Автор: Денис Аветисян
Новый подход dVoting позволяет повысить качество рассуждений больших языковых моделей, не увеличивая при этом вычислительные затраты.
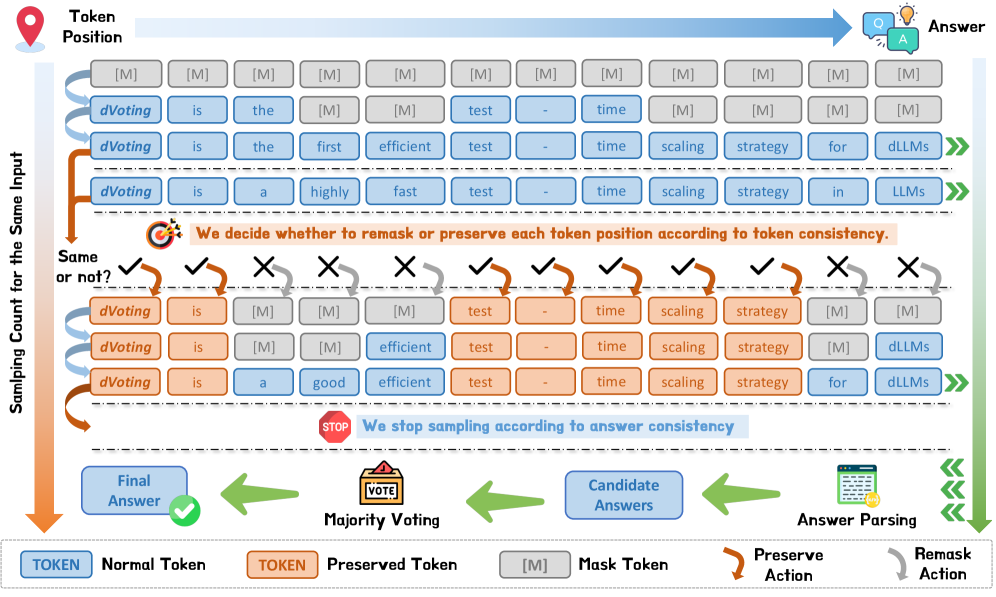
Метод dVoting использует ремаскинг и голосование для эффективного масштабирования диффузионных языковых моделей на этапе тестирования.
Несмотря на значительный прогресс в области больших языковых моделей, повышение их способности к рассуждению без трудоемкого переобучения остается сложной задачей. В данной работе представлена методика ‘dVoting: Fast Voting for dLLMs’, направленная на ускорение процесса получения ответов и улучшение логических способностей диффузионных языковых моделей (dLLMs). Предложенный подход dVoting, основанный на итеративном уточнении предсказаний посредством голосования и анализа согласованности, позволяет добиться существенного прироста производительности с минимальными дополнительными вычислительными затратами. Способна ли данная техника стать эффективным инструментом для масштабирования и повышения надежности dLLMs в различных областях применения?
За пределами Авторегрессии: Ограничения Традиционных Языковых Моделей
Несмотря на впечатляющие достижения авторегрессионных больших языковых моделей (БЯМ), их последовательная природа представляет собой узкое место при решении сложных задач, требующих логического вывода и анализа. В процессе генерации текста каждое последующее слово формируется исключительно на основе предыдущих, что ограничивает возможность одновременного рассмотрения всей входной информации и установления взаимосвязей между различными ее частями. Это особенно заметно в задачах, где требуется многоступенчатое рассуждение или учет контекста, охватывающего значительный объем данных. Фактически, модель вынуждена последовательно «проходить» через информацию, подобно чтению книги построчно, что замедляет процесс и повышает вероятность ошибок, особенно при обработке длинных и сложных текстов. В результате, эффективность авторегрессионных моделей снижается при решении задач, требующих глубокого понимания и синтеза информации, что указывает на необходимость поиска альтернативных архитектур, способных обрабатывать данные параллельно и более эффективно.
Дальнейшее увеличение масштаба традиционных авторегрессионных языковых моделей демонстрирует растущую неэффективность инвестиций. Несмотря на значительные вычислительные затраты и объемы данных, используемые для обучение, наблюдается тенденция к уменьшению отдачи в плане улучшения способности решать сложные задачи, требующие логического мышления и анализа. Это указывает на фундаментальные ограничения текущей архитектуры, побуждая исследователей искать альтернативные подходы, которые могли бы преодолеть узкие места последовательной обработки и обеспечить более эффективное решение проблем, не требующее экспоненциального увеличения вычислительных ресурсов. Иными словами, простое увеличение размера модели не является устойчивым решением для достижения подлинного искусственного интеллекта.
