Автор: Денис Аветисян
Новое исследование показывает, как большие языковые модели могут автоматизировать процесс одновременного развития грамматики и примеров кода в предметно-ориентированных языках (DSL), сохраняя при этом читаемость и понятность кода.
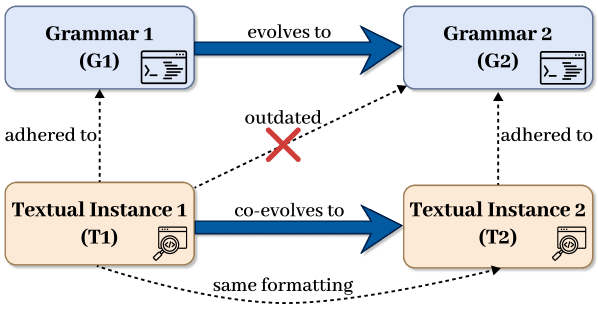
Систематическая оценка использования больших языковых моделей для коэволюции определений и экземпляров текстовых DSL.
Эволюция языков предметной области (DSL) часто сталкивается с проблемой поддержания соответствия между грамматикой и существующими экземплярами кода при внесении изменений. В работе ‘Leveraging LLMs to support co-evolution between definitions and instances of textual DSLs: A Systematic Evaluation’ систематически оценивается потенциал больших языковых моделей (LLM) для автоматической совместной эволюции грамматик и экземпляров текстовых DSL, сохраняя при этом важные для человека элементы, такие как комментарии и форматирование. Результаты показывают высокую эффективность LLM в небольших проектах, однако производительность снижается с увеличением масштаба, а время отклика значительно возрастает. Каковы перспективы дальнейшей оптимизации LLM для поддержки эволюции DSL в сложных, крупномасштабных проектах?
Иллюзии и Ограничения Больших Языковых Моделей
Современные большие языковые модели демонстрируют впечатляющие способности в обработке естественного языка, успешно генерируя текст, переводя языки и отвечая на вопросы. Однако, несмотря на значительный прогресс, эти модели часто сталкиваются с трудностями при решении задач, требующих глубокого понимания контекста, абстрактного мышления или применения знаний в новых ситуациях. Несмотря на способность обрабатывать огромные объемы данных, LLM могут допускать логические ошибки или выдавать неправдоподобные ответы, особенно в ситуациях, требующих критического анализа и здравого смысла. Это ограничение связано с тем, что модели обучаются на основе статистических закономерностей в данных, а не на реальном понимании мира, что создает разрыв между их кажущейся компетентностью и фактической способностью к рассуждению.
Несмотря на впечатляющие масштабы и способность генерировать связные тексты, большие языковые модели (LLM) часто демонстрируют трудности при решении задач, требующих глубокого понимания контекста или тонкого извлечения информации. Этот разрыв между потенциалом и реальной производительностью обусловлен тем, что модели, по сути, оперируют статистическими закономерностями в данных, а не истинным пониманием смысла. В результате, LLM могут успешно имитировать рассуждения, но часто терпят неудачу в ситуациях, требующих критического анализа, творческого подхода или учета неоднозначности. Хотя модели способны обрабатывать огромные объемы данных, они испытывают сложности с обобщением знаний и применением их в новых, нестандартных ситуациях, что ограничивает их применимость в задачах, требующих адаптивности и гибкости мышления.
Оценка больших языковых моделей (БЯМ) требует применения более сложных метрик, чем простая точность. Исследования показывают, что ключевым является способность модели следовать инструкциям и обобщать полученные знания для решения новых задач. Например, в ходе недавних испытаний, модель Claude Sonnet 4.5 продемонстрировала впечатляющие результаты, достигнув точности до 98.56% и полноты до 97.5% при выполнении конкретных заданий. Такие показатели свидетельствуют о прогрессе в разработке БЯМ, однако подчеркивают важность фокусировки на качественной оценке, выходящей за рамки стандартных тестов на соответствие и охватывающей способность к адаптации и пониманию контекста.
