Автор: Денис Аветисян
Исследователи представили MiniCPM-SALA — модель, сочетающую в себе разреженное и линейное внимание для повышения скорости и эффективности обработки очень длинных последовательностей данных.
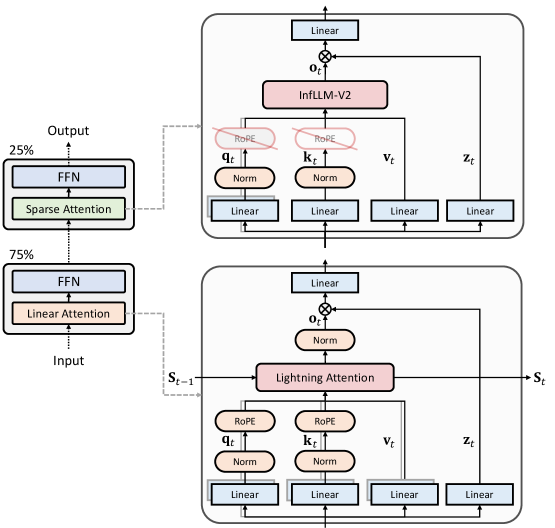
Гибридная архитектура MiniCPM-SALA позволяет значительно снизить потребление памяти и ускорить процесс вывода по сравнению с традиционными трансформаторными моделями при работе с большими объемами текста.
По мере увеличения масштабов языковых моделей возникает противоречие между необходимостью обработки всё более длинных контекстов и ограничениями вычислительных ресурсов. В работе ‘MiniCPM-SALA: Hybridizing Sparse and Linear Attention for Efficient Long-Context Modeling’ представлена новая гибридная архитектура, сочетающая разреженное и линейное внимание для эффективной обработки ультрадлинных последовательностей. Модель MiniCPM-SALA демонстрирует значительное повышение скорости вывода и снижение потребления памяти при сохранении общей производительности, достигая ускорения до 3.5x на последовательностях длиной 256K токенов. Сможет ли данный подход преодолеть существующие ограничения и открыть новые возможности для приложений, требующих обработки контекстов в миллион и более токенов?
Преодолевая границы масштабируемости: Ограничения полного внимания
Современные большие языковые модели произвели революцию в области обработки естественного языка, однако их эффективность достигает плато при увеличении длины обрабатываемой последовательности. Эта проблема обусловлена квадратичной сложностью механизма полного внимания — ключевого компонента этих моделей. По мере роста длины входных данных, вычислительные затраты и потребление памяти растут экспоненциально, что ограничивает возможность обработки действительно длинных текстов и затрудняет извлечение полезной информации из больших объемов данных. В результате, несмотря на значительные успехи в области NLP, модели сталкиваются с серьезными ограничениями при работе с текстами, превышающими определенный порог длины, что требует разработки новых архитектур и методов внимания для преодоления этого фундаментального препятствия.
Основная проблема, ограничивающая масштабируемость больших языковых моделей, заключается в колоссальных требованиях к памяти, предъявляемых к кешу ключей и значений (KV-кешу). Этот кеш, необходимый для механизма внимания, растет пропорционально как длине обрабатываемой последовательности, так и размеру самой модели. Таким образом, при увеличении длины текста или усложнении модели, потребность в памяти возрастает экспоненциально, что быстро становится узким местом. O(n^2) — такая сложность алгоритма внимания, где n — длина последовательности, и это делает обработку очень длинных текстов крайне ресурсоемкой и, в конечном итоге, невозможной на доступном оборудовании. Преодоление этой проблемы требует разработки новых архитектур и механизмов внимания, способных эффективно управлять и использовать память при работе с ультра-длинными контекстами.
