Автор: Денис Аветисян
Новое исследование показывает, что множественность равноценных прогнозов ИИ ставит под вопрос существующие методы оценки эффективности и требует пересмотра принципов прозрачности в рамках европейского AI Act.
Исследование фокусируется на влиянии ‘predictive multiplicity’ на оценку индивидуальной производительности высокорисковых систем искусственного интеллекта в контексте AI Act.
В современных системах поддержки принятия решений на основе искусственного интеллекта часто возникает феномен “предиктивной множественности” — существование нескольких равноценных моделей, дающих различные прогнозы для отдельных случаев. В данной работе, ‘Using predictive multiplicity to measure individual performance within the AI Act’, рассматривается влияние этой проблемы на соответствие требованиям нового закона об искусственном интеллекте ЕС, в частности, на необходимость оценки точности и прозрачности систем высокого риска. Показано, что учет предиктивной множественности позволяет обеспечить соблюдение норм закона и выявлять случаи, когда индивидуальные прогнозы могут быть противоречивыми. Какие метрики и методы оценки помогут эффективно измерить предиктивную множественность и обеспечить надежность решений, принимаемых на основе ИИ?
Иллюзия Точности: За пределами Статистических Показателей
Высокая статистическая точность, часто являющаяся главным критерием оценки искусственного интеллекта, может скрывать существенные разногласия между различными моделями. Несмотря на схожие общие показатели, модели могут демонстрировать значительные расхождения в прогнозах для отдельных случаев, что связано с особенностями их обучения и архитектуры. Такое несоответствие, не улавливаемое традиционными метриками, создает иллюзию надежности и может привести к непредсказуемым результатам, особенно в критически важных областях, где последовательность и согласованность решений имеют первостепенное значение. Поэтому, фокусировка исключительно на общей статистике может ввести в заблуждение относительно реальной степени согласованности и надежности системы искусственного интеллекта.
Феномен “прогностической множественности” представляет собой серьезную проблему, заключающуюся в том, что различные модели искусственного интеллекта, демонстрирующие схожую общую точность, могут существенно расходиться в своих предсказаниях для отдельных случаев. Эта расходимость особенно опасна в критически важных областях, таких как медицина, юриспруденция или финансовый анализ, где даже небольшие ошибки могут привести к значительным последствиям. В то время как традиционные метрики оценки фокусируются на агрегированных показателях, они не способны выявить подобные расхождения, создавая иллюзию надежности и потенциально приводя к непоследовательным и даже ошибочным решениям. Необходим более детальный анализ, учитывающий не только общую точность, но и согласованность предсказаний между различными моделями для каждого конкретного случая, чтобы обеспечить надежность и безопасность систем искусственного интеллекта.
Традиционные метрики оценки, такие как общая точность или средняя ошибка, зачастую не способны выявить существенные расхождения между различными моделями искусственного интеллекта, даже если они демонстрируют схожие общие показатели. Эта проблема, известная как “иллюзия точности”, создает ложное чувство уверенности в надежности системы. Модели могут успешно справляться с большинством задач, но значительно различаться в своих прогнозах для отдельных, критически важных случаев, что особенно опасно в сферах, где цена ошибки высока — например, в медицине или финансах. Неспособность этих метрик отразить подобную «прогностическую множественность» приводит к недооценке рисков и потенциально непоследовательным результатам, требуя разработки более тонких и информативных методов оценки.
