Автор: Денис Аветисян
Исследователи предлагают метод, стимулирующий языковые модели к более полному осмыслению задачи, что позволяет им находить более эффективные решения в сложных сценариях.
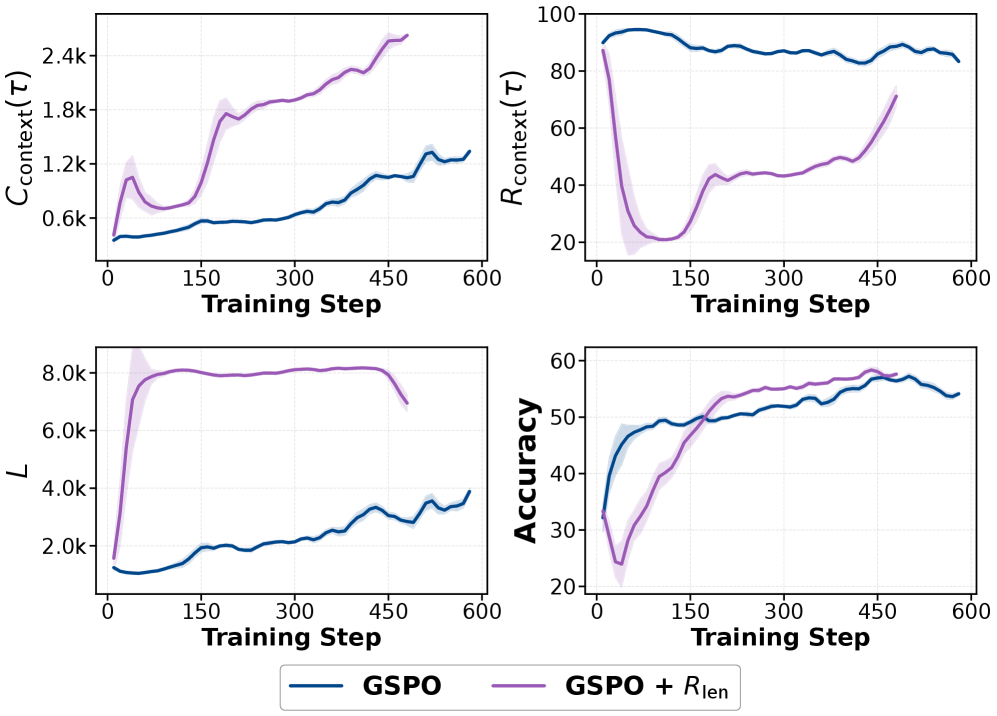
Разработанный метод Length-Incentivized Exploration (LIE) позволяет преодолеть ‘ловушку поверхностного исследования’ и улучшить производительность языковых моделей при решении задач, требующих глубокого логического мышления.
Несмотря на успехи больших языковых моделей, их способность к масштабированию в процессе тестирования ограничена недостаточной глубиной исследования пространства возможных решений. В работе ‘Think Longer to Explore Deeper: Learn to Explore In-Context via Length-Incentivized Reinforcement Learning’ предложен метод Length-Incentivized Exploration (LIE), основанный на обучении с подкреплением, который стимулирует модели к более широкому поиску состояний рассуждений и преодолению так называемой «ловушки поверхностного исследования». LIE использует вознаграждение, зависящее от длины генерируемой последовательности, и штраф за избыточность, что позволяет максимизировать покрытие состояний за два шага. Повысит ли предложенный подход эффективность языковых моделей в решении сложных задач, требующих глубокого анализа и рассуждений?
Ограничения масштаба: Поиск логики в больших языковых моделях
Несмотря на впечатляющие успехи больших языковых моделей в различных областях, надежное рассуждение остается сложной задачей, обусловленной фундаментальными вычислительными ограничениями. По мере увеличения объема данных и параметров модели, потребность в вычислительных ресурсах растет экспоненциально, что создает препятствия для углубленного анализа и поиска сложных логических связей. Это особенно заметно при решении задач, требующих многоступенчатых умозаключений, где ограниченность ресурсов может приводить к упрощенным или неполным решениям. Таким образом, прорыв в области рассуждений в больших языковых моделях требует не только увеличения масштаба, но и разработки новых, более эффективных алгоритмов и архитектур, способных преодолеть эти вычислительные барьеры.
