Автор: Денис Аветисян
Новая методика позволяет оценить возможности и узкие места при развертывании современных моделей искусственного интеллекта на мобильных и встраиваемых платформах.
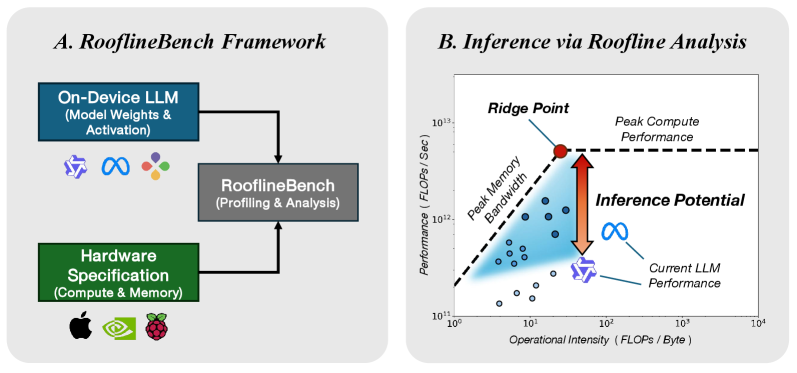
Представлен фреймворк RooflineBench для анализа производительности больших языковых моделей на устройствах и выявления возможностей аппаратного и программного со-проектирования.
Несмотря на растущий интерес к локальному интеллекту и малым языковым моделям, объективная оценка пределов их производительности на разнородном аппаратном обеспечении остается сложной задачей. В настоящей работе, представленной под названием ‘RooflineBench: A Benchmarking Framework for On-Device LLMs via Roofline Analysis’, предложен систематический фреймворк, основанный на Roofline-модели, для анализа и оптимизации инференса LLM на периферийных устройствах. Ключевым результатом является выявление зависимости производительности и операционной интенсивности от длины последовательности и глубины модели, а также определение “эффективной ловушки”, обусловленной неоднородностью аппаратного обеспечения. Какие стратегии совместного проектирования аппаратного и программного обеспечения позволят максимально раскрыть потенциал инференса LLM на ограниченных ресурсах?
Эффективность под вопросом: узкие места больших языковых моделей
Несмотря на впечатляющие возможности, большие языковые модели (БЯМ) сталкиваются с существенными трудностями в эффективности вычислений при использовании, что ограничивает их применение в средах с ограниченными ресурсами. Эта проблема становится особенно острой при развертывании моделей на мобильных устройствах или в системах реального времени, где важна скорость отклика и энергоэффективность. Высокие требования к вычислительной мощности и объему памяти, необходимые для обработки запросов, препятствуют широкому внедрению БЯМ в различных областях, от персональных помощников до автоматизированного анализа данных. Поиск способов оптимизации этих моделей без существенной потери качества является ключевой задачей для исследователей и разработчиков, стремящихся сделать передовые технологии искусственного интеллекта более доступными и практичными.
Увеличение масштаба и глубины архитектуры больших языковых моделей, хотя и способствует повышению их производительности, одновременно усугубляет проблемы, связанные с эффективностью вычислений. По мере добавления новых слоев и параметров, потребность в вычислительных ресурсах и памяти экспоненциально возрастает, что создает серьезные препятствия для развертывания этих моделей на устройствах с ограниченными возможностями или в приложениях, требующих быстродействия в реальном времени. Данное несоответствие между растущей мощностью и нарастающими затратами ресурсов подчеркивает острую необходимость в разработке новых методов оптимизации, направленных на повышение эффективности больших языковых моделей без ущерба для их способности к обработке и генерации текста. Исследования в этой области фокусируются на таких подходах, как квантизация, прунинг и дистилляция знаний, чтобы снизить вычислительную сложность и уменьшить объем необходимой памяти.