Диффузионные Языковые Модели: Новый Параллельный Подход к Генерации
Диффузионные большие языковые модели (LLM) представляют собой альтернативу авторегрессионным моделям, рассматривая генерацию текста как процесс удаления шума. В отличие от авторегрессионных моделей, которые генерируют текст последовательно, токен за токеном, диффузионные модели способны обрабатывать и генерировать токены параллельно. Этот подход позволяет существенно ускорить процесс генерации и потенциально улучшить способность модели к рассуждению, поскольку модель может одновременно учитывать взаимосвязи между всеми элементами генерируемого текста, а не только предыдущими. В основе метода лежит постепенное добавление шума к входному тексту, а затем обучение модели восстанавливать исходный текст из зашумленного состояния, что позволяет ей генерировать новые тексты, начиная со случайного шума.
Диффузионные языковые модели используют технику предсказания замаскированных токенов (masked token prediction) для восстановления текста, что позволяет итеративно улучшать качество генерации. В процессе обучения модель получает текст, в котором случайным образом скрыты некоторые токены, и учится предсказывать эти скрытые токены на основе контекста окружающих токенов. Повторение этого процесса, а также использование различных стратегий маскирования, обеспечивает более гибкий подход к генерации текста по сравнению с авторегрессионными моделями. Это приводит к улучшению показателей производительности, особенно в задачах, требующих высокой точности и детализации генерируемого текста, а также позволяет модели корректировать и уточнять выходные данные на каждом этапе.
Механизм повторной маскировки является ключевым элементом функционирования диффузионных языковых моделей. Он позволяет итеративно улучшать сгенерированный текст, повторно маскируя уже предсказанные токены и пересчитывая их вероятности на основе контекста. Этот процесс повторяется несколько раз, позволяя модели уточнять свои предсказания и избегать ошибок, характерных для авторегрессионных моделей. В отличие от последовательного предсказания токенов, повторная маскировка способствует параллельной обработке, что повышает эффективность генерации и позволяет модели исследовать различные варианты продолжения текста на каждом шаге.

dVoting: Быстрое и Эффективное Декодирование в Диффузионных Моделях
Метод dVoting значительно ускоряет процесс декодирования в диффузионных языковых моделях (LLM) за счет использования быстрой стратегии голосования. Данный подход итеративно перемаскирует и регенерирует токены, позволяя модели быстро сузить пространство возможных вариантов и выбрать наиболее вероятные. Вместо последовательного добавления токенов, dVoting параллельно рассматривает несколько кандидатов на каждом шаге, что существенно сокращает общее время генерации текста. Процесс включает в себя повторное маскирование уже сгенерированных токенов и повторную генерацию, основанную на голосовании между различными вариантами, что приводит к более эффективному исследованию пространства токенов и, как следствие, к ускорению декодирования.
Метод dVoting обеспечивает эффективное исследование пространства токенов и повышение качества генерации за счет использования параллельного декодирования и пороговой фильтрации энтропии. Параллельное декодирование позволяет одновременно рассматривать несколько наиболее вероятных токенов, что значительно ускоряет процесс генерации. Пороговая фильтрация энтропии динамически определяет, какие токены следует перегенерировать на основе их неопределенности (энтропии), фокусируясь на наиболее информативных позициях и избегая избыточной регенерации уже уверенных токенов. Это позволяет более эффективно использовать вычислительные ресурсы и повысить точность и согласованность сгенерированного текста.