Традиционное увеличение масштаба языковых моделей, заключающееся в наращивании параметров и объёма данных, часто приводит к так называемой “ловушке поверхностного исследования”. Вместо того, чтобы углубляться в сложные цепочки логических выводов, модели склонны к быстрому, но неполному освоению наиболее очевидных закономерностей. Это проявляется в затруднениях при решении задач, требующих последовательных, многоступенчатых умозаключений, где даже небольшая ошибка на раннем этапе может привести к полному отклонению от верного решения. В результате, несмотря на впечатляющие способности в обработке текста, модели оказываются неспособны к построению надёжных и продолжительных рассуждений, ограничивая их возможности в областях, требующих глубокого аналитического мышления и логической последовательности.
Ограничения больших языковых моделей особенно ярко проявляются при решении сложных задач, требующих последовательного проведения нескольких логических выводов. В подобных ситуациях модели часто демонстрируют снижение точности по мере увеличения длины цепочки рассуждений, сталкиваясь с трудностями в поддержании когерентности и предотвращении накопления ошибок. Это связано с тем, что каждая последующая инференция опирается на результат предыдущей, и даже незначительные неточности могут критически повлиять на конечный результат. Исследования показывают, что модели, несмотря на впечатляющие возможности в обработке естественного языка, часто испытывают трудности с задачами, требующими не просто извлечения информации, а её активного использования для построения логически обоснованных и последовательных заключений, что ограничивает их применение в областях, требующих надёжного и глубокого рассуждения.
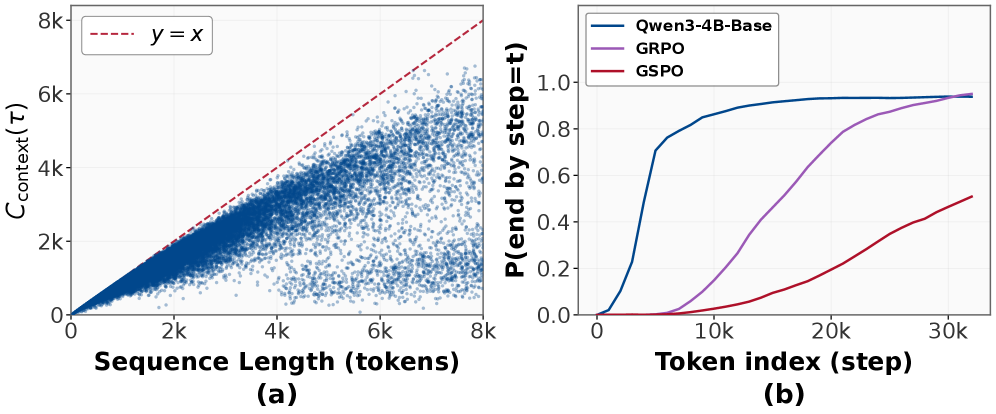
Исследование в контексте: Путь к более глубоким рассуждениям
Стратегия “Исследование в контексте” (In-Context Exploration) представляет собой подход к улучшению процесса рассуждений, основанный на активном исследовании и уточнении гипотез внутри заданного контекста. В отличие от традиционных методов, предполагающих однократное применение логических цепочек, данный подход фокусируется на последовательном развитии и оценке различных вариантов рассуждений в рамках одной и той же задачи. Это достигается путем генерации множества гипотез, их проверки и последующей итеративной доработки, что позволяет более полно охватить пространство возможных решений и повысить надежность получаемых выводов. Основная цель — не просто найти ответ, но и исследовать различные пути к нему, что способствует более глубокому пониманию проблемы и повышению обобщающей способности системы.
Метод последовательного масштабирования (Sequential Scaling) используется для приоритизации развернутых цепочек рассуждений, что позволяет преодолеть ограничения, свойственные поверхностному исследованию (shallow exploration). В рамках данного подхода, модели искусственного интеллекта не просто генерируют единичный ответ, а последовательно расширяют и уточняют свои рассуждения, увеличивая длину цепочки логических выводов. Это достигается путем постепенного увеличения вычислительных ресурсов, выделяемых для каждой итерации рассуждений, что позволяет модели глубже анализировать проблему и избегать преждевременной остановки на неполных или ошибочных выводах. В отличие от традиционных методов, где акцент делается на быстрой генерации ответов, последовательное масштабирование направлено на достижение более качественного и обоснованного решения путем всестороннего исследования пространства возможных рассуждений.
