Автор: Денис Аветисян
Исследователи разработали эффективный метод извлечения информации из научных статей по физике плазмы, основанный на глубоком обучении и автоматической оптимизации параметров.
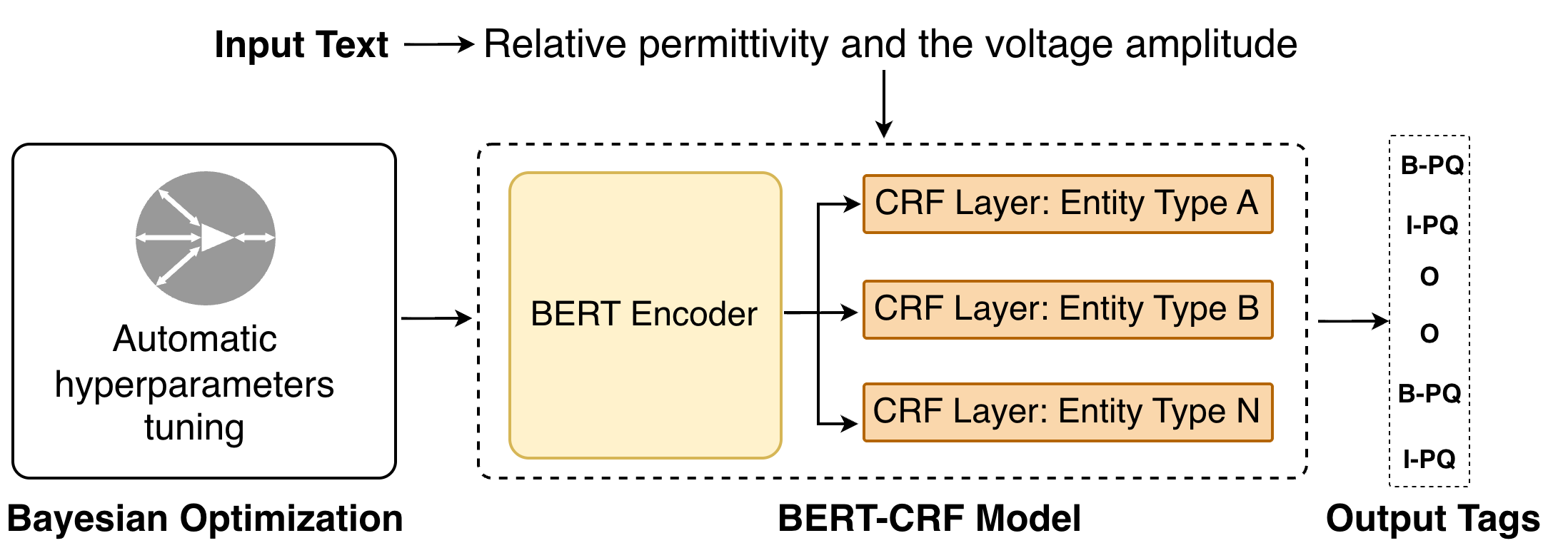
Представлена модель BERT-CRF с использованием байесовской оптимизации для распознавания вложенных именованных сущностей в специализированном наборе данных по физике плазмы.
Извлечение специализированной информации из научных текстов часто затруднено из-за сложности терминологии и контекста. В статье ‘Nested Named Entity Recognition in Plasma Physics Research Articles’ предложен подход к решению этой задачи в области физики плазмы, основанный на методах распознавания именованных сущностей (NER). Разработана модель на базе архитектуры BERT-CRF с применением байесовской оптимизации для автоматической настройки гиперпараметров и достигнуты конкурентоспособные результаты на новом, размеченном корпусе данных. Позволит ли это усовершенствовать поиск и анализ научной литературы в области физики плазмы и открыть новые возможности для автоматизации научных исследований?
Распознавание Скрытого: Вызовы Именованных Сущностей
Извлечение ключевой информации из текстовых данных напрямую зависит от точности распознавания именованных сущностей (Named Entity Recognition, NER), однако стандартные методы часто оказываются недостаточно эффективными в случаях, когда контекст сложен и многогранен. Существующие алгоритмы нередко испытывают трудности при определении границ сущностей, особенно если они представлены в неявном виде или связаны с другими элементами текста. Это приводит к ошибкам в понимании смысла и, как следствие, к неполной или искаженной информации, полученной из анализа текста. Для решения данной проблемы требуется разработка более усовершенствованных методов NER, способных учитывать нюансы контекста и обеспечивать высокую точность распознавания именованных сущностей даже в сложных лингвистических конструкциях.