Улучшение Рассуждений: Методы и Техники
Проектирование запросов (Prompt Engineering) является основополагающей техникой оптимизации производительности больших языковых моделей (LLM). Суть подхода заключается в тщательной разработке входных запросов, направленных на то, чтобы направить модель к желаемому ответу. Эффективное проектирование запросов включает в себя не только формулировку вопроса, но и структурирование информации, предоставление контекста, а также использование ключевых слов и фраз, которые помогают модели лучше понять задачу и выдать более релевантный и точный результат. Успех данной техники напрямую зависит от понимания принципов работы конкретной LLM и особенностей её обучения, что позволяет создавать запросы, максимально эффективно использующие её возможности.
Метод «Chain of Thought» (Цепочка Мыслей) представляет собой усовершенствование техник промт-инжиниринга, направленное на повышение точности и прозрачности ответов больших языковых моделей (LLM). Суть подхода заключается в стимулировании LLM к последовательному изложению этапов рассуждений, предшествующих выдаче конечного ответа. Вместо прямого предоставления ответа, модель обучается генерировать промежуточные шаги логических выводов, что позволяет не только улучшить корректность результатов, но и обеспечить возможность анализа процесса принятия решений моделью. Данный подход особенно эффективен в задачах, требующих многоступенчатого логического мышления и объяснения принятых решений.
Несмотря на эффективность методов, таких как проектирование запросов и последовательное рассуждение, производительность больших языковых моделей (LLM) ограничена объемом встроенных знаний. Для повышения точности и расширения возможностей требуется интеграция внешних источников информации. Исследования показывают, что модели, такие как Claude Sonnet 4.5, способны сохранять человеко-ориентированную информацию со 100%-ным удержанием комментариев при выполнении определенных задач, что демонстрирует потенциал для эффективного использования внешних знаний и поддержания контекста.
Расширение Знаний: Поиск и Обучение с Небольшим Количеством Примеров
Метод генерации с расширением извлечением (Retrieval Augmented Generation, RAG) значительно повышает производительность больших языковых моделей (LLM) в задачах, требующих обширных знаний. В основе RAG лежит динамическое извлечение релевантной информации из внешних источников данных непосредственно во время генерации ответа. Это позволяет LLM преодолеть ограничения, связанные с объемом знаний, заложенных в процессе предварительного обучения, и предоставлять более точные и контекстуально обоснованные ответы. Вместо того, чтобы полагаться исключительно на параметры модели, RAG дополняет их актуальной информацией, извлеченной из баз знаний, документов или других внешних ресурсов.
Комбинирование генерации с поиском (RAG) и обучения с небольшим количеством примеров (Few-Shot Learning) позволяет большим языковым моделям (LLM) адаптироваться к новым задачам, требуя минимального количества обучающих данных. Синергия между этими подходами заключается в том, что RAG предоставляет LLM релевантную информацию из внешних источников, а обучение с небольшим количеством примеров позволяет модели эффективно использовать эту информацию для выполнения задачи. Такой подход значительно расширяет возможности LLM, позволяя им выходить за рамки предварительно обученных знаний и адаптироваться к новым требованиям, используя только небольшое количество примеров, что демонстрирует значительное повышение эффективности и гибкости.
Использование подхода, позволяющего языковым моделям (LLM) выходить за рамки предварительно обученных знаний и получать доступ к релевантной информации для конкретной задачи, демонстрирует значительное повышение эффективности. В ходе тестирования Claude Sonnet 4.5 показал 96.60% точность сохранения формата ответа в десяти тестовых языках. В то же время, средняя точность GPT-5.2 составила 71.44%. Эти результаты подтверждают, что динамический доступ к внешним источникам информации позволяет LLM адаптироваться к новым задачам и улучшать качество генерируемых ответов.
Масштаб и Возникновение: Роль Размера Модели
Масштаб модели является определяющим фактором, влияющим на возможности больших языковых моделей (LLM). Исследования последовательно демонстрируют, что увеличение количества параметров в модели приводит к значительному улучшению производительности в широком спектре задач — от простого перевода и обобщения текста до решения сложных логических головоломок и написания креативного контента. Этот прогресс не является линейным; часто наблюдается, что увеличение масштаба приводит к экспоненциальному росту возможностей, позволяя моделям осваивать новые навыки и демонстрировать более глубокое понимание языка и мира. Таким образом, масштаб модели представляет собой ключевой фактор для раскрытия всего потенциала LLM и достижения новых рубежей в области искусственного интеллекта.
