Автор: Денис Аветисян
Исследователи предлагают метод адаптивной конфигурации систем на базе больших языковых моделей для повышения их эффективности и снижения затрат ресурсов.
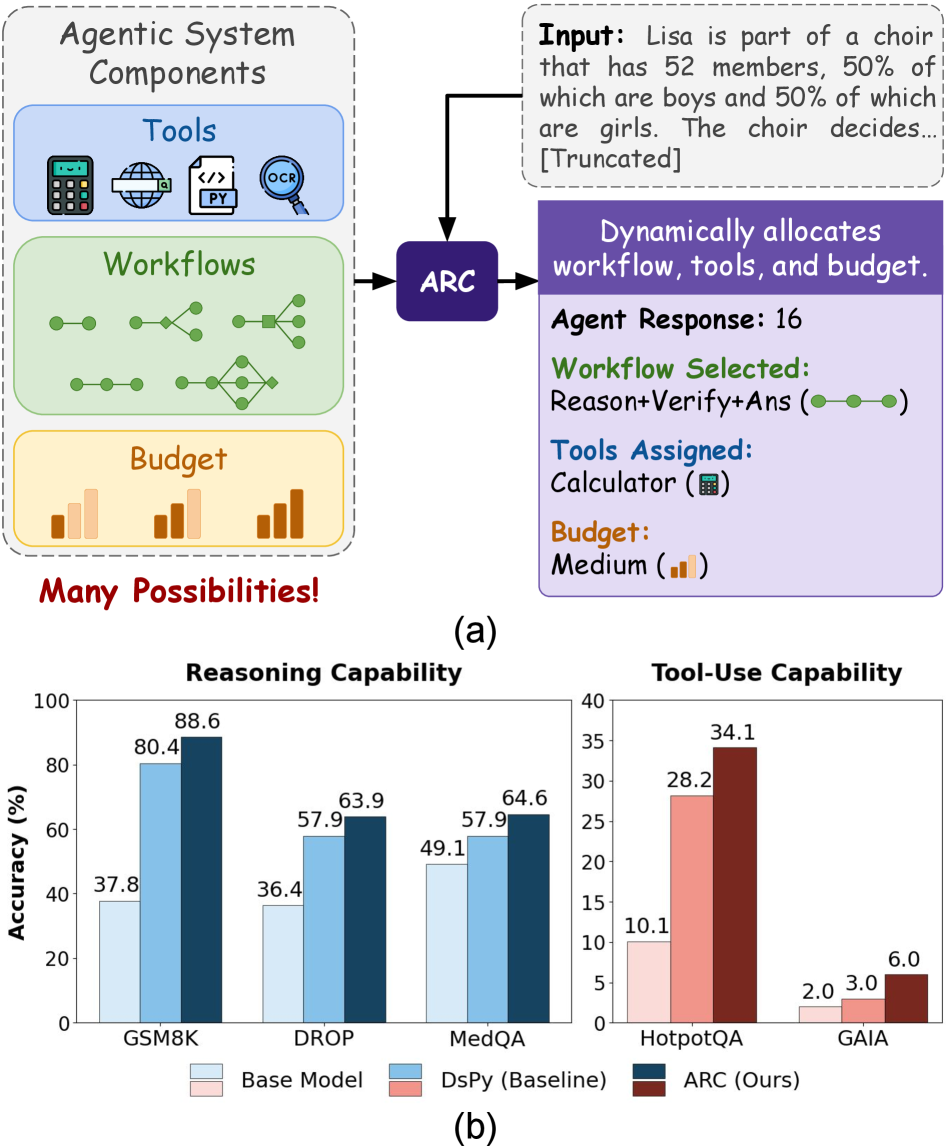
В статье представлена иерархическая система обучения с подкреплением ARC, позволяющая оптимизировать рабочие процессы, инструменты и инструкции для ИИ-агентов.
