Автор: Денис Аветисян
В статье предлагается инновационная система непрерывного обучения, позволяющая ИИ не только накапливать знания, но и совершенствовать сам процесс мышления.
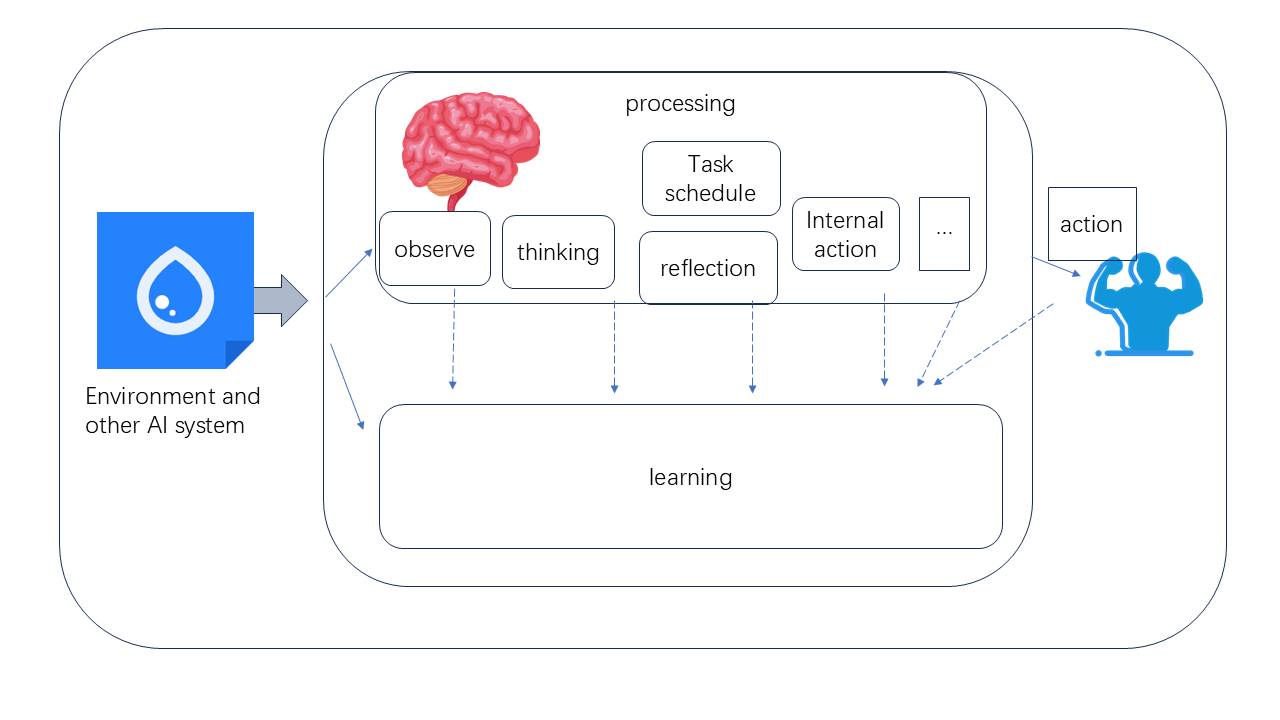
Предлагаемый подход позволяет ИИ системам адаптировать внутренние процессы рассуждений наряду с выполнением задач, обеспечивая непрерывное обучение и структурную адаптацию.
Несмотря на значительные успехи в области искусственного интеллекта, большинство существующих систем фокусируются на обучении конкретным задачам, упуская из виду развитие внутренних механизмов рассуждений. В данной работе, посвященной теме ‘Human-Inspired Continuous Learning of Internal Reasoning Processes: Learning How to Think for Adaptive AI Systems’, предлагается новый подход к непрерывному обучению, позволяющий ИИ-системам адаптировать не только что они знают, но и как они думают. Предложенная структура объединяет рассуждения, действия, рефлексию и верификацию в единую модель, оптимизируя организацию и эволюцию когнитивных процессов в процессе выполнения задач. Способны ли подобные системы, обучаясь “думать”, достичь принципиально нового уровня адаптивности и эффективности в динамичных реальных условиях?
