Автор: Денис Аветисян
Исследователи предлагают принципиально новую архитектуру, призванную сделать понимание работы языковых моделей более доступным.
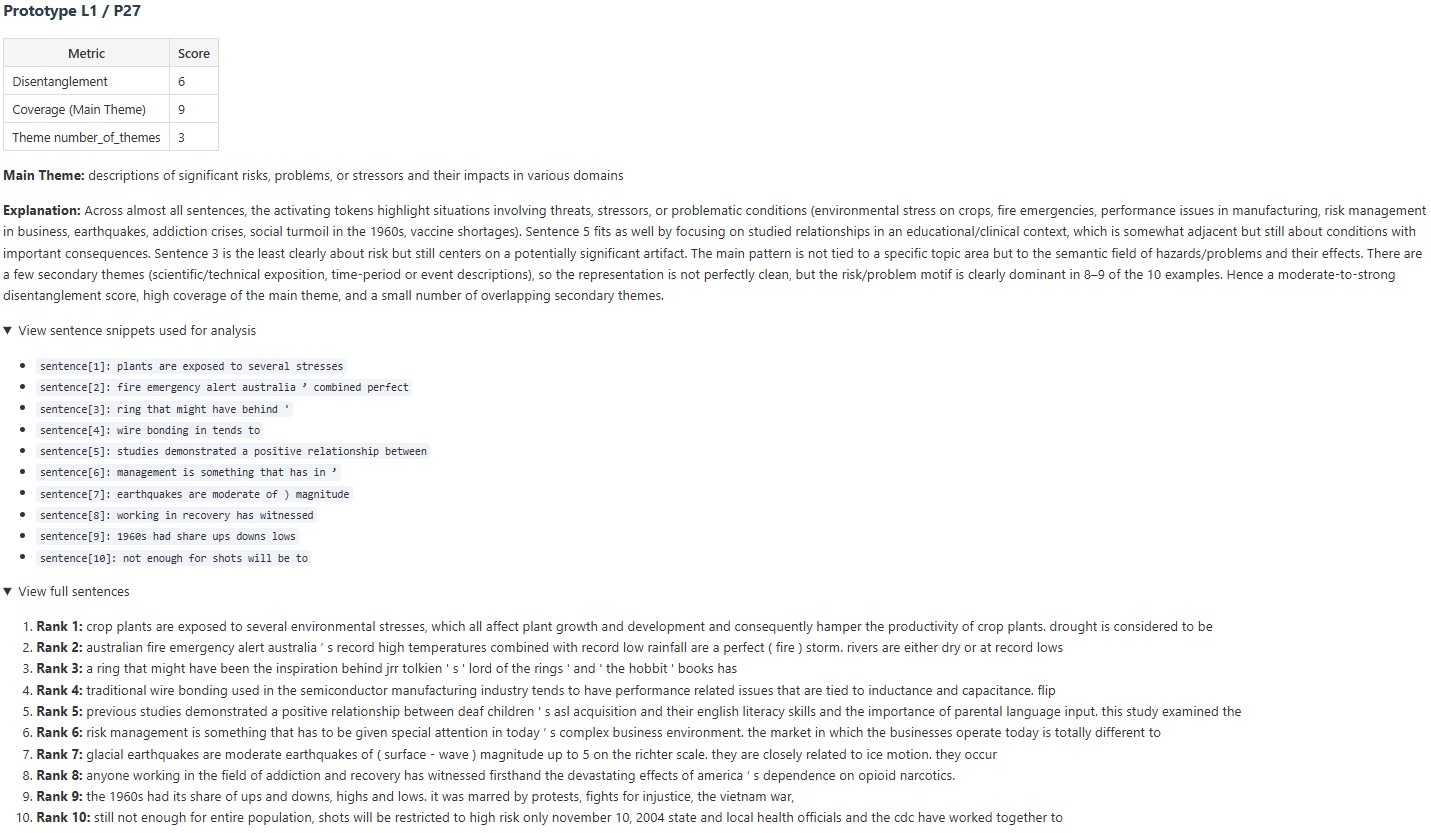
В статье представлена архитектура Prototype Transformer, заменяющая механизм самовнимания на коммуникацию на основе прототипов для повышения интерпретируемости без значительной потери производительности.
