Автор: Денис Аветисян
Новое исследование показывает, что обучение с подкреплением последовательно улучшает способность моделей, объединяющих зрение и язык, к логическому мышлению, фокусируясь на ключевых слоях нейронной сети.
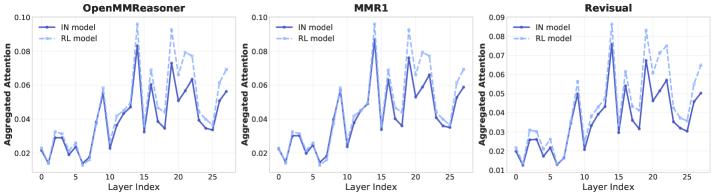
Анализ выявил, что обучение с подкреплением наиболее эффективно влияет на средние и поздние слои моделей, улучшая согласованность между визуальным восприятием и рассуждениями.
Несмотря на широкое применение обучения с подкреплением (RL) для улучшения визуального мышления в мультимодальных моделях, остается неясным, какие именно навыки оно улучшает по сравнению с традиционной тонкой настройкой. В своей работе ‘What does RL improve for Visual Reasoning? A Frankenstein-Style Analysis’ авторы предлагают оригинальный «Франкенштейновский» подход, включающий функциональную локализацию, анализ изменений параметров и проверку переносимости моделей. Ключевой результат исследования демонстрирует, что RL последовательно уточняет вычисления в средних и поздних слоях трансформеров, улучшая согласованность между визуальным восприятием и рассуждениями. Не является ли это свидетельством того, что стандартные бенчмарки недостаточно информативны для оценки реальных улучшений в мультимодальном мышлении и требуют более детального анализа внутренних механизмов моделей?
Визуальное мышление: Преодоление границ рассуждений
Несмотря на впечатляющие возможности, демонстрируемые моделями, объединяющими зрение и язык, истинное визуальное рассуждение продолжает оставаться сложной задачей. Эти модели способны успешно выполнять многие задачи, такие как классификация изображений и генерация подписей, однако сталкиваются с трудностями при анализе сложных визуальных сцен, требующих логических выводов и понимания контекста. Хотя модели и способны распознавать объекты на изображении, им часто не хватает способности понять взаимосвязи между ними, предсказать последствия событий или ответить на вопросы, требующие более глубокого анализа, чем простое сопоставление визуальных признаков с текстовыми метками. Это указывает на то, что для достижения настоящего визуального интеллекта необходимы новые подходы, выходящие за рамки простого увеличения размера модели и объема обучающих данных.
Современные модели, объединяющие зрение и язык, зачастую испытывают трудности при анализе сложных визуальных сцен, требующих многоступенчатых логических выводов. В то время как они успешно справляются с простыми задачами, такими как распознавание объектов или подписи к изображениям, более глубокое понимание контекста и взаимосвязей между элементами изображения представляет собой серьезную проблему. Например, при определении причины и следствия в визуальной ситуации или при прогнозировании дальнейшего развития событий, модели демонстрируют ограниченные возможности. Они склонны к поверхностному анализу и не способны к построению сложных умозаключений, необходимых для решения задач, требующих критического мышления и абстрактного рассуждения на основе визуальной информации.
Несмотря на впечатляющий прогресс в области мультимодальных моделей, связывающих зрение и язык, простое увеличение их размера не приводит к пропорциональному улучшению способности к рассуждениям. Исследования показывают, что увеличение количества параметров может привести к запоминанию обучающих данных, а не к развитию истинного понимания визуальной информации и способности делать логические выводы. Вместо этого, необходим более целенаправленный подход, ориентированный на разработку архитектур и методов обучения, которые активно стимулируют и развивают навыки визуального мышления, позволяя моделям не просто распознавать объекты, но и анализировать их взаимосвязи, предсказывать последствия и решать сложные задачи, требующие многоступенчатых умозаключений.