Ключевым показателем эффективности стратегии исследования в контексте является понятие «Покрытие состояний» (State Coverage). Оно используется в качестве прокси-метрики для оценки разнообразия и качества исследованных цепочек рассуждений. Покрытие состояний определяет, насколько полно алгоритм исследует различные возможные состояния и направления в процессе поиска решения. Высокое покрытие состояний указывает на более широкое и всестороннее исследование, что потенциально ведет к более надежным и обоснованным выводам. Вместо прямой оценки качества каждого отдельного шага рассуждений, покрытие состояний оценивает разнообразие путей рассуждений, предполагая, что более разнообразные пути с большей вероятностью охватят релевантные аспекты проблемы и приведут к оптимальному решению. Данная метрика позволяет эффективно оценивать эффективность алгоритма без необходимости ручной оценки каждого шага.
Оптимизация исследования: Стимулирование длины и подавление избыточности
Для снижения вычислительных затрат и повышения эффективности рассуждений, внедрена методика “Оптимизированного исследования с учетом длительности” (Length-Incentivized Exploration). Данный подход направлен на активное стимулирование модели к генерации более длинных цепочек рассуждений, что позволяет исследовать более широкий спектр возможных решений. В отличие от стандартных методов, которые могут приводить к преждевременной остановке или поверхностному анализу, эта методика способствует более глубокому и всестороннему исследованию пространства поиска, что потенциально приводит к более качественным результатам при сохранении приемлемых вычислительных ресурсов.
Метод стимулирования исследования объединяет в себе «Награду за длину» и «Штраф за избыточность». Награда за длину (R_{length}) пропорциональна длине траектории рассуждений, побуждая модель генерировать более развернутые цепочки логических шагов. Штраф за избыточность (P_{redundancy}) вычисляется на основе повторения уже пройденных состояний или шагов в процессе рассуждений, тем самым снижая вероятность циклического поведения и стимулируя исследование новых направлений. Комбинация этих двух компонентов позволяет активно направлять процесс рассуждений, поощряя как развернутость, так и новизну.
Внедрение предложенного подхода позволяет активно направлять модель к приоритезации новых и потенциально более содержательных путей рассуждений. Это достигается за счет стимулирования исследования более длинных цепочек логических выводов и одновременного снижения вероятности повторения уже пройденных шагов. Такой механизм способствует поиску нестандартных решений и более глубокому анализу задачи, что особенно важно для сложных сценариев, требующих многоэтапных рассуждений и выявления неочевидных связей.
