Автор: Денис Аветисян
Новое исследование показывает, что правильно масштабируемые открытые языковые модели способны конкурировать с проприетарными системами в задачах многоязыкового машинного перевода.
В статье рассматривается влияние масштабирования моделей и данных на качество многоязыкового машинного перевода с использованием открытых больших языковых моделей, включая методы непрерывного обучения и тонкой настройки.
Несмотря на значительные успехи в машинном переводе, адаптация открытых больших языковых моделей (LLM) для эффективной многоязыковой обработки остается сложной задачей. В данной работе, ‘Scaling Model and Data for Multilingual Machine Translation with Open Large Language Models’, исследуется влияние масштабирования модели и данных на качество многоязыкового машинного перевода с использованием открытых LLM, включая разработку MiLMMT-46. Полученные результаты демонстрируют, что тщательно масштабированные открытые модели способны конкурировать с проприетарными системами, такими как Google Translate и Gemini 3 Pro, превосходя при этом современные открытые модели, включая Seed-X и HY-MT-1.5. Возможно ли дальнейшее повышение эффективности открытых LLM в многоязыковом машинном переводе за счет инновационных стратегий обучения и расширения обучающих данных?
Вызов многоязыкового перевода: Сложность и нюансы
Многоязычный машинный перевод (ММП) является ключевым фактором для обеспечения глобальной коммуникации в современном мире, однако существующие модели зачастую сталкиваются с трудностями при передаче тонких нюансов языка. Несмотря на значительный прогресс в области искусственного интеллекта, сохраняется проблема адекватной передачи идиоматических выражений, культурных коннотаций и стилистических особенностей при переводе с одного языка на другой. Это связано с тем, что языки существенно различаются не только в лексике и грамматике, но и в способах выражения мыслей и восприятия мира. В результате, даже самые передовые системы ММП могут допускать ошибки, искажающие смысл оригинального текста или приводящие к неестественному звучанию перевода, что особенно критично в сферах, требующих высокой точности и культурной чувствительности.
Современные большие языковые модели, такие как серии GPT и Gemini, демонстрируют впечатляющие возможности в области машинного перевода, однако их применение сопряжено со значительными вычислительными затратами и потребностью в огромных объемах данных для обучения. Эти модели, основанные на сложных нейронных сетях, требуют мощного оборудования и значительных энергетических ресурсов для эффективной работы, что ограничивает их доступность и масштабируемость. Кроме того, для достижения высокой точности перевода требуется обучение на парах текстов на разных языках, что особенно проблематично для языков с ограниченными цифровыми ресурсами. Таким образом, несмотря на впечатляющие результаты, вычислительная сложность и зависимость от больших данных остаются серьезными препятствиями для широкого внедрения этих моделей в практические системы машинного перевода.
Эффективный машинный перевод требует обработки разнообразных лингвистических структур и сохранения семантической точности между языками, что представляет собой значительную проблему для универсальных моделей. Различия в грамматическом строе, порядке слов и способах выражения концепций создают серьезные трудности для алгоритмов, стремящихся к адекватному переносу смысла. Например, языки с богатой системой падежей, такие как русский, требуют иного подхода, чем языки, полагающиеся на фиксированный порядок слов и предлоги. Сохранение не только буквального значения, но и стилистических особенностей, идиоматических выражений и культурных нюансов — задача, требующая от моделей глубокого понимания как исходного, так и целевого языка. Неспособность учесть эти факторы приводит к неточностям, искажениям смысла и, в конечном итоге, к снижению качества перевода, что ограничивает практическое применение автоматизированных систем в различных областях, от международного бизнеса до научных исследований.
MiLMMT-46: Решение на основе Gemma3 для многоязыкового перевода
Представляем MiLMMT-46 — семейство многоязычных моделей машинного перевода, работающих в формате «многие ко многим» и основанных на архитектуре Gemma3. Данные модели разработаны для повышения эффективности и производительности в задачах перевода. MiLMMT-46 поддерживает перевод между 46 языками, обеспечивая гибкость и широкую применимость в различных лингвистических сценариях. Основная цель разработки — достижение конкурентоспособных результатов перевода при одновременном снижении вычислительных затрат и требований к ресурсам.
MiLMMT-46 использует фреймворк LlamaFactory для обучения, что обеспечивает быструю разработку прототипов и возможность кастомизации моделей. LlamaFactory предоставляет инструменты для эффективной настройки гиперпараметров, оптимизации процесса обучения и интеграции различных методов регуляризации. Это позволяет исследователям и разработчикам быстро экспериментировать с архитектурой модели и данными, адаптируя MiLMMT-46 к специфическим требованиям задач машинного перевода и обеспечивая гибкость в настройке для достижения оптимальной производительности.
Ключевым нововведением в MiLMMT-46 является оптимизация размера модели и используемых данных для обучения. Этот подход позволяет достигать конкурентоспособных результатов в машинном переводе при значительно сниженных вычислительных затратах. Оптимизация включает в себя тщательный отбор и обработку данных, а также применение методов уменьшения размера модели без существенной потери качества перевода. Данная архитектура поддерживает перевод между 46 языками, обеспечивая высокую производительность и эффективность при работе с многоязычными задачами.