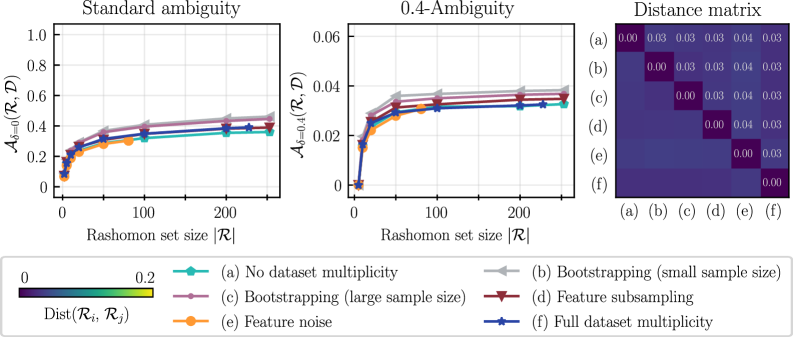
Количественная Оценка Несогласия: Введение в Понятие «Множества Расёмон»
Понятие “множества Расёмон” (Rashomon Set) предоставляет основу для понимания и количественной оценки “предиктивной множественности” (Predictive Multiplicity). Оно определяет совокупность всех сопоставимо точных моделей, которые могут генерировать различные прогнозы для одних и тех же входных данных. Важно отметить, что модели в этом множестве не обязательно являются ошибками; они все соответствуют наблюдаемым данным в пределах допустимой погрешности, но различаются в своих предсказаниях. Таким образом, множество Расёмон иллюстрирует присущую некоторым задачам неоднозначность, когда несколько решений могут быть одинаково обоснованными, что необходимо учитывать при интерпретации результатов моделирования и принятии решений.
Для количественной оценки степени расхождения между моделями, входящими в множество Рашомона, используются метрики “Коэффициент Конфликта” (Conflict Ratio) и “Дельта Неопределенность” (Delta Ambiguity). Коэффициент Конфликта определяет долю случаев, когда различные модели из множества Рашомона дают существенно отличающиеся прогнозы для одного и того же набора данных. Дельта Неопределенность измеряет разброс предсказаний, выдаваемых различными моделями, в отношении конкретной точки данных. Высокие значения этих метрик указывают на значительную неустойчивость индивидуальных предсказаний и повышенную чувствительность к незначительным изменениям в модели или данных, что позволяет выявить проблемные участки в данных или необходимость в более надежных моделях.
Метрики, такие как коэффициент конфликта и дельта-неопределенность, позволяют выявлять точки данных, где наблюдается низкий уровень согласия между моделями. Низкое согласие указывает на потенциальную неустойчивость прогнозов и может сигнализировать о проблемных областях в данных или в процессе моделирования. Выявление этих точек особенно важно для критических приложений, где надежность прогнозов имеет первостепенное значение, поскольку расхождения между моделями могут указывать на необходимость дополнительного анализа данных, пересмотра признаков или использования более надежных алгоритмов. В частности, высокая степень разногласий в определенных точках данных может свидетельствовать о наличии шума, выбросов или неполноты информации, влияющей на процесс обучения моделей.
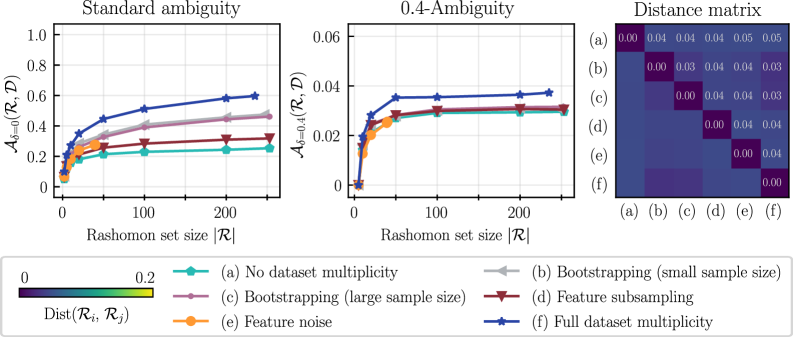
![Сравнительный анализ ad-hoc подхода и TreeFarms[47] на данных COMPAS показал, что использование Rashomon множеств различного размера позволяет оценить δ-неопределённости, сопоставимые с результатами, полученными с помощью TreeFarms, при использовании 1212 признаков и обучении на выборке размером 4144 и тестировании на выборке размером 2763.](https://arxiv.org/html/2602.11944v1/x4.png)
Приближение Неизвестного: Методы Анализа Множества Расёмон
Вычисление полного “набора Расёмон” (Rashomon Set) часто является вычислительно невыполнимой задачей, особенно при работе с моделями высокой сложности или большими объемами данных. Это связано с экспоненциальным ростом числа возможных решений, удовлетворяющих заданным критериям. В связи с этим, для практического анализа и понимания вариативности моделей машинного обучения, широко используются методы аппроксимации. Эти методы позволяют получить репрезентативное подмножество набора Расёмон, достаточное для оценки устойчивости модели и выявления ключевых факторов, влияющих на ее предсказания, при значительно меньших вычислительных затратах.