Предел Разума: Ограничения Традиционного Мышления LLM
Несмотря на впечатляющую способность генерировать текст и решать некоторые задачи, современные большие языковые модели (LLM) часто демонстрируют затруднения при решении сложных, многоступенчатых задач, требующих последовательного применения логических операций. Эта проблема проявляется в неспособности моделей эффективно отслеживать промежуточные результаты, планировать последовательность действий и адаптироваться к изменяющимся условиям в процессе решения. В частности, LLM испытывают трудности в задачах, требующих дедуктивного или индуктивного мышления, а также в ситуациях, где необходимо учитывать множество взаимосвязанных факторов. Наблюдаемые ошибки часто связаны с потерей контекста, неправильной интерпретацией информации или неспособностью модели выделить наиболее важные аспекты проблемы, что указывает на фундаментальные ограничения в архитектуре и принципах работы данных систем.
Несмотря на впечатляющий прогресс в увеличении размеров языковых моделей, простое наращивание числа параметров не гарантирует пропорционального улучшения их способности к сложному рассуждению. Исследования показывают, что после определенного порога, дальнейшее увеличение масштаба моделей приносит все меньше ощутимых результатов в решении задач, требующих многоступенчатого логического вывода и анализа. Это указывает на фундаментальное ограничение существующей архитектуры, где улучшение производительности связано не только с объемом знаний, но и с принципиально иными подходами к организации и обработке информации. Модели, лишенные механизмов эффективного управления внутренним состоянием и приоритезации данных, демонстрируют сложности в последовательном решении задач, даже обладая огромным объемом информации, что подчеркивает необходимость разработки новых архитектур, ориентированных на более сложные формы рассуждений.
Неспособность современных больших языковых моделей (LLM) к сложным рассуждениям обусловлена отсутствием явных механизмов для управления внутренним состоянием и расстановки приоритетов информации в процессе решения задач. В отличие от человеческого мышления, где важные детали удерживаются в рабочей памяти, а нерелевантные отсеиваются, LLM обрабатывают входные данные последовательно, без возможности эффективно выделять и сохранять промежуточные результаты. Это приводит к тому, что при решении многоступенчатых задач модель может «забывать» ключевую информацию или терять нить рассуждений, что негативно сказывается на точности и последовательности ответов. По сути, недостаток внутренней «оперативной памяти» и системы приоритетов ограничивает способность модели к эффективному планированию действий и адаптации к меняющимся условиям, даже при наличии обширных знаний.
Эффективное рассуждение требует не просто доступа к знаниям, но и умения выстраивать последовательность действий и постоянно адаптироваться к меняющимся условиям. Исследования показывают, что современные большие языковые модели (LLM) часто испытывают трудности не из-за недостатка информации, а из-за неспособности эффективно планировать и выполнять сложные задачи, требующие множества шагов. Модели, обладающие лишь способностью извлекать и комбинировать существующие знания, не могут адекватно реагировать на неожиданные препятствия или корректировать стратегию в процессе решения проблемы. Способность к динамическому планированию, приоритизации задач и корректировке действий на основе получаемой обратной связи является ключевым фактором, определяющим способность к действительно сложному и гибкому мышлению, что выходит за рамки простого масштабирования параметров модели.
Воссоздание Разума: Непрерывная Система Обучения
Непрерывная обучающаяся система (Continuous Learning Framework) разработана с учетом принципов человеческого познания, объединяя внутреннее рассуждение, выполнение действий и обучение в единую интегрированную структуру. В отличие от традиционных подходов, где эти процессы рассматриваются изолированно, данная система стремится к моделированию когнитивной архитектуры, позволяющей динамически переключаться между планированием, действиями и адаптацией на основе получаемого опыта. Интеграция этих компонентов позволяет системе не только решать поставленные задачи, но и улучшать свои способности в процессе работы, подобно тому, как это происходит в человеческом мозге. Основная цель — создание системы, способной к гибкому и эффективному решению задач в сложных и меняющихся условиях.