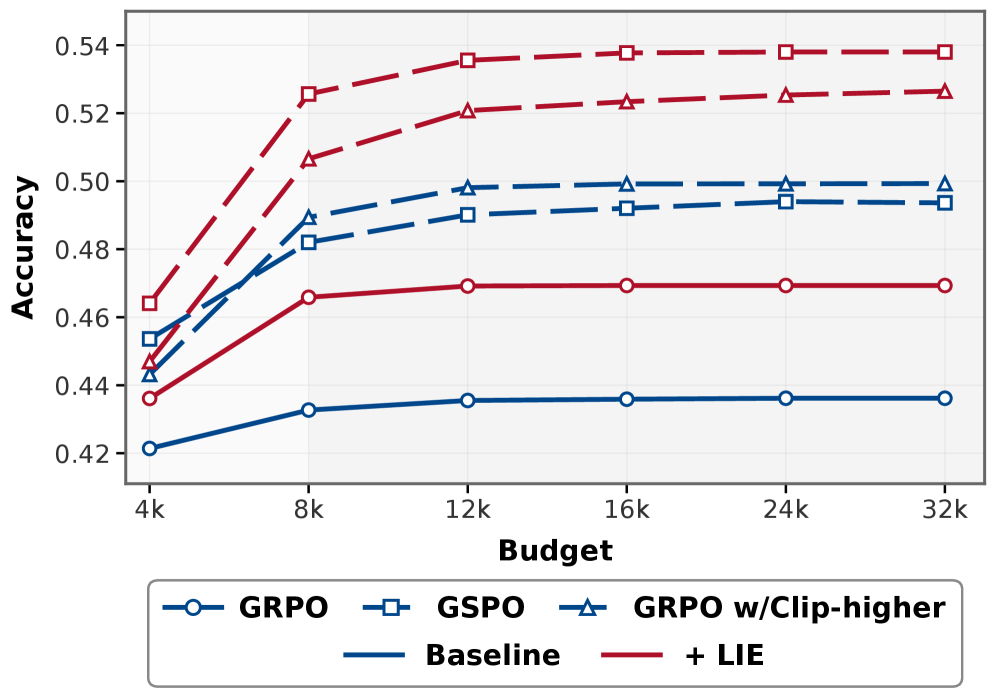
Экспериментальная валидация и производительность модели
В качестве базовой модели был использован ‘Qwen3-4B-Base’, который подвергся предварительному обучению и точной настройке на специализированных наборах данных, включающих ‘DAPO-Math-17k’, ‘Polaris’ и ‘DeepMath-5k’. Набор ‘DAPO-Math-17k’ содержит 17 тысяч математических задач, ‘Polaris’ представляет собой коллекцию задач, требующих логического вывода, а ‘DeepMath-5k’ включает 5 тысяч математических задач, требующих более глубокого анализа и доказательств. Использование этих наборов данных позволило улучшить способность модели к решению математических задач различной сложности и типов.
Обучение модели осуществлялось с применением метода обучения с подкреплением (Reinforcement Learning) на основе алгоритма Group Relative Policy Optimization. Для улучшения процесса исследования пространства решений и предотвращения преждевременной сходимости к локальным оптимумам была внедрена стратегия Length-Incentivized Exploration, стимулирующая исследование более длинных цепочек рассуждений. Данный подход позволяет модели более эффективно находить оптимальные решения, балансируя между использованием уже известных стратегий (exploitation) и исследованием новых возможностей (exploration).
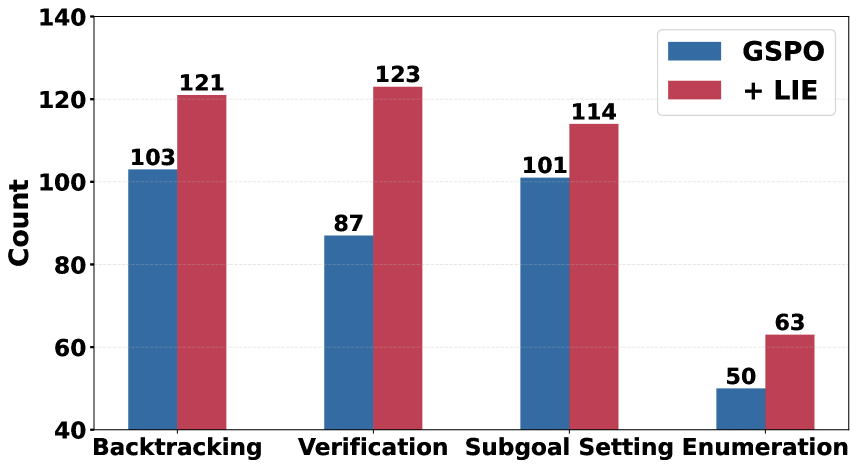
Результаты экспериментов показали, что предложенный подход позволил повысить точность логических рассуждений в рамках используемых данных на 4.4%, а также точность рассуждений на данных, не использованных в процессе обучения, на 2.7%. Наблюдалось увеличение средней глубины графа рассуждений с 13.8 до 14.75, а также увеличение его средней ширины с 2.15 до 2.30. Данные изменения свидетельствуют об эффективности сбалансированной стратегии исследования и использования информации, что положительно сказывается на сложности и структуре процесса логических умозаключений.

Перспективы развития: К более эффективным рассуждениям
Успешное применение методов исследования на основе подсчета и исследования в контексте указывает на перспективность их интеграции с параллельным масштабированием для значительного ускорения процесса рассуждений. Данный подход предполагает одновременное использование нескольких вычислительных ресурсов для оценки различных вариантов развития событий, что позволяет модели быстро находить наиболее вероятные и логичные решения. Комбинирование этих стратегий позволит не только повысить скорость обработки информации, но и расширить возможности модели в решении сложных задач, требующих многоступенчатого анализа и принятия решений. В результате, ускорение рассуждений достигается за счет параллельной обработки информации и эффективного использования вычислительных ресурсов, что открывает новые горизонты в области искусственного интеллекта.