Несмотря на растущую эффективность агентных систем на базе больших языковых моделей, их конфигурация остается сложной задачей, требующей ручной настройки рабочих процессов и параметров. В работе ‘Learning to Configure Agentic AI Systems’ предложена новая методология, основанная на обучении с подкреплением, позволяющая динамически адаптировать конфигурацию агентских систем к специфике каждого запроса. Разработанный фреймворк ARC демонстрирует значительное повышение точности выполнения задач — до 25% — при одновременном снижении потребления токенов и времени выполнения. Не является ли адаптивная конфигурация ключом к раскрытию полного потенциала агентных систем и их эффективному применению в реальных условиях?
Вызов Динамического Рассуждения: Преодоление Ограничений LLM
Традиционные большие языковые модели (LLM) зачастую испытывают трудности при обработке сложных запросов, требующих последовательного, многоступенчатого рассуждения и адаптации к изменяющимся условиям. В отличие от решения простых задач, где достаточно прямого сопоставления шаблонов, сложные вопросы предполагают декомпозицию проблемы на подзадачи, формирование и проверку гипотез, а также интеграцию полученных результатов. Неспособность LLM эффективно выполнять эти шаги приводит к неточностям, логическим ошибкам и неудовлетворительным ответам. Особенно заметны эти ограничения при решении задач, требующих экстраполяции знаний на новые, незнакомые ситуации, или при работе с неполной или противоречивой информацией. Таким образом, преодоление этих сложностей является ключевой задачей для дальнейшего развития искусственного интеллекта и расширения возможностей языковых моделей.
Традиционные методы проектирования подсказок и заранее заданные рабочие процессы, несмотря на свою кажущуюся эффективность, часто оказываются хрупкими и неспособными адаптироваться к новым, нестандартным ситуациям. Вместо гибкого подхода, они предлагают жесткую структуру, которая может успешно справляться с известными типами запросов, но быстро дает сбой при столкновении с чем-то не предусмотренным. Это ограничивает потенциал больших языковых моделей, поскольку их способность к логическому выводу и решению задач зависит от способности адаптировать процесс рассуждений к конкретному контексту, а не полагаться на заранее определенные схемы. В результате, системы, построенные на таких подходах, демонстрируют низкую обобщающую способность и требуют постоянной перенастройки для каждого нового типа запроса, что делает их использование неэффективным и ресурсоемким.
Ограниченность возможностей адаптации существующих больших языковых моделей (БЯМ) существенно препятствует раскрытию их полного потенциала. Несмотря на впечатляющие объемы данных, на которых они обучаются, и способность генерировать связные тексты, БЯМ часто демонстрируют неспособность эффективно решать задачи, требующие гибкого подхода и изменения стратегии в процессе рассуждений. Эта негибкость проявляется в сложности адаптации к новым, не встречавшимся ранее ситуациям, а также в ограниченности возможностей модификации процесса логического вывода в зависимости от специфики запроса. В результате, даже самые мощные БЯМ могут оказаться неспособными справиться со сложными задачами, требующими динамического мышления и творческого подхода к решению проблем, что существенно ограничивает сферу их практического применения и снижает эффективность в реальных сценариях.
Основная сложность в построении систем, использующих большие языковые модели, заключается в способности динамически адаптировать процесс рассуждений к конкретному запросу. Вместо жестко заданных алгоритмов, модель должна уметь самостоятельно определять оптимальную последовательность шагов для решения задачи, исходя из её сложности и специфики. Это требует не просто обработки информации, а активного анализа структуры запроса и выбора наиболее подходящей стратегии рассуждений. По сути, речь идет о создании системы, способной к самоконфигурации, где процесс решения задачи формируется «на лету», а не задается заранее. Такой подход позволит значительно повысить гибкость и эффективность языковых моделей, преодолевая ограничения, связанные с жесткостью традиционных методов.
