Автор: Денис Аветисян
Новая модель P-GenRM позволяет адаптировать большие языковые модели под индивидуальные предпочтения пользователя, значительно повышая качество генерируемого контента.

Представлена модель P-GenRM, использующая персональные профили и адаптацию в процессе работы для улучшения соответствия больших языковых моделей предпочтениям пользователей.
Персонализация больших языковых моделей сталкивается с трудностями в адаптации к индивидуальным предпочтениям пользователей из-за сложности получения точных и специфичных сигналов обратной связи. В данной работе представлена модель P-GenRM («Personalized Generative Reward Model with Test-time User-based Scaling»), использующая персонализированные профили и адаптацию в процессе тестирования для формирования более релевантных ответов. Предложенный подход позволяет добиться значительного улучшения результатов на стандартных бенчмарках, демонстрируя прирост в 2.31% и эффективную обобщающую способность. Сможет ли P-GenRM стать основой для создания действительно «умных» помощников, способных понимать и учитывать уникальные потребности каждого пользователя?
Неизбежные Трудности Персонализированного AI
Несмотря на впечатляющие возможности современных больших языковых моделей (БЯМ), их адаптация к индивидуальным предпочтениям пользователя представляет собой сложную задачу. БЯМ, обученные на огромных массивах данных, демонстрируют способность генерировать текст, переводить языки и отвечать на вопросы, однако, универсальный характер обучения часто приводит к ответам, не учитывающим уникальный стиль, тон или специфические знания конкретного пользователя. Достижение подлинной персонализации требует преодоления трудностей, связанных с пониманием и интеграцией тонких нюансов индивидуальных предпочтений, что выходит за рамки простого обучения на пользовательских данных и требует разработки более сложных механизмов адаптации и обучения с подкреплением.
Традиционные методы настройки больших языковых моделей (LLM) зачастую испытывают трудности при учете тонких нюансов индивидуальных предпочтений пользователя. Стандартные подходы, основанные на обобщенных данных и усредненных ожиданиях, нередко приводят к формированию шаблонных и недостаточно персонализированных ответов. Это связано с тем, что LLM, обученные на обширных, но усредненных корпусах текстов, склонны выдавать наиболее вероятные, но не обязательно наиболее подходящие для конкретного пользователя, результаты. Вследствие этого, ответы могут быть лишены индивидуального стиля, специфических знаний или предпочтительного тона, что снижает удовлетворенность пользователя и ограничивает потенциал LLM как действительно персонализированного помощника.

P-GenRM: Модель Генеративного Вознаграждения для Индивидуальных Предпочтений
P-GenRM представляет собой персонализированную генеративную модель вознаграждения, разработанную для преобразования неявных сигналов предпочтений пользователя в структурированные цепочки оценки. В отличие от традиционных моделей, требующих явных оценок, P-GenRM способен выводить критерии оценки на основе косвенных данных, таких как история взаимодействия, поведение пользователя и контекстная информация. Этот процесс включает в себя генерацию последовательности логических шагов, формирующих оценку, что позволяет модели не только определять степень соответствия результата предпочтениям, но и объяснять причины данной оценки. Полученные цепочки оценки служат основой для обучения и улучшения модели, обеспечивая адаптацию к индивидуальным потребностям каждого пользователя.
Использование генеративных моделей в P-GenRM обеспечивает высокую обобщающую способность и масштабируемость системы. В отличие от традиционных моделей, требующих обширных наборов данных для каждого пользователя, P-GenRM способен адаптироваться к разнообразным потребностям пользователей, используя ограниченное количество входных данных. Это достигается за счет способности генеративных моделей создавать новые, правдоподобные оценки, а не просто запоминать существующие. Такая архитектура позволяет эффективно обрабатывать запросы от большого числа пользователей с различными предпочтениями, а также быстро адаптироваться к изменениям в этих предпочтениях без необходимости переобучения всей модели. Масштабируемость обеспечивается за счет возможности параллельной обработки оценок и использования распределенных вычислений.