Исследования показывают, что адаптивные механизмы вознаграждения и динамические штрафы могут существенно повысить устойчивость и обобщающую способность языковых моделей. Вместо использования фиксированных параметров, система способна корректировать вознаграждение за успешные шаги и штрафы за ошибки в процессе рассуждений, основываясь на текущем контексте и прогрессе. Такой подход позволяет модели более эффективно справляться с неопределенностью и сложными задачами, адаптируясь к различным сценариям и избегая зацикливания на неоптимальных решениях. Эксперименты демонстрируют, что динамическая корректировка этих параметров способствует более гибкому и надежному процессу рассуждений, позволяя модели лучше обобщать полученный опыт на новые, ранее не встречавшиеся ситуации и повышать общую точность принимаемых решений.
Данная работа закладывает основу для создания больших языковых моделей (LLM), способных к осуществлению сложных, многоступенчатых рассуждений с повышенной эффективностью и точностью. Исследование демонстрирует потенциал для разработки систем, которые не просто генерируют текст, но и способны последовательно анализировать информацию, выводить логические заключения и решать задачи, требующие нескольких шагов для достижения результата. Развитие подобных моделей позволит значительно расширить область их применения, включая научные исследования, анализ данных и автоматизированное принятие решений, открывая новые горизонты для искусственного интеллекта и его интеграции в различные сферы человеческой деятельности.
В представленной работе авторы стремятся к созданию систем, способных к глубокому исследованию пространства решений, избегая поверхностного подхода, который часто ограничивает возможности языковых моделей. Эта задача созвучна принципам, которые подчеркивают важность ясности и простоты в проектировании систем. Барбара Лисков однажды заметила: «Программы должны быть такими, чтобы их можно было понять, не читая исходный код». Подобно этому, система, требующая сложных инструкций для раскрытия своего потенциала, уже проиграла. Работа над Length-Incentivized Exploration (LIE) направлена на то, чтобы модель самостоятельно расширяла границы своего понимания, находя оптимальные решения без необходимости в излишних указаниях. По сути, речь идет о создании системы, которая, подобно элегантному алгоритму, демонстрирует свою эффективность без необходимости в детальном объяснении.
Куда Ведет Этот Путь?
Предложенный подход, побуждающий языковые модели к более глубокому исследованию контекста, безусловно, выявляет уязвимость — “мелководную ловушку исследования”. Однако, решение этой проблемы, хоть и полезное, не устраняет фундаментальный вопрос: действительно ли количественное расширение охвата состояний автоматически ведет к более осмысленным выводам? Простота — признак интеллекта, а не ограничений, и необходимо помнить, что увеличение числа шагов не гарантирует нахождение верного пути.
Будущие исследования должны сосредоточиться на разработке более тонких метрик, оценивающих качество исследованных состояний, а не только их количество. Вместо слепого увеличения длины рассуждений, представляется важным выявлять и отсеивать тривиальные или нерелевантные пути. Иначе, мы рискуем создать систему, способную бесконечно перебирать варианты, не приближаясь к истине.
Более того, стоит задуматься о связи между длиной рассуждений и самой архитектурой языковых моделей. Возможно, текущие модели просто не способны эффективно использовать информацию, полученную в результате глубокого исследования контекста. Истинное решение может заключаться не в усовершенствовании алгоритмов обучения, а в создании принципиально новых архитектур, способных к более глубокому и осмысленному анализу.
Оригинал статьи: https://arxiv.org/pdf/2602.11748.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- Квантовые вычисления для молекул: оптимизация ресурсов
- Искусственный интеллект и закон: гармония неизбежна
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Молекулярный интеллект: проверка химического мышления
- Искусственный интеллект, который ищет сам: новая стратегия обучения
- Повышение точности AI-детекторов MIMO: новый подход к снижению неопределенности
- Мир в коде: Новая эра симуляций с открытым исходным кодом
- Искусственный интеллект проектирует алгоритмы: новый подход к автоматизации
- Математика и Искусственный Интеллект: Новые Горизонты Открытий
2026-02-14 00:57