Автор: Денис Аветисян
Новая архитектура с использованием двух больших языковых моделей и многоступенчатой фильтрации повышает точность и надежность автоматизированного контроля качества фармацевтической документации.
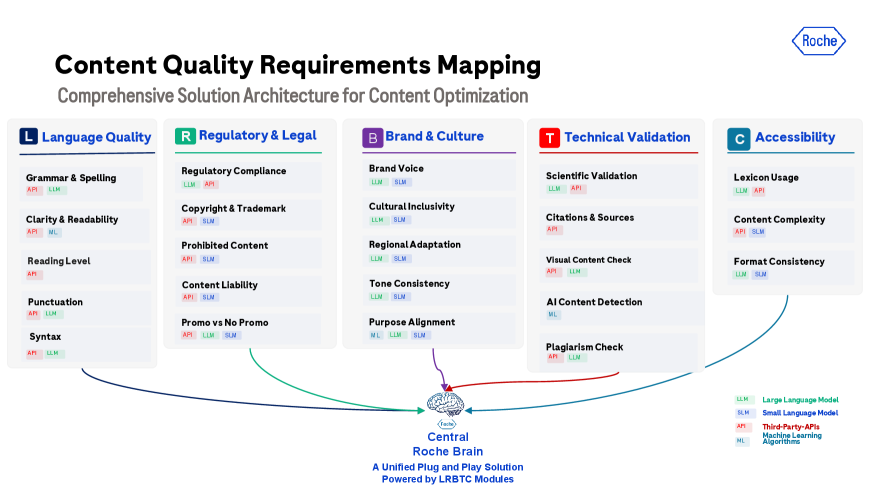
Предлагается модель «учитель-ученик» с каскадной фильтрацией и проверкой человеком для обеспечения соответствия нормативным требованиям.
Автоматический контроль качества контента в регулируемых отраслях, таких как фармацевтика, часто сталкивается с ограничениями по скорости и точности. В работе ‘Are Two LLMs Better Than One? A Student-Teacher Dual-Head LLMs Architecture for Pharmaceutical Content Optimization’ предложена архитектура LRBTC, использующая тандем больших языковых моделей и каскадную фильтрацию для верификации и оптимизации контента. Показано, что предложенный подход демонстрирует значительно более высокие показатели точности и полноты — до 83.0% F1 и 97.5% recall — по сравнению с существующими решениями, такими как Gemini 2.5 Pro, и позволяет снизить количество пропущенных ошибок в 5 раз. Сможет ли данная архитектура стать стандартом для обеспечения надежного и прозрачного контроля качества в отраслях, где критически важна соответствие нормативным требованиям?
Вызов валидации медицинского контента
В современной медицинской практике наблюдается растущая тенденция к использованию контента, генерируемого искусственным интеллектом, что обуславливает необходимость внедрения надежных механизмов контроля качества. Автоматизированные системы все чаще применяются для создания медицинских текстов, ответов на вопросы пациентов и даже для поддержки принятия клинических решений. Однако, полагаясь на алгоритмы, крайне важно обеспечить соответствие генерируемой информации актуальным научным знаниям и нормативным требованиям. Недостаточный контроль может привести к распространению неточной или устаревшей информации, что потенциально угрожает безопасности пациентов и требует разработки новых подходов к валидации и оценке достоверности медицинского контента, созданного ИИ.
Современные методы проверки медицинского контента, разработанные для обработки ограниченных объемов информации, испытывают серьезные трудности при работе с экспоненциально растущим потоком данных и возрастающей сложностью медицинских знаний. Традиционные подходы, основанные на ручной экспертизе и ограниченных базах данных, попросту не успевают за темпами публикации новых исследований, клинических рекомендаций и фармацевтических разработок. Это приводит к риску распространения устаревшей, неточной или даже ошибочной информации, что может негативно сказаться на качестве медицинской помощи и безопасности пациентов. Отсутствие эффективных инструментов автоматизированной проверки создает благоприятную среду для распространения дезинформации и требует разработки новых, более совершенных методов валидации медицинского контента.