Традиционные методы распознавания именованных сущностей (NER) часто оказываются неспособными уловить всю сложность объектов, особенно когда их взаимосвязи встроены непосредственно в текст. Вместо того чтобы рассматривать сущности как изолированные элементы, реальный текст часто представляет собой сеть взаимосвязанных понятий, где значение одной сущности зависит от ее отношений с другими. Например, фраза «дочь Ивана», помимо указания на человека, устанавливает родственную связь, которую стандартные алгоритмы NER могут упустить, классифицируя лишь «Иван» и «дочь» как отдельные сущности. Это приводит к неполному пониманию смысла и затрудняет дальнейшую обработку информации, поскольку теряется контекст и связи между ключевыми элементами текста. Поэтому, для эффективного извлечения информации, требуется развитие методов, способных учитывать не только сами сущности, но и их взаимосвязи, представленные в текстовом окружении.
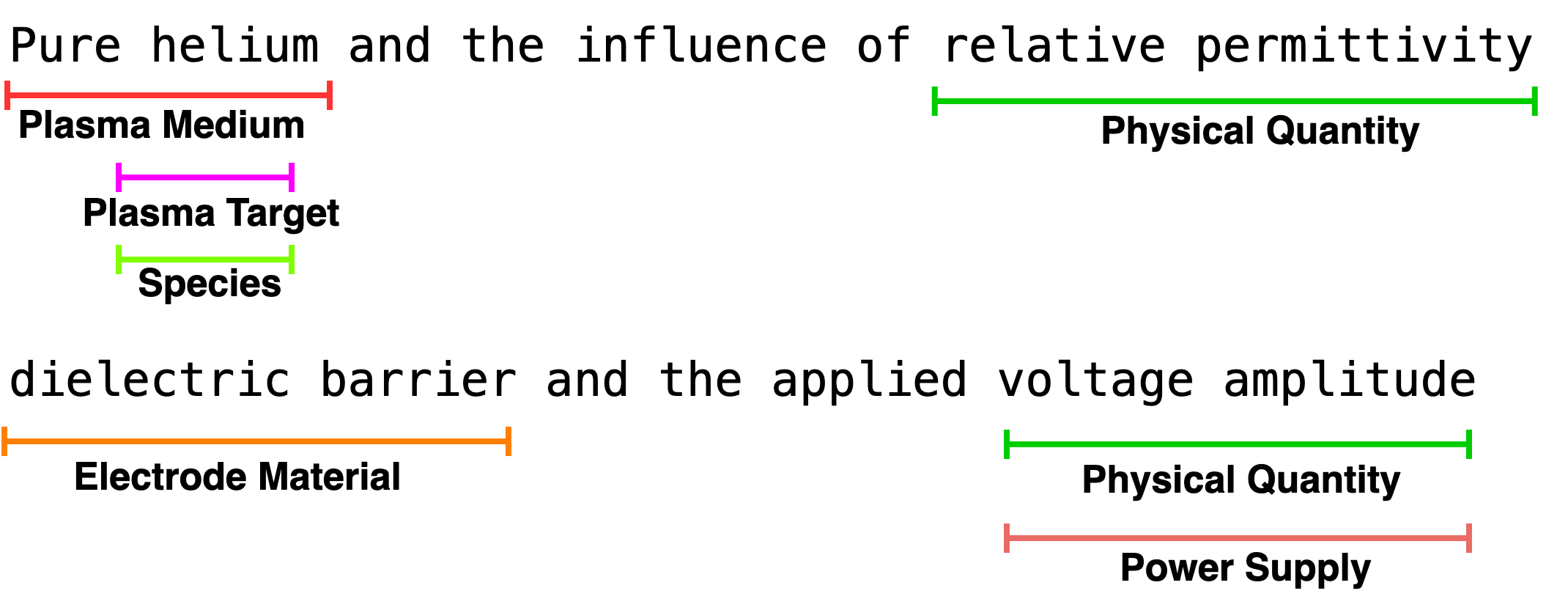
Проблема распознавания именованных сущностей значительно усложняется при наличии перекрывающихся или вложенных элементов. Традиционные методы часто не способны корректно идентифицировать ситуации, когда одна сущность содержится внутри другой или частично перекрывает ее, что приводит к неполной или ошибочной экстракции информации. Например, фраза «Александр Сергеевич Пушкин, автор романа «Евгений Онегин»» требует различения “Александр Сергеевич Пушкин” как единой личности и “Евгений Онегин” как названия произведения, вложенного в описание автора. Для решения этой задачи разрабатываются более сложные алгоритмы, учитывающие контекст, грамматическую структуру предложения и семантические связи между словами, что позволяет обеспечить более надежное и точное извлечение ключевой информации из текста.