В крупных языковых моделях часто наблюдаются так называемые «возникающие способности» — навыки, которые отсутствуют у моделей меньшего размера и проявляются только при достижении определенного масштаба. Эти способности не являются просто улучшением существующих, а представляют собой качественно новые возможности, особенно в области сложного рассуждения, решения проблем и понимания контекста. Исследования показывают, что по мере увеличения количества параметров модели, она начинает демонстрировать неожиданные навыки, такие как способность к многоступенчатому планированию, обобщению знаний из различных источников и даже к решению задач, которые явно не были предусмотрены при обучении. Данный феномен указывает на то, что масштабирование может раскрыть скрытый потенциал в архитектуре языковых моделей, однако требует внимательного изучения и оценки для понимания границ и возможностей этих новых способностей.
Увеличение масштаба языковых моделей демонстрирует не только постепенное улучшение существующих возможностей, но и появление принципиально новых, ранее не наблюдаемых свойств — так называемых эмерджентных способностей. Исследования показывают, что по мере роста числа параметров модели, она начинает проявлять навыки, такие как сложное рассуждение и понимание контекста, которые отсутствуют у более компактных аналогов. Однако, это требует внимательной оценки и понимания этих новых возможностей, поскольку их поведение может быть непредсказуемым. Например, зафиксировано, что Claude Sonnet 4.5 в среднем формирует ответ за 80.71 секунды, в то время как GPT-5.2 справляется с этой задачей значительно быстрее — за 36.57 секунды, что подчеркивает важность оптимизации и эффективности масштабированных моделей.
Исследование демонстрирует, что автоматическая совместная эволюция грамматик и экземпляров текстовых DSL с помощью больших языковых моделей не просто оптимизирует синтаксис, но и позволяет сохранить читаемость кода, включая комментарии и форматирование. Это особенно важно, поскольку, как отмечал Марвин Мински: «Лучший способ понять — это создать». Данная работа показывает, что LLM способны не просто анализировать существующие структуры, но и активно участвовать в их развитии, адаптируясь к изменяющимся требованиям и поддерживая эволюцию DSL, что соответствует принципу создания развивающихся систем, а не жестко заданных инструментов. Подход, описанный в статье, подчеркивает, что настоящая устойчивость начинается там, где кончается уверенность в неизменности системы.
Что же дальше?
Представленная работа демонстрирует возможность автоматической коэволюции грамматик и экземпляров текстовых DSL при помощи больших языковых моделей. Однако, это лишь первый шаг к созданию систем, которые способны не просто адаптироваться к изменениям, но и предвидеть их. Каждый новый деплой — маленький апокалипсис, и каждая автоматическая модификация грамматики — потенциальная катастрофа, замаскированная под эволюцию. Очевидно, что истинная проблема заключается не в автоматизации процесса, а в создании механизмов, которые позволяют контролировать энтропию в этой сложной экосистеме.
Следующим этапом представляется исследование методов верификации и валидации автоматически модифицированных грамматик. Проверка на соответствие не только формальным спецификациям, но и неявным ожиданиям пользователей — задача, которая требует гораздо большего, чем просто тестирование. А документация? Никто не пишет пророчества после их исполнения. Важнее — разработка самодокументирующихся DSL, способных объяснять логику своих изменений.
В конечном счете, успех этого направления зависит не от мощности языковых моделей, а от способности разработчиков смириться с тем, что системы — это не инструменты, а экосистемы. Их нельзя построить, только взрастить. А взращивание требует терпения, смирения и готовности к неожиданностям. И, конечно, осознания, что каждое решение — это пророчество о будущей ошибке.
Оригинал статьи: https://arxiv.org/pdf/2602.11904.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект и закон: гармония неизбежна
- Искусственный интеллект: хрупкость визуального мышления
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Нейросети, повинующиеся физике: новый подход к моделированию сложных систем
- Квантовые модели для моделирования потоков: новый взгляд на сжатие данных
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Эволюция Научного Поиска: Как Причинно-Следственный Подход Ускоряет Открытия
- Польский язык обретает свой интеллект
2026-02-15 22:28