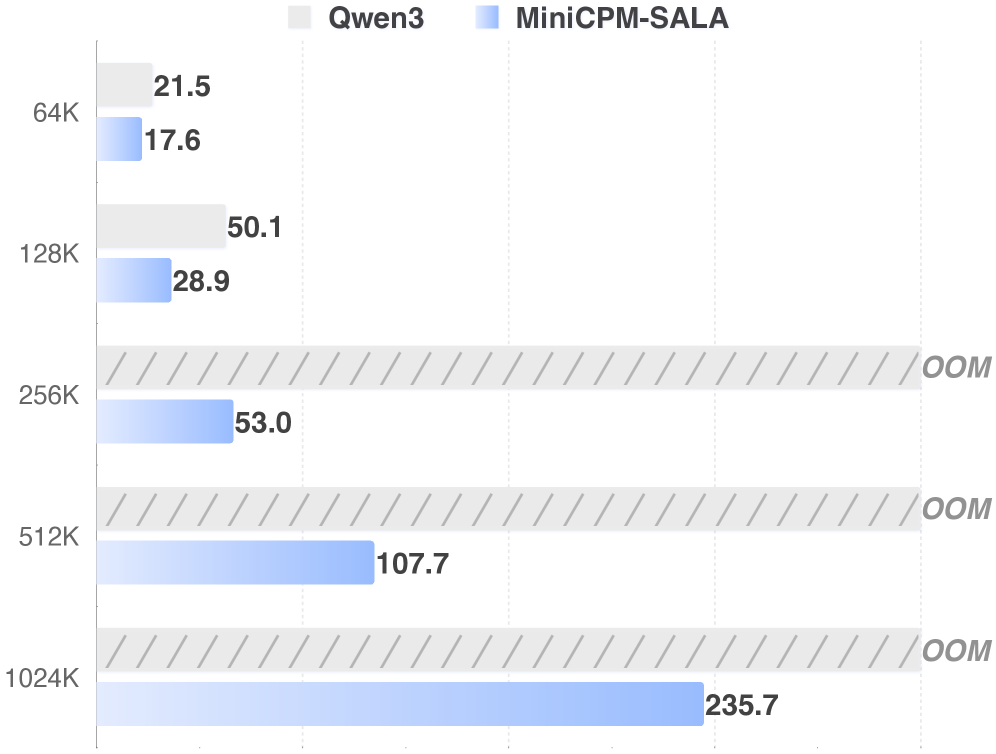
Традиционные подходы к обработке естественного языка сталкиваются с серьезными трудностями при работе с “сверхдлинными” контекстами, поскольку вычислительная сложность препятствует эффективному логическому выводу и извлечению информации. Например, модель Qwen3-8B демонстрирует ограниченные возможности при обработке контекстов, превышающих определенную длину, в то время как MiniCPM-SALA успешно справляется с последовательностями до 1 миллиона токенов. Данное различие подчеркивает, что простое увеличение размера модели не всегда приводит к улучшению работы с длинными текстами, и требует разработки инновационных архитектур и механизмов внимания, способных эффективно обрабатывать и использовать информацию из больших объемов данных.
Ограничения, связанные с масштабированием полновнимания в больших языковых моделях, обуславливают необходимость разработки инновационных архитектур и механизмов внимания. Исследователи активно работают над решениями, позволяющими преодолеть квадратичную сложность вычислений, которая становится критической при работе с длинными последовательностями текста. Эти усилия включают в себя поиск альтернативных подходов к обработке информации, таких как разреженное внимание, линейное внимание и рекуррентные механизмы, которые стремятся снизить потребление памяти и вычислительные затраты, не жертвуя при этом качеством генерации и понимания текста. Успешная реализация подобных инноваций откроет путь к созданию языковых моделей, способных эффективно обрабатывать и использовать огромные объемы информации, значительно расширяя их возможности в различных областях применения.
Гибридные архитектуры: Новый путь к эффективности
MiniCPM-SALA представляет собой новую гибридную архитектуру, разработанную для решения проблем масштабируемости, присущих механизмам полного внимания (full attention). Традиционные модели Transformer, использующие полное внимание, демонстрируют квадратичную сложность по отношению к длине последовательности, что ограничивает их применение к длинным текстам. MiniCPM-SALA преодолевает это ограничение за счет интеграции разреженного (sparse) и линейного внимания, что позволяет снизить вычислительную сложность без существенной потери информативности. Данный подход обеспечивает возможность обработки более длинных последовательностей с меньшими вычислительными затратами, что критически важно для задач, требующих анализа больших объемов текстовых данных.