Двухэтапный процесс: Уточнение визуального мышления
Для формирования базового понимания решаемых задач используется двухэтапный процесс обучения, начинающийся с контролируемой тонкой настройки (Supervised Finetuning). Этот этап предполагает обучение модели на размеченном наборе данных, где для каждого входного изображения предоставляется правильный ответ. Целью контролируемой тонкой настройки является оптимизация весов модели для точного воспроизведения этих размеченных данных, что позволяет ей усвоить основные закономерности и принципы, необходимые для дальнейшего обучения и решения более сложных задач. Этот начальный этап критически важен для обеспечения стабильного и эффективного обучения на последующих этапах.
После этапа контролируемого обучения модель подвергается обучению с подкреплением, направленному на конкретное улучшение навыков рассуждения. В отличие от простого распознавания закономерностей, обучение с подкреплением позволяет модели активно исследовать пространство решений и учиться на своих ошибках. Этот процесс включает в себя определение вознаграждения за правильные шаги в процессе решения задачи, что стимулирует модель к освоению более сложных стратегий и повышению способности решать визуальные задачи, требующие логического вывода и анализа.
Обучение модели с использованием предложенного подхода позволяет ей анализировать собственные ошибки, допущенные при решении сложных визуальных задач. В процессе обучения, модель идентифицирует неверные решения и корректирует свои внутренние параметры, чтобы избежать повторения этих ошибок в будущем. Такой механизм самокоррекции способствует постепенному улучшению способности модели к решению более сложных и разнообразных визуальных проблем, выходя за рамки простого распознавания паттернов и приближаясь к более глубокому пониманию и логическому анализу визуальной информации.
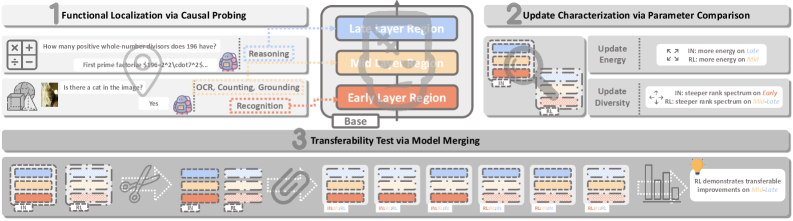
Локализация функций: Выявление ключевых слоев рассуждений
Функциональная локализация выявила, что обучение с подкреплением оказывает наибольшее влияние на средние и поздние слои архитектуры Transformer. Анализ показывает, что изменения, вызванные обучением с подкреплением, концентрируются именно в этих слоях, в то время как начальные слои остаются относительно нетронутыми. Это указывает на то, что обучение с подкреплением преимущественно модулирует процессы высокоуровневого рассуждения и принятия решений, которые реализуются в более глубоких слоях сети, а не базовое извлечение признаков, происходящее в начальных слоях. Наблюдаемое распределение изменений подтверждается результатами экспериментов по отмене отдельных слоев и обмену токенов, демонстрирующими снижение производительности в задачах, требующих рассуждений, при вмешательстве в средние и поздние слои.
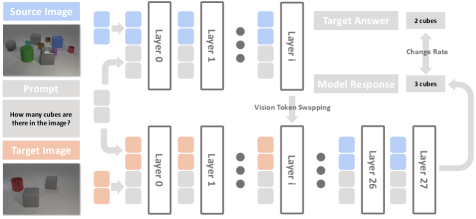
Методы нулевой абляции (Zero Ablation) и перестановки токенов изображения (Vision Token Swapping) подтверждают критическую роль средних и поздних слоев Transformer для выполнения задач, требующих сложных рассуждений. Эксперименты показали, что при удалении (абляции) этих слоев наблюдается значительное снижение точности на бенчмарках, ориентированных на математические и логические задачи, таких как GSM8K и MATH500. Перестановка токенов внутри этих слоев также приводит к заметному ухудшению результатов, что свидетельствует о важности их внутренней структуры и взаимодействия для обеспечения корректных выводов и решения задач, требующих анализа и логического мышления.