Обеспечение точности и соответствия нормативным требованиям имеет первостепенное значение в сфере медицинского контента. Неточности или несоблюдение установленных стандартов могут иметь серьезные последствия для здоровья пациентов, вплоть до ошибочной диагностики или неадекватного лечения. В связи с этим, строгий контроль качества и валидация информации становятся критически важными элементами любого процесса создания или распространения медицинского контента. Особое внимание уделяется соблюдению юридических и этических норм, регулирующих предоставление медицинской информации, а также необходимости подтверждения достоверности используемых источников и данных. Ответственность за точность и соответствие требованиям лежит на создателях и распространителях контента, и пренебрежение этими аспектами может привести к серьезным правовым и этическим последствиям.
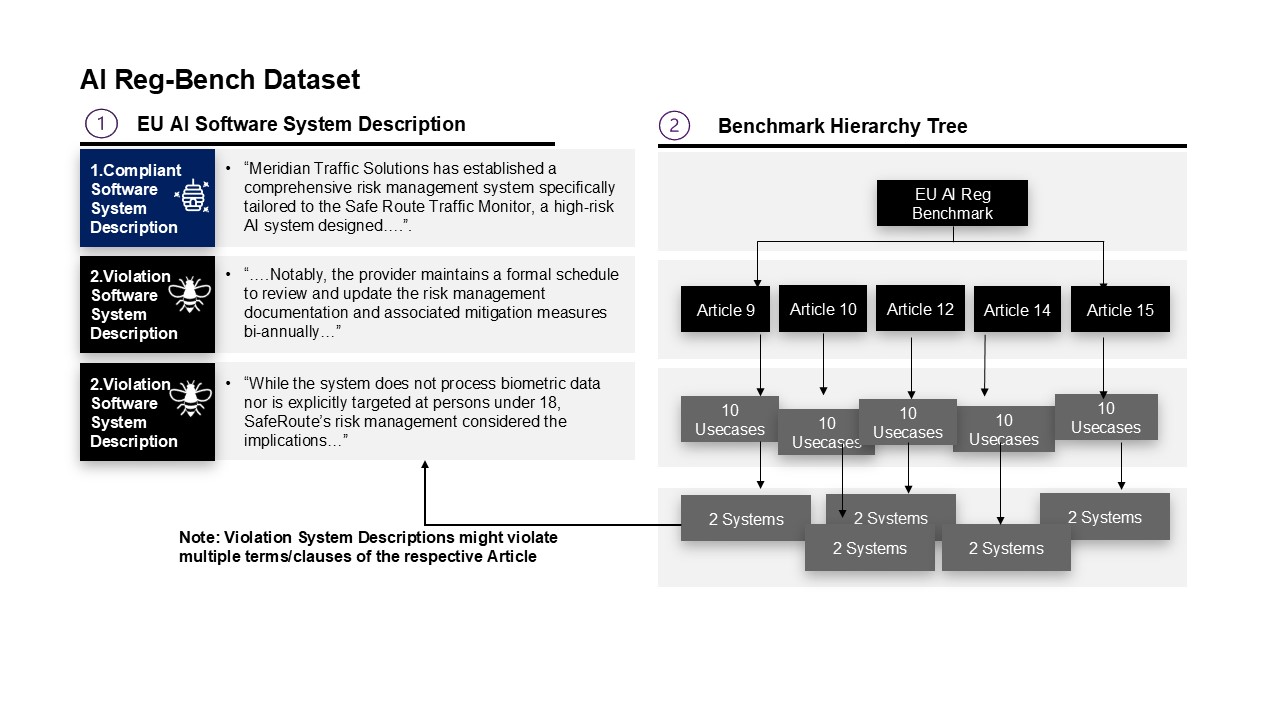
LRBTC: Модульный подход к валидации контента
Фреймворк LRBTC представляет собой комплексное решение для валидации контента, охватывающее пять ключевых измерений: лингвистическое, регуляторное и юридическое соответствие, соответствие бренду и культуре, техническую корректность и структурную целостность. Данный подход позволяет проводить всестороннюю проверку материалов на предмет соответствия различным требованиям и стандартам, обеспечивая качество и надежность контента. Каждое измерение включает в себя набор специфических проверок и критериев, предназначенных для выявления потенциальных проблем и ошибок на различных этапах создания и публикации контента.