Модель P-GenRM использует методы, такие как Persona-guided Scoring Induction и Criteria-based Reasoning Enhancement для формирования надежных и детализированных оценок. Persona-guided Scoring Induction предполагает индукцию оценочных шкал на основе профилей пользователей (персон), что позволяет учитывать индивидуальные предпочтения. Criteria-based Reasoning Enhancement, в свою очередь, усиливает логическую основу оценок путем явного определения и использования критериев, на которых они базируются. Комбинация этих подходов позволяет P-GenRM генерировать оценки, которые не только отражают предпочтения пользователя, но и обладают внутренней согласованностью и объяснимостью.

Динамическое Масштабирование с Учетом Индивидуальных и Групповых Предпочтений
P-GenRM использует масштабирование, основанное на предпочтениях пользователей, в процессе тестирования, что позволяет динамически корректировать схемы оценки на основе индивидуальных предпочтений каждого пользователя и предпочтений схожих пользователей. Этот подход предполагает анализ данных о взаимодействии пользователя с системой для выявления закономерностей и предпочтений. Система выявляет пользователей со схожими паттернами поведения и использует их предпочтения для улучшения персонализации оценки для текущего пользователя. Динамическая корректировка схемы оценки позволяет адаптироваться к меняющимся потребностям пользователя в реальном времени, повышая релевантность и точность результатов.
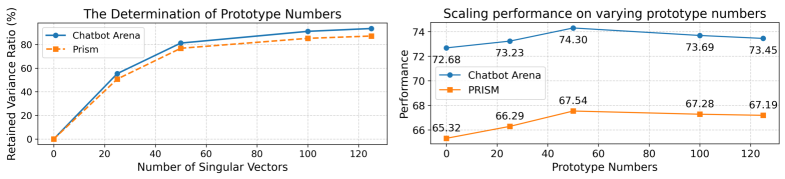
Масштабирование в P-GenRM использует методы коллаборативной фильтрации и прототипного масштабирования для снижения уровня шума и повышения обобщающей способности модели. Коллаборативная фильтрация позволяет выявлять схожие предпочтения между пользователями, что позволяет корректировать оценки на основе опыта других пользователей со схожими профилями. Прототипное масштабирование, в свою очередь, использует репрезентативные примеры (прототипы) для улучшения обобщения, уменьшая влияние выбросов и повышая устойчивость модели к новым данным. Комбинация этих двух подходов обеспечивает более точную и надежную адаптацию к индивидуальным предпочтениям пользователей.
P-GenRM использует расширенные методы оптимизации предпочтений, такие как Direct Preference Optimization (DPO) и Group Preference Optimization (GRPO), для обеспечения адаптивности к индивидуальным и коллективным предпочтениям пользователей. DPO позволяет модели обучаться непосредственно на данных о предпочтениях, максимизируя вероятность выбора предпочтительного ответа. GRPO расширяет этот подход, учитывая предпочтения целых групп пользователей, что позволяет модели адаптироваться к общим тенденциям и улучшать обобщающую способность. Комбинирование этих техник обеспечивает более точную настройку системы оценки в соответствии с разнообразными потребностями пользователей и групп, повышая релевантность и полезность генерируемых ответов.
В ходе тестирования установлено, что применение масштабирования в реальном времени (test-time scaling) обеспечивает прирост производительности на 3%. Данный показатель демонстрирует улучшенную масштабируемость и эффективность системы P-GenRM в задачах персонализации. Полученный прирост подтверждает возможность адаптации модели к индивидуальным предпочтениям пользователей и коллективным запросам, что положительно сказывается на общих показателях качества и релевантности результатов.
Экспериментальная Валидация и Производительность: Шаг к Реальной Персонализации
В ходе оценки модели P-GenRM с использованием языковых моделей LLaMA-3.1-8B и LLaMA-3.1-70B было продемонстрировано улучшение показателей на специализированных наборах данных, таких как LaMP-QA. Эти эксперименты позволили выявить, что применение P-GenRM способствует более точному и релевантному отклику на запросы, особенно в задачах, требующих понимания контекста и генерации развернутых ответов. Повышенная производительность на LaMP-QA свидетельствует об эффективности P-GenRM в задачах, связанных с логическим выводом и поиском информации, что делает её перспективной для широкого спектра приложений в области обработки естественного языка.