Каузальный зондинг позволяет установить причинно-следственные связи между отдельными компонентами средних и поздних слоев архитектуры Transformer и выходными данными модели. Данный метод предполагает целенаправленное изменение активности определенных нейронов или связей внутри этих слоев и последующую оценку влияния этих изменений на результаты решения задач. Анализ позволяет выявить, какие именно компоненты оказывают наиболее значимое влияние на формирование ответов, а также определить, как различные компоненты взаимодействуют друг с другом для достижения конкретных результатов. Результаты каузального зондинга используются для понимания механизмов принятия решений моделью и для выявления потенциальных возможностей улучшения ее производительности.
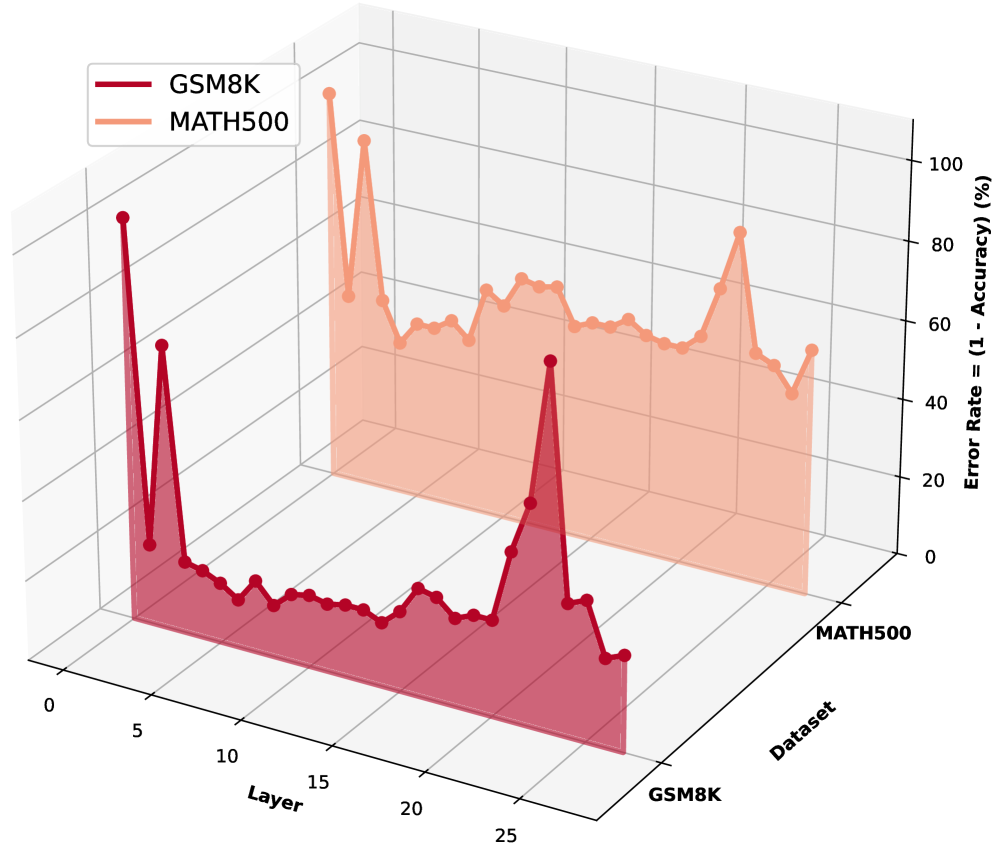
Согласованное уточнение: Усиление связи между зрением и рассуждением
Анализ показал, что обучение с подкреплением последовательно уточняет параметры слоев нейронной сети, расположенных в середине и в конце ее архитектуры. Это проявляется в более резком снижении спектра изменений весов в этих областях — иными словами, обновления параметров становятся более сфокусированными и менее распространенными по всей сети. Такой паттерн указывает на то, что обучение с подкреплением не просто вносит случайные корректировки, а целенаправленно перенастраивает уже сформированные представления, акцентируя внимание на наиболее важных параметрах в поздних слоях для повышения эффективности работы модели. Это позволяет сети более эффективно использовать визуальную информацию и улучшить процесс рассуждений, что подтверждается дальнейшими экспериментами.