Существенные ограничения в эффективности больших языковых моделей (БЯМ) обусловлены, прежде всего, пропускной способностью памяти и вычислительной сложностью механизмов внимания. Несмотря на значительные успехи в архитектуре и обучении, БЯМ требуют перемещения огромных объемов данных между памятью и процессором во время работы, что становится узким местом. Особенно ресурсоемким является вычисление внимания, где необходимо оценить взаимосвязи между всеми элементами последовательности, что приводит к квадратичному росту вычислительных затрат с увеличением длины входных данных. Таким образом, преодоление этих ограничений памяти и оптимизация вычислений внимания являются ключевыми задачами для обеспечения широкого внедрения БЯМ в реальных приложениях, особенно в условиях ограниченных ресурсов.
Длина последовательности оказывает непосредственное влияние на вычислительные затраты при работе с большими языковыми моделями. Каждая добавленная единица в последовательность ввода требует дополнительных вычислений, особенно в механизмах внимания, что приводит к экспоненциальному росту времени и ресурсов, необходимых для получения результата. В приложениях, работающих с длинными контекстами, таких как анализ больших документов или ведение продолжительных диалогов, эта проблема становится особенно актуальной. Увеличение длины последовательности не только замедляет процесс инференса, но и требует значительно больше памяти для хранения промежуточных результатов, что может стать узким местом даже на мощном оборудовании. Поэтому оптимизация работы с длинными последовательностями является ключевой задачей для расширения возможностей и практического применения больших языковых моделей в различных областях.
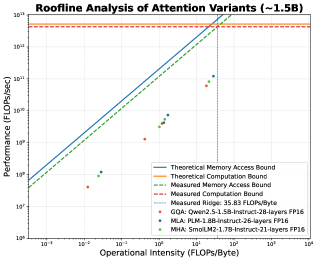
Модель «Крыша»: пределы вычислительной производительности
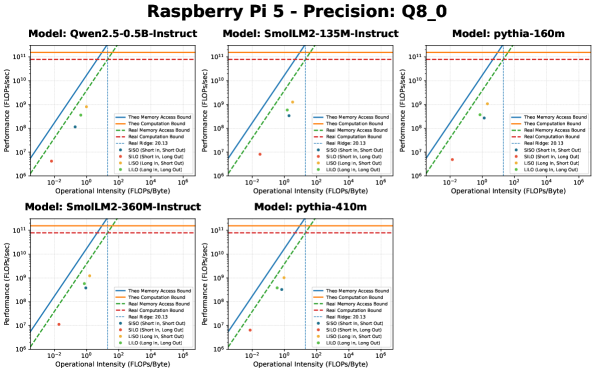
Модель “Крыша” (Roofline Model) представляет собой важный аналитический инструмент для оценки производительности больших языковых моделей (LLM). Она основана на взаимосвязи между вычислительной мощностью (compute) и пропускной способностью памяти (memory bandwidth). Данная модель позволяет определить теоретический предел производительности, ограниченный либо вычислительными ресурсами, либо скоростью доступа к памяти. В основе модели лежит понятие, что производительность ограничена наименьшим из двух факторов: максимальным количеством операций в секунду, которое может выполнить процессор, и максимальным объемом данных, который может быть получен из памяти за секунду. Анализ с использованием Roofline Model позволяет выявить узкие места в архитектуре системы и оптимизировать LLM для достижения максимальной эффективности на конкретном аппаратном обеспечении.
Операционная интенсивность, определяемая как отношение количества операций к количеству обращений к памяти, является ключевым показателем эффективности вычислений. Анализ показывает, что пиковое значение операционной интенсивности в нейронных сетях достигается на начальных слоях (глубине) модели, обычно в пределах 3-5 слоев. Дальнейшее увеличение глубины приводит к снижению операционной интенсивности, поскольку потребность в передаче данных из памяти растет быстрее, чем количество выполняемых операций. Это ограничение обусловлено архитектурными особенностями оборудования и физическими пределами пропускной способности памяти.