Несмотря на впечатляющие результаты современных языковых моделей, их внутренние механизмы принятия решений остаются непрозрачными, что снижает доверие к генерируемым ответам. В данной работе, представленной под названием ‘Prototype Transformer: Towards Language Model Architectures Interpretable by Design’, предлагается новая архитектура — Prototype Transformer (ProtoT), основанная на коммуникации через прототипы, в качестве альтернативы стандартным трансформерам с механизмом самовнимания. ProtoT автоматически выделяет именованные концепты в процессе обучения, обеспечивая возможность интерпретации логики модели и целенаправленного изменения её поведения. Может ли подобный подход к проектированию языковых моделей открыть путь к созданию действительно понятных и надежных систем искусственного интеллекта?
За пределами «Чёрных Ящиков»: Стремление к Интерпретируемым Моделям
Современные большие языковые модели, демонстрирующие впечатляющие возможности в обработке естественного языка, зачастую функционируют как “черные ящики”. Это означает, что внутренние механизмы принятия решений остаются непрозрачными, что существенно затрудняет понимание почему модель пришла к конкретному выводу. Отсутствие интерпретируемости не только подрывает доверие к результатам, особенно в критически важных областях, таких как медицина или финансы, но и усложняет процесс отладки и исправления ошибок. В случае некорректной работы модели, сложно определить, какая именно часть ее архитектуры или какие данные привели к ошибочному результату, что препятствует эффективному совершенствованию и повышению надежности системы. Невозможность “заглянуть внутрь” модели становится серьезным ограничением для ее широкого применения и требует разработки новых подходов к созданию более прозрачных и понятных алгоритмов.
Квадратичная сложность механизма самовнимания представляет собой серьезное ограничение для масштабирования современных языковых моделей. В процессе обработки длинных последовательностей, вычислительные затраты растут пропорционально квадрату длины входных данных O(n^2), что существенно замедляет обучение и вывод. Это создает узкое место в производительности, особенно при работе с большими объемами текста, такими как книги, статьи или длинные диалоги. В результате, обработка действительно длинных последовательностей становится либо невозможной из-за нехватки вычислительных ресурсов, либо крайне неэффективной, что препятствует созданию более мощных и функциональных языковых моделей, способных понимать и генерировать сложные тексты.
В современных системах искусственного интеллекта, особенно в области обработки естественного языка, всё большее значение приобретает не только достижение высокой производительности, но и понимание логики, лежащей в основе принимаемых решений. Простое достижение точного результата недостаточно; необходимо, чтобы модель могла объяснить, почему она пришла к тому или иному выводу. Это требование к интерпретируемости становится критически важным для применения искусственного интеллекта в областях, где требуется высокая степень ответственности и доверия, таких как медицина, финансы и юриспруденция. Разработка моделей, способных демонстрировать прозрачность своих рассуждений, позволит не только повысить уверенность пользователей, но и выявить потенциальные ошибки или предвзятости, что, в свою очередь, приведет к созданию более надежных и справедливых систем. В конечном итоге, баланс между производительностью и интерпретируемостью становится ключевым фактором для успешного внедрения и широкого распространения технологий искусственного интеллекта.
