Автор: Денис Аветисян
Новое исследование предлагает метод обнаружения, использовались ли конкретные данные для обучения больших языковых моделей, анализируя закономерности в их процессе рассуждений.

Предложен алгоритм Min-kkNN Distance для выявления следов обучения на основе структурной конвергенции траекторий рассуждений больших языковых моделей, обученных с подкреплением на основе обратной связи от человека.
Несмотря на успехи обучения современных моделей рассуждений с помощью обучения с подкреплением и верифицируемыми наградами (RLVR), вопрос о возможном загрязнении эталонных наборов данных остаётся открытым. В работе ‘Detecting RLVR Training Data via Structural Convergence of Reasoning’ представлен новый метод обнаружения примеров, на которых обучалась модель RLVR, основанный на анализе структурной конвергенции генерируемых траекторий рассуждений. Предложенный детектор Min-kNN Distance, не требующий доступа к параметрам модели или вероятностям токенов, выявляет снижение разнообразия ответов на знакомые запросы. Способен ли этот простой чёрный ящик эффективно отделить «увиденные» примеры от «неувиденных» и обеспечить более надежную оценку обобщающей способности моделей рассуждений?
Пределы масштабирования: Рассуждения в больших языковых моделях
Недавние достижения в области больших языковых моделей демонстрируют впечатляющие возможности в обработке и генерации текста, однако, несмотря на кажущуюся интеллектуальность, они зачастую сталкиваются с трудностями при решении сложных задач, требующих глубокого логического мышления. Модели преуспевают в распознавании и воспроизведении поверхностных закономерностей, но не способны к настоящему умозаключению или абстрактному мышлению. Это проявляется в неспособности корректно отвечать на вопросы, требующие комбинирования информации из разных источников, или в совершении логических ошибок при анализе сложных сценариев. Хотя модели могут генерировать грамматически правильные и стилистически связные тексты, их понимание смысла часто оказывается поверхностным, ограничивая их способность к решению задач, выходящих за рамки простого сопоставления шаблонов.
Несмотря на то, что закономерности масштабирования демонстрируют корреляцию между размером языковой модели и ее способностями, исследования показывают, что простое увеличение числа параметров не всегда приводит к существенному улучшению навыков логического мышления. Увеличение масштаба, хоть и полезно для запоминания и воспроизведения информации, зачастую не решает фундаментальных проблем, связанных с пониманием причинно-следственных связей или способностью к абстрактному мышлению. Это указывает на необходимость поиска новых архитектурных решений, которые позволят моделям не просто хранить больше данных, но и эффективно использовать их для решения сложных задач, требующих глубокого анализа и обобщения информации. Вместо дальнейшего увеличения размеров, исследователи фокусируются на разработке инновационных структур, способных имитировать более сложные когнитивные процессы.
Существует серьезная проблема, связанная с потенциальным загрязнением оценочных наборов данных примерами из обучающих выборок. Это означает, что модели искусственного интеллекта могут демонстрировать высокие результаты на тестах не из-за истинного понимания и способности к рассуждению, а из-за того, что они уже “увидели” эти примеры во время обучения. Такое “загрязнение” приводит к завышенным показателям производительности, искажающим реальную способность модели к обобщению и применению знаний в новых, незнакомых ситуациях. В результате, оценка прогресса в области искусственного интеллекта может быть неточной, а разработка действительно интеллектуальных систем — затруднена, поскольку модель может успешно решать задачи, которые ей уже известны, но испытывать трудности с чем-то новым.
Обучение с подкреплением с проверяемыми наградами: Новый подход
Обучение с подкреплением с проверяемыми наградами (RLVR) представляет собой перспективный подход, заключающийся в тренировке моделей на задачах, результаты которых могут быть автоматически проверены. Это позволяет формировать у модели корректные пути рассуждений, поскольку награда выдается только за достижение проверяемо верного результата. В отличие от традиционного обучения с подкреплением, где награда может быть субъективной или неточной, RLVR обеспечивает четкий и объективный сигнал для обучения, стимулируя модель к поиску решений, которые можно доказать как правильные. Такой подход особенно важен для задач, требующих логического мышления и обоснования ответов, поскольку он направлен на развитие не просто способности предсказывать, а именно способности рассуждать и доказывать правильность своих выводов.