Аппаратные ограничения, в особенности пропускная способность памяти, часто становятся узким местом, ограничивающим потенциал даже самых мощных вычислительных ресурсов. Так, графический процессор RTX 3090 демонстрирует теоретическую пиковую производительность в 38.00 FLOPs/Byte, что означает 38 операций с плавающей точкой на каждый байт переданных данных. В то же время, вычислительная платформа Jetson Orin Nano Super 8G ограничена показателем в 22.56 FLOPs/Byte. Данная разница иллюстрирует, что даже при наличии значительной вычислительной мощности, производительность может быть ограничена скоростью доступа к памяти, что критически важно учитывать при разработке и оптимизации моделей машинного обучения.
Потенциал инференса, или относительная эффективность, количественно оценивает, насколько близко большая языковая модель (LLM) подходит к достижению оптимальной производительности в заданных аппаратных условиях. Данный показатель рассчитывается как отношение фактической пропускной способности вычислений к теоретическому максимуму, определяемому пропускной способностью памяти и вычислительной мощностью. Более низкое значение потенциала инференса указывает на то, что производительность LLM ограничена не вычислительными ресурсами, а пропускной способностью памяти, что требует оптимизации алгоритмов или использования аппаратного обеспечения с большей пропускной способностью. Оценка потенциала инференса позволяет выявить узкие места и определить стратегии повышения эффективности развертывания LLM на конкретном оборудовании.
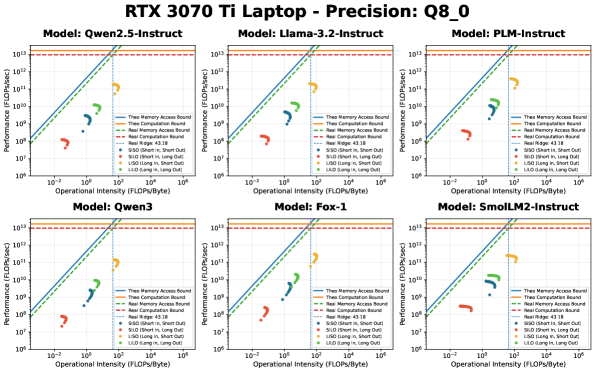
Оптимизация внимания: эффективный инференс на практике
Квантизация является эффективным методом снижения размера модели и вычислительных затрат, что позволяет ускорить и повысить эффективность инференса. Этот процесс заключается в уменьшении точности представления весов и активаций модели, например, с 32-битных чисел с плавающей точкой (FP32) до 8-битных целых чисел (INT8) или даже ниже. Уменьшение разрядности приводит к снижению объема памяти, необходимого для хранения модели, и уменьшению числа операций, необходимых для вычислений. Применение квантизации, в частности форматов Q8_0 и Q4_K_M, демонстрирует значительное улучшение операционной интенсивности в сценариях, доминирующих в предварительной обработке (LISO), что критически важно для повышения производительности больших языковых моделей.
Механизмы внимания, являясь ключевым компонентом современных больших языковых моделей (LLM) и обеспечивая высокое качество генерации текста, характеризуются значительными вычислительными затратами. Сложность вычислений внимания растет квадратично с увеличением длины входной последовательности O(n^2), что создает узкое место в процессе инференса, особенно при обработке длинных текстов. Повышенная потребность в памяти и пропускной способности для хранения и обработки матриц ключей, запросов и значений ограничивает скорость и масштабируемость LLM. В связи с этим, разработка и внедрение инновационных методов оптимизации внимания, направленных на снижение вычислительной сложности и потребления памяти, является критически важной задачей для повышения эффективности и практической применимости LLM.