Архитектура MiniCPM-SALA использует стратегическое сочетание разреженного (sparse) и линейного механизмов внимания для снижения вычислительной сложности, сохраняя при этом важную информацию. В отличие от традиционного механизма полного внимания, требующего O(n^2) операций, где n — длина последовательности, комбинация разреженного и линейного внимания позволяет приблизиться к линейной сложности O(n). Разреженное внимание выборочно фокусируется на наиболее релевантных частях входной последовательности, в то время как линейное внимание применяет линейные преобразования к векторам запросов и ключей, что значительно снижает вычислительные затраты без существенной потери точности. Такой подход позволяет обрабатывать более длинные последовательности и масштабировать модель для задач, требующих анализа больших объемов данных.
Для адаптации предварительно обученной архитектуры Transformer к гибридной конфигурации MiniCPM-SALA используется метод непрерывного обучения. Этот подход позволяет значительно сократить затраты на обучение — на 75% по сравнению с обучением модели с нуля. Непрерывное обучение позволяет использовать знания, полученные моделью в процессе предварительного обучения, и адаптировать их к новой, гибридной структуре, что обеспечивает максимальную производительность при значительно меньших вычислительных ресурсах и временных затратах. В процессе адаптации происходит тонкая настройка параметров модели для эффективной работы со смешанным механизмом внимания.
Для повышения стабильности и выразительности модели MiniCPM-SALA применяются методы QK-Нормализации и Output Gates. QK-Нормализация, применяемая к матрицам запросов (Q) и ключей (K), позволяет нормализовать их распределения, что способствует более стабильному процессу обучения и предотвращает затухание или взрыв градиентов. Output Gates, представляющие собой слои, управляющие потоком информации, позволяют модели динамически выбирать, какая информация из промежуточных слоев должна быть передана на следующий уровень, повышая ее способность к выражению сложных зависимостей и улучшая общую производительность. Эти техники позволяют более эффективно использовать возможности гибридной архитектуры, сочетающей разреженное и линейное внимание.
Строгая оценка: Бенчмаркинг производительности при работе с ультрадлинными контекстами
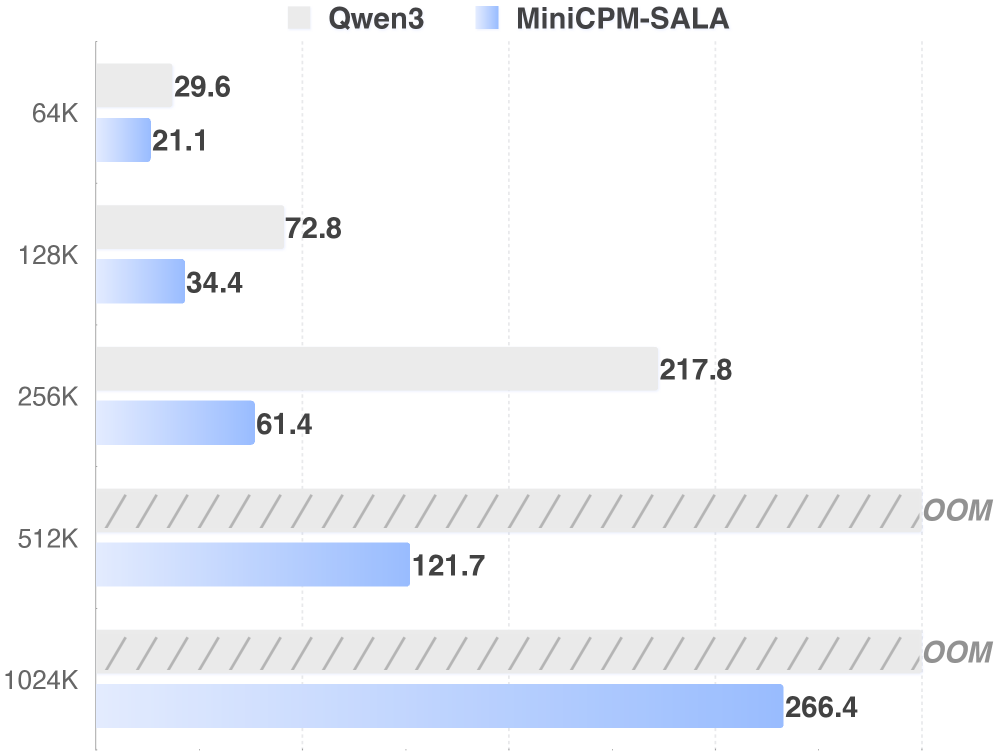
Для оценки производительности MiniCPM-SALA использовались общепризнанные бенчмарки для работы с длинным контекстом, включая MRCR (Multi-hop Reading Comprehension Reasoning), RULER (Reasoning Using Long-Range Context) и NoLiMa (Novel Long-context Information Retrieval and Matching). Эти бенчмарки позволяют объективно сравнить способность модели к обработке и анализу больших объемов информации, требующих понимания взаимосвязей между отдаленными фрагментами текста. Использование стандартизированных наборов данных обеспечивает воспроизводимость результатов и возможность сопоставления с другими моделями в области обработки естественного языка.