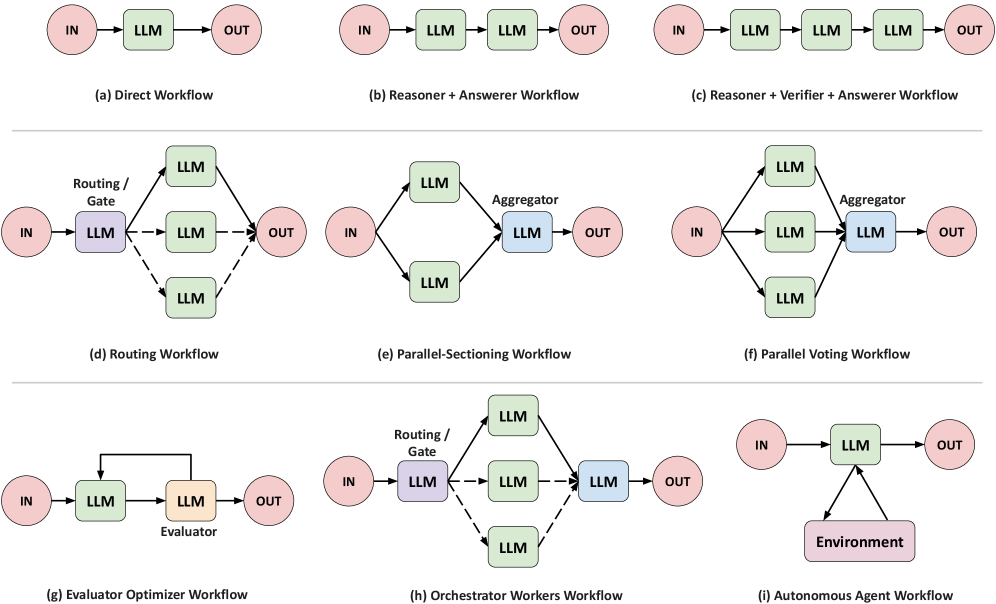
ARC: Адаптивная Конфигурация для Динамического Рассуждения
ARC представляет собой иерархическую систему обучения с подкреплением, предназначенную для динамической конфигурации агентов на базе больших языковых моделей (LLM). В отличие от статических конфигураций, ARC использует многоуровневую структуру, где агенты обучаются адаптировать свои стратегии и параметры в процессе взаимодействия со средой. Эта иерархичность позволяет разбивать сложные задачи на более простые подзадачи, оптимизируя процесс принятия решений и повышая эффективность агента. В основе системы лежит обучение с подкреплением, позволяющее агенту оценивать результаты своих действий и корректировать конфигурацию для достижения оптимальной производительности.
ARC расширяет возможности больших языковых моделей (LLM) за счет динамического выбора рабочих процессов, инструментов и подсказок. Вместо использования фиксированного набора параметров, ARC позволяет агенту LLM адаптировать свою конфигурацию в зависимости от конкретного запроса. Это достигается путем обучения иерархической модели обучения с подкреплением, которая определяет оптимальную последовательность действий — выбор подходящего инструмента, применение конкретного рабочего процесса и использование наиболее релевантной подсказки — для достижения наилучшего результата в каждой конкретной ситуации. Такой адаптивный подход позволяет эффективно использовать ресурсы LLM и повысить точность и надежность ответов.
Динамическая конфигурация в ARC позволяет оптимизировать процесс рассуждений для каждого конкретного запроса, что достигается путем адаптивного выбора рабочих процессов, инструментов и подсказок. Вместо использования фиксированного набора операций, ARC анализирует входной запрос и динамически настраивает цепочку действий, необходимую для его решения. Это позволяет системе более эффективно использовать свои ресурсы и избегать ненужных вычислений, что приводит к повышению производительности и улучшению способности к обобщению на новые, ранее не встречавшиеся запросы. В результате, ARC демонстрирует более высокую точность и надежность в решении различных задач по сравнению со статически сконфигурированными LLM-агентами.