Групповое внимание (Grouped-Query Attention, GQA) оптимизирует использование пропускной способности памяти за счет совместного использования проекций ключей и значений (key и value). Традиционные механизмы внимания требуют отдельных проекций для каждого запроса (query), что приводит к значительному потреблению памяти, особенно при увеличении числа запросов. GQA группирует запросы и совместно использует одни и те же проекции ключей и значений для нескольких запросов в группе. Это снижает требования к пропускной способности памяти, поскольку необходимо хранить и обрабатывать меньше проекций. Эффективность GQA проявляется при увеличении размера пакета (batch size), позволяя обрабатывать больше данных с меньшими затратами памяти и повышая общую скорость вычислений.
Механизм Latent Attention снижает объем занимаемой памяти за счет сжатия представлений, используемых в процессе вычисления внимания. Применение квантизации, в частности форматов Q8_0 и Q4_K_M, демонстрирует существенное улучшение операционной интенсивности в сценариях, доминирующих в фазе префикса (LISO — Large Input Sequence Optimization). Это достигается за счет уменьшения количества операций чтения-записи из памяти, что особенно важно для обработки длинных последовательностей и снижения задержек при инференсе больших языковых моделей.
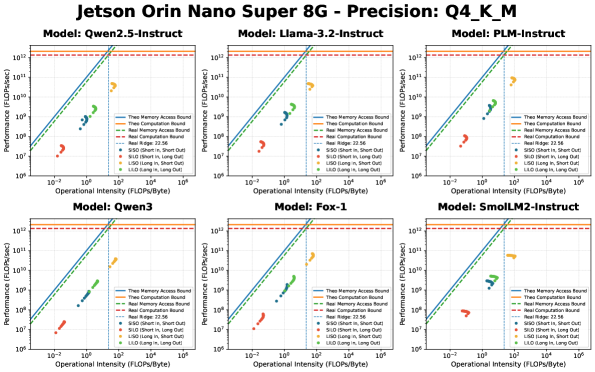
Будущее БЯМ: инференс на устройствах и за их пределами
Выполнение логических выводов непосредственно на устройстве, без обращения к облачным сервисам, открывает принципиально новые возможности для больших языковых моделей (LLM). Это позволяет создавать приложения, требующие мгновенного отклика и высокой степени конфиденциальности, например, персональные ассистенты, работающие в автономном режиме, или системы перевода, функционирующие без подключения к интернету. Устранение зависимости от облака также снижает задержки, повышает надежность и обеспечивает более эффективное использование ресурсов, делая LLM доступными для широкого спектра устройств, от смартфонов и носимой электроники до встроенных систем и периферийных вычислений. Такой подход способствует развитию интеллектуальных устройств, способных к самостоятельному обучению и адаптации к изменяющимся условиям, расширяя границы применения искусственного интеллекта.
Малые языковые модели (SLM) представляют собой специализированные алгоритмы, разработанные для эффективной работы непосредственно на пользовательских устройствах, без необходимости подключения к облачным серверам. В отличие от своих более крупных аналогов, SLM оптимизированы для снижения потребления ресурсов — вычислительной мощности, памяти и энергии — при сохранении приемлемого уровня производительности. Этот компромисс позволяет развертывать сложные функции обработки естественного языка на устройствах с ограниченными возможностями, таких как смартфоны, планшеты и встраиваемые системы. Подобный подход открывает перспективы для реализации приложений, требующих мгновенного отклика и конфиденциальности данных, поскольку обработка информации происходит локально, без передачи в сторонние сервисы. Эффективность SLM достигается за счет уменьшения количества параметров модели и применения методов квантизации и обрезки, что позволяет значительно снизить её размер и сложность, не жертвуя при этом ключевыми возможностями понимания и генерации текста.
Дальнейшее развитие алгоритмической оптимизации и аппаратного ускорения представляется критически важным для расширения возможностей локального (on-device) применения больших языковых моделей. Усилия в области квантизации, прунинга и дистилляции моделей направлены на снижение их размера и вычислительной сложности без существенной потери точности. Параллельно, разработка специализированных аппаратных решений, таких как нейроморфные чипы и ускорители искусственного интеллекта, способна обеспечить значительное повышение производительности и энергоэффективности. Сочетание этих подходов позволит преодолеть существующие ограничения и открыть путь к реализации сложных задач обработки естественного языка непосредственно на мобильных устройствах, встроенных системах и других ресурсоограниченных платформах, что приведет к появлению принципиально новых приложений и сервисов.