Вложенные Сущности: Понимание Иерархии Знаний
Стандартные методы извлечения именованных сущностей (NER) часто не способны корректно обрабатывать случаи, когда одна сущность находится внутри другой или пересекается с ней. Например, в предложении «Президент компании Apple Тим Кук» стандартный NER может распознать только «Тим Кук» как сущность, упуская иерархическую связь — «Apple» является частью названия организации, а «Тим Кук» — ее руководителем. Вложенное NER (Nested NER) направлено на решение этой проблемы, позволяя идентифицировать иерархически связанные сущности и учитывать вложенность одних сущностей в другие, что обеспечивает более полное и точное извлечение информации из текста.
Для выявления иерархических связей между сущностями в тексте применяются методы, такие как рекурсивные условные случайные поля (Recursive-CRF), TreeCRF и многослойные (Layered) подходы. Рекурсивные CRF строят древовидную структуру над текстом, позволяя моделировать отношения между вложенными сущностями. TreeCRF, в свою очередь, использует структуру дерева для представления и анализа иерархии сущностей, что позволяет более эффективно извлекать вложенные структуры. Многослойные подходы применяют последовательное извлечение сущностей, где каждый слой идентифицирует определенный уровень иерархии, а результаты предыдущих слоев используются для уточнения результатов текущего слоя. Все эти методы направлены на преодоление ограничений плоского подхода к распознаванию именованных сущностей, где учитывается только наличие сущности без анализа её взаимосвязи с другими сущностями.
Методы, основанные на моделировании диапазонов (span-based methods), и подходы, использующие Triaffine Attention, повышают точность идентификации вложенных именованных сущностей за счет непосредственного моделирования границ сущностей в тексте. В отличие от традиционных методов, которые рассматривают сущности как отдельные токены, эти подходы рассматривают сущности как диапазоны токенов, что позволяет более эффективно захватывать иерархические отношения между ними. Triaffine Attention, в частности, позволяет моделировать взаимодействия между тремя компонентами — началом, концом и типом сущности — что способствует более точному определению границ и типов вложенных сущностей. Это особенно полезно при анализе сложных текстов, где сущности могут быть вложены друг в друга на несколько уровней.
Экспериментальная Проверка: Наборы Данных и Результаты
Наборы данных GENIA и Chilean Waiting List представляют собой ценные ресурсы для оценки моделей вложенного NER (Named Entity Recognition). При использовании данных GENIA модель демонстрирует F1-оценку в 0.77, а на наборе Chilean Waiting List — 0.79. Эти результаты подтверждают эффективность предложенного подхода к вложенному NER и обеспечивают возможность количественной оценки производительности модели на различных типах текстов и задачах распознавания именованных сущностей.
Комбинация условных случайных полей (Conditional Random Fields, CRF) с векторными представлениями, полученными с помощью модели BERT, демонстрирует высокую эффективность в задачах распознавания именованных сущностей на различных наборах данных. CRF позволяют моделировать зависимости между соседними токенами, что улучшает точность идентификации границ сущностей, в то время как BERT предоставляет контекстуализированные векторные представления слов, улавливая семантические особенности текста. Такой подход позволяет достичь конкурентоспособных результатов по сравнению с другими современными методами, обеспечивая надежную производительность в задачах извлечения информации.
Набор данных по физике плазмы, размеченный для распознавания именованных сущностей, демонстрирует необходимость специализированных наборов данных в сложных научных областях. Данный набор данных, включающий тексты по физике плазмы, был создан для оценки моделей NER в этой узкоспециализированной области. Наша модель, протестированная на этом наборе, достигла строгого показателя F1-меры, основанного на span-определении сущностей, равного 0.68, что указывает на потенциал, но и на необходимость дальнейшей оптимизации моделей для работы со сложной терминологией и структурой научных текстов.
Применение байесовской оптимизации для тонкой настройки моделей BERT-CRF позволило добиться повышения точности и устойчивости. Полученная модель демонстрирует конкурентоспособные результаты, достигая показателя F1 в 0.69, что сопоставимо с лучшими базовыми моделями, при этом сохраняя легковесность архитектуры. Оптимизация параметров модели с использованием байесовского подхода позволила эффективно исследовать пространство гиперпараметров и выявить оптимальную конфигурацию, обеспечивающую высокую производительность без значительного увеличения вычислительной сложности.