Для приближенного вычисления множества Рашомона, когда полный перебор невозможен, применяется так называемый ad-hoc подход. Данный метод основан на использовании техники бутстрапа (resampling с возвращением) для генерации множества различных обучающих выборок. На каждой из этих выборок обучаются различные модели машинного обучения, такие как XGBoost и MLP (многослойный персептрон). Полученные модели и составляют репрезентативное подмножество множества Расёмона, позволяя оценить вариативность решений и чувствительность модели к изменениям в данных без необходимости полного перебора всех возможных комбинаций параметров и обучающих выборок.
Для разреженных моделей на основе деревьев решений существуют алгоритмы, такие как TreeFarms, позволяющие вычислить полный набор Рашомона (Rashomon Set) с приемлемыми вычислительными затратами. Данный подход использует пороговое значение целевой функции, равное 0.6236, и точность 0.6536 для включения конкретного дерева в набор Рашомона. Для ограничения вычислительной сложности применяется штраф в 33 конечных узла (leaf nodes), что позволяет эффективно оценивать и отбирать наиболее релевантные модели из пространства возможных деревьев решений.
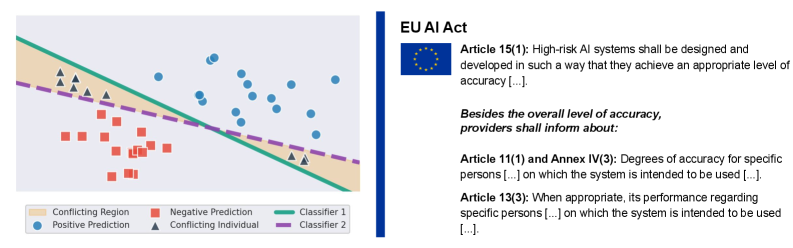
Влияние на Регулирование ИИ и Высокорисковые Системы
Развивающийся нормативный акт, известный как «AI Act», устанавливает строгие требования к оценке точности систем искусственного интеллекта, уделяя особое внимание так называемым “высокорисковым ИИ-системам”. Данный акт предполагает необходимость всесторонней проверки и подтверждения надежности алгоритмов, особенно в областях, где ошибки могут привести к серьезным последствиям для безопасности, здоровья или основных прав человека. Регулирование направлено на обеспечение прозрачности, подотчетности и надежности ИИ-технологий, чтобы минимизировать потенциальные риски и способствовать ответственному внедрению инноваций. Особое внимание уделяется разработке четких критериев и методологий оценки, которые позволят определить, соответствуют ли системы ИИ установленным стандартам безопасности и этическим нормам, а также обеспечить возможность аудита и контроля.
Анализ так называемого “множества Расёмон” представляет собой более тонкий и всесторонний подход к оценке искусственного интеллекта, чем традиционные метрики точности. В отличие от простого определения, правильно ли модель выдает ответ, этот метод выявляет различные решения, которые модель может предложить для одного и того же входного сигнала. Именно это разнообразие и позволяет обнаружить потенциальные уязвимости и слабые места системы, которые остаются незамеченными при стандартных проверках. Если модель демонстрирует значительное расхождение в своих ответах, даже при незначительных изменениях во входных данных, это указывает на нестабильность и непредсказуемость, что особенно критично для систем, работающих в условиях повышенного риска. Таким образом, рассмотрение “множества Расёмона” предоставляет более полное представление о надежности и устойчивости искусственного интеллекта, позволяя заранее выявить и устранить возможные проблемы.