Преодоление ограничений, связанных с вычислительной эффективностью, открывает путь к раскрытию всего потенциала больших языковых моделей и значительно расширяет сферу их применения. Исследования, проведенные, в частности, на базе Raspberry Pi 5, выявили критическую точку в 20.13, демонстрирующую существующие пределы возможностей периферийных устройств. Это указывает на необходимость дальнейшей оптимизации алгоритмов и аппаратного обеспечения, чтобы обеспечить работу LLM непосредственно на устройствах, не требуя постоянного подключения к облачным серверам. Такой подход позволит создавать приложения, работающие в режиме реального времени и не зависящие от сетевого соединения, что особенно важно для мобильных устройств, встроенных систем и других сценариев, где надежность и скорость обработки данных имеют первостепенное значение.
Исследование, представленное в статье, демонстрирует, что понимание пределов производительности вычислительных систем — ключ к оптимизации сложных задач, таких как вывод больших языковых моделей на мобильных устройствах. Анализ, основанный на модели Roofline, выявляет узкие места, связанные с пропускной способностью памяти и вычислительной мощностью. Как однажды заметила Грейс Хоппер: «Лучший способ объяснить — это сделать». Эта фраза отражает подход, представленный в статье, где теоретический анализ сочетается с практическими рекомендациями по совместной оптимизации аппаратного и программного обеспечения. Понимание этих ограничений позволяет взломать систему, найдя оптимальные пути для достижения максимальной эффективности, что соответствует философии реверс-инжиниринга реальности.
Куда двигаться дальше?
Представленная работа, по сути, лишь приоткрыла ящик Пандоры. Модель Roofline, как инструмент анализа, оказалась неожиданно эффективной в выявлении узких мест при развертывании больших языковых моделей на периферийных устройствах. Однако, следует признать: понимание ограничений — это лишь первый шаг. Настоящая задача — не просто констатировать, что пропускная способность памяти является критическим фактором, а найти способы обойти эти ограничения, взломать систему, если хотите. Необходимо углубленное исследование новых архитектур памяти, методов квантования и разрежения, которые позволят выжать максимум производительности из ограниченных ресурсов.
Особый интерес представляет концепция “относительного потенциала вывода”. Она намекает на то, что эффективность модели зависит не только от её абсолютных характеристик, но и от конкретного аппаратного обеспечения. Это открывает пространство для разработки специализированных ускорителей, заточенных под конкретные классы языковых моделей и задачи. По сути, речь идет о переходе от универсальных решений к кастомизированным, о взломе самой идеи универсальности.
В конечном итоге, предложенный фреймворк — это лишь инструмент. Его ценность будет определяться не количеством проведенных тестов, а способностью стимулировать творческий подход к решению проблем. Понимание принципов работы системы — это лишь отправная точка. Настоящий прогресс начнется тогда, когда исследователи начнут не просто следовать правилам, а проверять их на прочность, взламывать и переписывать, чтобы создать что-то принципиально новое.
Оригинал статьи: https://arxiv.org/pdf/2602.11506.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самообучающиеся агенты: извлечение навыков из открытого кода
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Понимание ориентации объектов: новый взгляд на 3D-пространство
- Искусственный интеллект на службе физики высоких энергий
- Стратегия подцелей: Как научить ИИ долгосрочному планированию
- Квантовая неопределенность: новый взгляд на измерения
- Квантовые машины Больцмана для обучения с подкреплением: новый подход
- Квантовые Иллюзии и Практические Шаги
- Геном под контролем: Ускорение анализа данных для персонализированной медицины
- Вероятностный интеллект на скорости света: новые горизонты машинного обучения
2026-02-16 05:09