Для точной настройки способности модели улавливать предпочтения пользователей, ключевую роль сыграли данные, полученные из платформ Chatbot Arena и PRISM. Эти платформы предоставили обширный набор реальных взаимодействий с пользователями, позволяя разработчикам оценить качество ответов модели с точки зрения человеческих суждений. Анализ этих данных позволил выявить тонкие нюансы в предпочтениях пользователей, что, в свою очередь, способствовало созданию более персонализированных и релевантных ответов. Благодаря использованию этих данных, модель получила возможность не только генерировать грамматически верные тексты, но и учитывать индивидуальные запросы и ожидания каждого пользователя, значительно повышая общий уровень удовлетворенности.
Эффективность модели значительно возрастает благодаря применению обучения с подкреплением на основе обратной связи от людей. Этот процесс позволяет точно настроить поведение модели, обеспечивая соответствие желаемым критериям и предпочтениям пользователей. В ходе обучения, люди оценивают ответы модели, предоставляя ценные данные для корректировки алгоритмов и повышения качества генерируемого контента. Такой подход не только улучшает точность и релевантность ответов, но и способствует формированию более естественного и понятного стиля общения, делая взаимодействие с моделью более продуктивным и приятным для пользователя.
Модель P-GenRM демонстрирует передовые результаты на специализированных бенчмарках, оценивающих персонализированные вознаграждения, превосходя предыдущие лучшие показатели на 2.77% в среднем. Данный показатель свидетельствует о значительном улучшении способности модели адаптироваться к индивидуальным предпочтениям пользователей и генерировать ответы, соответствующие их ожиданиям. Такой прогресс достигается благодаря усовершенствованным алгоритмам обучения и оптимизации, позволяющим P-GenRM более эффективно учитывать нюансы пользовательского взаимодействия и предоставлять более релевантный и полезный контент.
Результаты экспериментов демонстрируют значительное превосходство P-GenRM над существующими решениями в области персонализированных систем вознаграждения. В частности, при использовании модели LLaMA-3.1-70B с применением метода LORA, P-GenRM показал улучшение на 1.99% по сравнению с предыдущим лидером. Более того, модель превзошла исходную 70B модель на 1.04%, что свидетельствует о её эффективности в оптимизации и повышении точности персонализированных ответов и поведения системы. Данный результат подтверждает потенциал P-GenRM для создания более адаптивных и полезных взаимодействий с пользователем.

Будущее Персонализированного AI: За Гранью Ожиданий
Генеративные модели вознаграждения, такие как P-GenRM, представляют собой важный шаг на пути к созданию больших языковых моделей (LLM), способных обеспечивать действительно персонализированный опыт взаимодействия. В отличие от традиционных методов, полагающихся на ручную разметку или упрощенные метрики, эти модели обучаются генерировать вознаграждения, отражающие индивидуальные предпочтения пользователя непосредственно из его взаимодействия с системой. Это позволяет LLM адаптироваться к уникальному стилю общения, интересам и потребностям каждого пользователя, предлагая более релевантные и полезные ответы. По сути, P-GenRM позволяет модели «понимать», что конкретному пользователю нравится, и оптимизировать свои ответы соответствующим образом, открывая перспективы для создания искусственного интеллекта, который действительно адаптируется к индивидуальности каждого.
Дальнейшие исследования направлены на масштабирование этих методов для применения к моделям ещё большего размера и более сложным областям предпочтений. Увеличение вычислительных мощностей и разработка более эффективных алгоритмов позволят обрабатывать гораздо более обширные и детализированные наборы данных о пользователях, что критически важно для создания действительно персонализированных систем. Особое внимание уделяется решению проблемы “размывания” предпочтений при работе с высокоразмерными пространствами, где небольшие изменения в входных данных могут приводить к значительным отклонениям в выходных результатах. Преодоление этих трудностей откроет возможности для создания искусственного интеллекта, способного адаптироваться к индивидуальным потребностям каждого пользователя с беспрецедентной точностью и гибкостью.
