Автор: Денис Аветисян
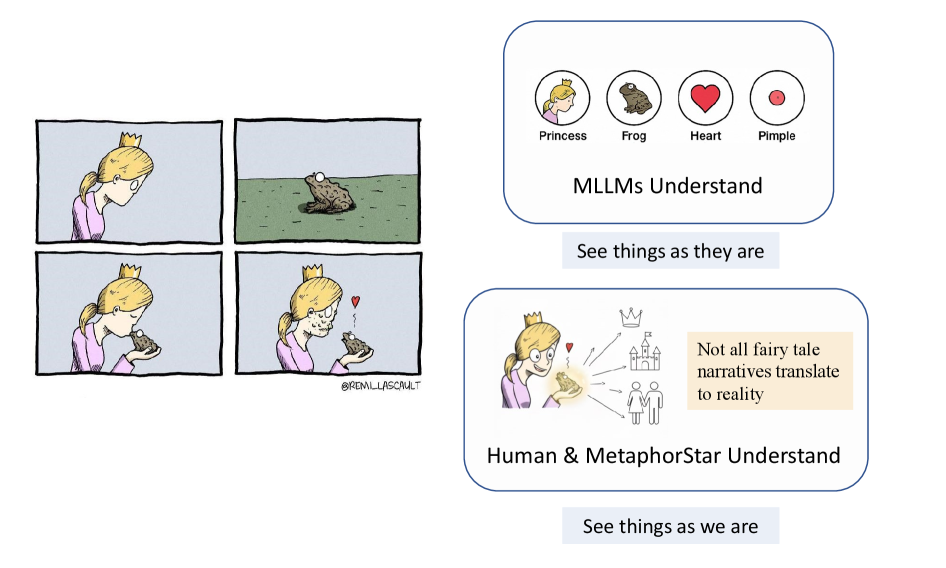
Новая модель MetaphorStar демонстрирует значительный прогресс в понимании и интерпретации скрытых смыслов на изображениях, расширяя возможности мультимодальных систем.
Представлен фреймворк обучения с подкреплением для анализа импликаций изображений и выполнения сложных задач визуального рассуждения.
Несмотря на успехи современных мультимодальных больших языковых моделей, понимание образных значений в изображениях остается сложной задачей. В данной работе, посвященной разработке системы ‘MetaphorStar: Image Metaphor Understanding and Reasoning with End-to-End Visual Reinforcement Learning’, предложен новый подход, основанный на обучении с подкреплением, для решения задач интерпретации скрытых смыслов в визуальном контенте. Предложенный фреймворк MetaphorStar, включающий датасет TFQ-Data и алгоритм TFQ-GRPO, демонстрирует значительное превосходство над существующими моделями в задачах визуального рассуждения и понимания метафор, превосходя даже Gemini-3.0-pro. Способны ли подобные системы, обученные на понимании сложных образных значений, расширить границы возможностей искусственного интеллекта в области общего понимания и рассуждения?
За пределами видимого: Понимание скрытого смысла изображений
Современные мультимодальные модели демонстрируют впечатляющие результаты в задачах визуального вопросно-ответного взаимодействия, однако их способность к глубокому пониманию изображений остается ограниченной. Несмотря на умение распознавать объекты и отвечать на прямые вопросы, модели часто испытывают трудности при анализе контекста и выявлении скрытых смыслов. В то время как распознавание конкретных элементов на изображении происходит с высокой точностью, понимание общих намерений, эмоций или ситуаций, представленных визуально, остается сложной задачей. Это указывает на существенный разрыв между поверхностным распознаванием и истинным пониманием, подчеркивая необходимость разработки моделей, способных к более сложному анализу визуальной информации.
Истинный интеллект проявляется не только в распознавании объектов на изображении, но и в понимании скрытых смыслов, неявно заложенных в визуальном контексте. Способность улавливать импликации — то, что не сказано напрямую, а подразумевается ситуацией — является ключевым признаком когнитивных способностей. Например, изображение улыбающегося человека на фоне подарков не просто фиксирует наличие человека, улыбки и подарка; оно подразумевает празднование, радость и положительные эмоции. Понимание этих неявных связей требует от системы способности к логическим выводам и обобщению знаний о мире, что выходит за рамки простого сопоставления визуальных признаков с метками. Отсутствие этой способности ограничивает возможности современных мультимодальных моделей, снижая их эффективность в задачах, требующих глубокого понимания визуальной информации.