В рамках данной структуры искусственного интеллекта реализовано явное моделирование ключевых когнитивных компонентов, включая механизмы планирования действий и расстановки приоритетов для внутренних процессов рассуждения. Это достигается путем формализации процедур выбора оптимальной последовательности действий для достижения поставленных целей, а также путем динамической оценки важности различных внутренних задач, таких как анализ данных, генерация гипотез и проверка результатов. Приоритезация осуществляется на основе заданных критериев, контекста текущей ситуации и доступных ресурсов, что позволяет эффективно распределять вычислительные мощности и обеспечивать своевременное выполнение критически важных операций.
В основе данной структуры лежит одновременное использование последовательного рассуждения и параллельного обучения. Последовательное рассуждение обеспечивает возможность целенаправленного планирования и решения задач, требующих многошагового подхода. Параллельное обучение, в свою очередь, позволяет системе быстро адаптироваться к изменяющимся условиям внешней среды, оперативно корректируя поведение на основе поступающих данных. Такое сочетание позволяет эффективно решать как сложные, требующие предварительного планирования задачи, так и быстро реагировать на непредсказуемые изменения, обеспечивая высокую гибкость и эффективность системы в динамических условиях.
В отличие от традиционных архитектур больших языковых моделей (LLM), которые полагаются исключительно на контекстное окно для удержания информации, предложенная структура непрерывного обучения активно управляет внутренним состоянием посредством внешней памяти. Это позволяет преодолеть ограничения, связанные с фиксированным размером контекста, и поддерживать более длительные и сложные цепочки рассуждений. Внешняя память функционирует как адресное пространство, где система может хранить, извлекать и обновлять информацию, необходимую для текущей задачи или для будущих взаимодействий. Такой подход позволяет модели сохранять и использовать знания, полученные на предыдущих этапах, и адаптироваться к изменяющимся условиям без потери контекста или необходимости повторного обучения.
Адаптивный Интеллект: Обучение Мыслить и Действовать
Непрерывный обучающий фреймворк (Continuous Learning Framework) включает в себя механизмы обучения обучению (learning to learn), что позволяет агенту со временем улучшать собственные алгоритмы и стратегии обучения. Это достигается путем мета-обучения, когда система не просто осваивает конкретные задачи, но и оптимизирует процесс приобретения знаний, адаптируя свои внутренние параметры и архитектуру. В результате, агент способен быстрее и эффективнее осваивать новые навыки и задачи, а также лучше обобщать полученный опыт на ранее не встречавшиеся ситуации, демонстрируя улучшенную адаптивность и производительность в динамичной среде.
Контроль процесса, осуществляемый посредством оценки промежуточных шагов рассуждений, позволяет проводить детализированную оптимизацию и предотвращать катастрофическое забывание. В рамках данной системы, оценка каждого этапа логической цепочки позволяет выявлять и корректировать ошибки на ранних стадиях, что существенно повышает точность и стабильность работы агента. Такой подход к обучению, в отличие от традиционных методов, где оценивается только конечный результат, обеспечивает более эффективное использование данных и предотвращает потерю ранее приобретенных знаний при обучении новым задачам. Оценка промежуточных этапов также позволяет выявить узкие места в логической цепи и сосредоточить усилия по оптимизации на наиболее критичных участках.