Перспективы персонализированного искусственного интеллекта напрямую связаны с разработкой усовершенствованных механизмов обратной связи и изучением новых генеративных архитектур. Исследования направлены на создание систем, способных не просто адаптироваться к предпочтениям пользователя, но и предвосхищать их, формируя уникальный опыт взаимодействия. Внедрение более сложных алгоритмов обучения с подкреплением, позволяющих модели самостоятельно оценивать качество генерируемого контента и корректировать свои действия, открывает возможности для создания действительно интеллектуальных помощников. Параллельно, изучение альтернативных архитектур генеративных моделей, выходящих за рамки традиционных трансформаторов, может привести к созданию систем, более эффективно использующих данные и способных генерировать более релевантный и креативный контент, максимально соответствующий индивидуальным потребностям каждого пользователя.
Исследование демонстрирует закономерность, знакомую по бесчисленным постмортамам: элегантная теория персонализированных моделей вознаграждения, P-GenRM, сталкивается с суровой реальностью адаптации к конкретному пользователю в момент использования. Авторы пытаются приручить хаос предпочтений, создавая модели, которые учитывают пользовательские персоны. Однако, даже самые сложные алгоритмы не застрахованы от внезапных изменений вкуса. Как заметил Пол Эрдёш: «Математика — это искусство избегать тривиальных ошибок». Здесь же, тривиальной ошибкой может оказаться предположение о стабильности пользовательских предпочтений. Модель P-GenRM — это не панацея, а лишь инструмент, который, как и любой другой, нуждается в постоянной калибровке и адаптации к непредсказуемости человеческого фактора. Всё это — очередной кирпичик в культе DevOops.
Что Дальше?
Представленная работа, безусловно, добавляет ещё один уровень сложности в и без того запутанную область обучения с подкреплением на основе обратной связи от человека. Персонализация моделей вознаграждения — это, конечно, интересно, но не стоит забывать, что каждый «уникальный пользователь» в конечном итоге сгенерирует достаточно данных, чтобы стать очередным усредненным профилем. И тогда все эти сложные механизмы адаптации окажутся просто избыточными вычислениями.
Попытки точно отразить предпочтения пользователя в модели вознаграждения неизбежно столкнутся с проблемой стабильности. Каждое незначительное изменение в данных, каждая новая порция обратной связи будут вносить искажения, требующие постоянной перекалибровки. В итоге, вместо элегантной системы, получится хрупкая конструкция, зависящая от непрерывного потока данных. Нам не нужно больше персонализированных моделей — нам нужно меньше иллюзий о возможности их точного построения.
Следующим этапом, вероятно, станет поиск способов упростить процесс адаптации, возможно, за счет отказа от попыток моделировать сложные индивидуальные предпочтения. Вместо этого, стоит сосредоточиться на создании более робастных и обобщающих моделей вознаграждения, которые менее чувствительны к индивидуальным особенностям. Каждая «революционная» технология сегодня — это завтрашний технический долг, который рано или поздно придется выплачивать.
Оригинал статьи: https://arxiv.org/pdf/2602.12116.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Молекулярный интеллект: проверка химического мышления
- Видеосинтез без тормозов: новый подход к генерации видео в реальном времени
- Искусственный интеллект и закон: гармония неизбежна
- Квантовый поиск гравитационных волн: новый алгоритм для повышения точности
- Иллюзии восприятия: Как формулировка вопроса влияет на зрение нейросетей
- Иллюзии понимания: Как правильно оценивать объяснимые модели
- Видео-рассуждения: готовы ли модели выйти за рамки лаборатории?
- Мир текстов без границ: Новые возможности многоязыковых представлений
- Favia: Искусственный интеллект на страже безопасности кода
2026-02-14 12:39