Существующий разрыв в возможностях современных мультимодальных моделей указывает на необходимость перехода от простого распознавания объектов к пониманию скрытых смыслов и импликаций в визуальном контексте. Исследования показывают, что текущие системы, демонстрирующие успехи в визуальных вопросах и ответах, часто испытывают затруднения при интерпретации нюансов, не выраженных явно на изображении. В задачах, требующих вывода неявных значений, производительность моделей снижается на 20% и более, что подчеркивает потребность в более сложных алгоритмах, способных к логическому мышлению и умозаключениям на основе визуальной информации. Преодоление этого пробела является ключевым шагом к созданию искусственного интеллекта, способного к действительно глубокому пониманию окружающего мира.
MetaphorStar: Обучение с подкреплением для визуального рассуждения
В основе MetaphorStar лежит обучение с подкреплением (Reinforcement Learning, RL), где агенты обучаются «интерпретации» изображений посредством максимизации сигнала вознаграждения. Этот процесс предполагает, что агент, взаимодействуя с визуальными данными, выполняет определенные действия, за которые получает положительное или отрицательное вознаграждение. Алгоритмы RL используются для оптимизации стратегии агента, направленной на максимизацию суммарного вознаграждения, что позволяет ему постепенно осваивать способность к более сложным формам визуального рассуждения и извлечения смысла из изображений, выходящих за рамки простого распознавания объектов.
В основе MetaphorStar лежит модель QwenVL, представляющая собой предварительно обученную архитектуру для обработки визуальной информации. Использование QwenVL в качестве фундамента позволяет системе эффективно извлекать признаки из изображений и устанавливать связи между визуальными элементами. Дополнительное обучение с подкреплением (Reinforcement Learning) не изменяет базовую архитектуру QwenVL, а скорее настраивает её для решения конкретной задачи визуального рассуждения, повышая её способность к пониманию скрытых смыслов и неявных связей в изображениях. Этот подход позволяет MetaphorStar превзойти возможности QwenVL в задачах, требующих более глубокого анализа и интерпретации визуального контента.
Ключевым нововведением MetaphorStar является способность обучаться политикам, которые сопоставляют визуальные входные данные с подразумеваемыми смыслами, выходя за рамки простого распознавания объектов. В отличие от систем, ограничивающихся идентификацией видимых элементов, MetaphorStar формирует понимание контекста и скрытых значений в изображениях. Это достигается посредством обучения с подкреплением, позволяющего агенту разрабатывать стратегии интерпретации визуальной информации. В результате, на стандартных бенчмарках для оценки понимания подразумеваемых значений в изображениях, MetaphorStar демонстрирует среднее улучшение производительности на 82.6%.
TFQ-Bench: Оценка понимания подразумеваемого через целенаправленные вопросы
Набор данных TFQ-Data был разработан для детальной оценки способности моделей понимать подразумеваемый смысл изображений. В отличие от существующих наборов данных, ориентированных на общие категории объектов или сцен, TFQ-Data содержит тщательно отобранные изображения и связанные с ними вопросы в формате «истина/ложь», требующие от модели вывода информации, неявно представленной на изображении. Это достигается за счет фокусировки на тонких деталях и контексте, что позволяет более точно измерить способность модели к интерпретации визуальной информации и выявлению подразумеваемых связей.
TFQ-Bench — это оценочный набор данных, использующий формат вопросов с ответами «истина/ложь» (TFQ) для проверки способности моделей понимать подразумеваемый смысл изображений. В рамках TFQ-Bench модели сталкиваются с вопросами, требующими интерпретации визуального контента и определения соответствия утверждений представленному изображению. Такой подход позволяет более точно оценить не просто распознавание объектов на изображении, а именно понимание контекста и скрытых смыслов, которые могут быть подразумеваются визуальной информацией. Формат «истина/ложь» обеспечивает строгий критерий оценки, требующий от модели точной интерпретации и логического вывода.
Метод TFQ-GRPO продемонстрировал наилучшие результаты на бенчмарке TFQ-Bench, достигнув точности в 84% с использованием модели MetaphorStar-7B. Данный показатель является текущим лидером среди протестированных моделей на данном наборе данных, предназначенном для оценки способности к интерпретации и пониманию имплицитных связей в изображениях. Точность оценивалась на основе ответов на вопросы в формате «истина/ложь», проверяющих понимание взаимосвязей между визуальными элементами и представленными утверждениями.