Анализ параметров модели после обучения с подкреплением выявил заметные изменения в весах и активациях, сконцентрированные в среднем и поздних слоях нейронной сети. Исследование показало, что эти изменения не являются случайными, а отражают целенаправленную адаптацию, направленную на усиление взаимодействия между визуальной информацией и процессами рассуждения. В частности, наблюдается перераспределение весов, акцентирующее внимание на особенностях, релевантных для решения задач, требующих сопоставления визуальных данных и логического анализа. Данная закономерность подтверждается увеличением активности в соответствующих слоях при обработке визуальных стимулов и демонстрирует, что обучение с подкреплением эффективно оптимизирует внутреннее представление данных, способствуя более точному и эффективному решению задач.
Анализ показывает, что применение обучения с подкреплением приводит к усилению внимания так называемых «рассуждающих» токенов к визуальным данным. Это проявляется в заметном улучшении согласованности между зрительным восприятием и логическими выводами модели, что было подтверждено в экспериментах по слиянию моделей. В частности, наблюдается увеличение степени опоры на визуальную информацию (измеряемое показателем «Изменения — Видение — Оптическое распознавание символов») в слоях, подвергшихся обучению с подкреплением. Данное усиление связи между визуальными данными и процессами рассуждения способствует повышению общей производительности и надежности модели при решении задач, требующих комплексного анализа визуальной информации.
Исследование демонстрирует, что применение обучения с подкреплением последовательно улучшает средние и поздние слои моделей, объединяющих зрение и язык, что подтверждает их ключевую роль в улучшении согласованности между визуальным восприятием и логическими рассуждениями. Это согласуется с идеей о том, что понимание системы достигается через изучение ее закономерностей, поскольку именно эти слои отвечают за интерпретацию визуальной информации и ее преобразование в абстрактные понятия. Как отмечал Дэвид Марр: «Визуальная информация не является самоцелью, а лишь средством для построения трехмерной модели мира». Данное утверждение подчеркивает важность анализа и интерпретации визуальных данных для достижения полноценного понимания, что находит отражение в улучшении слоев, отвечающих за визуально-логическое соответствие.
Что дальше?
Полученные результаты, демонстрирующие, что обучение с подкреплением последовательно улучшает средние и поздние слои моделей, занимаются лишь локализацией функциональности, а не её глубоким пониманием. Это, конечно, ожидаемо. Вопрос в том, насколько далеко можно зайти, просто “подкручивая” эти слои, и не достигнем ли мы точки, где дальнейшая оптимизация принесет лишь незначительные улучшения. Настоящий вызов заключается в выявлении тех фундаментальных принципов визуального мышления, которые лежат в основе успешной работы этих моделей.
Необходимо переходить от анализа “что работает” к пониманию “почему это работает”. Исследование должно быть направлено на разработку более интерпретируемых моделей, позволяющих отслеживать процесс принятия решений и выявлять слабые места. Ключевым направлением представляется разработка методов, позволяющих модели не просто находить закономерности, но и объяснять их, демонстрируя причинно-следственные связи между визуальной информацией и логическими выводами.
Предлагаемый подход к “слиянию” моделей, хотя и перспективен, требует дальнейшей проработки. Важно понимать, какие именно компоненты модели вносят наибольший вклад в улучшение результатов, и как их можно эффективно комбинировать. Возможно, будущее за не просто “Франкенштейновскими” конструкциями, а за более элегантными архитектурами, сочетающими в себе сильные стороны различных подходов.
Оригинал статьи: https://arxiv.org/pdf/2602.12395.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Квантовые модели для моделирования потоков: новый взгляд на сжатие данных
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Нейросети, повинующиеся физике: новый подход к моделированию сложных систем
- Искусственный интеллект и человек: надежность как основа сотрудничества
- Разумное распределение задач: новый подход к управлению ИИ-агентами
- Понять, почему код не работает: объяснимый ИИ для отладки интеллектуальных агентов
2026-02-16 08:35