В рамках обучения с подкреплением с проверяемыми наградами (RLVR) для оптимизации моделей используются алгоритмы DAPO (Differentially Private Online) и GRPO (Gradient-based Policy Optimization). Эти алгоритмы расширяют возможности генерации цепочки рассуждений (Chain-of-Thought Generation) путем акцентирования внимания на достижении доказательно верных решений. DAPO и GRPO позволяют обучать модели, способные не просто предсказывать ответы, но и генерировать последовательности шагов, которые можно верифицировать как логически корректные, обеспечивая тем самым более надежные и интерпретируемые результаты. Оптимизация с использованием этих алгоритмов направлена на максимизацию вероятности получения решений, подтвержденных автоматизированными системами проверки.
В отличие от традиционных моделей машинного обучения, ориентированных на предсказание результата, подход, используемый в Reinforcement Learning with Verifiable Rewards (RLVR), направлен на создание моделей, способных демонстрировать процесс рассуждения, приводящий к ответу. Это достигается путем обучения моделей решению задач, где корректность ответа может быть автоматически проверена, что стимулирует развитие не просто способности выдавать правильный ответ, а способности обосновывать его логически. В результате, модель предоставляет не только финальный результат, но и последовательность шагов, подтверждающих его корректность, что обеспечивает прозрачность и возможность верификации принятых решений.
Обнаружение использования обучающих данных: Метод минимального расстояния до k-ближайших соседей
Оценка моделей, обученных с использованием обучения с подкреплением на основе обратной связи от человека (RLVR), сталкивается с серьезной проблемой: возможностью неявного запоминания обучающих данных. Это приводит к искусственно завышенным показателям производительности, поскольку модель, вместо того чтобы демонстрировать обобщающую способность, просто воспроизводит информацию из тренировочного набора. Выявление такой «переобученности» критически важно для достоверной оценки качества модели и предотвращения ее использования в ситуациях, где требуется генерация новых, а не просто воспроизводимых ответов. Неспособность обнаружить запоминание данных может привести к ошибочным выводам о реальных возможностях модели и ее применимости в реальных сценариях.
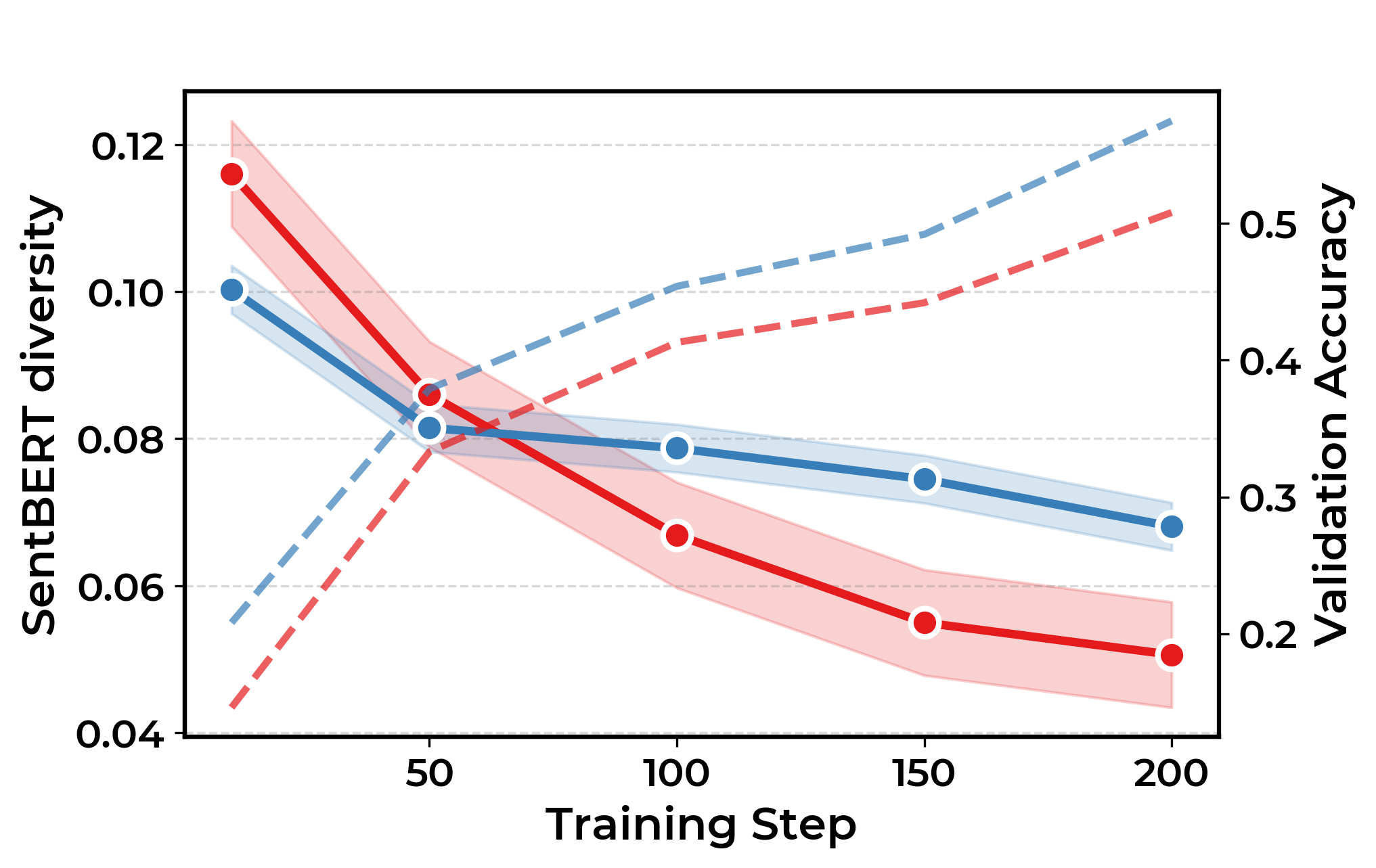
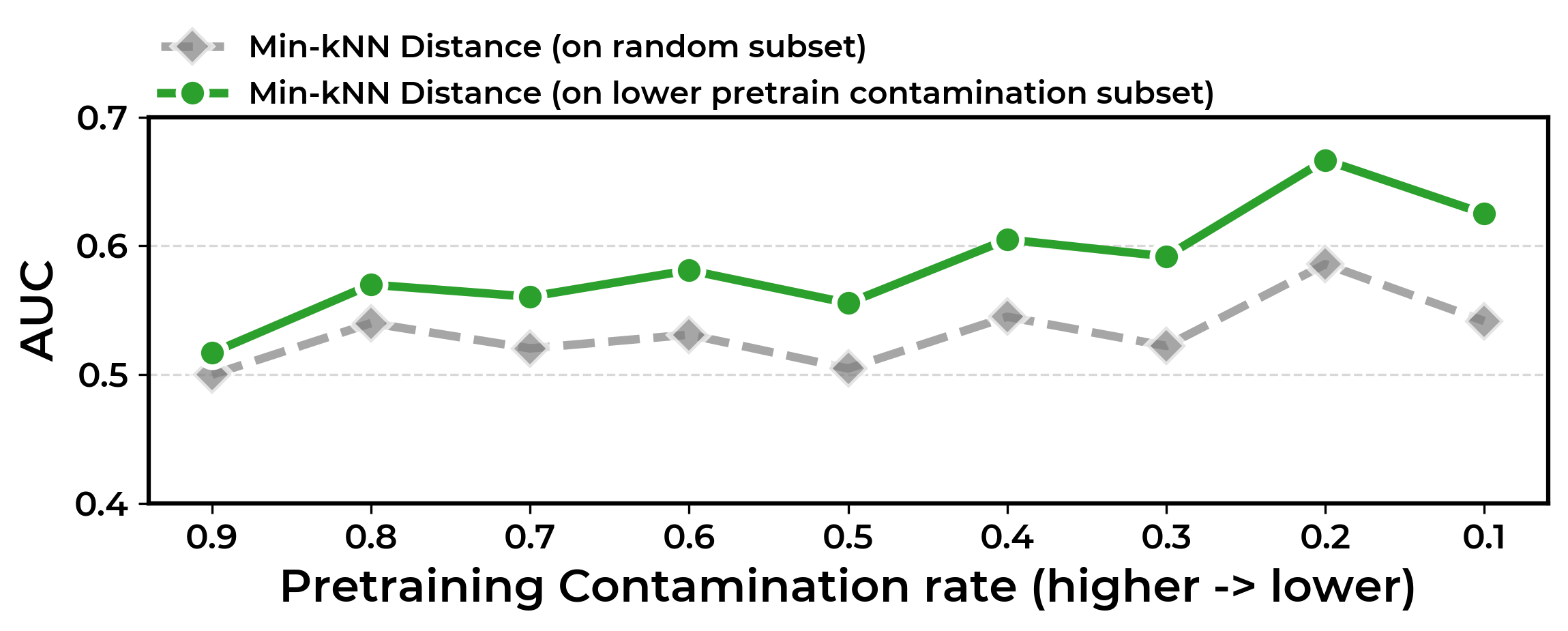
Метод Min-kkNN Distance позволяет выявлять случаи компрометации обучающих данных без доступа к внутренним параметрам модели. Он основан на количественной оценке структурного разнообразия генерируемых выходных данных. Суть подхода заключается в измерении расстояния между сгенерированным текстом и его ближайшими соседями в пространстве представлений, полученных из набора данных. Низкое структурное разнообразие, проявляющееся в небольших минимальных расстояниях до ближайших соседей, указывает на то, что модель, вероятно, запомнила обучающие примеры, а не научилась обобщать знания. По сути, метод определяет, насколько сгенерированные ответы отличаются от данных, на которых модель обучалась, выявляя признаки запоминания, а не истинного понимания.
Метод Min-kkNN Distance демонстрирует среднюю площадь под ROC-кривой (AUC) в 0.70 при обнаружении утечки обучающих данных в RLVR-моделях. Это на 17% превосходит показатели базовых методов. Для обеспечения эффективного инференса используется фреймворк vLLM, а для оценки сходства и логической согласованности сгенерированных цепочек рассуждений применяются метрики Edit Distance и NLI (Natural Language Inference). Комбинация этих инструментов позволяет количественно оценивать структурное разнообразие выходных данных и выявлять признаки запоминания обучающих примеров.