В ходе оценки на базе TFQ-Bench модель MetaphorStar-3B продемонстрировала превосходство над Gemini-3.0-pro в задаче определения импликаций. MetaphorStar-3B достигла точности 62% при ответе на вопросы в формате «истина/ложь» (TFQ), в то время как Gemini-3.0-pro показала результат в 58%. Данное сравнение подтверждает более высокую способность MetaphorStar-3B к интерпретации визуальной информации и выявлению скрытых смыслов, представленных на изображениях.
За пределами распознавания: Широкое влияние на искусственный интеллект
Успех MetaphorStar наглядно демонстрирует, что истинная ценность искусственного интеллекта заключается не только в распознавании поверхностных визуальных признаков, но и в способности к подлинному пониманию. В отличие от систем, ограничивающихся идентификацией объектов на изображении, данная разработка стремится к интерпретации скрытых смыслов и неявных связей. Это означает переход от простого «видения» к способности делать выводы, улавливать контекст и понимать намерения, что открывает новые горизонты в области визуального мышления и приближает искусственный интеллект к способности к теории разума — способности, традиционно считавшейся прерогативой человеческого интеллекта. Такой подход позволяет системе не просто отвечать на вопросы о том, что изображено, а понимать почему и какие последствия могут быть связаны с изображенным.
Разработанная система не ограничивается простым распознаванием визуальных образов, а активно моделирует имплицитные связи и скрытые смыслы, что значительно расширяет границы визуального рассуждения. Этот подход, моделируя процесс вывода заключений на основе неявной информации, приближает искусственный интеллект к пониманию так называемой “теории разума” — способности приписывать ментальные состояния другим агентам. По сути, система учится не только видеть, что изображено на картинке, но и понимать, почему это изображено, и какие последствия это может иметь, что открывает новые возможности для создания более интеллектуальных и адаптивных систем искусственного интеллекта.
Представленная система продемонстрировала впечатляющие результаты в задачах визуального рассуждения, превзойдя существующие модели искусственного интеллекта. В тестах с выбором одного ответа, система достигла точности в 76%, что значительно выше показателей Gemini-3.0-pro. Еще более заметно превосходство в задачах с открытым ответом, где система получила оценку 3.94, тогда как Gemini-3.0-pro — всего 3.82. Данные результаты подтверждают эффективность разработанного подхода к моделированию имплицитных знаний и его потенциал для создания более интеллектуальных и способных к рассуждению систем искусственного интеллекта.
Способность к пониманию подразумеваемого, невысказанного, имеет решающее значение для областей, требующих тонких суждений и сложного анализа. В контексте автономных систем принятия решений, например, робот или автомобиль, нуждается не просто в распознавании объектов, но и в интерпретации намерений и прогнозировании действий других участников среды. Аналогично, в сфере взаимодействия человека и компьютера, система, способная улавливать скрытые смыслы, может обеспечить более естественный и эффективный диалог, адаптируясь к потребностям пользователя и предвосхищая его запросы. Отсутствие этой способности ограничивает возможности искусственного интеллекта, превращая его в инструмент, способный лишь к формальному анализу данных, но не к истинному пониманию контекста и целей.
Будущие направления: Интеграция контекста и неявных знаний
Интеграция методов контекстного выравнивания значительно расширяет возможности модели в использовании внешних знаний и культурных отсылок. Данный подход позволяет не просто распознавать объекты на изображении, но и понимать их значение в более широком контексте, учитывая исторические, социальные и культурные нюансы. Например, модель, обученная с применением этих техник, способна интерпретировать символику, скрытую в изображении, или понимать аллюзии, основанные на общеизвестных культурных кодах. Это достигается путем сопоставления визуальной информации с обширной базой знаний, включающей исторические факты, литературные произведения и другие источники культурного наследия, что позволяет модели генерировать более осмысленные и релевантные ответы, выходящие за рамки простого визуального анализа.
Исследования показали, что внедрение методов неявного рассуждения, в частности, подхода “Цепочка мыслей” (Chain-of-Thought), значительно расширяет возможности модели извлекать смысл из тонких визуальных подсказок. Данный метод позволяет системе не просто идентифицировать объекты на изображении, но и последовательно анализировать взаимосвязи между ними, делая логические выводы, аналогичные человеческому мышлению. Вместо прямого сопоставления изображения с ответом, модель строит цепочку рассуждений, объясняющую, как она пришла к определенному заключению, что позволяет ей успешно справляться с задачами, требующими понимания контекста и скрытых смыслов. Такой подход особенно полезен при анализе сложных визуальных сцен, где значение определяется не только видимыми объектами, но и их взаимным расположением, освещением и другими нюансами.