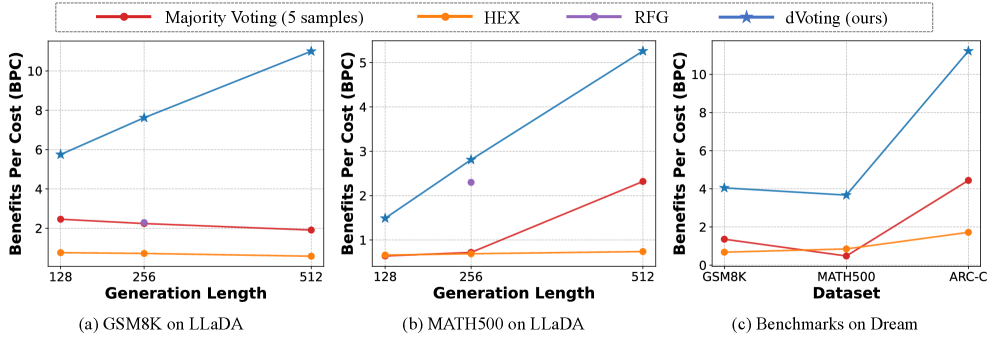
В ходе экспериментов было показано, что методика dVoting значительно повышает производительность на сложных бенчмарках. Набор данных GSM8K демонстрирует прирост точности в диапазоне от 6.22% до 7.66%, а на MATH500 — от 4.40% до 7.20%. Наиболее существенный прирост наблюдается на ARC-C, где точность увеличивается на 3.16%-14.84%. Полученные результаты подтверждают эффективность dVoting в задачах, требующих высокой точности и способности к решению сложных математических и логических задач.
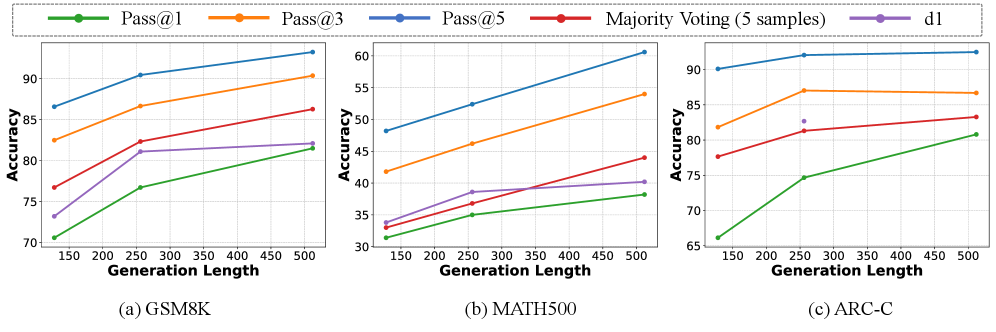
Повышение Производительности с Помощью Масштабирования во Время Тестирования и Обучения с Подкреплением
Механизм масштабирования во время тестирования, в сочетании с обучением с подкреплением, представляет собой эффективный подход к тонкой настройке диффузионных языковых моделей, таких как LLaDA-1.5. Этот метод позволяет адаптировать модель к конкретным задачам непосредственно в процессе генерации текста, без необходимости переобучения всей модели. Используя обучение с подкреплением, система способна оптимизировать процесс масштабирования, выбирая наилучшие параметры для достижения максимальной производительности и качества генерируемого текста. Такой подход особенно ценен для сложных задач, где требуется высокая степень адаптивности и точности, позволяя модели эффективно использовать имеющиеся ресурсы и демонстрировать улучшенные результаты по сравнению со статически обученными аналогами.
Алгоритм оптимизации предпочтений с пониженной дисперсией, представляющий собой специфический метод обучения с подкреплением, обеспечивает эффективную тренировку и улучшение результатов при решении сложных задач. В отличие от традиционных подходов, данный алгоритм снижает вариативность оценок, что позволяет быстрее сходиться к оптимальному решению и требует меньше вычислительных ресурсов. Это достигается за счет более точной оценки вознаграждения и эффективного использования данных, что особенно важно при работе с большими языковыми моделями, требующими значительных объемов информации для обучения. В результате, модель способна демонстрировать более высокую производительность и адаптироваться к разнообразным задачам с повышенной эффективностью, что делает данный алгоритм ценным инструментом в области машинного обучения и искусственного интеллекта.
Исследования показали, что методика dVoting обеспечивает значительное ускорение процесса декодирования по сравнению с традиционными подходами. В частности, при работе с моделью LLaDA, dVoting демонстрирует прирост производительности в 1.1-4.4 раза по сравнению с методом Majority Voting, в 1.1-2.2 раза быстрее RFG и впечатляющие 5.5-22.1 раза быстрее, чем HEX. Важно отметить, что ускорение не идет в ущерб качеству — dVoting демонстрирует оптимальное соотношение между эффективностью и результатами, достигая показателя Benefits per Cost (BPC) в 5.75 при работе с набором данных GSM8K и моделью LLaDA-8B-Instruct, что свидетельствует о высокой практической ценности данной методики.