Модель MiniCPM-SALA демонстрирует существенное улучшение в обработке ультра-длинных последовательностей, что подтверждается результатами тестов на стандартных бенчмарках. На бенчмарке RULER с контекстом 128K модель достигла точности 89.37%, а на бенчмарке NoLiMa с таким же контекстом — 23.86%. Эти показатели свидетельствуют о превосходстве модели в задачах, требующих обработки и анализа больших объемов информации, по сравнению с существующими подходами в данной области.
Архитектура MiniCPM-SALA эффективно использует разреженное внимание (InfLLM-V2) и линейное внимание (Lightning Attention) для обработки длинных последовательностей. Реализация этих механизмов внимания оптимизирована на уровне слоев с помощью HALO (High-order Attention with Layer Optimization), что позволяет снизить вычислительные затраты и повысить эффективность использования памяти. Разреженное внимание фокусируется на наиболее релевантных частях входной последовательности, в то время как линейное внимание обеспечивает более быструю обработку длинных контекстов. Комбинация этих подходов, усиленная оптимизацией HALO, позволяет модели эффективно масштабироваться для обработки ультра-длинных последовательностей без значительного увеличения вычислительных ресурсов.
Оптимизация позиционного кодирования посредством HyPE (Hypothesis-based Positional Encoding) позволила улучшить моделирование долгосрочных зависимостей в последовательностях. В результате, средняя точность модели на длинных контекстах составила 38.97. При оценке на последовательностях длиной 1 миллион токенов, MiniCPM-SALA продемонстрировала точность 81.6, превзойдя показатели модели Qwen3-Next-80B-A3B-Instruct, чей результат составил 80.3.
К практической реализации: Квантизация и будущие направления
Для повышения практической применимости, MiniCPM-SALA подверглась оптимизации посредством квантизации GPTQ INT4, что позволило существенно уменьшить размер модели и увеличить скорость вывода. Данный подход заключается в представлении весов нейронной сети с использованием 4-битных целых чисел, что снижает требования к памяти и вычислительным ресурсам. В результате, модель становится более доступной для развертывания на устройствах с ограниченными ресурсами, таких как мобильные телефоны или встроенные системы, открывая новые возможности для широкого спектра приложений, требующих обработки естественного языка.
Оптимизация модели MiniCPM-SALA посредством квантизации GPTQ INT4 открывает возможности для её развертывания на устройствах с ограниченными ресурсами, таких как мобильные телефоны или встроенные системы. Это значительно расширяет доступ к передовым языковым моделям для более широкой аудитории и позволяет интегрировать их в приложения, где ранее требовались значительные вычислительные мощности. Возможность запуска модели на менее мощном оборудовании не только снижает затраты на инфраструктуру, но и способствует развитию новых сценариев использования, включая локальную обработку данных и персонализированные приложения, работающие непосредственно на пользовательских устройствах.