В основе ARC лежит решение проблемы статической логики в больших языковых моделях (LLM) посредством гибкого, обучаемого подхода. Традиционные LLM часто применяют фиксированные цепочки рассуждений к каждому запросу, что ограничивает их адаптивность и эффективность. ARC преодолевает это ограничение, используя иерархическое обучение с подкреплением для динамической конфигурации процесса рассуждений. Это позволяет модели выбирать оптимальные рабочие процессы, инструменты и подсказки для каждого конкретного запроса, что приводит к повышению производительности и обобщающей способности, поскольку конфигурация адаптируется на основе опыта, полученного в процессе обучения.
Обучение Рассуждению: Политика ARC
В ARC используется политика обучения с подкреплением (RL), предназначенная для выбора оптимальной конфигурации для каждого запроса. Данная политика обучается путем взаимодействия с окружением, где каждое действие — выбор определенной конфигурации, а вознаграждение определяется качеством полученного результата. Цель обучения — максимизировать суммарное вознаграждение, что позволяет политике автоматически адаптироваться к различным типам запросов и выбирать наиболее эффективные параметры для их обработки. Процесс обучения позволяет ARC динамически настраиваться и оптимизировать свою работу без необходимости ручного вмешательства.
Политика ARC использует представление состояния (State Representation), построенное на базе модели MetaCLIP-H/14, для анализа характеристик запроса. MetaCLIP-H/14 представляет собой мультимодальную модель, способную кодировать как текстовые запросы, так и визуальную информацию в единое векторное пространство. Это позволяет системе извлекать значимые признаки из запроса, включая семантическое содержание и визуальные аспекты, необходимые для выбора оптимальной конфигурации. Полученное векторное представление состояния служит входными данными для алгоритма обучения с подкреплением, определяя дальнейшие действия политики.
Процесс обучения с подкреплением (RL) в ARC использует методы формирования вознаграждения (Reward Shaping) для оптимизации стратегии выбора конфигураций. Формирование вознаграждения позволяет направлять обучение, предоставляя промежуточные сигналы, облегчающие обнаружение оптимальных действий и ускоряющие сходимость. В качестве алгоритма обучения используется Proximal Policy Optimization (PPO), выбранный благодаря своей эффективности и стабильности при обучении политик в сложных средах. PPO обеспечивает итеративное улучшение политики, ограничивая изменения в каждом шаге обучения, что способствует предотвращению резких изменений поведения и повышению надежности процесса обучения.
После обучения с подкреплением (RL), политика дополнительно уточняется с помощью метода обучения с учителем на основе человеческой обратной связи (SFT). Этот этап позволяет повысить производительность и стабильность модели, корректируя её поведение на основе размеченных данных. SFT настраивает параметры политики, чтобы она генерировала более предпочтительные ответы, соответствующие ожиданиям пользователей, и снижает вероятность нежелательных или некорректных результатов, достигая большей надежности в различных сценариях использования.