Оценка степени разногласий между моделями искусственного интеллекта позволяет выйти за рамки простого измерения точности, переходя к пониманию причин, лежащих в основе тех или иных прогнозов, и оценке их устойчивости. Традиционные метрики часто игнорируют тот факт, что различные модели могут приходить к одному и тому же результату, опираясь на совершенно разные основания, что делает систему уязвимой к незначительным изменениям входных данных. Анализ, основанный на концепции «множества Расёмона», позволяет выявить эти скрытые различия и оценить, насколько надежны предсказания модели в различных ситуациях. В частности, использование порога в 0.05 для определения включения модели в «множество Расёмона» позволяет количественно оценить степень несогласия и, следовательно, уровень риска, связанного с принятием решений на основе этих моделей. Это особенно важно для систем с высоким уровнем риска, где понимание причинно-следственных связей и надежность предсказаний имеют первостепенное значение.
Исследование показывает, что множественность предсказаний, даже при одинаковой точности, создаёт проблемы для оценки работы отдельных систем ИИ, особенно в контексте AI Act. Это, конечно, неудивительно. Как говорится, Барбара Лисков однажды заметила: «Программы должны быть спроектированы так, чтобы изменения в одной части не приводили к неожиданным последствиям в других». Иными словами, предсказуемость — иллюзия. Разумный разработчик всегда ожидает, что продакшен найдёт способ сломать даже самую элегантную модель, создавая альтернативные, но столь же валидные предсказания. Множественность предсказаний — это не ошибка, а закономерность, которую необходимо учитывать при оценке соответствия высоким требованиям AI Act.
Что дальше?
Предложенный анализ множественности предсказаний, несомненно, указывает на сложность оценки производительности отдельных субъектов в контексте регулирования ИИ. Однако, стоит помнить: каждая элегантная метрика — это всего лишь аппроксимация реальности, а реальность всегда найдёт способ её обойти. Идея о “множестве Расёмона” в применении к системам ИИ высокого риска, безусловно, интересна, но её практическая реализация потребует значительных усилий по сбору и анализу данных — усилий, которые, вероятно, будут потрачены впустую, как только появится следующая, ещё более сложная модель.
Настоящая проблема, как обычно, не в алгоритмах, а в людях. Регулирование может потребовать прозрачности, но кто гарантирует, что эта прозрачность будет понята? А если будет понята, то кто будет нести ответственность за решения, принятые на её основе? Каждая попытка формализовать понятие “справедливости” в коде — это лишь отсрочка неизбежного столкновения с человеческой субъективностью.
В конечном счёте, эта работа — ещё один шаг на пути к созданию всё более сложных систем оценки, которые, вероятно, будут столь же несовершенны, как и те, что им предшествовали. Если код выглядит идеально — значит, его ещё никто не запустил в продакшен. И это, пожалуй, самое важное, что следует помнить.
Оригинал статьи: https://arxiv.org/pdf/2602.11944.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Поймать изменчивый сигнал: Как нейросети расшифровывают политику ФРС
- Молекулярный интеллект: проверка химического мышления
- Оптимизация процессов: симбиоз классических и квантовых вычислений
- Искусственный интеллект и закон: гармония неизбежна
- Звук как помощник зрения: Новые горизонты генерации видео
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Видеосинтез без тормозов: новый подход к генерации видео в реальном времени
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Живые частицы: самоорганизация в новом свете
- От токенов к смыслу: новая стратегия адаптивной обработки больших языковых моделей
2026-02-15 00:25