Качество и Надежность: Улучшение Извлечения Знаний
Схема BIO представляет собой устоявшийся стандарт для аннотирования текстовых данных и маркировки сущностей, что особенно важно при работе с комплексными наборами данных, такими как набор данных по физике плазмы. Данная схема, основанная на тегах Begin, Inside и Outside, позволяет последовательно идентифицировать границы и типы сущностей внутри текста. Применение схемы BIO обеспечивает согласованность и унификацию процесса разметки, что, в свою очередь, существенно повышает качество обучающих данных для моделей обработки естественного языка. Такой подход позволяет автоматизированным системам более точно извлекать знания и информацию из научных текстов, способствуя развитию исследований в области физики плазмы и смежных дисциплин.
Для более точного выявления и классификации вложенных сущностей в данных, таких как те, что встречаются в наборах данных физики плазмы, применяются гиперграфовые модели и многоголовые плотно-аугментированные модели условных случайных полей (CRF). Гиперграфы позволяют моделировать сложные взаимосвязи между сущностями, учитывая, что одна сущность может быть частью другой. Многоголовый подход в CRF, в свою очередь, позволяет учитывать различные аспекты контекста и улучшает способность модели различать сложные случаи вложенности. Такое сочетание технологий значительно повышает качество извлечения информации и обеспечивает более глубокое понимание структуры данных, что особенно важно для задач, требующих высокой точности и полноты извлечения знаний.
Значительные усовершенствования в области вложенного извлечения именованных сущностей (Nested NER) открывают новые возможности для автоматизированного обнаружения и анализа знаний в больших текстовых массивах. Разработанная модель демонстрирует впечатляющую эффективность, достигая показателя полноты в 0.74 — наивысшего среди сопоставимых методов. Это позволяет более точно извлекать сложные взаимосвязи между сущностями, что критически важно для задач интеллектуального анализа данных, автоматического построения баз знаний и повышения качества работы систем обработки естественного языка, таких как чат-боты и системы машинного перевода. Улучшенная точность извлечения информации способствует более глубокому пониманию сложных научных текстов и ускоряет процесс открытия новых знаний в различных областях, включая физику плазмы и другие научные дисциплины.
Исследование демонстрирует, что даже относительно легковесные модели, такие как BERT-CRF, способны достигать конкурентоспособных результатов в задаче извлечения информации, если правильно подобраны гиперпараметры. Автоматическая настройка этих параметров с помощью байесовской оптимизации позволяет раскрыть потенциал модели и эффективно обрабатывать специфические данные, в данном случае, статьи по физике плазмы. Как точно заметила Барбара Лисков: «Программы должны быть спроектированы так, чтобы изменения в одной части не приводили к неожиданным последствиям в других». Этот принцип особенно важен при разработке систем извлечения информации, где даже незначительные изменения в параметрах модели могут существенно повлиять на точность и надежность результатов, особенно в узкоспециализированной области, такой как физика плазмы.
Что дальше?
Представленная работа демонстрирует, что даже в, казалось бы, устоявшихся областях, таких как извлечение информации, можно найти лазейки для оптимизации. Автоматическая настройка гиперпараметров, примененная к относительно легковесной модели BERT-CRF, обнажила неожиданную эффективность. Однако, стоит признать, что настоящий хаос заключается не в случайности, а в неполноте данных. Созданный домен-специфичный набор данных, безусловно, шаг вперед, но он лишь верхушка айсберга. Истинная сложность физики плазмы проявляется в нюансах, упущенных при аннотации, в контекстах, которые модель пока не способна уловить.
Следующим этапом видится не столько усложнение модели, сколько расширение горизонтов данных. Необходимо сместить фокус с простого распознавания именованных сущностей на понимание отношений между ними — выявление неявных связей, которые формируют основу физических процессов. Возможно, стоит обратиться к графовым нейронным сетям, способным моделировать сложные взаимосвязи. Или, что еще интереснее, попробовать обойти проблему машинного обучения вовсе, обратившись к символьному выводу и знаниям, закодированным в физических принципах.
В конечном итоге, задача состоит не в создании идеального алгоритма, а в построении системы, способной адаптироваться к неполноте и противоречивости информации. Ведь именно в этих несовершенствах и кроется истинная красота и сложность физического мира. Задача не в том, чтобы взломать код, а понять архитектуру, лежащую в основе хаоса.
Оригинал статьи: https://arxiv.org/pdf/2602.11163.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Звук как помощник зрения: Новые горизонты генерации видео
- Поймать изменчивый сигнал: Как нейросети расшифровывают политику ФРС
- Молекулярный интеллект: проверка химического мышления
- Искусственный интеллект и закон: гармония неизбежна
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Видеосинтез без тормозов: новый подход к генерации видео в реальном времени
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Оптимизация процессов: симбиоз классических и квантовых вычислений
- Социальные сети: Искусство правдоподобных взаимодействий
- Нейросети на резистивной памяти: Новый подход к решению сложных задач
2026-02-15 02:22