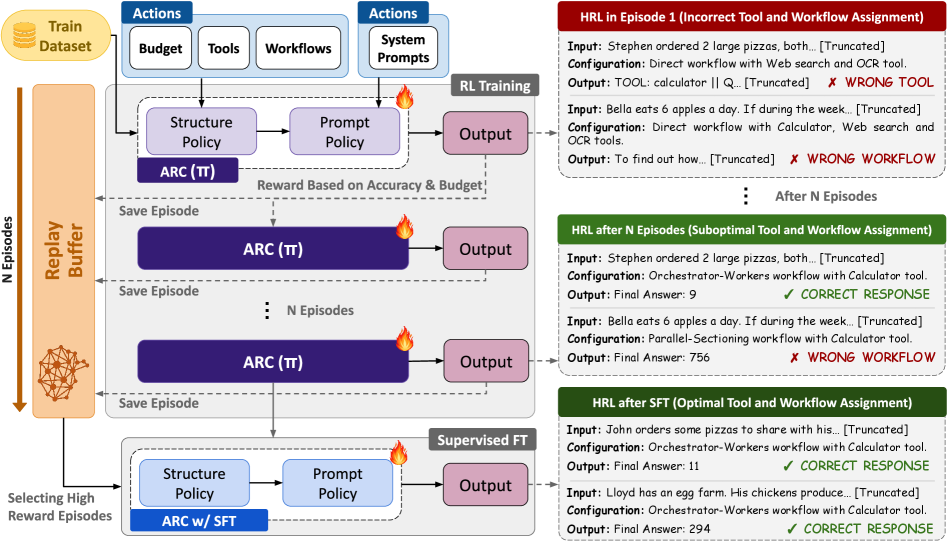
Оптимизация Распределения Ресурсов и Шагов Рассуждения
В своей работе ARC использует стратегическое применение внешних инструментов для расширения возможностей больших языковых моделей (LLM) и решения сложных задач. Этот подход позволяет разбивать обширные проблемы на более мелкие, управляемые подзадачи, каждая из которых решается с помощью специализированного инструмента. Например, для задач, требующих математических вычислений, может быть использован калькулятор, а для поиска информации — поисковая система. Интеграция этих инструментов не просто дополняет LLM, но и позволяет им эффективно справляться с задачами, которые были бы недостижимы при использовании только языковых способностей. Такой подход значительно повышает точность и надежность результатов, особенно в областях, требующих фактических знаний или сложных вычислений.
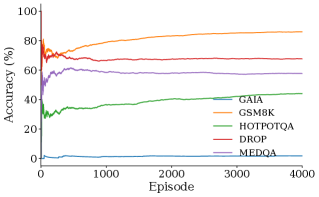
Эффективный выбор рабочего процесса играет центральную роль в организации процесса рассуждений и обеспечении его результативности. Система ARC не просто применяет инструменты, но и тщательно определяет последовательность их использования, адаптируясь к сложности задачи. Этот динамический подход позволяет оптимизировать каждый шаг, избегая излишних вычислений и направляя ресурсы на наиболее важные подзадачи. В результате, система способна решать сложные проблемы, требующие многоэтапных рассуждений, с повышенной точностью и эффективностью, что подтверждается результатами на наборах данных, таких как GSM8K, DROP и HotpotQA, где ARC демонстрирует значительное превосходство над базовыми моделями и альтернативными подходами.
Управление бюджетом токенов является ключевым элементом архитектуры ARC, обеспечивающим динамическое распределение вычислительных ресурсов между отдельными агентами или этапами рассуждений. Вместо фиксированного выделения ресурсов, система оценивает сложность каждого шага и потребность в токенах, распределяя их по требованию. Такой подход позволяет оптимизировать использование вычислительной мощности, направляя больше ресурсов на наиболее сложные задачи и экономя их на более простых. Эффективное управление бюджетом токенов не только повышает общую производительность системы, но и позволяет ей решать более сложные задачи, которые были бы недоступны при использовании фиксированных ограничений на ресурсы, что подтверждается улучшенными показателями на таких наборах данных, как GSM8K, DROP и HotpotQA.
Архитектура ARC демонстрирует существенное повышение производительности и эффективности за счет оптимизации распределения ресурсов и выбора оптимальной последовательности действий. На примере задачи GSM8K, где требуется решение математических задач, ARC достигает точности в 88.6%, что превосходит результаты моделей GEPA (83.6%) и RL Episodes (85.2%). Такой прогресс обусловлен не только более эффективным использованием вычислительных мощностей, но и способностью системы динамически адаптировать процесс решения, концентрируясь на наиболее важных этапах и избегая избыточных вычислений. Это позволяет ARC решать сложные задачи быстрее и точнее, устанавливая новый стандарт для систем искусственного интеллекта, ориентированных на решение задач, требующих логического мышления и глубокого анализа.