Полученные результаты демонстрируют значительный потенциал для масштабирования больших языковых моделей (LLM) до обработки контекстов существенно большей длины без существенного увеличения вычислительных затрат. В частности, оптимизированная архитектура MiniCPM-SALA позволяет достичь 3.5-кратного ускорения процесса инференса при работе с контекстами в 256 тысяч токенов по сравнению с моделью Qwen3-8B. Такое повышение эффективности открывает возможности для применения LLM в задачах, требующих анализа и генерации текста на основе обширной информации, и делает перспективным создание моделей, способных понимать и обрабатывать сложные, многослойные тексты с высокой скоростью и точностью.
Дальнейшие исследования направлены на усовершенствование гибридной архитектуры модели и изучение инновационных методов моделирования долгосрочных зависимостей. Предварительные результаты демонстрируют значительный прогресс в различных бенчмарках: HumanEval (95.12%), MBPP (89.11%), AIME24 (83.75%) и AIME25 (78.33%). Эти показатели свидетельствуют о перспективности предложенного подхода для создания более эффективных и производительных больших языковых моделей, способных успешно решать сложные задачи, требующие анализа информации на больших расстояниях.
Исследование представляет собой элегантный пример оптимизации сложной системы. Авторы MiniCPM-SALA демонстрируют, что упрощение внимания за счет гибридного подхода — сочетания разреженного и линейного внимания — позволяет добиться значительного прироста в скорости вывода и экономии памяти при работе с ультра-длинными контекстами. Это соответствует принципу, что структура определяет поведение: изменяя способ обработки информации, можно кардинально улучшить производительность системы. Как однажды заметила Грейс Хоппер: «Лучший способ предсказать будущее — это создать его». В данном случае, создавая инновационную архитектуру внимания, исследователи формируют будущее обработки длинных последовательностей.
Куда Далее?
Представленная работа, демонстрируя эффективность гибридной архитектуры разреженного и линейного внимания, лишь подчеркивает фундаментальную дилемму: оптимизация одной части системы неизбежно порождает новые точки напряжения. Ускорение вывода и снижение потребления памяти — ценные достижения, однако они не решают проблему самой природы трансформаторов, склонных к квадратичной сложности при работе с длинными контекстами. Архитектура — это поведение системы во времени, а не схема на бумаге; и MiniCPM-SALA, безусловно, демонстрирует улучшенное поведение, но остается лишь шагом на пути к более элегантному решению.
Перспективным направлением представляется не только дальнейшая оптимизация существующих механизмов внимания, но и пересмотр самой концепции контекста. Вместо того чтобы пытаться захватить всю историю последовательности, возможно, стоит сосредоточиться на выявлении и сохранении лишь наиболее релевантной информации, подобно тому, как это делает биологический интеллект. Успех в этой области потребует отхода от чисто перцептивных моделей в сторону систем, способных к активному обучению и построению абстракций.
Неизбежно, будущие исследования столкнутся с необходимостью преодоления разрыва между теоретической элегантностью и практической применимостью. Любая оптимизация, даже самая удачная, является компромиссом, и понимание этих компромиссов — ключ к созданию действительно устойчивых и масштабируемых систем обработки длинных последовательностей. Поиск простоты и ясности, а не слепое наращивание сложности, — вот истинная задача, стоящая перед исследователями в этой области.
Оригинал статьи: https://arxiv.org/pdf/2602.11761.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- Искусственный интеллект и закон: гармония неизбежна
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Квантовые вычисления для молекул: оптимизация ресурсов
- Молекулярный интеллект: проверка химического мышления
- Восстановление рейтингов: Машинное обучение для неполных данных
- Проверка свойств бесконечных семейств систем: новый подход
- Видео-рассуждения: готовы ли модели выйти за рамки лаборатории?
- Видеоредактирование по запросу: Новый подход к точности и связности
- Топoлогические формы и тайны Вселенной
2026-02-14 02:47