Тщательная оценка и метрики производительности
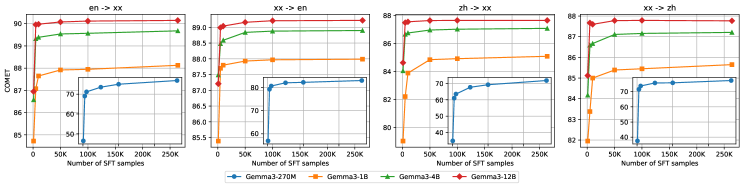
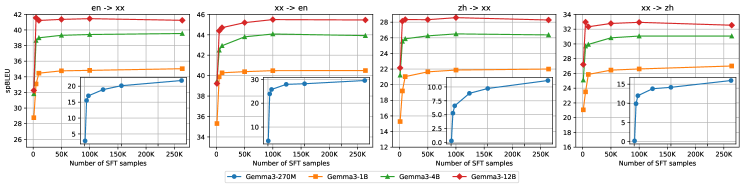
Модель MiLMMT-46 была протестирована на общепринятых бенчмарках машинного перевода, таких как WMT24++ и FLORES+, для оценки ее производительности. Сравнение проводилось с установленными моделями, включая NLLB-54.5B и Google Translate. Использование этих стандартных наборов данных позволило объективно оценить качество перевода MiLMMT-46 и сопоставить ее результаты с другими системами машинного перевода, как открытыми, так и проприетарными.
Оценка качества машинного перевода MiLMMT-46 проводилась с использованием как автоматических метрик, так и экспертной оценки. Автоматическая оценка включала в себя расчет показателей spBLEU и COMET, которые позволяют количественно оценить сходство между сгенерированным переводом и эталонными переводами. Параллельно проводилась экспертная оценка качества перевода, включающая оценку беглости и адекватности перевода лингвистами-носителями языка. Комбинирование автоматических и экспертных оценок позволило получить всестороннюю оценку качества перевода MiLMMT-46.
Результаты оценки MiLMMT-46 на стандартных бенчмарках машинного перевода, таких как WMT24++ и FLORES+, демонстрируют ее конкурентоспособность и превосходство над базовыми моделями, особенно в задачах перевода для языков с ограниченными ресурсами. В этих сценариях MiLMMT-46 стабильно превосходит другие модели с открытым исходным кодом и достигает результатов, сопоставимых с проприетарными системами, такими как Google Translate и Gemini 3 Pro. Достигнутые показатели подтверждают эффективность архитектуры MiLMMT-46 и её способность эффективно обрабатывать языки с недостаточным количеством обучающих данных.
Данные и стратегии обучения для достижения оптимальных результатов
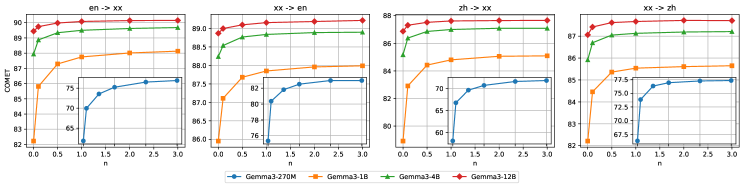
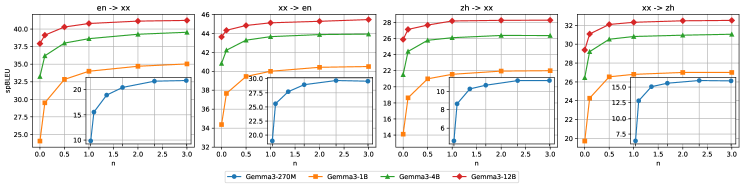
В процессе предварительного обучения модели MiLMMT-46 использовался комбинированный подход, включающий параллельные данные из коллекции OPUS и монолингвальные данные. Параллельные данные, состоящие из предложений и их переводов, обеспечивают модель способностью к машинному переводу и пониманию соответствия между языками. Дополнительное использование монолингвальных данных позволило значительно расширить языковые знания модели и улучшить её способность к генерации связного и грамматически правильного текста на целевых языках. Комбинация этих типов данных способствовала повышению общей языковой компетенции модели и улучшению понимания контекста.
Эксперименты с непрерывным предварительным обучением (continual pretraining) и последующей точной настройкой на инструкциях (instruction finetuning) показали значительное улучшение качества и беглости перевода. Непрерывное предварительное обучение позволило модели адаптироваться к новым данным без потери ранее приобретенных знаний, в то время как точная настройка на инструкциях оптимизировала её способность генерировать переводы, соответствующие заданным указаниям и контексту. Количественная оценка качества перевода с использованием метрик BLEU и METEOR подтвердила статистически значимое повышение показателей после применения данных техник, что свидетельствует об их эффективности в улучшении производительности модели MiLMMT-46.