В основе LRBTC Framework лежит автоматизация процессов валидации контента посредством генеративных моделей искусственного интеллекта (GenAI). Данные модели используются для выполнения таких задач, как проверка соответствия нормативным требованиям, выявление несоответствий брендовым гайдлайнам и проверка технической корректности. Автоматизация позволяет значительно снизить объем ручной работы, связанной с проверкой контента, что приводит к повышению эффективности и сокращению времени, необходимого для публикации или внедрения материалов. Использование GenAI обеспечивает более последовательную и масштабируемую проверку, уменьшая вероятность человеческих ошибок и повышая общую надежность процесса валидации.
Модульность фреймворка LRBTC обеспечивает возможность его адаптации к различным типам контента и специфическим регуляторным требованиям. Архитектура, основанная на независимых модулях, позволяет избирательно применять компоненты валидации, соответствующие конкретным задачам и отраслевым стандартам. Это включает в себя настройку параметров проверки, добавление или удаление модулей, а также интеграцию с существующими системами управления контентом и процессами комплаенса. Возможность гибкой конфигурации снижает затраты на внедрение и обслуживание, а также повышает эффективность валидации за счет фокусировки на наиболее важных аспектах для каждого типа контента и регуляторной среды.

Оптимизация валидации: каскадный подход и модель «Ученик-Учитель»
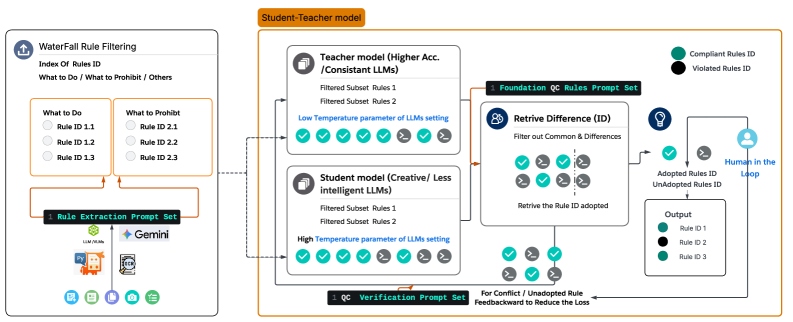
Логика «водопада» эффективно сужает пространство правил для верификации, что позволяет снизить задержку и повысить пропускную способность. Принцип заключается в последовательном применении правил, начиная с наиболее вероятных или критичных, и исключении из рассмотрения тех, которые не соответствуют входным данным на ранних этапах. Это значительно уменьшает объем вычислений, необходимых для проверки оставшихся правил, и ускоряет процесс валидации, особенно в задачах с большим количеством потенциальных нарушений или сложных правил.
В основе системы валидации используется модель «Ученик-Учитель», состоящая из двух больших языковых моделей (LLM). «Учитель» генерирует правила и первоначальные оценки, которые затем передаются «Ученику». «Ученик» выполняет итеративную валидацию, уточняя правила на основе полученных результатов и предоставляя обратную связь «Учителю». Этот процесс повторяется, что позволяет непрерывно совершенствовать правила и повышать точность определения соответствия нормативным требованиям за счет последовательного улучшения итераций валидации.