В ходе экспериментов с наборами данных DROP и HotpotQA, архитектура ARC продемонстрировала значительное превосходство над существующими моделями. На наборе данных DROP, предназначенном для оценки понимания текста и способности к рассуждениям, ARC превзошел базовые модели на 27,5%. В свою очередь, на наборе HotpotQA, требующем поиска и объединения информации из нескольких источников, ARC достиг точности в 34,1%, что на 6,7% выше, чем у лучших существующих методов. Эти результаты свидетельствуют о высокой эффективности ARC в задачах, требующих сложного анализа текста и многоступенчатых рассуждений, подтверждая его потенциал для решения задач, требующих глубокого понимания и синтеза информации.
В ходе тестирования на наборе данных GAIA, система ARC продемонстрировала улучшение на 4,0% по сравнению с базовыми моделями, достигнув точности в 6,0%. Этот результат свидетельствует об эффективности подхода ARC к решению задач, требующих глубокого понимания контекста и способности к логическим выводам. Набор данных GAIA, специализирующийся на вопросах, требующих многоступенчатого рассуждения и поиска информации из различных источников, представляет собой серьезный вызов для современных языковых моделей. Улучшение, показанное ARC, указывает на его способность более эффективно обрабатывать сложные запросы и предоставлять более точные ответы, что открывает перспективы для применения системы в задачах, требующих высокого уровня интеллектуального анализа.
Наблюдая за стремлением к «агентам», управляемым большими языковыми моделями, становится ясно, что за каждой новой архитектурой скрывается старая проблема — оптимизация. Эта работа, представляющая ARC, лишь подтверждает закономерность: иерархическое обучение и адаптивная конфигурация — это не революция, а переупаковка проверенных методов. Как говорил Эдсгер Дейкстра: «Программирование — это не столько о создании новых вещей, сколько об организации существующих». ARC, по сути, делает именно это — организует существующие инструменты и промпты, чтобы заставить их работать чуть более эффективно. И, вероятно, через пару лет кто-нибудь объявит это «новой парадигмой», пока продакшен не найдёт способ сломать и эту «оптимизацию».
Что Дальше?
Представленная работа, несомненно, добавляет ещё один уровень абстракции между человеком и машиной. Идея адаптивной конфигурации агентных систем, управляемых большими языковыми моделями, звучит привлекательно, пока не столкнётся с реальностью продакшена. Каждый «оптимизированный» рабочий процесс — это потенциальная точка отказа, каждый подобранный промпт — хрупкая конструкция, ожидающая неминуемой поломки. Полагать, что алгоритм сможет учесть все нюансы взаимодействия с внешним миром, — наивно. CI/CD станет новым храмом, где инженеры будут молиться, чтобы ничего не сломалось после очередного «улучшения».
Очевидным направлением для дальнейших исследований представляется попытка формализации «здравого смысла» для агентных систем. Однако, опыт подсказывает, что документация, описывающая этот самый «здравый смысл», останется мифом, придуманным менеджерами. Более вероятно, что усилия будут направлены на создание всё более сложных инструментов мониторинга и отладки, призванных хотя бы локализовать неизбежные сбои.
В конечном счете, каждая «революционная» технология неизбежно превратится в технический долг. Оптимизация ради оптимизации — путь в никуда. Важнее осознать, что истинная ценность заключается не в автоматизации как таковой, а в понимании ограничений и компромиссов, которые она влечет за собой.
Оригинал статьи: https://arxiv.org/pdf/2602.11574.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Звук как помощник зрения: Новые горизонты генерации видео
- Искусственный интеллект и закон: гармония неизбежна
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Моделирование биомолекул: новый импульс от нейросетей
- Оптимизация процессов: симбиоз классических и квантовых вычислений
- Молекулярный интеллект: проверка химического мышления
- Видеосинтез без тормозов: новый подход к генерации видео в реальном времени
- Поймать изменчивый сигнал: Как нейросети расшифровывают политику ФРС
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Социальные сети: Искусство правдоподобных взаимодействий
2026-02-14 21:19