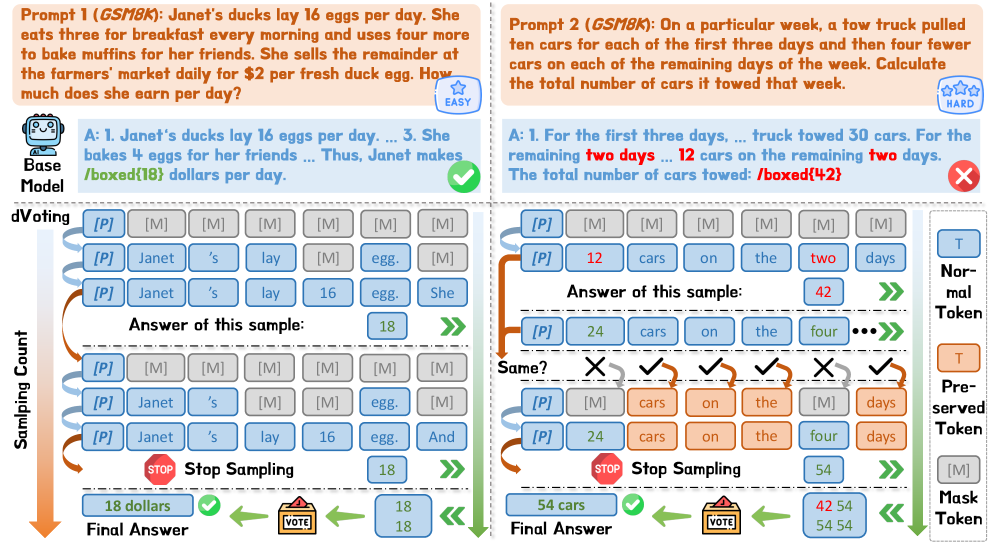
Исследование демонстрирует, что кажущаяся простота голосования — метода dVoting — скрывает глубокую эффективность в усилении рассуждений диффузионных языковых моделей. Этот подход, использующий перемаскировку и голосование, напоминает о том, как из хаоса случайных процессов может возникнуть устойчивый и надежный результат. Как однажды заметил Карл Фридрих Гаусс: «Если бы другие знали, сколько всего я не знаю, они бы перестали удивляться тому, что я знаю». Эта фраза прекрасно отражает суть работы — признание неопределенности и использование коллективного разума (в данном случае, нескольких прогонов модели) для достижения более точного и обоснованного вывода. dVoting не стремится построить идеальную систему, а скорее создает экосистему, в которой ошибки компенсируются, а сильные стороны усиливаются.
Что Дальше?
Представленная работа, исследующая стратегию dVoting для диффузионных языковых моделей, лишь добавляет еще один слой к сложной картине масштабирования логических способностей. Не стоит обольщаться иллюзией полного решения: улучшение производительности — это всегда временный компромисс. Каждое новое правило голосования, каждая маска, наложенная на входные данные, несет в себе зародыш будущей уязвимости, новый способ обмануть систему. В конечном итоге, это не архитектура, а застывший во времени компромисс.
Настоящая проблема лежит не в скорости или эффективности алгоритма, а в фундаментальной неопределенности самой задачи. Мы пытаемся заставить машину мыслить, используя инструменты, созданные для обработки данных. Когда один фреймворк сменяет другой, зависимость от лежащих в основе предположений остается неизменной. Будущие исследования, вероятно, уйдут от поиска оптимальных стратегий голосования и обратятся к более глубокому пониманию того, как информация представляется и обрабатывается внутри этих моделей.
В конечном счете, системы не строятся, а растут. Их эволюция непредсказуема, а их будущее — это не результат нашего проектирования, а следствие неминуемых ошибок и неожиданных взаимодействий. Технологии сменяются, зависимости остаются.
Оригинал статьи: https://arxiv.org/pdf/2602.12153.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Молекулярный интеллект: проверка химического мышления
- Видеосинтез без тормозов: новый подход к генерации видео в реальном времени
- Искусственный интеллект и закон: гармония неизбежна
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Видео-рассуждения: готовы ли модели выйти за рамки лаборатории?
- Мир текстов без границ: Новые возможности многоязыковых представлений
- Скрытые симметрии материи: новая схема для экзотических фаз
- Визуальное мышление с языком: новый взгляд на 3D-понимание
- Оптимизация процессов: симбиоз классических и квантовых вычислений
- Топoлогические формы и тайны Вселенной
2026-02-14 16:11