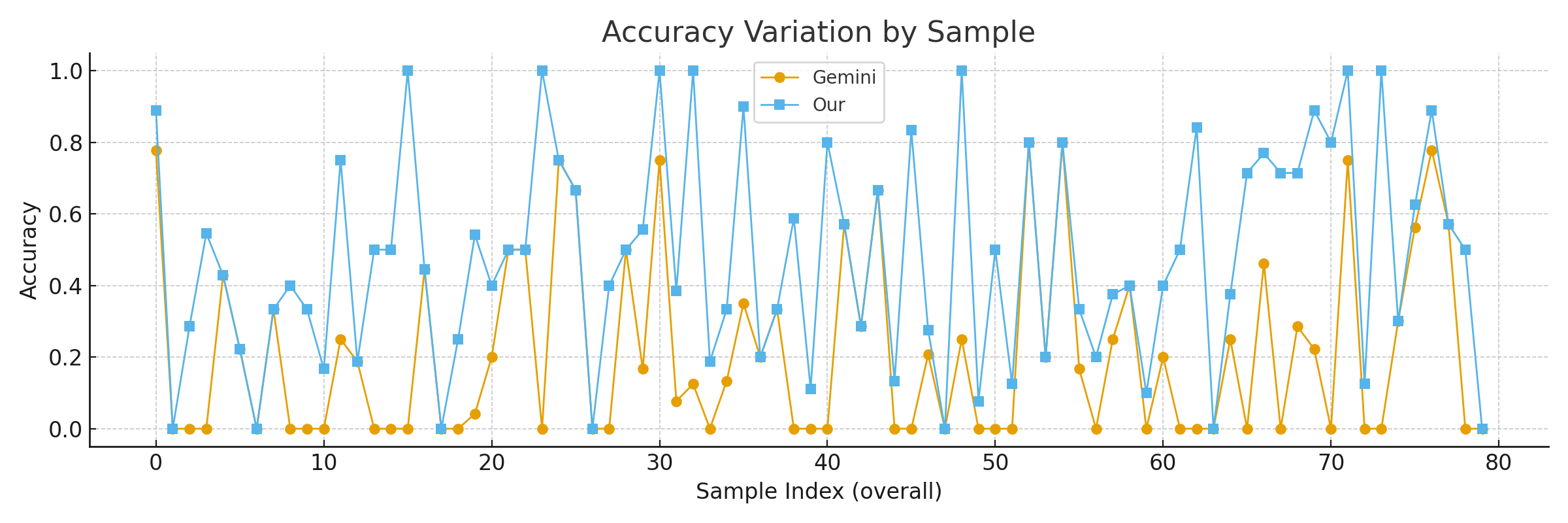
При тестировании на наборе данных AIReg-Bench, предложенная архитектура продемонстрировала абсолютное увеличение общей точности на 10 процентных пунктов — 75.9% против 65.9% у Gemini 2.5 Pro. Наблюдается также значительное улучшение показателя полноты с 88.7% до 97.5%. Данные результаты свидетельствуют о повышенной эффективности системы в обнаружении нормативно-правовых требований по сравнению с базовой моделью Gemini 2.5 Pro.
Человеческий фактор: обеспечение надежности и соответствия нормам
Внедрение верификации с участием человека обеспечивает критически важную проверку сложных или неоднозначных правил экспертами в соответствующей области. Такой подход позволяет преодолеть ограничения автоматизированных систем, которые могут испытывать затруднения при интерпретации нюансов и контекста. Эксперты анализируют случаи, требующие дополнительной оценки, и предоставляют точные решения, что значительно повышает надежность и точность принимаемых решений. Данный процесс особенно важен в сферах, где ошибки могут иметь серьезные последствия, и позволяет гарантировать соответствие самым высоким стандартам качества и безопасности, дополняя возможности автоматизированных алгоритмов и систем.
В рамках модели «Учитель-Ученик» взаимодействие с человеком значительно расширяет возможности автоматизированной системы. Человек выступает в роли эксперта, способного проанализировать сложные или неоднозначные случаи, которые алгоритм может обработать с ошибкой. Этот процесс позволяет не только корректировать выходные данные модели, повышая их точность, но и добавлять необходимый контекст, который алгоритм самостоятельно не может учесть. Благодаря такому симбиозу, система способна принимать более обоснованные решения, особенно в ситуациях, требующих глубокого понимания предметной области и учета нюансов, недоступных для автоматической обработки.
Комбинированный подход, объединяющий возможности автоматизированных систем и экспертной оценки, позволяет добиться максимальной точности и снизить риски, связанные с принятием решений в критически важных областях. Такая гибридная модель особенно важна для соблюдения строгих нормативных требований, где даже незначительные ошибки могут иметь серьезные последствия. Подтверждение эффективности данной стратегии обеспечивается специализированными наборами данных, такими как AIReg-Bench, которые позволяют объективно оценить соответствие систем установленным стандартам и выявить потенциальные уязвимости. Использование подобных инструментов позволяет не только повысить надежность принимаемых решений, но и гарантировать их соответствие законодательным и этическим нормам, что особенно актуально в сферах, регулируемых государством.