ProtoT: Новая Архитектура для Эффективной Коммуникации
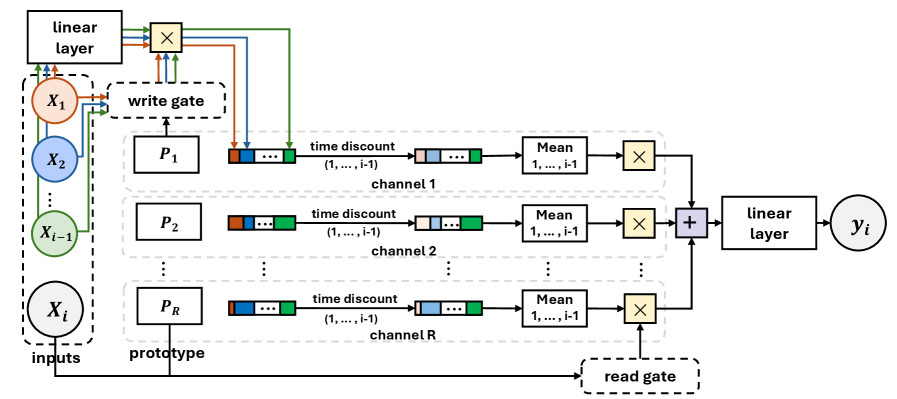
В архитектуре ProtoT механизм самовнимания заменен на коммуникацию на основе прототипов. Этот подход предполагает использование обучаемых параметрических векторов для представления ключевых концепций, что позволяет модели эффективно кодировать и обмениваться информацией. Вместо вычисления внимания между всеми парами токенов, ProtoT сопоставляет каждый токен с набором дискретных прототипов, представляющих собой фиксированные векторы, которые модель изучает в процессе обучения. Это значительно снижает вычислительную сложность по сравнению с традиционным самовниманием, особенно при обработке длинных последовательностей. Каждый прототип функционирует как компактное представление определенной концепции или шаблона, что позволяет модели обобщать информацию и эффективно передавать знания между различными частями последовательности.
Коммуникация в ProtoT осуществляется посредством механизмов ‘Write’ и ‘Read’ — управляемых ворот, динамически агрегирующих и извлекающих информацию на основе степени вовлеченности прототипов. ‘Write’ ворота определяют, какая информация из текущего состояния скрытого вектора должна быть записана в прототипы, формируя их представление. ‘Read’ ворота, в свою очередь, взвешивают прототипы, определяя, какая информация из них должна быть использована для обновления скрытого вектора. Веса, определяемые этими воротами, зависят от релевантности прототипов для текущего контекста, обеспечивая избирательное внимание к наиболее важным концепциям и эффективное управление информационным потоком в процессе обработки последовательностей.
Для обеспечения последовательной и когерентной генерации последовательностей в ProtoT используется строгая авторегрессионная зависимость, реализуемая через механизм ‘Prefix Mean’. Этот механизм вычисляет среднее значение скрытых состояний, полученных на предыдущих шагах генерации (префикс), и использует его в качестве смещения для текущего скрытого состояния. Фактически, \text{hidden}_t = \text{LSTM}(\text{input}_t + \text{mean}(\text{hidden}_{
Подтверждение Возможностей: Производительность и Надежность ProtoT
Модель ProtoT демонстрирует сопоставимые результаты с существующими моделями, такими как LLaMA, DeltaNet и Mamba, на стандартных бенчмарках. В частности, на датасете FineWeb ProtoT достигает значения Perplexity в 29.5, что указывает на высокую вероятность предсказания следующего токена в последовательности и, следовательно, на качество языкового моделирования. Данный показатель позволяет оценить эффективность модели в генерации связного и грамматически правильного текста.
В ходе тестирования ProtoT продемонстрировал сопоставимую производительность с моделью LLaMA, достигнув значения Perplexity 30.1 на стандартном наборе данных, в то время как DeltaNet показала результат 31.5. Это указывает на то, что ProtoT обеспечивает аналогичный уровень предсказательной силы, как и LLaMA, и превосходит DeltaNet в оценке вероятности последовательностей токенов. Perplexity является метрикой, используемой для оценки языковых моделей, и более низкие значения указывают на лучшую производительность.
В ходе тестирования производительности ProtoT продемонстрировал значительно улучшенную пропускную способность, достигая 25.2 токенов в секунду при размере пакета 32. Этот показатель в два раза превышает аналогичный для модели Mamba (11.9 токенов/секунду) при идентичных настройках размера пакета. Увеличение пропускной способности позволяет ProtoT обрабатывать большие объемы текста быстрее, что является важным преимуществом при задачах генерации и анализа текста в реальном времени.
Преодолевая Границы: Влияние и Перспективы Развития
Линейная вычислительная сложность ProtoT представляет собой значительный прорыв в обработке длинных последовательностей данных. В отличие от многих существующих моделей, требующих экспоненциальных ресурсов при увеличении длины входных данных, ProtoT сохраняет предсказуемую и эффективную производительность. Это открывает двери для решения задач, ранее недоступных из-за вычислительных ограничений, таких как генерация и анализ объемных текстов, создание связных нарративов, обработка научных статей и даже создание детальных отчетов. Возможность эффективно обрабатывать длинные последовательности делает ProtoT особенно перспективным для приложений, требующих понимания контекста и долгосрочных зависимостей в данных, что существенно расширяет спектр его потенциального применения.