Исследования показали, что применение разработанного подхода к задачам открытого типа (Open-Style Question, OSQ) и множественного выбора (Multiple-Choice Question, MCQ) приводит к заметному улучшению результатов. В частности, способность системы эффективно оперировать с метафорическими связями, выявленными в изображениях, позволяет ей точнее отвечать на вопросы, требующие не просто распознавания объектов, но и понимания скрытого смысла и контекста. Такая универсальность демонстрирует потенциал данной методологии для широкого спектра задач компьютерного зрения и обработки естественного языка, где важна способность к логическому выводу и интерпретации визуальной информации, выходящей за рамки прямого восприятия.
Семейство моделей MetaphorStar демонстрирует значительный прогресс в понимании скрытых смыслов изображений, достигая в среднем 82.6% улучшения результатов на стандартных бенчмарках, оценивающих способность к выявлению импликаций. Такой существенный прирост производительности указывает на эффективность предложенного подхода к анализу визуальной информации и интерпретации метафорических связей. Данный показатель подтверждает, что модели способны не просто распознавать объекты на изображении, но и делать обоснованные выводы о более глубоком контексте и подразумеваемых значениях, что открывает перспективы для развития систем компьютерного зрения, способных к более тонкому и человекоподобному пониманию визуального мира.
Исследование, представленное в данной работе, демонстрирует стремление к элегантности в решении сложных задач визуального рассуждения. MetaphorStar, используя подход обучения с подкреплением, не просто улучшает показатели существующих моделей, но и открывает новые возможности для понимания метафор в изображениях. Этот фреймворк, подобно хорошо спроектированному интерфейсу, позволяет моделям не только отвечать на вопросы типа «истинно-ложно», но и глубже понимать имплицитные значения, заложенные в визуальном контенте. Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект должен быть направлен на расширение человеческих возможностей, а не на их замену». MetaphorStar, безусловно, соответствует этому принципу, предоставляя инструменты для более глубокого и интуитивного взаимодействия человека с машиной.
Куда же дальше?
Представленная работа, безусловно, вносит гармонию в какофонию попыток научить машины понимать неявное. MetaphorStar, словно искусно настроенный инструмент, демонстрирует способность к визуальному рассуждению, но даже самая совершенная скрипка нуждается в мастере. Остаётся открытым вопрос о масштабируемости: насколько легко этот подход адаптируется к более сложным, многослойным метафорам, где образные связи требуют не просто распознавания, но и понимания контекста, культурных нюансов, даже иронии?
Важно понимать, что успех в решении задач TFQ-GRPO — это лишь первый аккорд. Настоящая симфония понимания потребует преодоления разрыва между корреляцией и причинностью. Машина может научиться предсказывать, но сможет ли она понять, почему определенный образ является метафорой для другого? Каждая деталь важна, даже та, которую не замечают, и пока что, кажется, что мы лишь касаемся поверхности этой сложной проблемы.
Дальнейшие исследования, вероятно, потребуют интеграции с более широкими моделями знаний, с учётом не только визуальной информации, но и лингвистического, и даже эмпирического опыта. Возможно, потребуется сместить акцент с обучения на конкретных примерах на создание моделей, способных к абстрактному мышлению и генерации собственных метафор — то есть, к настоящему творчеству, а не просто к имитации.
Оригинал статьи: https://arxiv.org/pdf/2602.10575.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый импульс для нейросетей: новый подход к распознаванию изображений
- Искусственный интеллект и квантовая физика: кто кого?
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Взрыв скорости: Оптимизация внимания для современных GPU
- Знаем, чего не знаем: Моделирование вероятностных рассуждений на основе множественных доказательств
- Искусственный интеллект в действии: как расширяется сфера возможностей?
- Языковые модели и границы возможного: что делает язык человеческим?
- Учимся с интересом: как создать AI-репетитора, вдохновлённого лучшими учителями
- Траектория Рассуждений: Новая Стратегия для Больших Языковых Моделей
- Адаптивная точность: Новый подход к ускорению больших языковых моделей
2026-02-15 15:32