Параметрически-эффективная тонкая настройка (Parameter-Efficient Fine-Tuning, PEFT) в рамках данной системы позволяет адаптировать модель к новым задачам и предметным областям с минимальными вычислительными затратами. Вместо переобучения всех параметров модели, PEFT фокусируется на обучении лишь небольшой части параметров, либо добавляет небольшие, обучаемые модули к существующей модели. Это достигается за счет использования таких методов, как адаптеры, LoRA (Low-Rank Adaptation) и префикс-настройка. В результате, требуемый объем памяти и вычислительных ресурсов значительно снижается, позволяя быстро и эффективно развертывать модель в новых условиях, сохраняя при этом производительность, сравнимую с полной тонкой настройкой.
Замена фиксированного кода позволяет фреймворку интегрировать новые процедуры и знания без необходимости переобучения всей модели. Данный механизм предполагает, что определенные участки кода, отвечающие за конкретные функции, могут быть заменены на новые реализации без нарушения общей структуры и работоспособности системы. Это достигается путем использования стандартизированных интерфейсов и протоколов взаимодействия, что обеспечивает бесшовную интеграцию новых модулей и алгоритмов. Такой подход значительно повышает адаптивность фреймворка, позволяя ему быстро реагировать на изменения в окружающей среде и эффективно использовать новые данные и знания, минимизируя при этом вычислительные затраты и риск катастрофического забывания.
Реальное Влияние: Расширение Интеллекта до Сенсорных Сетей
Разработанная система демонстрирует способность к сложному рассуждению посредством применения в задаче обнаружения аномалий в показаниях датчиков. Она способна интегрировать данные из различных источников, включая температурные датчики, и, анализируя их взаимосвязи, выявлять неисправные устройства с высокой точностью. Данный подход позволяет перейти от простого мониторинга к интеллектуальному анализу, предсказывая возможные сбои и оптимизируя работу всей системы. В результате, повышается надежность критически важной инфраструктуры и снижаются затраты на ее обслуживание за счет своевременного выявления и устранения проблем.
В рамках разработанной системы, объединение данных, поступающих от температурных датчиков и других источников, позволяет с высокой точностью выявлять неисправности оборудования. Анализ поступающей информации, включающий сопоставление текущих показаний с историческими данными и ожидаемыми значениями, позволяет системе автоматически определять отклонения, свидетельствующие о возможных проблемах. Такой подход, в отличие от традиционных методов мониторинга, не требует ручной настройки пороговых значений для каждого датчика, что значительно упрощает обслуживание и повышает надежность системы. Выявление неисправностей на ранней стадии позволяет предотвратить более серьезные поломки и оптимизировать работу критически важной инфраструктуры, обеспечивая ее бесперебойную работу и снижая риски возникновения аварийных ситуаций.
Предложенная система демонстрирует значительный потенциал для повышения надёжности и эффективности критически важной инфраструктуры. Интегрируя сложные алгоритмы рассуждений, она способна оперативно выявлять аномалии в работе сенсорных сетей, например, обнаруживая неисправности в температурных датчиках. Это позволяет не только предотвратить потенциальные сбои в системах, зависящих от этих датчиков, но и оптимизировать их работу за счет своевременной диагностики и устранения проблем. В перспективе, подобный подход может быть масштабирован для мониторинга и управления широким спектром инфраструктурных объектов — от электростанций и транспортных сетей до систем водоснабжения и связи — обеспечивая более устойчивую и эффективную работу жизненно важных сервисов.