Структурная конвергенция и разнообразие рассуждений
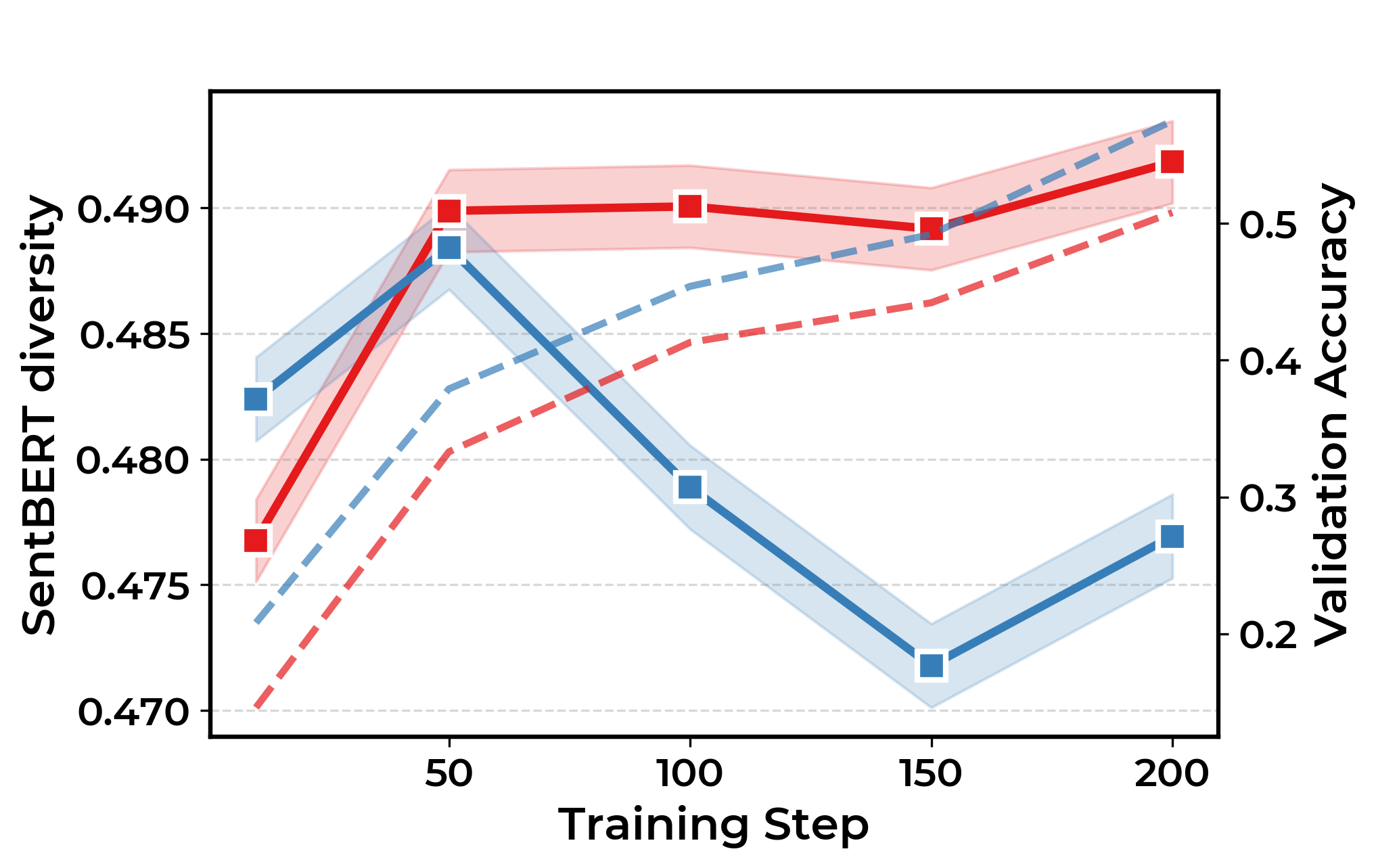
Анализ траекторий рассуждений, полученных в ходе обучения моделей с подкреплением для визуального логического вывода (RLVR), демонстрирует тенденцию к структурной конвергенции. Это означает, что модели, стремясь к оптимальному решению, все чаще приходят к использованию ограниченного набора общих стратегий рассуждений, как бы «сжимая» пространство возможных путей к ответу. Вместо разнообразия и исследования различных логических цепочек, модели склонны сосредотачиваться на небольшом количестве наиболее эффективных, но однообразных подходов. Такое сужение пространства рассуждений может привести к потере гибкости и способности решать задачи, требующие нестандартного мышления, поскольку модель становится менее восприимчивой к альтернативным решениям и новым типам данных.