Повышенная интерпретируемость ProtoT представляет собой значительный прорыв в области искусственного интеллекта, особенно когда речь идет о приложениях, требующих высокой степени надежности и безопасности. В отличие от многих современных нейронных сетей, функционирующих как «черные ящики», ProtoT позволяет проследить логику принятия решений, выявляя ключевые факторы, влияющие на результат. Это открывает возможности для более тщательной проверки и валидации модели, что критически важно в таких областях, как медицина, автономное вождение и финансовый анализ. Возможность понимания и контроля над процессом работы ProtoT не только повышает доверие к системе, но и позволяет оперативно выявлять и устранять потенциальные ошибки или предвзятости, обеспечивая более надежное и предсказуемое поведение в критических ситуациях.
Дальнейшие исследования ProtoT направлены на расширение масштаба модели путем обучения на значительно более крупных наборах данных, что позволит раскрыть ее потенциал в обработке еще более сложных и объемных информационных потоков. Особое внимание уделяется изучению возможностей мультимодального обучения, то есть способности ProtoT интегрировать и анализировать данные, поступающие из различных источников - текста, изображений, аудио и видео. Такой подход позволит создать систему, способную к комплексному пониманию окружающего мира и генерации более реалистичных и осмысленных ответов, открывая перспективы для ее применения в областях, требующих обработки разнородной информации, таких как робототехника, автоматический перевод и создание интеллектуальных систем поддержки принятия решений.
Исследование демонстрирует стремление к упрощению сложных систем, что находит отклик в философии ясности. Авторы, представляя Prototype Transformer, предлагают архитектуру, заменяющую самовнимание прототипной коммуникацией, стремясь к большей интерпретируемости. Это напоминает о том, как часто усложнение скрывает недостаток понимания. Блез Паскаль заметил: «Всякое величие требует простоты». И действительно, предложенный подход, заменяя сложные механизмы самовнимания более прозрачной коммуникацией на основе прототипов, демонстрирует зрелость в понимании того, что истинная сила заключается не в сложности, а в ясности и эффективности. Подобное стремление к упрощению позволяет не только лучше понять модель, но и повысить ее устойчивость к различным воздействиям, что является важным аспектом в разработке надежных систем.
Что дальше?
Представленная архитектура, стремясь к прозрачности, лишь слегка отодвигает завесу над сложностью языковых моделей. Полагать, что замена одного механизма другим автоматически дарует понимание - упрощение. Более того, вопрос о том, что вообще значит «понимание» в контексте искусственного интеллекта, остаётся открытым. Поиск интерпретируемости - это не столько инженерная задача, сколько философский поиск, и каждое решение несёт с собой новые вопросы.
Очевидным направлением представляется исследование границ применимости прототипного подхода. Насколько эффективно он масштабируется к более сложным задачам и более крупным наборам данных? Не возникнет ли ситуации, когда «ясность» архитектуры обернётся потерей выразительности, необходимой для адекватного моделирования языка? И, что не менее важно, как обеспечить устойчивость и надёжность подобных моделей перед лицом намеренных искажений или непредсказуемых входных данных.
В конечном счёте, истинный прогресс требует не просто создания интерпретируемых моделей, но и разработки инструментов для их осмысления. Понимание внутренней логики модели - это не самоцель, а средство для достижения более глубокого понимания языка как такового. Ясность - это минимальная форма любви, и в данном контексте - это любовь к самой сути познания.
Оригинал статьи: https://arxiv.org/pdf/2602.11852.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект и закон: гармония неизбежна
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Нейросети, повинующиеся физике: новый подход к моделированию сложных систем
- Квантовые модели для моделирования потоков: новый взгляд на сжатие данных
- Время и эмпатия: проверка ИИ-агентов на сложности распознавания эмоций.
- Предвидение будущего текста: новый подход к генерации
2026-02-16 01:48