Увеличение объема обучающих данных оказалось критически важным для достижения передовых результатов в работе MiLMMT-46. Эксперименты показали стабильное улучшение производительности во всех размерах моделей и языковых направлениях, что подтверждает важность подхода, основанного на данных. Наблюдалась устойчивая положительная корреляция между объемом данных и качеством перевода, что указывает на необходимость дальнейшего увеличения масштаба обучающих корпусов для достижения ещё более высоких показателей точности и беглости генерируемого текста.
Перспективы и влияние на глобальное общение
Успешная разработка MiLMMT-46 наглядно демонстрирует значительный потенциал моделей, основанных на Gemma3, в сфере эффективного и качественного многоязыкового перевода. Данная архитектура позволила добиться высокой производительности при относительно небольших вычислительных затратах, открывая возможности для создания доступных систем машинного перевода, способных обрабатывать широкий спектр языковых пар. Результаты показывают, что Gemma3 обеспечивает надежную основу для построения моделей, эффективно справляющихся со сложностями многоязыковой обработки, включая поддержание семантической точности и стилистической адекватности перевода. Таким образом, MiLMMT-46 служит убедительным доказательством перспективности Gemma3 как ключевого компонента будущих систем машинного перевода, способствующих преодолению языковых барьеров и расширению возможностей глобальной коммуникации.
Дальнейшие исследования направлены на оптимизацию эффективности токенизации, что позволит сократить вычислительные затраты и ускорить процесс перевода. Особое внимание будет уделено изучению возможностей обучения в контексте (in-context learning), когда модель адаптируется к новым языковым особенностям и стилям непосредственно во время перевода, без дополнительной переподготовки. Предполагается, что сочетание оптимизированной токенизации и эффективного обучения в контексте значительно повысит качество машинного перевода, обеспечивая более точную и естественную передачу смысла между различными языками и делая технологию доступной для более широкого круга пользователей.
Данное исследование вносит значимый вклад в преодоление языковых барьеров и стимулирование глобального общения посредством доступного и высококачественного машинного перевода. Разработка эффективных и многоязычных моделей, таких как MiLMMT-46, позволяет значительно расширить возможности коммуникации между людьми, говорящими на разных языках, способствуя более тесному международному сотрудничеству в различных сферах — от науки и образования до бизнеса и культуры. Доступность качественного машинного перевода не только облегчает обмен информацией, но и способствует взаимопониманию и уважению между различными культурами, что является ключевым фактором для построения более гармоничного и взаимосвязанного мира. Подобные разработки открывают новые горизонты для глобальной интеграции и позволяют преодолеть ограничения, связанные с лингвистическими различиями.

Исследование демонстрирует, что тщательно подобранное масштабирование моделей и данных позволяет открытым большим языковым моделям (LLM) достигать конкурентоспособных результатов в многоязычном машинном переводе. Этот подход, акцентирующий внимание на эффективности и доступности, перекликается с идеей о том, что хорошая система — это живой организм, где каждая часть взаимосвязана. Как заметил Дональд Кнут: «Прежде чем оптимизировать код, убедитесь, что он работает». Подобно этой мудрости, представленная работа подчеркивает важность фундаментальных основ — масштабирования моделей и данных — для достижения надежной производительности в области машинного перевода, и показывает, что сложные решения не всегда необходимы, когда можно добиться успеха через простоту и ясность структуры.
Что Дальше?
Представленная работа, демонстрируя конкурентоспособность открытых больших языковых моделей в машинном переводе, лишь обнажает глубину нерешенных вопросов. Масштабирование модели и данных, безусловно, является важным шагом, однако подобно лечению симптомов, а не болезни, оно не затрагивает фундаментальных ограничений. Настоящая проблема заключается не в увеличении размеров, а в понимании того, как информация структурируется и передается внутри этих сложных систем. Документация фиксирует структуру, но не передает поведение — оно рождается во взаимодействии.
Очевидным направлением для дальнейших исследований является выход за рамки простого увеличения объемов данных. Необходимо исследовать качество этих данных, их разнообразие и, что особенно важно, способы их представления. Поверхностное накопление терабайтов текста не заменит глубокого понимания лингвистических нюансов и культурных контекстов. Следует сосредоточиться на разработке методов, позволяющих моделям не просто “запоминать” переводы, а действительно “понимать” смысл.
В конечном итоге, успех в области многоязычного машинного перевода зависит не от технологической гонки за параметрами, а от способности создать системы, которые имитируют, а возможно, и превосходят человеческое понимание языка. Это требует не только вычислительной мощности, но и глубокого философского осмысления самой природы языка и познания. Простота и ясность — вот принципы, которые должны лечь в основу будущих исследований.
Оригинал статьи: https://arxiv.org/pdf/2602.11961.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект и закон: гармония неизбежна
- Искусственный интеллект: хрупкость визуального мышления
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Квантовые модели для моделирования потоков: новый взгляд на сжатие данных
- Нейросети, повинующиеся физике: новый подход к моделированию сложных систем
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Подлинность под вопросом: Как отличить реальное от сгенерированного
- Квантовая криптография под ударом: скрытые уязвимости в детекторах
2026-02-16 00:01