Масштабирование валидации: данные, использование токенов и перспективы развития
Эффективность разработанного фреймворка напрямую зависит от объема используемых токенов, что требует тщательной оптимизации как запросов к языковой модели, так и сложности задаваемых правил. Избыточность в формулировках или чрезмерная детализация правил приводят к увеличению потребляемых токенов, что, в свою очередь, влияет на скорость обработки и стоимость использования. Поэтому, при проектировании системы, особое внимание уделяется лаконичности и точности запросов, а также минимизации избыточности в логике правил, чтобы достичь оптимального баланса между производительностью и затратами. Подобный подход позволяет значительно повысить эффективность фреймворка, особенно при работе с большими объемами данных и сложными задачами.
Для оценки эффективности разработанного фреймворка в обработке реальных медицинских текстов, ключевое значение имеют специализированные наборы данных, такие как CSpelling. Этот ресурс содержит обширный корпус медицинских терминов и распространенных орфографических ошибок, что позволяет точно измерить способность системы к коррекции и пониманию сложных медицинских концепций. Использование CSpelling в процессе валидации позволяет не только определить текущий уровень производительности, но и выявить области, требующие дальнейшей оптимизации и улучшения. Результаты тестов на данном наборе данных демонстрируют способность фреймворка эффективно справляться с задачами, характерными для реальной медицинской практики, обеспечивая надежность и точность обработки информации.
Исследования показали, что разработанная модель демонстрирует значительное улучшение точности — в среднем на 26,7% — при работе с набором данных CSpelling, предназначенным для оценки качества обработки медицинской терминологии, по сравнению с моделью Gemini 2.5 Pro. При этом, достигнутая эффективность не отразилась на стоимости использования: затраты на обработку одного запроса составляют от 0,38 до 0,64 цента (при использовании 1,8-1,9 тысяч токенов), что существенно ниже, чем у Gemini 2.5 Pro, где стоимость аналогичного запроса (2-11 тысяч токенов) варьируется от 3 до 8 центов. Полученные результаты подчеркивают перспективность предложенного подхода для задач, требующих высокой точности и экономичности обработки текста в медицинской сфере.
Исследование демонстрирует стремление к созданию надежных систем контроля качества в фармацевтической сфере. Авторы предлагают архитектуру, где одна модель обучает другую, а фильтрация и проверка человеком служат гарантом точности. Это напоминает о словах Джона фон Неймана: «Если вы говорите, что знаете, что не знаете, то вы мудры». Ведь в контексте регулируемых отраслей, признание потенциальных ошибок и внедрение механизмов их выявления — основа устойчивой и безопасной системы. В данном случае, «ученик» и «учитель» в тандеме с человеческой проверкой формируют структуру, способную адаптироваться к сложности фармацевтического контента и обеспечить соответствие нормативным требованиям.
Куда двигаться дальше?
Представленная работа, подобно тщательно спроектированному кварталу в развивающемся городе, демонстрирует потенциал архитектуры “учитель-ученик” для повышения надежности автоматизированного контроля качества фармацевтической информации. Однако, как и в любом градостроительном проекте, остаются вопросы, требующие дальнейшей проработки. Простое увеличение масштаба модели или количества фильтров, вероятно, не решит фундаментальную проблему: способность системы к истинному пониманию контекста и выявлению тонких, но критических неточностей.
Будущие исследования должны сосредоточиться не столько на усовершенствовании отдельных компонентов, сколько на интеграции различных подходов к верификации. Подобно тому, как инфраструктура города нуждается в бесшовной интеграции транспортных, энергетических и коммуникационных сетей, система контроля качества должна объединять возможности больших языковых моделей, формальных методов проверки и, что особенно важно, человеческий опыт. Упор следует сделать на создание систем, способных к самообучению и адаптации к меняющимся требованиям регуляторных органов.
В конечном счете, истинный прогресс заключается не в создании все более сложных систем, а в разработке элегантных и эффективных решений, способных обеспечить безопасность и надежность фармацевтической информации, не требуя при этом постоянной перестройки всего “квартала”. Необходимо помнить, что структура определяет поведение, и только тщательно продуманная архитектура может обеспечить долгосрочную устойчивость и надежность системы.
Оригинал статьи: https://arxiv.org/pdf/2602.11957.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект и закон: гармония неизбежна
- Квантовые модели для моделирования потоков: новый взгляд на сжатие данных
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Нейросети, повинующиеся физике: новый подход к моделированию сложных систем
- Польский язык обретает свой интеллект
- Индустриальные аномалии: обнаружение и сегментация без обучения
2026-02-16 03:33