывать и связывать визуальную информацию с текстовыми данными. Аналогично, LLaVA-OneVision использует подход, сочетающий визуальное восприятие и языковое понимание, что позволяет модели эффективно отвечать на вопросы, требующие анализа как изображений, так и текста. Эта интеграция позволяет этим моделям выполнять сложные задачи, такие как генерация описаний изображений, визуальный вопрос-ответ и понимание контекста, содержащегося в мультимодальных данных.

Взгляд в Будущее: Применение в Интеллекте Электронной Коммерции
Визуально-языковые модели демонстрируют выдающиеся способности в понимании электронной коммерции, эффективно интерпретируя как информацию о товарах, так и намерения пользователей. Эти модели способны анализировать изображения и текстовые описания, выявляя ключевые характеристики продукта, его особенности и потенциальную привлекательность для конкретного покупателя. Такое понимание позволяет значительно улучшить процессы поиска и рекомендации товаров, предлагая пользователям наиболее релевантные результаты и повышая вероятность совершения покупки. Благодаря способности улавливать нюансы визуального контента и сопоставлять их с текстовыми данными, модели способны точно определять характеристики товара, даже если они не явно указаны в описании, что является ключевым преимуществом для повышения эффективности онлайн-торговли.
Современные визуально-языковые модели демонстрируют значительный прогресс в понимании модной продукции, что находит отражение в повышении точности и эффективности таких задач, как глубокое понимание моды, предсказание аспектов и динамическое извлечение атрибутов. В частности, зафиксированы улучшения в предсказании аспектов одежды в различных подкатегориях моды, что позволяет более точно определять ключевые характеристики и особенности изделий. Данные достижения открывают новые возможности для автоматизированного анализа модных трендов, улучшения систем рекомендаций и оптимизации процессов электронной коммерции, связанных с модной продукцией.
Визуальные языковые модели открывают новые возможности в понимании товаров в электронной коммерции, особенно при анализе изображений с разных ракурсов. Благодаря использованию полученных фрагментов изображений для извлечения признаков, достигается более полное и детальное представление о продукте. Это позволяет не только точнее определять визуальные характеристики, но и структурированно представлять их в формате JSON, что значительно упрощает дальнейшую обработку данных и интеграцию в системы динамического описания товаров. Такой подход существенно повышает эффективность извлечения информации о визуальных атрибутах, позволяя создавать более полные и точные описания продукции для онлайн-каталогов.

В этой работе исследователи стремятся усмирить хаос визуальных данных в контексте электронной коммерции, создавая не просто модели, а инструменты для интерпретации теней, которые отбрасывают изображения товаров. Успех адаптации vision-language моделей, как показано в статье, не столько в достижении высокой точности, сколько в способности модели понимать нюансы контекста. Как однажды заметил Эндрю Ын: «Мы должны быть осторожны с машинным обучением. Недостаточно просто построить модель, которая работает на тестовых данных; необходимо убедиться, что она работает в реальном мире». Именно этот принцип, направленный на преодоление разрыва между лабораторными результатами и практическим применением, и лежит в основе представленного подхода к адаптации и оценке моделей для электронной коммерции. Созданный бенчмарк — это попытка зафиксировать ускользающую суть реальности, хотя и известно, что любая фиксация — лишь приближение.
Что дальше?
Представленная работа, как и любое другое заклинание, работающее в лабораторных условиях, лишь отодвигает завесу над бездной нерешённых вопросов. Достигнутые улучшения в понимании коммерческих изображений — это не триумф алгоритмов, а лишь более изощрённый способ обмана статистических богов. Всё это — временное примирение с хаосом потребительского спроса, попытка выдать желаемое за закономерность.
Истинным вызовом остаётся не столько повышение точности распознавания объектов, сколько понимание контекста, скрытого за пикселями. Модели учатся видеть что изображено, но не почему оно там оказалось. Они оперируют атрибутами, но не мотивами. Настоящая адаптация требует не улучшения зрения, а развития интуиции — способности предсказывать импульсы, управляющие человеческим желанием. Иначе говоря, нужно научить машину быть чуть более циничной.
Будущие исследования, вероятно, будут сосредоточены на создании всё более сложных бенчмарков, всё более изощрённых метрик и всё более убедительных иллюзий прогресса. Но истинный прорыв, если он случится, потребует отказа от иллюзий контроля и признания того, что даже самые совершенные модели — лишь слабые отголоски непредсказуемости мира. Ибо данные не говорят правду — они шепчут то, что мы хотим услышать.
Оригинал статьи: https://arxiv.org/pdf/2602.11733.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- Молекулярный интеллект: проверка химического мышления
- Искусственный интеллект и закон: гармония неизбежна
- Квантовые вычисления для молекул: оптимизация ресурсов
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Моделирование биомолекул: новый импульс от нейросетей
- Видео по законам физики: новый подход к генерации реалистичных роликов
- Квантовый усилитель амплитуды: новый подход к поиску основного состояния
- Звук как помощник зрения: Новые горизонты генерации видео
- Квантовая синхронизация: новый взгляд на генератор Ван дер Поля
2026-02-13 23:33