Анализ показывает, что тенденция к структурной конвергенции в моделях, обученных с подкреплением и визуальными рассуждениями (RLVR), напрямую влияет на разнообразие генерируемых ответов. Это проявляется в снижении показателей лексического разнообразия — ограниченности используемых слов и фраз, логического разнообразия — однообразия в подходах к решению задач, и семантического разнообразия — схожести смысловых оттенков в ответах. Уменьшение этих показателей указывает на то, что модель, возможно, не демонстрирует подлинных рассуждений, а лишь воспроизводит ограниченный набор шаблонов, что ограничивает ее способность к решению новых или нестандартных задач и подчеркивает необходимость стимулирования исследования различных стратегий и предотвращения преждевременной конвергенции к узкому спектру решений.
Снижение разнообразия в процессах рассуждений, наблюдаемое в обученных моделях, может свидетельствовать о поверхностном характере выводимых заключений и ограничениях в способности к символьному мышлению. Когда алгоритм сходится к узкому набору общих стратегий, он теряет гибкость и способность рассматривать проблему с разных точек зрения, что негативно сказывается на качестве и оригинальности получаемых решений. Поэтому, поддержание высокой степени исследовательской активности и предотвращение преждевременной сходимости к единым шаблонам рассуждений представляется критически важным для развития действительно интеллектуальных систем, способных к глубокому анализу и креативному решению задач.
Исследование, представленное в данной работе, демонстрирует изящную элегантность подхода к обнаружению загрязнения данных в моделях, обученных с подкреплением на основе обратной связи от человека. Метод Min-kkNN Distance, оценивая структурную сходимость траекторий рассуждений, позволяет с высокой точностью определить, обучалась ли модель на конкретном наборе данных. Этот подход, подобно математической чистоте, стремится к доказательству, а не к простой работоспособности на тестовых примерах. Тим Бернерс-Ли однажды заметил: «Веб должен быть для всех, и у всех должна быть возможность участвовать в нем». В контексте данной работы, это означает, что инструменты обнаружения загрязнения данных необходимы для обеспечения честности и прозрачности моделей, доступных для широкого круга пользователей, и для защиты от нежелательных смещений и манипуляций.
Куда Далее?
Представленный метод, измеряющий сходимость траекторий рассуждений, открывает путь к более глубокому пониманию «памяти» больших языковых моделей. Однако, следует признать, что определение «структурной сходимости» остается в значительной степени эвристическим. Будущие исследования должны сосредоточиться на формализации этого понятия, возможно, через призму теории информации или теории категорий, дабы избежать произвольности в выборе метрик и параметров. Иначе, мы рискуем лишь констатировать очевидное — что модели, обученные на схожих данных, демонстрируют схожее поведение.
Особое внимание заслуживает вопрос об устойчивости метода к «шуму» в данных и к вариациям в процессе обучения с подкреплением. Идеальный детектор должен быть инвариантен к незначительным изменениям в обучающей выборке, не выдавая ложных срабатываний. Более того, необходимо исследовать, возможно ли использование данного подхода для идентификации не только принадлежности к конкретному датасету, но и для определения степени влияния этого датасета на финальную модель.
В конечном счете, истинный прогресс в данной области потребует не просто разработки новых алгоритмов обнаружения, но и создания фундаментальной теории, объясняющей, как информация кодируется и хранится в нейронных сетях. Только тогда мы сможем перейти от эмпирических наблюдений к предсказаниям и, возможно, даже к управлению этим процессом.
Оригинал статьи: https://arxiv.org/pdf/2602.11792.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- Мир текстов без границ: Новые возможности многоязыковых представлений
- Квантовые вычисления для молекул: оптимизация ресурсов
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Искусственный интеллект и закон: гармония неизбежна
- Видеосинтез без тормозов: новый подход к генерации видео в реальном времени
- Топoлогические формы и тайны Вселенной
- Молекулярный интеллект: проверка химического мышления
- Визуальный интеллект машин: новый тест на сообразительность
- Зрение и язык: новый шаг к автономному вождению
2026-02-14 04:21