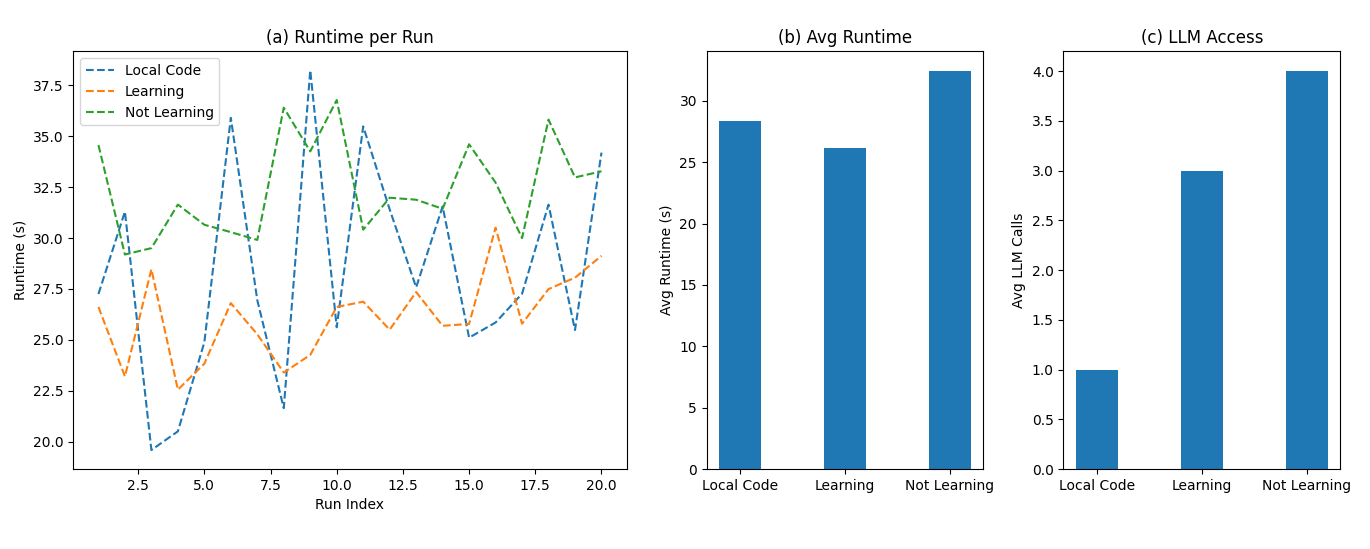
Предложенная система непрерывного обучения продемонстрировала значительное повышение эффективности при обнаружении неисправностей в сети температурных датчиков. В ходе тестирования зафиксировано снижение среднего времени выполнения задачи на 23.9%, что позволило сократить его с 32.42 секунд до 26.16 секунд. Это достигнуто благодаря способности системы к самообучению и адаптации внутренних механизмов рассуждений, что позволяет оптимизировать процесс анализа данных и более оперативно выявлять аномалии в работе оборудования. Данный результат подтверждает потенциал данной архитектуры для повышения надежности и производительности критически важной инфраструктуры, где важна быстрая и точная диагностика неисправностей.
Будущее Интеллекта Агентов: За Пределами Текущих Ограничений
Новая схема непрерывного обучения, объединяющая подходы ReAct и Toolformer, закладывает основу для создания действительно интеллектуальных агентов. Данная архитектура позволяет агентам бесшовно интегрировать рассуждения, выполнение действий и обучение, что критически важно для решения сложных задач в динамично меняющихся условиях. В отличие от традиционных систем, которые требуют перепрограммирования для адаптации к новым ситуациям, эта схема обеспечивает агентам возможность самостоятельно приобретать знания и совершенствовать свои навыки в процессе взаимодействия с окружающей средой. Такой подход позволяет не просто реагировать на изменения, но и предвидеть их, оптимизируя свои действия для достижения поставленных целей с максимальной эффективностью и гибкостью.
Современные интеллектуальные агенты демонстрируют способность к беспрепятственной интеграции рассуждений, выполнения действий и обучения, что позволяет им эффективно решать сложные задачи в меняющихся условиях. Вместо последовательного выполнения операций, агенты способны динамически адаптировать свои стратегии, анализируя результаты действий и корректируя дальнейший план. Такой подход позволяет им не только достигать поставленных целей, но и оптимизировать процесс их достижения, снижая потребность в ручном вмешательстве и повышая общую эффективность. Способность к обучению на собственном опыте и извлекаемым урокам позволяет агентам улучшать свои навыки и адаптироваться к новым, ранее не встречавшимся ситуациям, что делает их ценным инструментом для решения широкого спектра задач в различных областях — от автоматизации рутинных процессов до разработки сложных систем управления.
Дальнейшие исследования, направленные на моделирование процессов, свойственных человеческому мышлению, способны существенно расширить возможности интеллектуальных агентов. Изучение когнитивных механизмов, таких как интуиция и адаптивность, позволит создавать системы, не просто решающие задачи, но и предвосхищающие изменения в окружающей среде и эффективно реагирующие на них. Такой подход, выходящий за рамки традиционного программирования, позволит агентам не только выполнять заданные инструкции, но и проявлять гибкость и креативность в решении сложных и непредсказуемых проблем, приближая их к уровню человеческого интеллекта и открывая новые горизонты в области искусственного интеллекта.
Разработанный фреймворк продемонстрировал значительное повышение эффективности работы интеллектуальных агентов. В ходе исследований зафиксировано сокращение среднего числа взаимодействий с большими языковыми моделями (LLM) с четырех до трех. Это снижение не только упрощает процесс решения задач, но и существенно уменьшает время выполнения, что подтверждено статистической значимостью полученных результатов (p < 0.05). Данное улучшение свидетельствует о более рациональном использовании вычислительных ресурсов и открывает возможности для создания более быстрых и отзывчивых интеллектуальных систем, способных оперативно адаптироваться к изменяющимся условиям.
Исследование, представленное в статье, подчеркивает важность адаптации не только знаний, но и самого процесса мышления искусственного интеллекта. Это напоминает о сложности систем и их непредсказуемости. Тим Бернерс-Ли однажды заметил: «Веб — это не просто набор страниц, связанных гиперссылками, а система, которая развивается и меняется вместе с нами.». Подобно тому, как веб требует постоянной эволюции, чтобы оставаться актуальным, так и AI-системы нуждаются в непрерывном обучении и адаптации внутренних процессов рассуждения, чтобы эффективно функционировать в динамичной среде. Статья, по сути, демонстрирует, что истинный прогресс в AI заключается в создании систем, способных учиться думать, а не просто накапливать факты.
Что дальше?
Представленная работа, стремясь к моделированию адаптивности человеческого мышления, неизбежно сталкивается с парадоксом: система, способная к самоизменению внутренних процессов рассуждения, одновременно становится непредсказуемой. Развитие таких систем — это не конструирование идеального инструмента, а взращивание сложной экосистемы, где сбой — не ошибка, а акт очищения. Вопрос не в том, чтобы избежать отказа, а в том, чтобы понять его природу и включить в цикл обучения.
Следующим этапом представляется не столько увеличение вычислительной мощности или сложности алгоритмов, сколько исследование границ адаптивности. Где проходит граница между полезной эволюцией внутренних моделей и неконтролируемым отклонением от заданной цели? И как обеспечить, чтобы система, обучаясь “думать”, не утратила способность действовать? Идеальное решение, в котором всё предсказуемо, не оставляет места для человека.
Перспективы лежат в области создания систем, способных к рефлексии — к оценке не только результатов своих действий, но и самих процессов рассуждения. Система, которая учится учиться, должна уметь задавать вопросы о своей собственной логике. В конечном счете, задача заключается не в создании искусственного интеллекта, а в формировании искусственной самосознательности, что, возможно, является утопией — и в этом её истинная ценность.
Оригинал статьи: https://arxiv.org/pdf/2602.11516.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- Молекулярный интеллект: проверка химического мышления
- Искусственный интеллект и закон: гармония неизбежна
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Квантовые вычисления для молекул: оптимизация ресурсов
- Стиль сквозь века: математика искусства
- Искусственный интеллект, который ищет сам: новая стратегия обучения
- Favia: Искусственный интеллект на страже безопасности кода
- Квантовая устойчивость к ошибкам: новый взгляд на исправление вставок и удалений
- От мгновений к движению: Новая эра предсказания структуры белков
2026-02-13 23:38